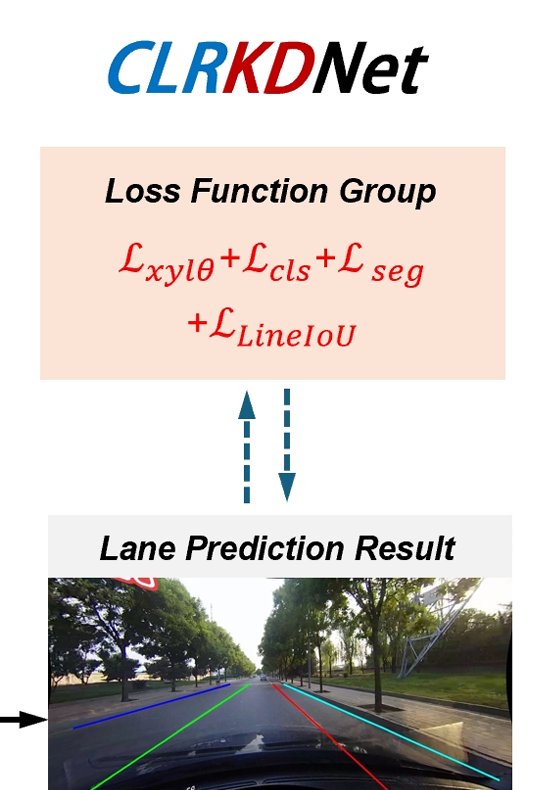
题目要求从字符串数组 words 中选出一个最长的子序列,使得该子序列中相邻字符串对应的 groups 数组中的值不同。通过贪心算法,可以高效地解决该问题。具体步骤为:初始化一个结果列表,遍历 words 数组,检查当前字符串的 groups 值是否与结果列表中最后一个字符串的 groups 值不同,若不同则将其加入结果列表。该算法的时间复杂度和空间复杂度均为 O(n),其中 n 为 words 数组的长度。通过一次遍历即可得到满足条件的最长子序列。
目录
题目链接:2900. 最长相邻不相等子序列 I - 力扣(LeetCode)
题目描述
解法一:贪心算法
Java写法:
C++写法:
运行时间
时间复杂度和空间复杂度
时间复杂度
空间复杂度
总结
总结
题目链接:2900. 最长相邻不相等子序列 I - 力扣(LeetCode)
注:下述题目描述和示例均来自力扣
题目描述
给你一个下标从 0 开始的字符串数组 words ,和一个下标从 0 开始的 二进制 数组 groups ,两个数组长度都是 n 。
你需要从 words 中选出 最长子序列。如果对于序列中的任何两个连续串,二进制数组 groups 中它们的对应元素不同,则 words 的子序列是不同的。
正式来说,你需要从下标 [0, 1, ..., n - 1] 中选出一个 最长子序列 ,将这个子序列记作长度为 k 的 [i0, i1, ..., ik - 1] ,对于所有满足 0 <= j < k - 1 的 j 都有 groups[ij] != groups[ij + 1] 。
请你返回一个字符串数组,它是下标子序列 依次 对应 words 数组中的字符串连接形成的字符串数组。如果有多个答案,返回 任意 一个。
注意:words 中的元素是不同的 。
示例 1:
输入:words = ["e","a","b"], groups = [0,0,1] 输出:["e","b"] 解释:一个可行的子序列是 [0,2] ,因为 groups[0] != groups[2] 。 所以一个可行的答案是 [words[0],words[2]] = ["e","b"] 。 另一个可行的子序列是 [1,2] ,因为 groups[1] != groups[2] 。 得到答案为 [words[1],words[2]] = ["a","b"] 。 这也是一个可行的答案。 符合题意的最长子序列的长度为 2 。
示例 2:
输入:words = ["a","b","c","d"], groups = [1,0,1,1] 输出:["a","b","c"] 解释:一个可行的子序列为 [0,1,2] 因为 groups[0] != groups[1] 且 groups[1] != groups[2] 。 所以一个可行的答案是 [words[0],words[1],words[2]] = ["a","b","c"] 。 另一个可行的子序列为 [0,1,3] 因为 groups[0] != groups[1] 且 groups[1] != groups[3] 。 得到答案为 [words[0],words[1],words[3]] = ["a","b","d"] 。 这也是一个可行的答案。 符合题意的最长子序列的长度为 3 。
提示:
1 <= n == words.length == groups.length <= 1001 <= words[i].length <= 10groups[i]是0或1。words中的字符串 互不相同 。words[i]只包含小写英文字母。
解法一:贪心算法
-
初始化:我们需要一个结果列表来存储最终的答案,以及一个映射(或直接使用索引)来追踪每个单词在原数组中的位置。
-
遍历:对于每一个单词,检查它是否可以加入到当前的结果列表中:
- 如果结果列表为空,直接添加。
- 否则,比较当前单词对应的
groups值和结果列表中最后一个单词的groups值。如果这两个值不同,则将当前单词添加到结果列表中。
这样确保了我们能够构造出一个满足条件的最长子序列,并且只需要一次遍历整个数组即可完成任务。
Java写法:
class Solution {
public List<String> getLongestSubsequence(String[] words, int[] groups) {
// 用于存储word到其索引的映射
Map<String, Integer> wordToIndex = new HashMap<>();
for (int i = 0; i < words.length; i++) {
wordToIndex.put(words[i], i);
}
List<String> result = new ArrayList<>();
for (String word : words) {
if (result.isEmpty()) {
result.add(word);
} else {
// 当前单词对应的group值
int currentGroup = groups[wordToIndex.get(word)];
// 结果列表中最后一个单词对应的group值
int lastGroup = groups[wordToIndex.get(result.get(result.size() - 1))];
// 如果当前单词与结果列表中最后一个单词对应不同的group,则添加到结果列表
if (currentGroup != lastGroup) {
result.add(word);
}
}
}
return result;
}
}C++写法:
#include <vector>
#include <string>
#include <unordered_map>
using namespace std;
vector<string> getLongestSubsequence(vector<string>& words, vector<int>& groups) {
unordered_map<string, int> wordToIndex;
for (int i = 0; i < words.size(); ++i) {
wordToIndex[words[i]] = i;
}
vector<string> result;
for (const string& word : words) {
if (result.empty()) {
result.push_back(word);
} else {
int currentIndex = wordToIndex[word];
int lastIndex = wordToIndex[result.back()];
if (groups[currentIndex] != groups[lastIndex]) {
result.push_back(word);
}
}
}
return result;
}
// 示例测试函数
#include <iostream>
void test() {
vector<string> words = {"a","b","c","d"};
vector<int> groups = {1,0,1,1};
vector<string> result = getLongestSubsequence(words, groups);
cout << "Result: ";
for (const string& str : result) {
cout << str << " ";
}
cout << endl;
}
int main() {
test();
return 0;
}运行时间
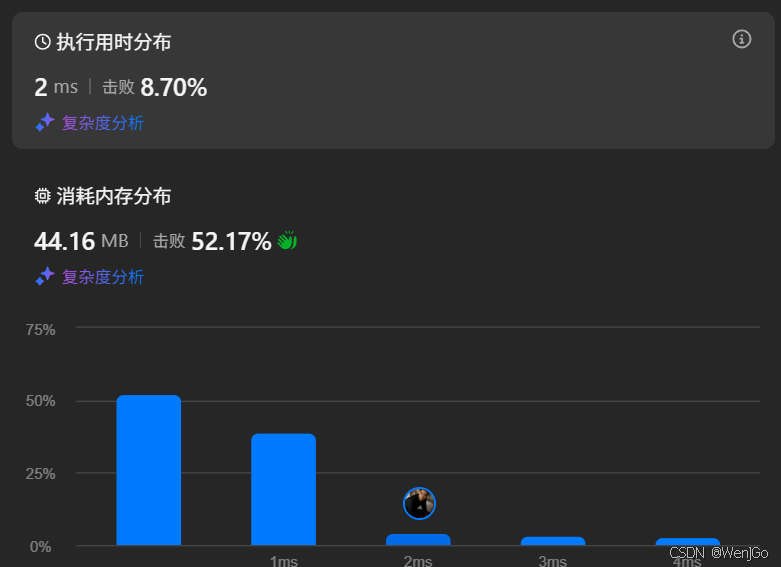
时间复杂度和空间复杂度
时间复杂度
-
初始化映射(unordered_map):在开始时,我们需要遍历一次
words数组来填充wordToIndex映射。这一步的时间复杂度是 O(n),其中 n 是words数组的长度。 -
遍历
words数组构建结果列表:接下来,我们再次遍历整个words数组来构建最长子序列。对于数组中的每个单词,我们检查其对应的groups值与结果列表中最后一个单词的groups值是否不同。这里假设查找操作(包括在unordered_map中查找以及访问向量末尾元素的操作)平均为 O(1)。因此,这一步的时间复杂度也是 O(n)。
空间复杂度
-
存储
wordToIndex映射:我们需要一个额外的空间来存储words数组中每个单词及其索引位置的映射。由于有 n 个单词,所以这部分的空间复杂度是 O(n)。 -
存储结果列表
result:在最坏的情况下,所有单词都可能被添加到结果列表中(例如当groups数组交替变化时)。这意味着结果列表的最大长度也可能达到 n,因此这部分的空间复杂度同样是 O(n)。
总结
- 时间复杂度:O(n)
- 空间复杂度:O(n)
总结
题目要求从字符串数组 words 中选出一个最长的子序列,使得该子序列中相邻字符串对应的 groups 数组中的值不同。通过贪心算法,可以高效地解决该问题。具体步骤为:初始化一个结果列表,遍历 words 数组,检查当前字符串的 groups 值是否与结果列表中最后一个字符串的 groups 值不同,若不同则将其加入结果列表。该算法的时间复杂度和空间复杂度均为 O(n),其中 n 为 words 数组的长度。通过一次遍历即可得到满足条件的最长子序列。

![[逆向工程]DebugView捕获WPS日志?解析未运行WPS时Shell扩展加载的原因与解决方案(二十五)](https://i-blog.csdnimg.cn/direct/f6529ac9069d406a8e242f2d06b4b2cd.png#pic_center)