权重的初始值
在神经网络的学习中,权重的初始值特别重要。实际上,设定什么样的权重初始值,经常关系到神经网络的学习能否成功。
不要将权重初始值设为 0
权值衰减(weight decay):抑制过拟合、提高泛化能力的技巧。
如果想减小权重的值,一开始就将初始值设为较小的值才是正途。
将权重初始值设为0的话,将无法正确进行学习。为什么呢?
在误差反向传播法中,所有的权重值都会进行相同的更新。比如,在2层神经网络中,假设第1层和第2层的权重为0。这样一来,正向传播时,因为输入层的权重为0,所以第2层的神经元全部会被传递相同的值。第2层的神经元中全部输入相同的值,这意味着反向传播时第2层的权重全部都会进行相同的更新。因此,权重被更新为相同的值,并拥有了对称的值(重复的值)。这使得神经网络拥有许多不同的权重的意义丧失了。为了防止“权重均一化”(瓦解权重的对称结构),必须随机生成初始值。
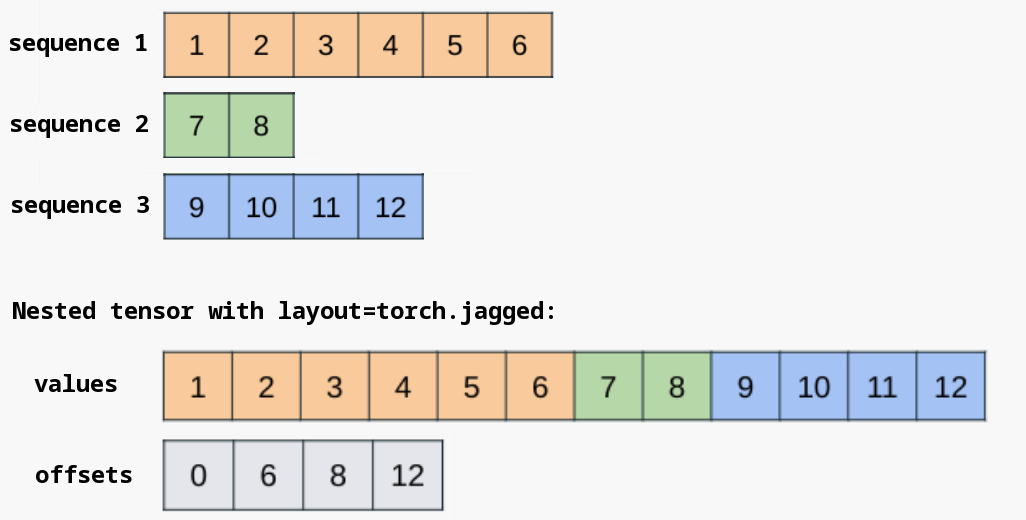
隐藏层的激活值的分布
向一个5层神经网络(激活函数使用sigmoid函数)传入随机生成的输入数据,用直方图绘制各层激活值的数据分布。
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
# 设置中文字体
rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def ReLU(x):
return np.maximum(0, x)
def tanh(x):
return np.tanh(x)
input_data = np.random.randn(1000, 100) # 1000个数据
node_num = 100 # 各隐藏层节点(神经元)数
hidden_layer_size = 5 # 隐藏的层有5层
activations = {} # 激活值的结果保存在这里
x = input_data
for i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
# 改变初始值进行实验!
w = np.random.randn(node_num, node_num) * 1
# w = np.random.randn(node_num, node_num) * 0.01
# w = np.random.randn(node_num, node_num) * np.sqrt(1.0 / node_num) # Xavier初始值,适用 sigmoid、tanh等S型曲线
# w = np.random.randn(node_num, node_num) * np.sqrt(2.0 / node_num) # He初始值,适用 ReLU
a = np.dot(x, w)
# 将激活函数的种类也改变,来进行实验!
z = sigmoid(a)
# z = ReLU(a)
# z = tanh(a)
activations[i] = z
# 绘制直方图
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1) + "-layer")
if i != 0: plt.yticks([], [])
# plt.xlim(0.1, 1)
# plt.ylim(0, 7000)
plt.hist(a.flatten(), 30, range=(0,1))
# plt.hist(a.flatten(), 30)
if i == 0:
plt.xlabel("标准差为1的高斯分布作为权重初始值时的sigmoid的各层激活值的分布", loc='left')
plt.show()

各层的激活值呈偏向0和1的分布。这里使用的sigmoid函数是S型函数,随着输出不断地靠近0(或者靠近1),它的导数的值逐渐接近0。因此,偏向0和1的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失(gradient vanishing)。层次加深的深度学习中,梯度消失的问题可能会更加严重。

集中在0.5附近的分布。没有偏向0和1,所以不会发生梯度消失的问题。但是,激活值的分布有所偏向,不同数量的神经元的输出几乎相同,说明在表现力上会有很大问题。因此,激活值在分布上有所偏向会出现“表现力受限”的问题。
各层的激活值的分布都要求有适当的广度。为什么呢?因为通过在各层间传递多样性的数据,神经网络可以进行高效的学习。反过来,如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行。
Xavier初始值
Xavier的论文中,为了使各层的激活值呈现出具有相同广度的分布,推导了合适的权重尺度。推导出的结论是,如果前一层的节点数为 n n n,则初始值使用标准差为的分布 1 n \frac{1}{\sqrt{n}} n1

越是后面的层,图像变得越歪斜,但是呈现了比之前更有广度的分布。因为各层间传递的数据有适当的广度,所以sigmoid函数的表现力不受限制,有望进行高效的学习。

使用tanh函数后,会呈漂亮的吊钟型分布。tanh函数和sigmoid函数同是 S型曲线函数,但tanh函数是关于原点(0, 0)对称的 S型曲线,而sigmoid函数是关于(x, y)=(0, 0.5)对称的S型曲线。
用作激活函数的函数最好具有关于原点对称的性质。
He初始值
Xavier初始值是以激活函数是线性函数为前提而推导出来的。因为sigmoid函数和tanh函数左右对称,且中央附近可以视作线性函数,所以适合使用Xavier初始值。
但当激活函数使用ReLU时,一般推荐使用ReLU专用的初始值,He初始值。
当前一层的节点数为 n n n时,He初始值使用标准差为 2 n \sqrt{\frac{2}{n}} n2 的高斯分布。当Xavier初始值是 1 n \sqrt{\frac{1}{n}} n1时,(直观上)可以解释为,因为ReLU的负值区域的值为0,为了使它更有广度,所以需要2倍的系数。

当“std = 0.01”时,各层的激活值非常小 。神经网络上传递的是非常小的值,说明逆向传播时权重的梯度也同样很小。这是很严重的问题,实际上学习基本上没有进展。

随着层的加深,偏向一点点变大。实际上,层加深后,激活值的偏向变大,学习时会出现梯度消失的问题。

各层中分布的广度相同。由于即便层加深,数据的广度也能保持不变,因此逆向传播时,也会传递合适的值。
当激活函数使用ReLU时,权重初始值使用He初始值,当激活函数为sigmoid或tanh等S型曲线函数时,初始值使用Xavier初始值。这是目前的最佳实践。

神经网络有5层,每层有100个神经元,激活函数使用的是ReLU。
从上图分析可知,std = 0.01时完全无法进行学习。这和刚才观察到的激活值的分布一样,是因为正向传播中传递的值很小(集中在0附近的数据)。因此,逆向传播时求到的梯度也很小,权重几乎不进行更新。相反,当权重初始值为Xavier初始值和He初始值时,学习进行得很顺利。并且,我们发现He初始值时的学习进度更快一些。
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import SGD
from matplotlib import rcParams
# 设置中文字体
rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 0:读入MNIST数据==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000
# 1:进行实验的设置==========
weight_init_types = {'std=0.01': 0.01, 'Xavier': 'sigmoid', 'He': 'relu'}
optimizer = SGD(lr=0.01)
networks = {}
train_loss = {}
for key, weight_type in weight_init_types.items():
networks[key] = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100],
output_size=10, weight_init_std=weight_type)
train_loss[key] = []
# 2:开始训练==========
for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for key in weight_init_types.keys():
grads = networks[key].gradient(x_batch, t_batch)
optimizer.update(networks[key].params, grads)
loss = networks[key].loss(x_batch, t_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print("===========" + "iteration:" + str(i) + "===========")
for key in weight_init_types.keys():
loss = networks[key].loss(x_batch, t_batch)
print(key + ":" + str(loss))
# 3.绘制图形==========
markers = {'std=0.01': 'o', 'Xavier': 's', 'He': 'D'}
x = np.arange(max_iterations)
for key in weight_init_types.keys():
plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("学习迭代次数")
plt.ylabel("损失函数值")
plt.title("基于MNIST数据集的权重初始值的比较")
plt.ylim(0, 2.5)
plt.legend()
plt.show()