文章目录
- 案例介绍
- 源码地址
- 代码实现
- 导入相关库
- 数据获取和处理
- 搭建LSTM模型
- 训练模型
- 测试模型
- 绘制折线图
- 主函数
- 绘制结果
案例介绍
- 本例使用长短期记忆网络模型对上海证券交易所工商银行的股票成交量做一个趋势预测,这样可以更好地掌握股票买卖点,从而提高自己的收益率。
源码地址
- stock_prediction
代码实现
导入相关库
import os
import pandas as pd
import torch # 导入PyTorch库
import torch.nn as nn # 导入神经网络模块
import torch.optim as optim # 导入优化器模块
from tqdm import tqdm # 导入tqdm库,用于显示进度条
import matplotlib.pyplot as plt # 导入matplotlib库,用于绘制图表
from copy import deepcopy as copy # 导入deepcopy函数,用于深拷贝对象
from torch.utils.data import DataLoader, TensorDataset # 导入DataLoader和TensorDataset类,用于加载数据
数据获取和处理
data.csv文件中包括开盘价,收盘价,最高价,最低价,成交量5个数据特征,使用每天的收盘价作为学习目标,每个样本都包含连续几天的数据作为一个序列样本,然后,将数据划分为训练集和测试集供后续使用。- GetData类用于获取和处理数据,它具有以下方法:
init(self, stock_id,save_path):初始化方法,接受股票ID和数据保存路径作为参数,并将它们存储在实例变量中。getData(self):获取数据的方法,获取股票历史数据并进行处理,然后保存到文件中。返回处理后的数据。process_data(self,n):处理数据的方法,将数据分为特征和标签,并划分为训练集和测试集。接受滑动窗口大小n作为参数。如果数据为空,则调用getData方法获取数据。返回训练集的特征、测试集的特征、训练集的标签和测试集的标签。
# 获取数据
class GetData:
def __init__(self, stock_id, save_path):
"""
初始化方法
:param stock_id: 股票id
:param save_path: 数据保存路径
"""
self.min_value = None
self.max_value = None
self.stock_id = stock_id
self.save_path = save_path
self.data = None
def getData(self):
"""
获取数据
数据处理并保存
:return: None
"""
"""
# 获取股票数据
self.data = ts.get_hist_data(self.stock_id).iloc[::-1]
# 选取特定列作为数据
self.data = self.data[["open", "close", "high", "low", "volume"]]
# 计算数据列的最大值和最小值
self.max_value = self.data['volume'].max()
self.min_value = self.data['volume'].min()
# 归一化处理
self.data = self.data.apply(lambda x: (x - min(x)) / (max(x) - min(x)))
# 保存数据
self.data.to_csv(self.save_path)
return self.data
"""
# 本地数据data.csv由于是归一化后的数据,所以最大值和最小值并不准确,所以运行结果会有误差,重在体验整个项目的逻辑即可
columns = ['open', 'close', 'high', 'low', 'volume']
self.data = pd.read_csv(self.save_path, names=columns, header=0)
# 计算数据列的最大值和最小值
self.max_value = self.data['volume'].max()
self.min_value = self.data['volume'].min()
return self.data
def process_data(self, n):
"""
处理数据
:param n: 滑动窗口大小
:return: 训练集的特征、测试集的特征、训练集的标签、测试集的标签
"""
if self.data is None:
self.getData()
# 提取特征和标签数据
"""
iloc 是 Pandas 库中用于按位置索引选取数据的方法
"""
feature = [
self.data.iloc[i: i + n].values.tolist()
for i in range(len(self.data) - n + 2)
if i + n < len(self.data)
]
label = [
self.data.close.values[i + n]
for i in range(len(self.data) - n + 2)
if i + n < len(self.data)
]
# 划分训练集和数据集
train_x = feature[:500]
test_x = feature[500:]
train_y = label[:500]
test_y = label[500:]
return train_x, test_x, train_y, test_y
搭建LSTM模型
- 定义一个Model的神经网络模块,包含一个LSTM层和线性层,在初始化方法中接受一个参数
n,并创建一个LSTM层和一个线性层。 - 在前向传播方法中,通过LSTM层处理输入x得到输出
lstm_output和隐藏状态hidden_state, cell_state,然后通过线性处理num_layers得到最终输出final_output ,最终返回final_output `作为模型的输出。
# 搭建LSTM模型: 单层单向LSTM网络+全连接层输出
class Model(nn.Module):
def __init__(self, n):
# 初始化方法
super(Model, self).__init__() # 调用父类的初始化方法
# 定义LSTM层 输入大小为n, 隐藏层大小为256,批次优先为True
self.lstm_layer = nn.LSTM(input_size=n, hidden_size=256, batch_first=True)
# 定义全连接层 输入特征数为256, 输出特征数为1 有偏差
self.linear_layer = nn.Linear(in_features=256, out_features=1, bias=True)
# 向前传播方法
def forward(self, x):
"""
x: 输入数据(通常是时间序列的特征)
lstm_output: LSTM 层的输出序列
hidden_state: LSTM 的隐藏状态(用于传递长期记忆)
cell_state: LSTM 的细胞状态(仅在 LSTM 中存在)
final_output: 经过全连接层后的最终输出
"""
# LSTM 层的前向传播,得到输出和隐藏状态
lstm_output, (hidden_state, cell_state) = self.lstm_layer(x)
# 获取隐藏状态的维度:batch_size, num_layers, hidden_size
batch_size, num_layers, hidden_size = hidden_state.shape
# 将隐藏状态输入全连接层,需要先展平为二维
final_output = self.linear_layer(hidden_state.view(batch_size * num_layers, hidden_size))
return final_output
训练模型
- 模型训练包括训练,测试,损失计算和模型保存等功能。
# 训练模型
def train_model(epoch, train_dataloader, test_dataloader, optimizer, early_stop, model):
"""
训练模型的函数
:param model: 模型
:param early_stop: 提前停止的轮数
:param optimizer: 优化器
:param epoch: 训练轮次
:param train_dataloader: 训练数据加载器
:param test_dataloader: 测试数据加载器
:return:
"""
best_model = None # 用于保存最佳模型
train_loss = 0 # 训练损失
test_loss = 0 # 测试损失
best_loss = 100 # 最佳损失
epoch_cnt = 0 # 训练轮次计数器
for i in range(epoch):
total_train_loss = 0 # 训练总损失
total_train_num = 0 # 训练总样本数
total_test_loss = 0 # 测试总损失
total_test_num = 0 # 测试总样本数
for x, y in tqdm(train_dataloader, desc=f"Epoch:{i} | Train Loss:{train_loss} | Test Loss:{test_loss}"):
x_num = len(x) # 当前批次样本数
p = model(x) # 模型预测 ✅ 使用 model(x),而不是 Model(x)
loss = loss_func(p, y) # 计算损失
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_train_loss += loss.item() # 训练损失累加
total_train_num += x_num # 训练样本数累加
# 计算训练损失
train_loss = total_train_loss / total_train_num
for x, y in test_dataloader:
x_num = len(x) # 当前批次样本数
p = model(x) # 模型预测 ✅ 使用 model(x),而不是 Model(x)
loss = loss_func(p, y) # 计算损失
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_test_loss += loss.item() # 测试损失累加
total_test_num += x_num # 测试样本数累加
test_loss = total_test_loss / total_test_num
# 如果当前测试损失小于最佳损失,则更新最佳模型和轮次计数器 否则 轮次计数器加1
if test_loss < best_loss:
best_loss = test_loss
best_model = copy(model) # ✅ 使用 copy(model),而不是 copy(Model
torch.save(best_model.state_dict(), './best_model.pth')
epoch_cnt = 0
else:
epoch_cnt += 1
if epoch_cnt > early_stop:
break
测试模型
- 在代码中定义一个名为test_model的函数,用于测试模型并返回预测值、真实标签以及测试损失,函数接收一个名为test_dataLoader_的DataLoader参数,其中包含测试数据。
- 在函数内部,首先创建了空的预测值列表pred和真实标签列表label。然后创建了一个模型对象model_f,加载了预先保存的模型状态字典
./best_model.pth,并将模型设置为评估模式。 - 接着,通过遍历
test_dataLoader中的数据进行预测。对每个数据样本x,模型预测p,计算损失
值并累加到total_test_loss中。同时,将预测值和真实标签分别添加到pred和label列表中。 - 最后,计算平均测试损失test_loss,并将预测值列表pred、真实标签列表label和测试损失test_loss作为结果返回。
def test_model(test_dataloader):
"""
测试模型,并返回预测值、真实标签和测试损失
:param test_dataloader: 测试数据加载器
:return: pred,label,test_loss
"""
pred = [] # 预测值列表
label = [] # 真实标签列表
model_f = Model(5) # 创建模型对象
model_f.load_state_dict(torch.load('./best_model.pth')) # 加载最佳模型
model_f.eval() # 设置模型为评估模式
total_test_loss = 0
total_test_num = 0
for x, y in test_dataloader:
x_num = len(x)
p = model_f(x) # ✅ 使用 model_f(x)
loss = loss_func(p, y)
total_test_loss += loss.item()
total_test_num += x_num
# 将预测值和真实标签添加到列表中
pred.extend(p.data.squeeze(1).tolist())
label.extend(y.data.tolist())
# 获取预测值和真实标签
test_loss = total_test_loss / total_test_num
return pred, label, test_loss
绘制折线图
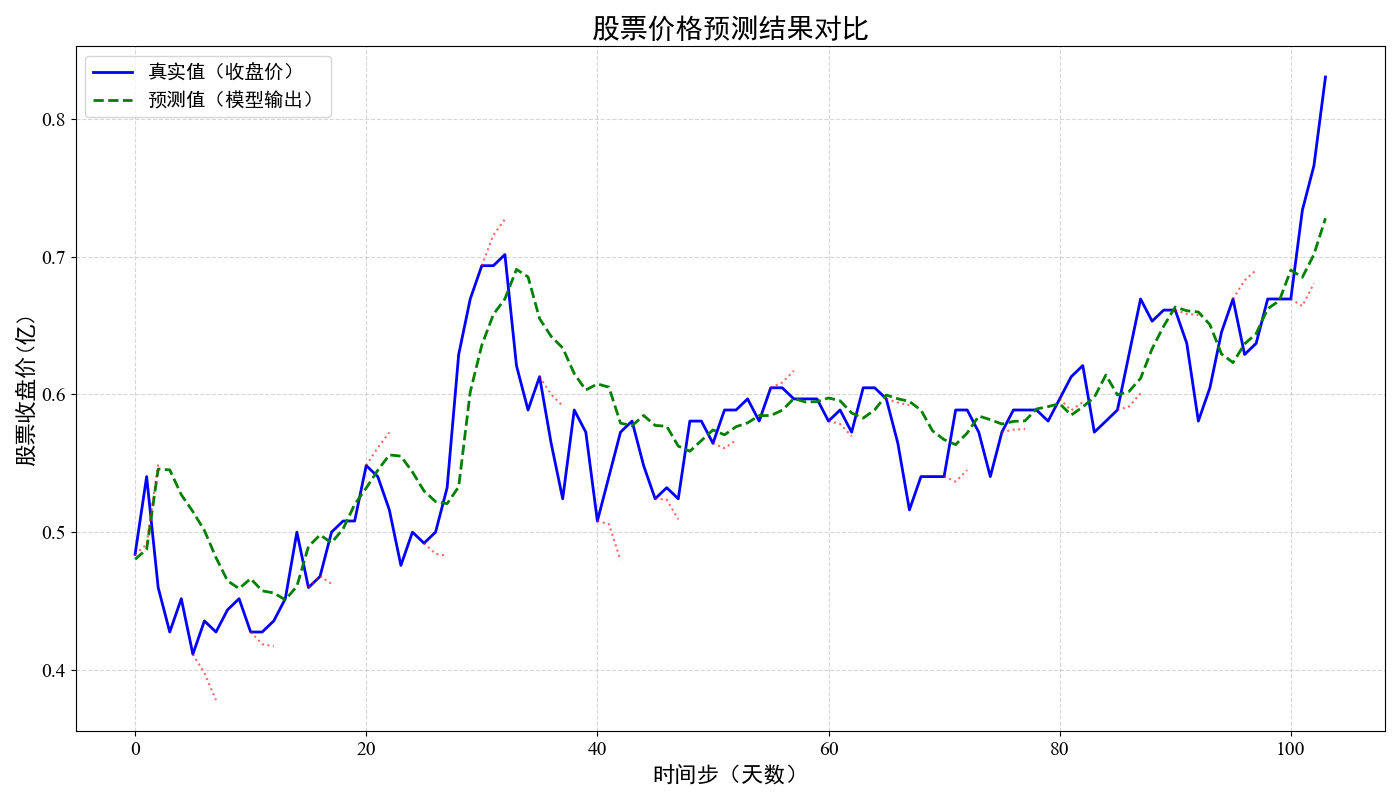
- 绘制股票日成交量的折线图,并输出模型测试集的损失。
def plot_img(data, pred):
"""
绘制真实值与预测值对比图
:param data: 真实标签列表
:param pred: 模型预测值列表
:return:
"""
# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.figure(figsize=(14, 8))
# 绘制真实值曲线
plt.plot(range(len(data)), data, color='blue', label='真实值(收盘价)', linewidth=2)
# 绘制预测值曲线
plt.plot(range(len(pred)), pred, color='green', label='预测值(模型输出)', linestyle='--', linewidth=2)
# 添加预测区间(每5个点绘制一个3天的预测区间)
for i in range(0, len(pred) - 3, 5):
price = [data[i] + pred[j] - pred[i] for j in range(i, i + 3)]
plt.plot(range(i, i + 3), price, color='red', alpha=0.6, linestyle=':', linewidth=1.5)
# 设置标题和标签
plt.title('股票价格预测结果对比', fontsize=20)
plt.xlabel('时间步(天数)', fontsize=16)
plt.ylabel('股票收盘价(亿)', fontsize=16)
# 设置刻度字体
plt.xticks(fontproperties='Times New Roman', size=14)
plt.yticks(fontproperties='Times New Roman', size=14)
# 显示图例
plt.legend(loc='upper left', fontsize=14)
# 显示网格
plt.grid(True, linestyle='--', alpha=0.5)
# 展示图形
plt.tight_layout()
plt.show()
主函数
-
初始化设置
- 定义超参数(训练轮次、批次大小等)。
- 创建模型和数据加载对象,指定股票ID和数据保存路径。
-
数据处理
- 获取股票数据,按时间窗口(5天)生成输入序列和标签。
- 将数据转换为PyTorch张量,并分批次加载(
batch_size=20)。
-
模型训练
- 使用均方误差损失和Adam优化器训练模型。
- 监控验证损失,若连续5轮无改进则提前停止,保存最佳模型。
-
模型测试
- 加载保存的最佳模型,在测试集上预测并计算损失。
- 将预测值和真实值反归一化,还原为原始价格。
-
结果输出
- 绘制预测值与真实值的对比图。
- 打印测试集上的最终损失值。
- 设置参数 → 加载并预处理数据 → 训练模型(含早停) → 测试并还原预测结果 → 可视化输出。
if __name__ == '__main__':
# 超参数
days_num = 5 # 天数
epoch = 20 # 训练轮次
fea = 5 # 特征数量
batch_size = 20 # 批次大小
early_stop = 5 # 提前停止轮次
# 创建模型对象
model = Model(fea)
# 创建数据加载器
gd = GetData(stock_id='601398', save_path='./data.csv')
train_x, test_x, train_y, test_y = gd.process_data(days_num)
# 将数据转换为张量
train_x = torch.tensor(train_x).float()
test_x = torch.tensor(test_x).float()
train_y = torch.tensor(train_y).float()
test_y = torch.tensor(test_y).float()
# 构建训练数据集和测试数据集
train_data = TensorDataset(train_x, train_y)
train_dataloader = DataLoader(train_data, batch_size=batch_size)
test_data = TensorDataset(test_x, test_y)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
# 创建损失函数和优化器
loss_func = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
train_model(epoch, train_dataloader, test_dataloader, optimizer, early_stop, model)
# 只有模型存在时才进行测试
if os.path.exists('./best_model.pth'):
pred, label, test_loss = test_model(test_dataloader)
else:
print("模型文件不存在,请先完成训练并确保模型已保存。")
# 将预测值和真实标签转换为真实价格
pred = [ele * (gd.max_value - gd.min_value) + gd.min_value for ele in pred]
data = [ele * (gd.max_value - gd.min_value) + gd.min_value for ele in label]
# 绘制图像
plot_img(data, pred)
print(f"模型损失:{test_loss}")
绘制结果