知识蒸馏综述提炼
目录
知识蒸馏综述提炼
前言
参考文献
一、什么是知识蒸馏?
二、为什么要知识蒸馏?
三、一点点理论
四、知识蒸馏代码
总结
前言
知识蒸馏作为一种新兴的、通用的模型压缩和迁移学习架构,在最近几年展现出蓬勃的活力。综合看的一些知识蒸馏综述总结如下。
参考文献
[1]邵仁荣,刘宇昂,张伟,等.深度学习中知识蒸馏研究综述[J].计算机学报,2022,45(08):1638-1673.
一、什么是知识蒸馏?
知识蒸馏本质上属于迁移学习的范畴,其主要思路是将已训练完善的模型作为教师模型,通过控制“温度”从模型的输出结果中“蒸馏”出“知识”用于学生模型的训练,并希望轻量级的学生模型能够学到教师模型的“知识”,达到和教师模型相同的表现。这里的“知识”狭义上的解释是教师模型的输出中包含了某种相似性,这种相似性能够被用迁移并辅助其它模型的训练,Hinton称之为“暗知识”;广义上的解释是教师模型能够被利用的一切知识形式,如特征、参数、模块等等。而“蒸馏”是指通过某些方法(如控制参数),能够放大这种知识的相似性,并使其显现的过程;由于这一操作类似于化学实验中“蒸馏”的操作,因而被形象地称为“知识蒸馏”。知识蒸馏的发展历程如图1所示,根据不同的划分形式,知识蒸馏框架又可细分如图2所示,图3-4对比了不同方法的优缺点。
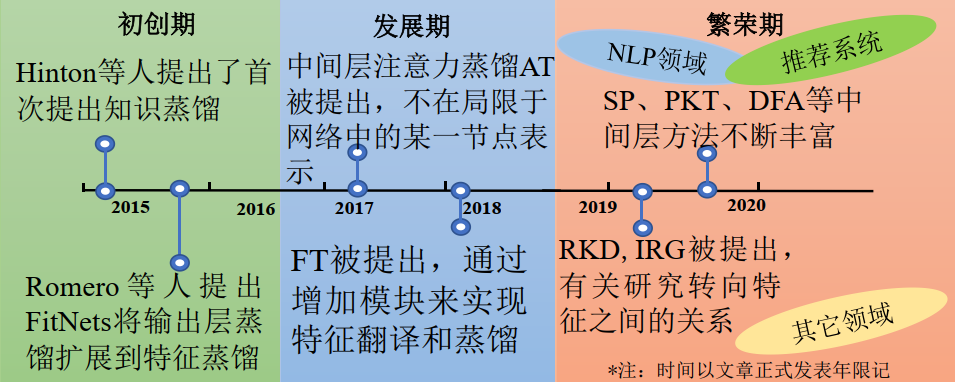
图1 知识蒸馏的发展历程
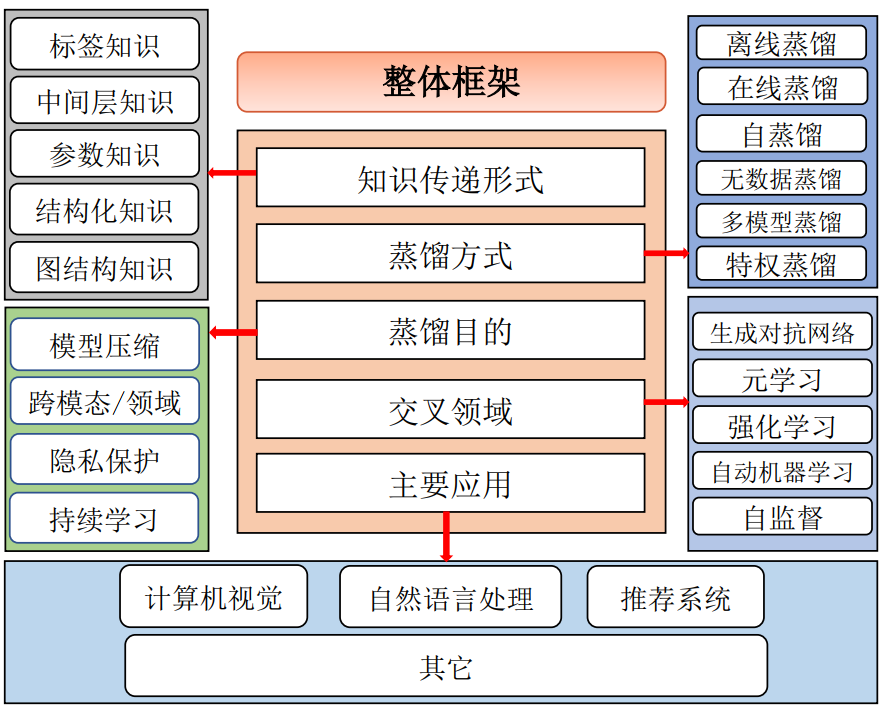
图2 知识蒸馏整体分类框架

图3 不同“知识”表达形式的优缺点
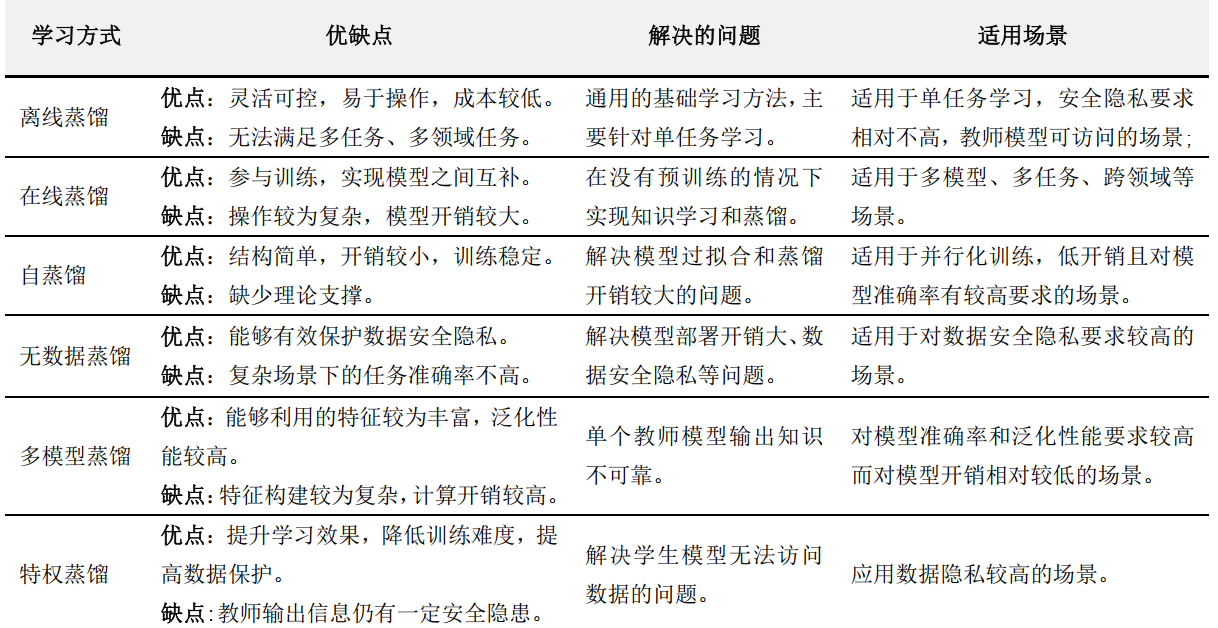
图4 不同蒸馏方法的优缺点
二、为什么要知识蒸馏?
深度学习在计算机视觉、语音识别、自然语言处理等内的众多领域中均取得了令人难以置信的性能。但是,当前的一些SOTA模型也存在一定的局限,比如过于依赖计算设备的性能
模型压缩
随着任务的复杂性增加、性能要求愈高,导致神经网络模型的结构愈加复杂,这直接导致了计算成本的急剧上升,严重限制了其在移动嵌入式设备上的部署和应用。
跨模态/跨领域
知识蒸馏结合跨领域能够很好地解决交叉任务和不同任务上知识的融合。通过重用跨任务模型的知识有助于提升目标域的泛化效果和鲁棒性。其存在的主要问题在于源域中的数据分布和目标域数据分布不一致,可能会带来一定的偏差,因此在迁移过程中需要考虑域适应(Domain Adaptation)的问题。
隐私保护
传统的深度学习模型很容易受到隐私攻击。因此,出于隐私或机密性的考虑,大多数数据集都是私有的,不会公开共享。特别是在处理生物特征数据、患者的医疗数据等方面。因此,模型获取用于模型训练优质数据,并不现实。对于模型来说,既希望能访问这些隐私数据的原始训练集,而又不能将其直接暴露给应用。因而,可以通过教师-学生结构的知识蒸馏来隔离的数据集的访问。让教师模型学习隐私数据,并将知识传递给外界的模型。
持续学习
持续学习(Continual Learning) 是指一个学习系统能够不断地从新样本中学习新的知识,并且保存大部分已经学习到的知识,其学习过程也十分类似于人类自身的学习模式。但是持续学习需要面对一个非常重要的挑战是灾难性遗忘,即需要平衡新知识与旧知识之间的关系。知识蒸馏能够将已学习的知识传递给学习模型实现“知识”的增量学习(Incremental Learning)
三、一点点理论
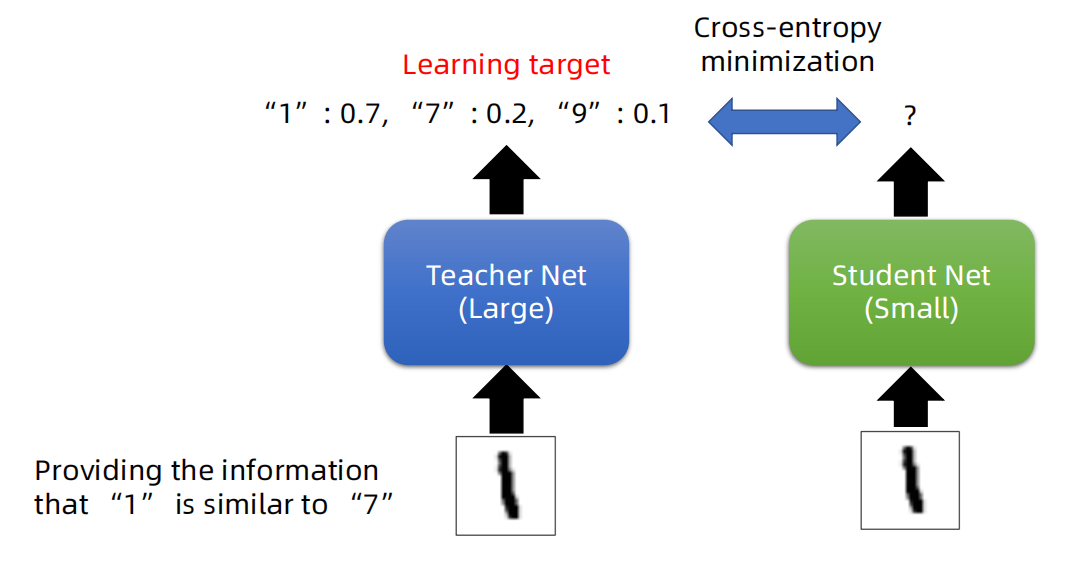
图1 “暗知识”
以手写数字为例,教师网络对数字1 11的预测标签为" 1 " : 0.7 , " 7 " : 0.2 , " 9 " : 0.1,这里1的预测概率最大为 0.7 是正确的分类,但是标签" 7 " " 9 " 的预测概率也能提供一些信息,就是说 " 7 " , " 9 " 和预测标签1 还是有某种预测的相似度的。如果把这个信息也教会学生网络,学生网络就可以了解到这种类别之间的相似度,可以看作为学习到了教师网络中隐藏的知识,对于学生网络的分类是有帮助的。
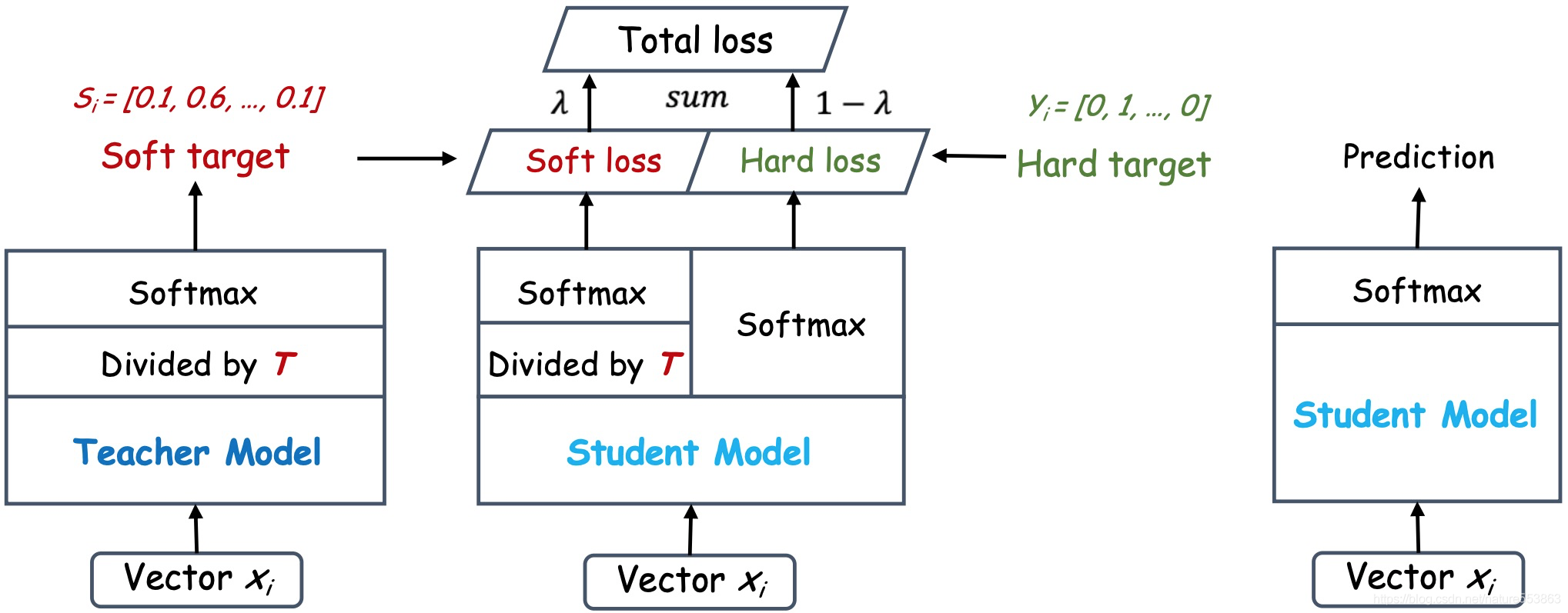
图2 知识蒸馏的过程
如上图所示,教师网络(左侧)的预测输出除以温度参数(Temperature)之后、再做Softmax计算,可以获得软化的概率分布(软目标或软标签),数值介于0 − 1之间,取值分布较为缓和。Temperature数值越大,分布越缓和;而Temperature数值减小,容易放大错误分类的概率,引入不必要的噪声。针对较困难的分类或检测任务,Temperature通常取1 ,确保教师网络中正确预测的贡献。硬目标则是样本的真实标注,可以用One-hot矢量表示。Total loss设计为软目标与硬目标所对应的交叉熵的加权平均(表示为KD loss与CE loss),其中软目标交叉熵的加权系数越大,表明迁移诱导越依赖教师网络的贡献,这对训练初期阶段是很有必要的,有助于让学生网络更轻松的鉴别简单样本,但训练后期需要适当减小软目标的比重,让真实标注帮助鉴别困难样本。另外,教师网络的预测精度通常要优于学生网络,而模型容量则无具体限制,且教师网络推理精度越高,越有利于学生网络的学习。
教师网络与学生网络也可以联合训练,此时教师网络的暗知识及学习方式都会影响学生网络的学习,具体如下(式中三项分别为教师网络Softmax输出的交叉熵loss、学生网络Softmax输出的交叉熵loss、以及教师网络数值输出与学生网络Softmax输出的交叉熵loss)
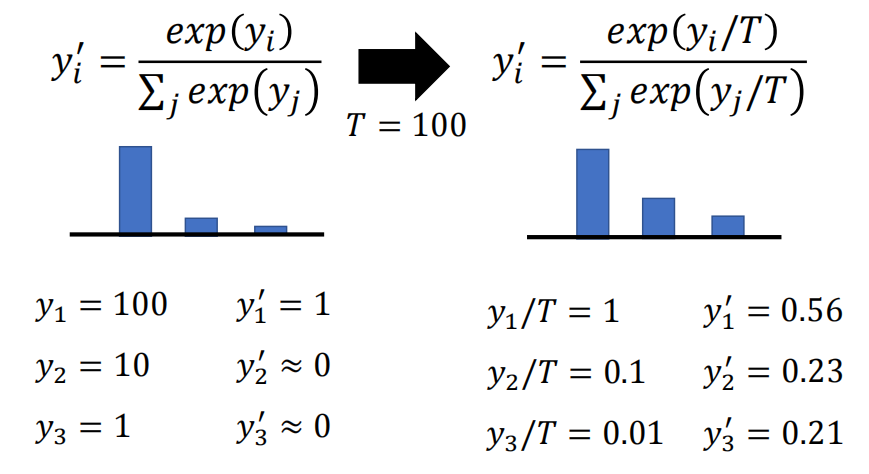
图3 温度函数的作用
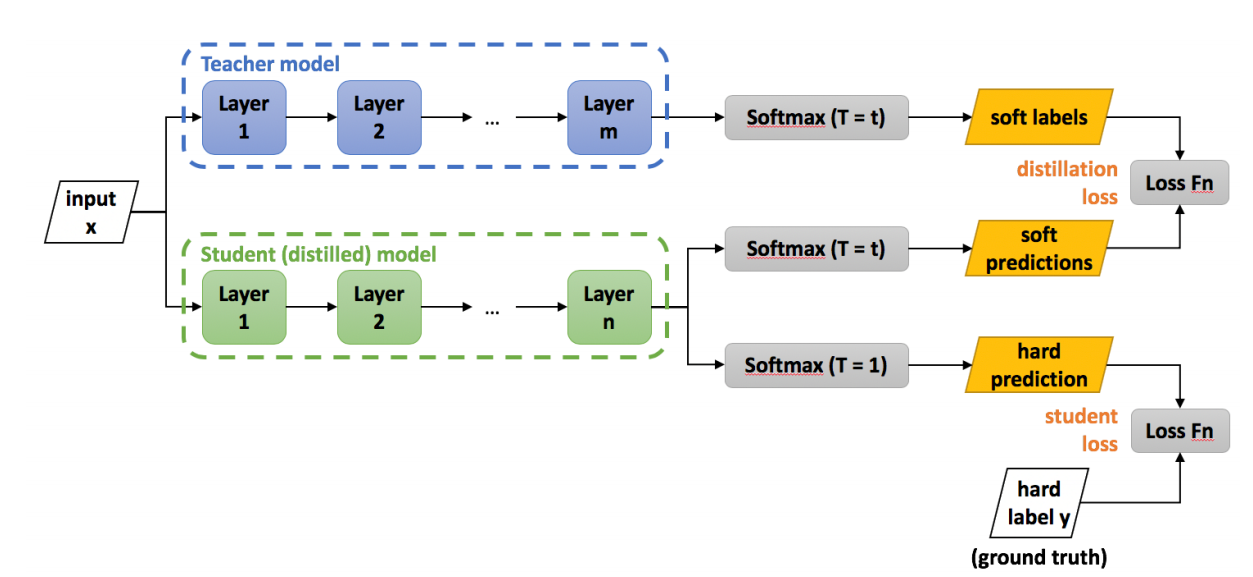
图4 损失函数的计算步骤
在分类网络中知识蒸馏的 Loss 计算
上部分教师网络,它进行预测的时候, softmax要进行升温,升温后的预测结果我们称为软标签(soft label)
学生网络一个分支softmax的时候也进行升温,在预测的时候得到软预测(soft predictions),然后对soft label和soft predictions 计算损失函数,称为distillation loss ,让学生网络的预测结果接近教师网络;
学生网络的另一个分支,在softmax的时候不进行升温T =1,此时预测的结果叫做hard prediction 。然后和hard label也就是 ground truth直接计算损失,称为student loss 。
总的损失结合了distilation loss和student loss ,并通过系数a加权,来平衡这两种Loss ,比如与教师网络通过MSE损失,学生网络与ground truth通过cross entropy损失, Loss的公式可表示如下:
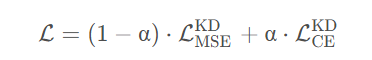
四、知识蒸馏代码
一个简单的基于pytorch实现的知识蒸馏代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 超参数设置
batch_size = 64
epochs_teacher = 5 # 教师模型训练轮数
epochs_student = 5 # 学生模型训练轮数
temperature = 5 # 温度参数(关键超参数)
alpha = 0.7 # 蒸馏损失权重
lr = 0.001 # 学习率
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据加载
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 教师模型定义
class TeacherModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = x.view(-1, 784)
x = torch.relu(self.fc1(x))
x = self.dropout(x)
x = torch.relu(self.fc2(x))
x = self.dropout(x)
return self.fc3(x)
# 学生模型定义(更简单结构)
class StudentModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 784)
x = torch.relu(self.fc1(x))
return self.fc2(x)
# 训练教师模型
def train_teacher():
teacher = TeacherModel().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(teacher.parameters(), lr=lr)
for epoch in range(epochs_teacher):
teacher.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = teacher(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 验证
teacher.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = teacher(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print(f"Teacher Epoch {epoch + 1}, Accuracy: {correct / len(test_loader.dataset):.4f}")
return teacher
# 知识蒸馏训练
def distill(teacher, student):
student = student.to(device)
teacher.eval() # 固定教师模型参数
# 定义两个损失函数
criterion_ce = nn.CrossEntropyLoss()
criterion_kl = nn.KLDivLoss(reduction="batchmean")
optimizer = optim.Adam(student.parameters(), lr=lr)
for epoch in range(epochs_student):
student.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# 获取教师和学生的输出
with torch.no_grad():
teacher_logits = teacher(data)
student_logits = student(data)
# 计算学生损失(常规交叉熵损失)
student_loss = criterion_ce(student_logits, target)
# 计算蒸馏损失(KL散度损失)
soft_targets = nn.functional.softmax(teacher_logits / temperature, dim=1)
soft_output = nn.functional.log_softmax(student_logits / temperature, dim=1)
distillation_loss = criterion_kl(soft_output, soft_targets) * (temperature ** 2)
# 组合损失
total_loss = alpha * student_loss + (1 - alpha) * distillation_loss
total_loss.backward()
optimizer.step()
# 验证
student.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = student(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print(f"Distillation Epoch {epoch + 1}, Accuracy: {correct / len(test_loader.dataset):.4f}")
return student
# 普通训练学生模型(作为对比)
def train_student():
student = StudentModel().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(student.parameters(), lr=lr)
for epoch in range(epochs_student):
student.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = student(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 验证
student.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = student(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print(f"Normal Student Epoch {epoch + 1}, Accuracy: {correct / len(test_loader.dataset):.4f}")
return student
# 主程序
if __name__ == "__main__":
# 训练教师模型
print("Training Teacher Model...")
teacher = train_teacher()
# 普通训练学生模型
print("\nTraining Student Model Normally...")
normal_student = train_student()
# 知识蒸馏训练学生模型
print("\nDistilling Knowledge to Student Model...")
distilled_student = distill(teacher, StudentModel())总结
本文仅仅简单介绍了知识蒸馏的相关知识,讲解不到的地方请指正!







![【问题】Watt加速github访问速度:好用[特殊字符]](https://i-blog.csdnimg.cn/direct/f495eb5554a74537ae6a9879676c1f99.png)

![[训练和优化] 3. 模型优化](https://i-blog.csdnimg.cn/blog_migrate/tags/671f42ab07fd990f949a1c903140dd83.png#pic_center)
