PPO(Proximal Policy Optimization)是一种基于策略梯度的强化学习算法,旨在通过限制策略更新幅度来提升训练稳定性。传统策略梯度方法(如REINFORCE)直接优化策略参数,但易因更新步长过大导致性能震荡或崩溃。PPO通过引入近端策略优化目标函数和截断技巧(Clipping Trick)替代TRPO的信任区域约束,约束新旧策略之间的差异,避免策略突变,既保持了策略更新的稳定性,又显著降低了计算成本。其核心思想是:在保证策略改进的同时,限制策略更新的幅度。
前文基础:
(1)基于值函数的强化学习算法之Q-Learning详解:基于值函数的强化学习算法之Q-Learning详解_网格世界q值-CSDN博客
(2)基于值函数的强化学习算法之SARSA详解:基于值函数的强化学习算法之SARSA详解_sarsa算法流程-CSDN博客
(3)基于值函数的强化学习算法之深度Q网络(DQN)详解:基于值函数的强化学习算法之深度Q网络(DQN)详解_dqn算法对传统q-learning算法进行了改进,使用了神经网络(结构可以自行设计)对acti-CSDN博客(4)基于策略的强化学习方法之策略梯度(Policy Gradient)详解:基于策略的强化学习方法之策略梯度(Policy Gradient)详解-CSDN博客
一、理论基础
(一)强化学习与策略梯度方法概述
1. 强化学习基本框架
强化学习(Reinforcement Learning, RL)旨在解决智能体与环境交互过程中的序列决策问题。其核心要素包括:
(1)环境(Environment):用马尔可夫决策过程(MDP)建模,状态空间S,动作空间A,转移概率p(s′|s,a),奖励函数r(s,a,s′)。马尔可夫决策过程(MDP)示例图:
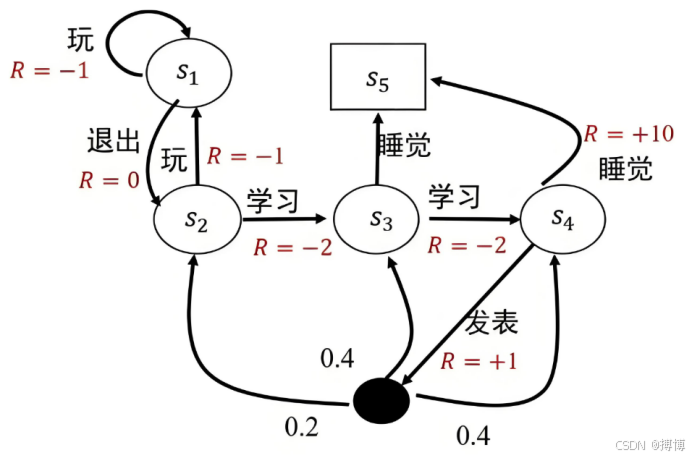
(2)智能体(Agent):通过策略π(a|s)选择动作,目标是最大化长期累积奖励的期望,即回报![]() 的期望,其中γ∈[0,1]为折扣因子。
的期望,其中γ∈[0,1]为折扣因子。
回报公式说明:回报是智能体从时刻t开始的未来累积奖励,通过折扣因子γ对远期奖励进行衰减,体现“即时奖励比远期奖励更重要”的特性。γ=0时仅考虑即时奖励,γ=1时等同蒙特卡洛回报(无折扣)。引入折扣因子可确保无限序列的期望收敛,便于数学处理。
(3)价值函数:状态价值函数![]() ,动作价值函数
,动作价值函数![]() 。
。
状态价值函数说明:表示在策略π下,从状态s出发的期望回报,是评估策略长期性能的核心指标。满足贝尔曼方程:![]() ,体现递归性质。
,体现递归性质。
动作价值函数说明:表示在策略π下,从状态s执行动作a后的期望回报,用于比较不同动作的优劣。与状态价值函数的关系:![]() ,即状态价值是动作价值的策略期望。
,即状态价值是动作价值的策略期望。
以下是强化学习核心三要素之间的关系:
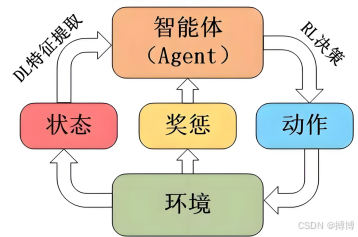
强化学习基本框架如下:
2. 策略梯度方法核心思想
策略梯度方法直接对策略进行参数化(θ为参数),通过优化目标函数提升策略性能。常见目标函数
包括:
(1)初始价值(Start Value):![]() ,对应从初始状态出发的期望回报。
,对应从初始状态出发的期望回报。
(2)平均价值(Average Value):![]() ,其中
,其中为策略π下的状态分布。
(3)平均奖励(Average Reward):![]() ,适用于无限horizon问题。
,适用于无限horizon问题。
策略梯度定理表明,在参数θ下的目标函数的梯度可表示为:
![]()
该公式揭示了策略优化的本质:通过提升高价值动作的选择概率,降低低价值动作的选择概率。
(二)近端策略优化(PPO)的提出背景
1. 传统策略梯度方法的局限性
(1)高方差问题:直接使用θ参数下的动作价值函数作为优势估计会引入较大方差,通常用优势函数
![]() 替代,以减少基线(Baseline)以上的波动。
替代,以减少基线(Baseline)以上的波动。
(2)样本效率低:策略更新后需重新收集数据,导致离线策略(Off-Policy)方法难以直接应用。
2. 信任区域策略优化(TRPO)的改进与不足
TRPO 通过引入信任区域(Trust Region)约束,确保策略更新不会导致性能大幅下降。其优化目标为:
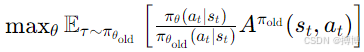
约束条件为:
![]()
TRPO通过共轭梯度法求解带约束的优化问题,保证了单调改进,但计算复杂度高(需计算Hessian矩阵),工程实现难度大。
3. PPO的核心创新
PPO通过近端策略优化目标函数和截断技巧(Clipping Trick)替代TRPO的信任区域约束,既保持了策略更新的稳定性,又显著降低了计算成本。其核心思想是:在策略更新时,限制新旧策略的概率比值在合理范围内,避免过大的策略变化。
二、数学基础
(一)策略梯度与重要性采样
先对公式关联关系进行说明:
(1)策略梯度定理是所有策略优化方法的基石,引出了优势函数的核心作用。
(2)重要性采样使离线策略优化成为可能,是PPO复用旧样本的理论基础。
(3)GAE通过加权求和优化优势估计,提升了策略梯度的估计精度,直接影响PPO目标函数的有效性。
(4)TRPO的信任区域思想通过PPO的截断技巧近似实现,平衡了优化效率与稳定性。
(5)梯度裁剪、归一化从数学层面解决了优化过程中的数值稳定性问题,确保理论公式在实际训练中有效落地。
1. 策略梯度推导
目标函数:
![]()
梯度推导:
(1)对目标函数求导,利用期望的线性性质和链式法则:
![]()
其中,表示轨迹,
是策略的对数概率,其梯度指示策略参数变化对动作概率的影响方向。
(2)引入价值函数作为基线(Baseline),消去常数项以减少方差
![]()
其中,![]() 为差分误差(TD Error),等价于优势函数
为差分误差(TD Error),等价于优势函数。
(3)代入后化简得策略梯度定理,因此,在θ参数下的策略梯度可简化为:
![]()
物理意义:策略梯度是优势函数与策略对数梯度的期望,表明应增加高优势动作的概率,降低低优势动作的概率。
2. 重要性采样(Importance Sampling)
在离线策略优化中,利用旧策略收集的数据训练新策略
,需通过重要性采样权重校正分布差异:
![]()
重要性采样权重的说明:用于离线策略优化,校正旧策略
与新策略
的分布差异。权重是轨迹中各动作概率比值的累积乘积,反映新旧策略生成该轨迹的相对概率。
则离线策略梯度可表示为:
![]()
通过重要性采样,可利用旧策略收集的数据优化新策略,避免频繁交互环境,提升样本效率。但权重可能导致高方差,需通过优势函数归一化或截断技巧缓解。
(二)优势函数估计与广义优势估计(GAE)
1. 优势函数的作用
优势函数表示动作a在状态s下相对于平均动作的优劣,其估计精度直接影响策略更新的稳定性。若直接使用蒙特卡洛回报
作为优势估计,方差较高;若使用TD误差
,偏差较高。
2. 广义优势估计(GAE)
GAE通过引入参数λ∈[0,1]平衡偏差与方差,其递归公式为:
![]()
其中,![]() 。表示当前状态价值估计与下一状态价值估计的差异,是单步引导(Bootstrapping)的结果。低方差但有偏差(依赖价值函数估计精度)。当λ=0时,退化为TD误差,等价于单步优势估计(低方差,高偏差);当λ=1时,等价于蒙特卡洛优势估计(无偏差,高方差),通常取λ∈[0.9, 0.99]平衡偏差与方差。将GAE递归公式展开,等价于加权求和,因此,GAE的优势估计可表示为:
。表示当前状态价值估计与下一状态价值估计的差异,是单步引导(Bootstrapping)的结果。低方差但有偏差(依赖价值函数估计精度)。当λ=0时,退化为TD误差,等价于单步优势估计(低方差,高偏差);当λ=1时,等价于蒙特卡洛优势估计(无偏差,高方差),通常取λ∈[0.9, 0.99]平衡偏差与方差。将GAE递归公式展开,等价于加权求和,因此,GAE的优势估计可表示为:
![]()
该估计具有较低的方差和较好的计算效率,是PPO的关键技术之一。
补充:蒙特卡洛优势:
![]()
直接使用实际回报减去状态价值,无偏差但方差高(需完整轨迹)。
(三)PPO目标函数推导
1. 原始目标函数与截断思想
PPO的优化目标基于重要性采样的策略梯度,结合截断技巧防止策略更新幅度过大。定义概率比值:
![]()
概率比值用于衡量新旧策略在相同状态下选择相同动作的概率变化,表示新策略更倾向于该动作,反之则更抑制。
则截断目标函数为:
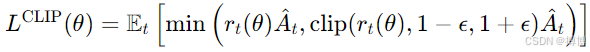
其中,clip(·,l,u)为截断函数,将概率比值限制在[1−ϵ,1+ϵ]范围内。截断目标函数的推导逻辑:
(1)当优势函数时(高价值动作),鼓励
增大以提升动作概率,但不超过1+ϵ,避免过度偏离旧策略;
(2)当时(低价值动作),限制
减小以降低动作概率,但不低于1−ϵ,从而避免策略更新过于激进;
(3)clip函数形成 “安全区间”,确保策略更新在旧策略的“近端”范围内,类似TRPO的信任区域约束。
2. 包含价值函数的联合优化目标
为同时优化价值函数,PPO引入价值损失,并通过熵正则项
增强探索性,最终联合目标函数为:
![]()
其中,各分量作用:
(1):策略优化的核心项,平衡性能提升与稳定性。
(2):价值损失通常采用均方误差(MSE),提升优势估计精度(优势估计为:
![]() ):
):
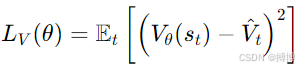
为目标价值,可通过GAE计算的回报
![]() 得到。
得到。
(3)熵正则项![]() ,鼓励策略探索,用于防止策略过早收敛到确定性策略。
,鼓励策略探索,用于防止策略过早收敛到确定性策略。
3. PPO与TRPO的理论关联
TRPO通过KL散度约束确保策略更新在信任区域内,而PPO通过截断概率比值间接实现类似约束。理论上,当ϵ较小时,PPO的截断操作近似于TRPO的信任区域约束,但计算复杂度显著降低。
(1)TRPO约束条件:
![]()
解析:通过KL散度约束新旧策略的分布差异,确保策略更新在“信任区域”内,理论上保证性能单调提升。需计算二阶导数(Hessian 矩阵),计算复杂度高。
(2)PPO的近似性:当ϵ较小时,截断操作近似于KL散度约束。例如,若![]() ,则对数概率差异
,则对数概率差异![]() ,根据泰勒展开:
,根据泰勒展开:
![]()
即ϵ间接控制了KL散度的上界,实现与TRPO类似的稳定性保证,但无需显式计算KL散度。
三、网络结构
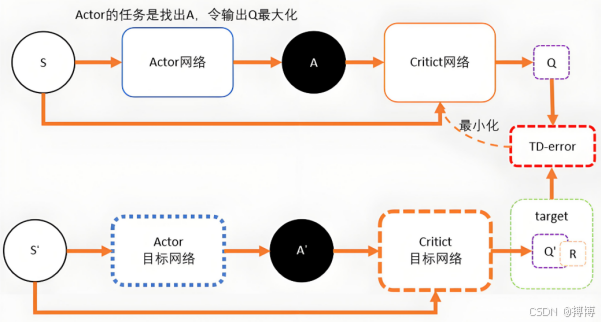
(一)Actor-Critic 架构
1. 网络组成
PPO采用Actor-Critic架构(策略+价值学习),包含两个神经网络:
(1)Actor策略网络:输入状态s,输出动作概率分布,对于离散动作空间通常使用Softmax层,连续空间则使用高斯分布(输出均值和标准差)。
(2)Critic价值网络:输入状态s,输出价值估计,通常为全连接网络,输出标量值。
2. 共享特征提取层
为提高样本效率,Actor和Critic网络通常共享前几层卷积层(图像输入)或全连接层(状态为向量时),仅在输出层分支为策略输出和价值输出。例如,对于Atari游戏,共享卷积层提取视觉特征,Actor输出各动作概率,Critic输出价值估计。
(二)执行流程图
PPO执行流程:
初始化策略网络π_old和π_new,价值网络V,优化器
for 每个训练周期:
1. 数据收集阶段:
用π_old与环境交互,收集轨迹D = {(s_t, a_t, r_t, s_{t+1})}
计算优势估计Â_t和目标价值Ŕ_t(使用GAE)
2. 策略更新阶段:
将D输入π_new,计算概率比值r_t = π_new(a_t|s_t)/π_old(a_t|s_t)
计算截断目标函数L_CLIP = min(r_t*Â_t, clip(r_t, 1-ε, 1+ε)*Â_t)
计算熵损失L_ent = -E[log π_new(a_t|s_t)]
总策略损失L_pi = -E[L_CLIP + c2*L_ent]
反向传播更新π_new参数
重复K次更新(通常K=3-10)
3. 价值网络更新阶段:
计算价值损失L_v = MSE(V(s_t), Ŕ_t)
反向传播更新V参数
4. 同步策略网络:
π_old = π_new
end for
(三)关键组件细节
1. 经验回放与批量处理
PPO通常不使用大规模经验回放缓冲区(因策略更新需保证数据来自相近策略),而是将每个周期收集的轨迹分割为多个小批量(Mini-Batch),在每个小批量上进行多次更新,以模拟SGD的效果,减少内存占用。
2. 优势归一化
为稳定训练,通常对优势估计进行归一化处理,使其均值为0,标准差为1:
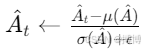
其中ϵ为极小值防止除零。
3. 动作空间处理
(1)离散动作空间:Actor网络输出各动作的logits,经Softmax得到概率分布,采样时根据概率选择动作。
(2)连续动作空间:Actor网络输出动作均值μ和对数标准差,动作通过
采样,其中
。
四、工程化实现技术
(一)优化技巧
1. 梯度裁剪(Gradient Clipping)
为防止梯度爆炸,对策略梯度和价值梯度进行范数裁剪:
![]()
前者为值裁剪,后者为范数裁剪,实际中范数裁剪更常用。
解析:将梯度范数限制在c以内,防止梯度爆炸(如||g||过大时,梯度方向不变但幅值缩放)。数学上保证优化过程的稳定性,避免参数更新步长过大导致振荡。
优势归一化:
![]()
解析:将优势估计标准化为均值 0、标准差1的分布,避免不同批次数据的尺度差异影响训练。减少梯度方差,加速收敛,尤其在多环境并行训练时效果显著。
2. 学习率衰减
采用线性衰减或指数衰减学习率,提升训练后期的稳定性。例如,线性衰减公式为:
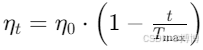
其中t为当前训练步数,为总步数。
3. 参数初始化
使用正交初始化(Orthogonal Initialization)对网络权重进行初始化,激活函数通常选择 ReLU或Tanh。例如,Actor网络的输出层权重初始化为0.01,以避免初始策略过于确定。
(二)并行训练与样本效率提升
1. 向量化环境(Vectorized Environment)
通过并行运行多个环境实例(如使用SubprocVecEnv),同时收集多条轨迹,减少CPU空闲时间。例如,在Python中使用gym.vector库创建向量化环境:
python代码:
from gym.vector import SyncVectorEnv
env = SyncVectorEnv([lambda: gym.make("CartPole-v1") for _ in range(8)])2. 异步策略更新(Asynchronous Update)
在分布式架构中,多个工作节点(Worker)并行收集数据,参数服务器(Parameter Server)汇总梯度并更新全局模型。该方法可显著提升样本采集速度,但需注意策略过时(Staleness)问题。
(三)部署与泛化能力增强
1. 环境归一化
对状态输入进行归一化处理,如减去均值、除以标准差,可提升模型泛化能力。通常维护一个运行均值和方差,在训练过程中动态更新:
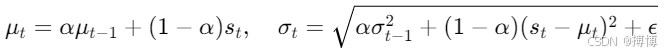
2. 多任务学习与迁移学习
通过预训练模型在相似任务上的参数,初始化目标任务的网络,可加速收敛。例如,在机器人控制中,先在仿真环境中训练PPO模型,再通过域随机化(Domain Randomization)迁移到真实环境。
五、Python 完整示例(以 CartPole 为例)
(一)环境配置与依赖安装
python代码:
import gymimport torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
import numpy as np
# 超参数
LR = 3e-4
GAMMA = 0.99
EPS_CLIP = 0.2
K_EPOCHS = 4
UPDATE_INTERVAL = 2000
ENTROPY_COEF = 0.01
VALUE_COEF = 0.5(二)Actor-Critic网络定义
python代码:
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim):
super(ActorCritic, self).__init__()
self.common = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU()
)
self.actor = nn.Linear(64, action_dim)
self.critic = nn.Linear(64, 1)
def forward(self, state):
x = self.common(state)
action_logits = self.actor(x)
value = self.critic(x)
return action_logits, value
def act(self, state):
state = torch.from_numpy(state).float().unsqueeze(0)
action_logits, _ = self.forward(state)
dist = Categorical(logits=action_logits)
action = dist.sample()
return action.item(), dist.log_prob(action)(三)PPO算法实现
python代码:
class PPO:
def __init__(self, state_dim, action_dim):
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.policy = ActorCritic(state_dim, action_dim).to(self.device)
self.optimizer = optim.Adam(self.policy.parameters(), lr=LR)
self.MseLoss = nn.MSELoss()
def select_action(self, state):
with torch.no_grad():
action, log_prob = self.policy.act(state)
return action, log_prob
def update(self, transitions):
states, actions, log_probs_old, rewards, next_states, dones = zip(*transitions)
# 预计算优势函数和目标价值,避免在训练循环中重复计算
states_tensor = torch.FloatTensor(states).to(self.device)
next_states_tensor = torch.FloatTensor(next_states).to(self.device)
# 计算优势函数和目标价值(使用GAE)
with torch.no_grad():
values = self.policy.forward(states_tensor)[1].squeeze()
next_values = self.policy.forward(next_states_tensor)[1].squeeze()
rewards_tensor = torch.FloatTensor(rewards).to(self.device)
dones_tensor = torch.FloatTensor(dones).to(self.device)
deltas = rewards_tensor + GAMMA * next_values * (1 - dones_tensor) - values
advantages = self.gae(deltas, values, next_values, dones_tensor)
returns = values + advantages
# 标准化优势函数
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
# 将数据转换为张量并移动到设备
actions_tensor = torch.LongTensor(actions).to(self.device)
log_probs_old_tensor = torch.FloatTensor(log_probs_old).to(self.device)
# PPO更新 - 每次迭代重新计算损失
for _ in range(K_EPOCHS):
# 重新计算当前策略下的动作概率和价值估计
action_logits, values_pred = self.policy.forward(states_tensor)
dist = Categorical(logits=action_logits)
log_probs = dist.log_prob(actions_tensor)
entropy = dist.entropy().mean()
# 计算概率比值和截断目标
ratios = torch.exp(log_probs - log_probs_old_tensor)
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1-EPS_CLIP, 1+EPS_CLIP) * advantages
policy_loss = -torch.min(surr1, surr2).mean()
value_loss = self.MseLoss(values_pred.squeeze(), returns)
total_loss = policy_loss + VALUE_COEF * value_loss - ENTROPY_COEF * entropy
self.optimizer.zero_grad()
total_loss.backward()
nn.utils.clip_grad_norm_(self.policy.parameters(), 0.5) # 梯度裁剪
self.optimizer.step()
def gae(self, deltas, values, next_values, dones):
advantages = torch.zeros_like(deltas)
running_advantage = 0
for t in reversed(range(len(deltas))):
running_advantage = deltas[t] + GAMMA * 0.95 * running_advantage * (1 - dones[t])
advantages[t] = running_advantage
return advantages(四)训练与测试流程
python代码:
def train():
env = gym.make("CartPole-v1")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
ppo = PPO(state_dim, action_dim)
print("开始训练...")
running_reward = 0
transitions = []
for step in range(1, 1000001):
state, _ = env.reset()
episode_reward = 0
while True:
action, log_prob = ppo.select_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated # 合并终止和截断标志
transitions.append((state, action, log_prob, reward, next_state, done))
episode_reward += reward
state = next_state
if len(transitions) >= UPDATE_INTERVAL or done:
ppo.update(transitions)
transitions = []
if done:
running_reward = 0.99 * running_reward + 0.01 * episode_reward if running_reward != 0 else episode_reward
print(f"Step: {step}, Reward: {episode_reward:.2f}, Running Reward: {running_reward:.2f}")
break
# 训练完成后保存模型
torch.save(ppo.policy.state_dict(), "ppo_cartpole.pth") # 修改:使用实例变量ppo
env.close()
return ppo # 返回训练好的模型实例
def test():
env = gym.make("CartPole-v1", render_mode="human")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
ppo = PPO(state_dim, action_dim)
ppo.policy.load_state_dict(torch.load("ppo_cartpole.pth"))
state, _ = env.reset()
while True:
action, _ = ppo.select_action(state)
state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
env.render()
if done:
break
env.close()
if __name__ == "__main__":
trained_ppo = train() # 保存训练好的模型实例
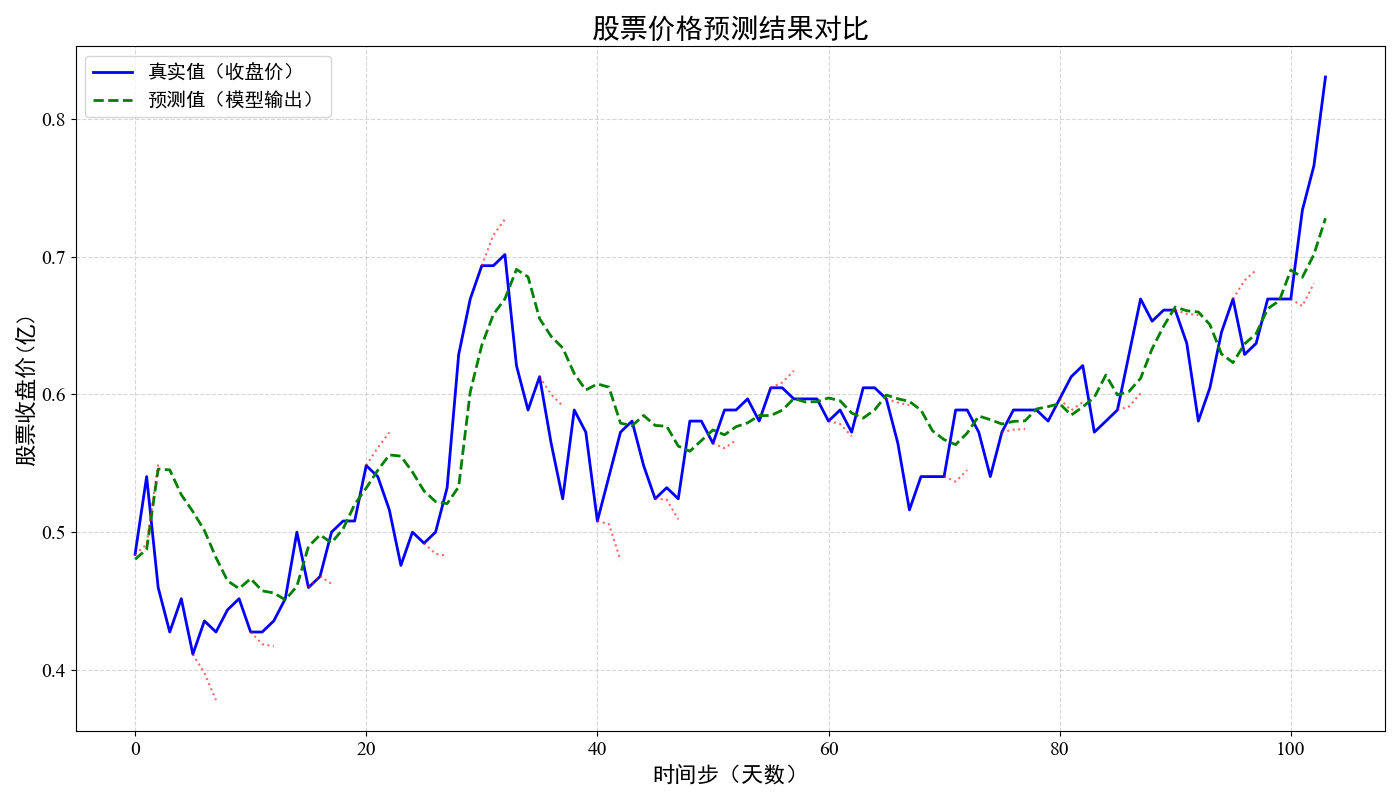
test()要执行的步骤次数在train()函数中修改,当前默认是1000000次,会很久。训练过程如下:
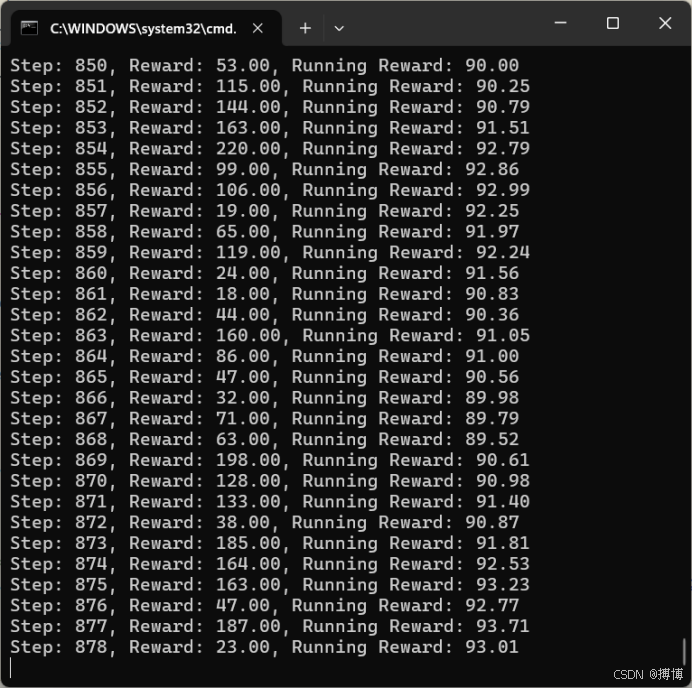
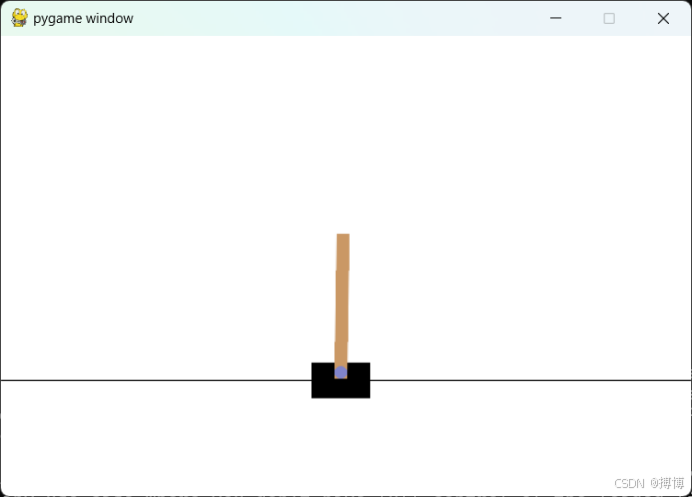
效果如下:
六、总结与扩展
(一)PPO的优缺点分析
1.优点:
(1)稳定性强:通过截断技巧有效控制策略更新幅度,避免性能骤降。
(2)样本效率高:支持离线策略优化,可重复利用旧样本。
(3)工程友好:无需复杂的二阶导数计算,易于实现和调试。
2.缺点:
(1)超参数敏感:ϵ、K_EPOCHS等参数需仔细调整。
(2)连续动作空间处理:需额外设计动作分布(如高斯分布),收敛速度可能慢于离散空间。
(二)扩展方向
1. 连续动作空间优化
对于机器人控制等连续动作场景,可将Actor网络改为输出高斯分布的均值和标准差,并使用Tanh激活函数限制动作范围。此时,概率比值计算需考虑动作空间的雅可比行列式(Jacobian Determinant)。
2. 多智能体强化学习
将PPO扩展至多智能体场景(如MADDPG),需引入全局状态或联合动作空间,并设计通信机制或集中式评论家(Centralized Critic)。
3. 与模仿学习结合
通过逆强化学习(IRL)从专家数据中学习奖励函数,结合PPO进行策略优化,可提升在复杂环境中的表现。
(三)理论延伸:PPO 的收敛性分析
尽管 PPO未严格证明全局收敛性,但其通过截断操作保证了每次更新的单调改进(在理想情况下)。研究表明,当学习率足够小且截断参数ϵ适当,PPO可收敛到局部最优策略,其性能接近TRPO但计算成本更低。
全文总结:
PPO通过理论创新(截断目标函数)和工程优化(梯度裁剪、批量更新),成为当前最流行的策略梯度方法之一。其数学基础融合了策略梯度、重要性采样和信任区域思想,网络结构基于Actor-Critic架构,工程实现中通过多种技巧提升稳定性和样本效率。通过上述深度解析,读者可全面掌握PPO的核心原理与实践方法,并能根据具体场景进行扩展应用。

![【问题】Watt加速github访问速度:好用[特殊字符]](https://i-blog.csdnimg.cn/direct/f495eb5554a74537ae6a9879676c1f99.png)

![[训练和优化] 3. 模型优化](https://i-blog.csdnimg.cn/blog_migrate/tags/671f42ab07fd990f949a1c903140dd83.png#pic_center)