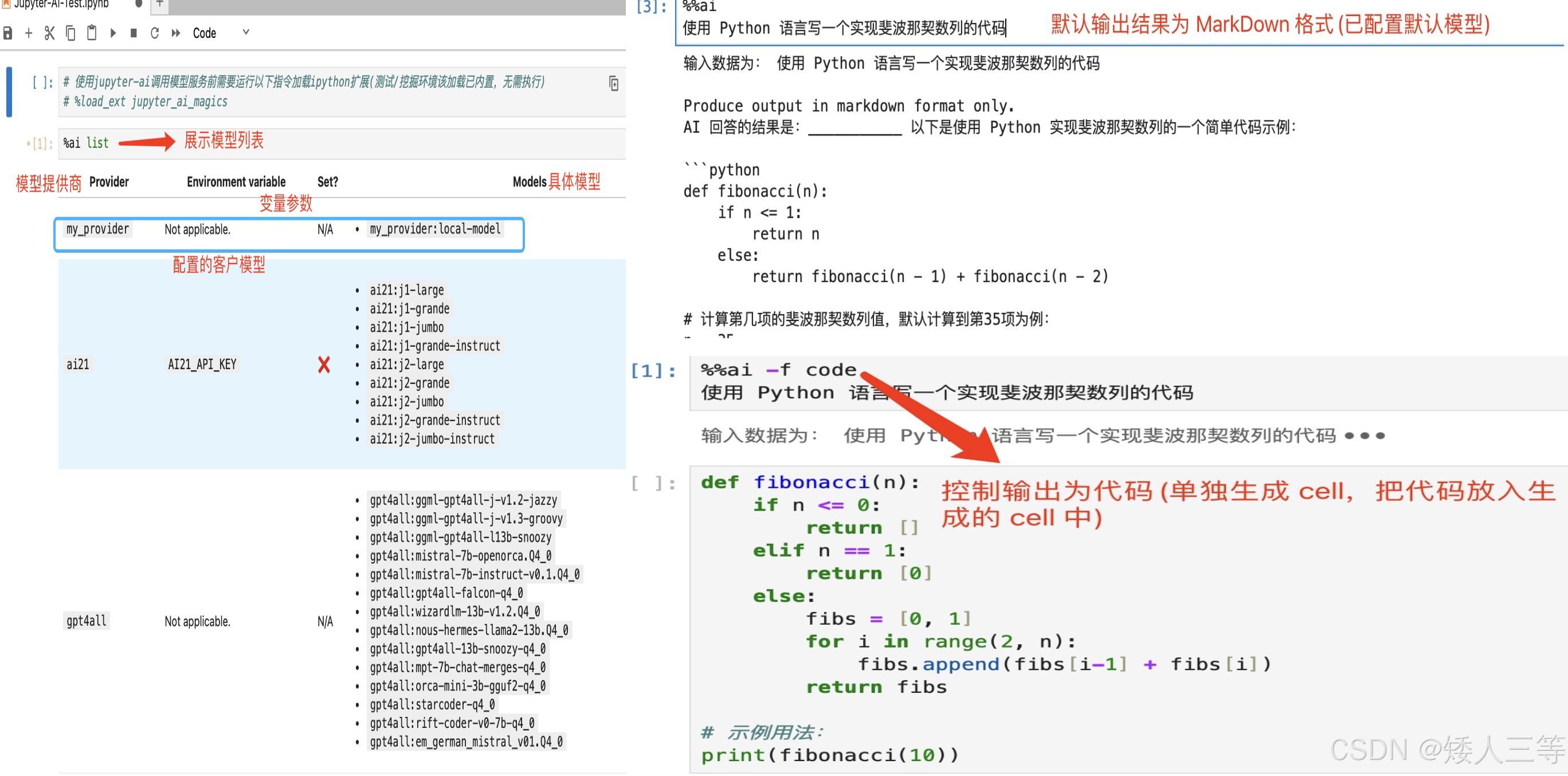
这是一个Benchmark,超分辨率+视频编码(2024)
- 专题介绍
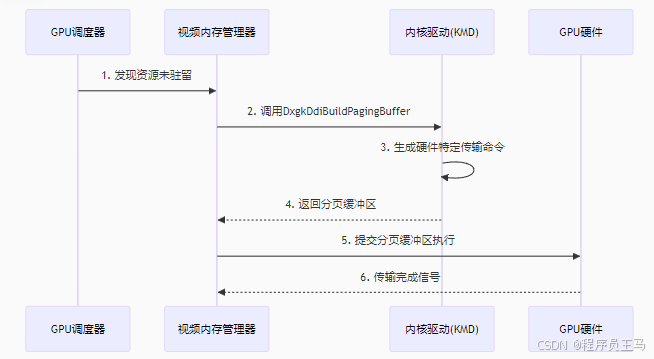
- 一、研究背景
- 二、相关工作
- 2.1 SR的发展
- 2.2 SR benchmark的发展
- 三、Benchmark细节
- 3.1 数据集制作
- 3.2 模型选择
- 3.3 编解码器和压缩标准选择
- 3.4 Benchmark pipeline
- 3.5 质量评估和主观评价研究
- 四、实验论证
- 4.1 视频质量评估结果
- 4.2 比特率降低测试
- 4.3 视频质量度量指标评估
- 五、总结
- 个人思考
本文将对SR+Codec: a Benchmark of Super-Resolution for Video Compression Bitrate Reduction进行解读,正如标题所示,建立了新的benchmark。参考资料如下:
[1]. SR+Codec Benchmark 论文地址
[2]. Benchmark(课题组成果展示)地址
专题介绍
现在是数字化时代,图像与视频早已成为信息传递的关键载体。超分辨率(super resolution,SR)技术能够突破数据源的信息瓶颈,挖掘并增强低分辨率图像与视频的潜能,重塑更高品质的视觉内容,是底层视觉的核心研究方向之一。并且SR技术已有几十年的发展历程,方案也从最早的邻域插值迭代至现今的深度学习SR,但无论是经典算法还是AI算法,都在视觉应用领域内发挥着重要作用。
本专题旨在跟进和解读超分辨率技术的发展趋势,为读者分享有价值的超分辨率方法,欢迎一起探讨交流。
一、研究背景
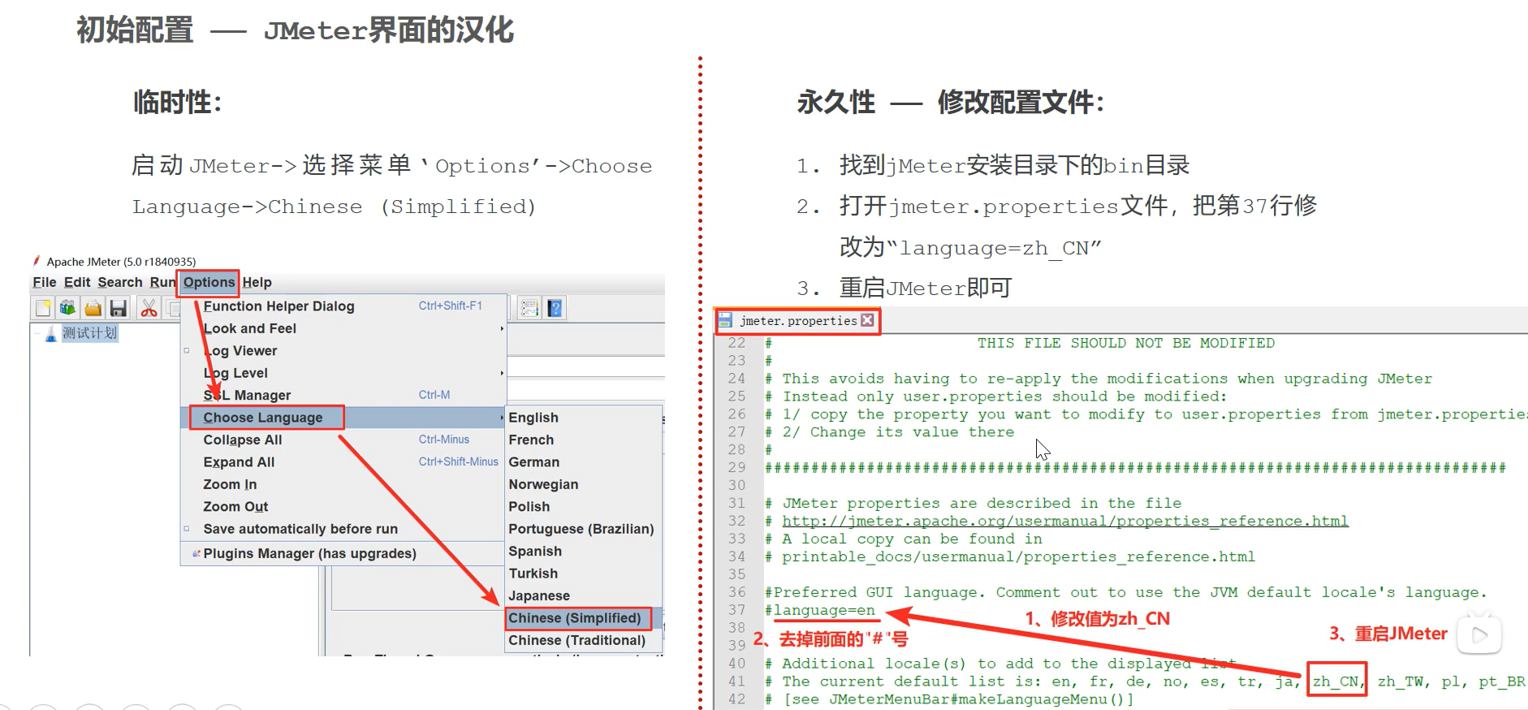
截至2022年,视频流量占比超80%互联网流量且持续增长,视频压缩技术能有效降低数据带宽消耗,但压缩意味着有损失。而SR技术可通过恢复细节以增强视频质量,具备优化压缩的潜力;不过现有SR模型对强压缩视频恢复效果有限且易出瑕疵(如下图示例)。

那么针对效果问题该如何做改进呢?哎,这不是本文的目的,本文的核心工作是:
- 提出了一个新的针对视频压缩复原的SR模型评测的benchmark。
- 评估了5个视频编解码器和19个SR模型。考虑了不同压缩比特率下的测试情况,考虑了在编码前对视频做降分辨率的情况。得出了几个结论
- 提出了将客观度量和主观评价(5397名受试者)相结合的评判标准。重点关注细节恢复和主观感知的表现,以及消除压缩伪影问题的能力。并构建了一个与主观评价相关性高的简单度量组合。
- 量化分析了SR在视频质量恢复与比特率优化中的实际效能,为编解码器设计(如LCEVC)提供模型选型依据。
作者期望本工作能够为低带宽高清视频传输提供技术路径,推动SR在实时编解码场景中的应用。
“我们来定更好的标准,你们来做更好的算法。”
有些新入坑的朋友可能会想,啥是benchmark呢?
benchmark是一种标准化的测试方法或数据集,用于衡量和比较不同算法或模型在特定任务上的性能。它提供了一种客观的评估标准,帮助研究人员和开发者了解他们的算法或模型在实际应用中的表现。根据类型划分,包括了数据集基准,任务基准,性能指标基准。
二、相关工作
2.1 SR的发展
言归正传,作者捋了捋当前的SR技术发展。这里基于文章内容简单整理了一个表。
| 功能维度 | 时间冗余利用类视频 SR 方法 | GAN 类 SR 方法 | 扩散模型类 SR 方法 |
|---|---|---|---|
| 核心思想 | 通过递归/双向传播对齐时空上下文 | 利用对抗训练生成逼真纹理 | 多步推理生成高质量结果 |
| 代表模型 | RBPN [17], COMISR [27], BasicVSR++ [15], VRT [29], RVRT [30], Swin2SR [16] | ESRGAN [38], Real-ESRGAN [39] | diffusion SR系列 [33,35,41,51] |
| 技术优势 | 双向递归扭曲(COMISR)、局部-全局注意力(Swin2SR)、跨片段预测(RVRT) | 高阶退化建模(Real-ESRGAN)、增强感知损失 | 图像生成质量优异 |
| 局限性 | 对压缩伪影敏感(如 VRT 在强压缩场景失效) | 过度锐化风险 | 推理步骤多(>100 步)→ 实时性差 |
| 适用场景 | 视频序列中运动连续性强(如手持抖动视频 [45]) | 压缩图像纹理修复(如自然图像) | 离线非实时任务(如存档修复) |
鉴于设计用于压缩视频的SR模型数量有限,所以作者认为评估现有SR模型在压缩视频上的性能仍是一项关键任务。(因少故难,不忘督促各位学者赶紧研究)
另外,有些方案会对视频做降分辨率的操作,从而降低比特率,在解码端设计特殊的解码器将同时实现解码和SR。
在本次基准测试中,仅考虑编解码器和SR方法彼此独立的情况,评估不同编解码器和SR方法如何结合在一起最佳。
2.2 SR benchmark的发展
其实关于SR的benchmark已有很多,本文更加聚焦于SR与Codec相结合。当然,前两年也有类似的benchmark
- NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video
- AIM 2022 Challenge on Super-Resolution of Compressed Image and Video
But!本项工作做了几个点的改进,采用了更广泛的视频质量度量和更多的视频编解码器。还做了不同SR对优化比特率能力的测试。
特地去看了下NTIRE2022,编码仅采用了HEVC。评价指标仅采用了PSNR,确实单一。同时建立了数据集LDV2.0。而AIM2022中关于视频压缩的超分挑战规则跟NTIRE2022中是一样的,只是将LDV数据集升级至3.0,新增了30个4K视频(来自youtube)。
博主对比了一下LDV2.0和LDV3.0的描述,基本上就是ctrl+c和ctrl+v,仅仅是数据量上增加了一些。(那为何要在同一年搞两次类似的挑战?难以理解) LDV1.0-3.0的数据集路径https://github.com/RenYang-home/LDV_ dataset,感兴趣的可以去看下。
三、Benchmark细节
3.1 数据集制作
作者没有考虑沿用LDV系列,而是自己搜集制作。为了保证基准数据集足够多样化,从多个来源收集了1920x1080的视频,包括:
- 视频网站片段:从视频网站截取了50个序列,包括real world和动画,并用VQMT将数据拆分成多个场景类型。
- 相机实拍:用佳能EOS 7D去拍摄室内室外场景,保证亮度和清晰度较为合适,共20个室内素材和30个室外素材,包含了目标运行和相机水平运动的两种情况。(大家可以思考下:这两种运动的区别是什么,为什么要区分?)
- 游戏视频片段,截取了20个片段,包括的2D和3D游戏视频。
然后获取了每个视频的特征,包括google时空特征,fps,颜色和最大face数量。基于这些特征,用k-means进行聚类,分成20个簇,每个簇选择一个视频,将其称为源视频。如下图所示。


这里有个新词汇,Google Spatial and Temporal features(google时空特征),其实就是空间复杂度和时间复杂度,前者用I帧的编码比特来计算,后者用P帧的编码比特来计算。(详情可参考引文《YouTube UGC dataset for video compression research》)
作者为了保证重要细节在降尺度和压缩后不完全丢失,只考虑了空间和时间复杂度低的视频,且没有很重的模糊和噪声。还表示相机运动有助于SR算法利用帧间信息做恢复。
拍脑袋想,所谓空间复杂度低就是没有很丰富的细节纹理,时间复杂度低就是没有大范围的剧烈运动。
为啥这么选?因为丰富的细节纹理压缩后损失明显,难以复原,也就很难体现SR的效果,那岂不是等于白评估。
3.2 模型选择
数据标准搞定了,模型怎么选?
作者从细节复原和感知质量提升这两个维度评估和考虑,排除了一些类似的方案,选择了19种模型,包括BasicVSR++,COMISR,DBVSR,EGVSR,LGFN,RBPN,Real-ESRGAN,RealSR,RSDN,SOF-VSR-BD,SOF-VSR-BI,SwinIR,TMNet,VRT,RVRT,IART,AnimeSR,Topaz Video AI 和 bicubic插值。 均采用原作者的预训练权重。
等等,里面怎么还有图像超分算法呢?原来是作者认为高质量视频SR模型稀缺,所以加入了图像SR一起作为比较。
3.3 编解码器和压缩标准选择
作者选择5种编码器,突出一个丰富且全面。

3.4 Benchmark pipeline
benchmark pipeline如下图所示。

- 先用FFmpeg将源视频降分辨率至480x270,用双三次选型。
- 选用0.6、1.0和2 Mbps的比特率对低分辨率视频做压缩。(客观评价时还增加了0.1,0.3,4.0Mbps的压缩档位)
- 编码器均采用了medium配置(应该理解为中等质量)。
- 压缩后的视频使用FFmpeg对PNG序列进行转码,作为SR模型输入。
- 将图像SR模型单独应用于每一帧;视频SR模型按照正确的顺序接收到包含帧的目录路径。
- 测试4x放大的效果,部分模型只支持2x,这种情况就处理2次。
说实话,图像SR会吃亏一些(缺少时域维度信息),个人感觉缺乏点严谨性,要么就图像SR相互对比,视频SR相互对比。
3.5 质量评估和主观评价研究
客观评价指标有:PSNR,MS-SSIM,VMAF,LPIPS,MDTVSFA(唯一的无参考)和ERQA。主要考虑了全参考指标,优先关注细节恢复,而不是感知质量。
主观评价采用了众包评价(找一堆不相干的人来评估)。由于在整个画面中,细节丢失和压缩伪影可能不容易被注意到,因此改为对剪裁块做评估。裁剪区域则是通过计算视频的显著性区域来确定。为了让评估者在屏幕上能够更好地进行比较,他们将剪裁的分辨率设置为480×270。这种方法使得评估者能够更清晰地观察到细节和压缩伪影,从而更准确地比较不同超分辨率模型的效果。除此之外,用对应的裁剪块计算客观指标,以确定客观指标与主观评分的相关性。
具体主观评价过程是随机给出两个SR模型的一对视频,让评价者选择看起来更真实、压缩伪影更少的视频(“不可区分”也是选择)。
那么由于担心有些人浑水摸鱼,睁眼说瞎话。还很机智地设置了3个验证性问题。还真筛选出了265位摸鱼侠(剔除了)。最后用Bradley-Terry模型计算最终的主观分数。(共120316个评估结果)
四、实验论证
针对每个编解码器,基于LPIPS指标,挑选了10个最佳的模型进行评估。(并不是所有模型都有资格进入决赛圈,肯定不是为了省事)
4.1 视频质量评估结果
作者选了每个编解码方案下,无SR和两种最佳SR效果作为结果展示。发现了几个有意思的点:
- x264编码器: SwinIR和Real-ESRGAN抗压缩伪影效果最优,带生成能力的方案有优势。
- AV1编码器: 直接压缩(无需SR)表现最佳,加SR反而冗余。
- H.265/H.266: RVRT和RBPN模型恢复能力突出。

作者解释这种差异性跟编解码器的特性是相关的。
4.2 比特率降低测试
下表说明了,主观评分下,没有一种SR模型是具备通用性的。例如RealSR在高比特率效果不佳,但低比特率的效果反而有优势,在AVI数据上甚至NO SR是最好的。原因表述与上个结论一样。


效果上看,低比特率+SR能改善伪影问题,但至于比特率下降到多少是合适的,得看具体任务目标还有选用的编解码器。
4.3 视频质量度量指标评估
通过计算PLCC和SRCC来评价主观和客观指标的相关性,发现相关性普遍较低。

结合**ERQA(边缘恢复质量)与MDTVSFA(多维度时空质量)**的复合指标,与主观评分相关性提升至0.801。建议可以用该复合指标来逼近主观评价。
五、总结
最后回顾一下,作者建立了一个关于SR+Codec的benchmark,然后研究过程中有以下几个结论:
- 例如RealSR和RVRT能够在解码之后提升低比特率视频的主观感知质量。
- RVRT可以提高x265和vvenc编解码后的视频质量。
- RealSR可以配合x264一起使用,在不降质的情况下,将视频比特率降低65%以上。
- 现有视频质量评价指标与主观评分的相关性很差,不适合评估基于降尺度的视频编码结果。
- 但ERQAxMDTVSFA组合的评价方式与主观评价的相关性较高,可以采用该组合作为评价指标。
- 对于一些高级编解码器而言,如uavs3e,aomenc等,用SR算法做增强处理的价值不大,主观效果不如无SR的。
根据文章提供的benchmark网址,博主点进去看了看,好家伙,这个实验室或是专门搞benchmark的,有个专题列表,这里截了点一部分,感兴趣的可以去详细了解一下。(组织名:MCU Graphics & Media Laboratory)

不过有一说一,好的benchmark确实能够给领域内的研究人员或开发人员提供不错参考和对比。
个人思考
AI SR+Codec的组合可能已经在一些视觉产品上落地使用了。Codec实现低成本数据传输,SR实现高质量结果展示。博主认为这个方向的研究与探索是很有价值的,特别是对于轻量化采集设备而言。
当然,确实没有一个SR方案能够通吃,很多模型都有各自的局限性(不考虑大模型)。要做好此类任务,需要开发者了解各模型的优劣势,同时掌握一些Codec的知识,这样才能针对性地做调整和改进。
感谢阅读!如有疑问,欢迎留言或私信。
关注博主,一起学习更多的底层视觉技术!