文章目录
- 前言
- 1.数据预处理
- 1.1数据集介绍
- 1.2数据集抽取
- 1.3划分数据集
- 1.4数据清洗
- 1.5数据保存
- 2.样本的向量化表征
- 2.1词汇表
- 2.2向量化
- 2.3自定义数据集
- 2.4备注
- 结语
前言
本篇博客主要介绍自然语言处理领域中一个项目案例——文本分类,具体而言就是判断评价属于积极还是消极的模型,选用的模型属于最简单的单层感知机模型。
1.数据预处理
1.1数据集介绍
本项目数据集来源:2015年,Yelp 举办了一场竞赛,要求参与者根据点评预测一家餐厅的评级。该数据集分为 56 万个训练样本和3.8万个测试样本。共计两个类别,分别代表该评价属于积极还是消极。这里以训练集为例,进行介绍展示:
import pandas as pd
train_reviews=pd.read_csv('data/yelp/raw_train.csv',header=None,names=['rating','review'])
train_reviews,train_reviews.rating.value_counts()
运行结果:
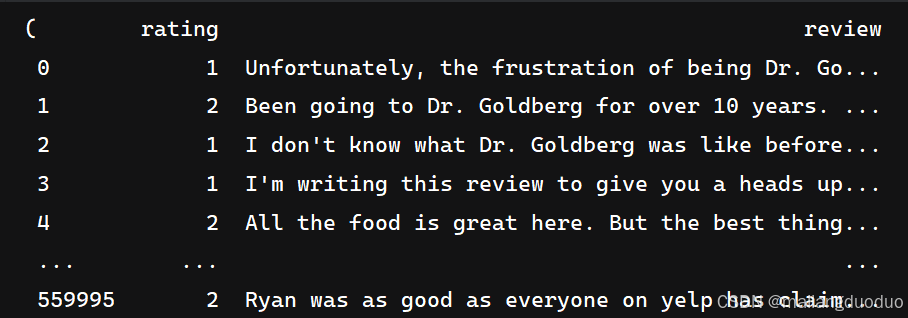
共计两个类别,同时类别数量相等,因此不需要进行类平衡操作。因为当前数据集过大,因此这里对数据集进行抽取。
1.2数据集抽取
首先,将两个类别的数据分别使用两个列表进行保存。代码如下:
import collections
by_rating = collections.defaultdict(list)
for _, row in train_reviews.iterrows():
by_rating[row.rating].append(row.to_dict())
运行查看:
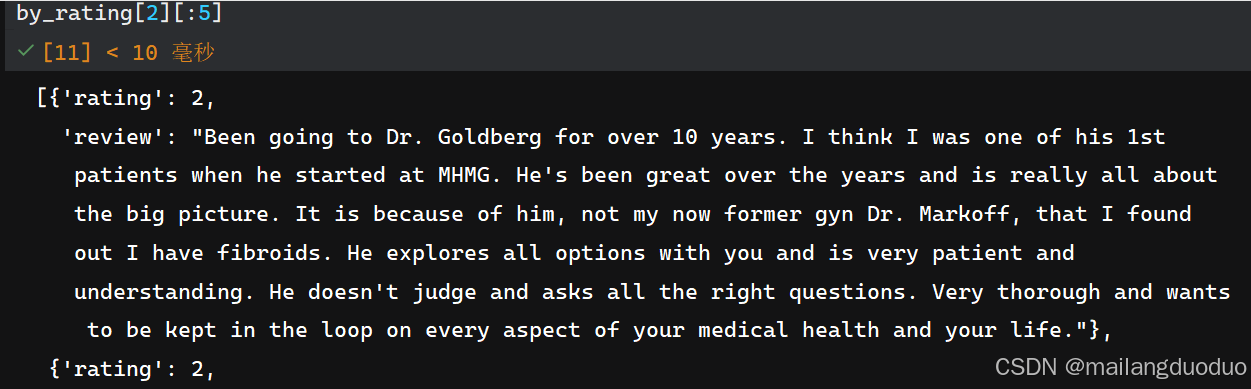
共计两个类别,分别存储在by_rating[1]和by_rating[2]对于的列表中。
接着选择合适的比例将数据从相应的类别中抽取出来,这里选择的比例为0.01,具体代码如下:
review_subset = []
for _, item_list in sorted(by_rating.items()):
n_total = len(item_list)
n_subset = int(0.01 * n_total)
review_subset.extend(item_list[:n_subset])
为了可视化方便,这里将抽取后的子集转化为DataFrame数据格式,具体代码如下:
review_subset = pd.DataFrame(review_subset)
review_subset.head(),review_subset.shape
运行结果:
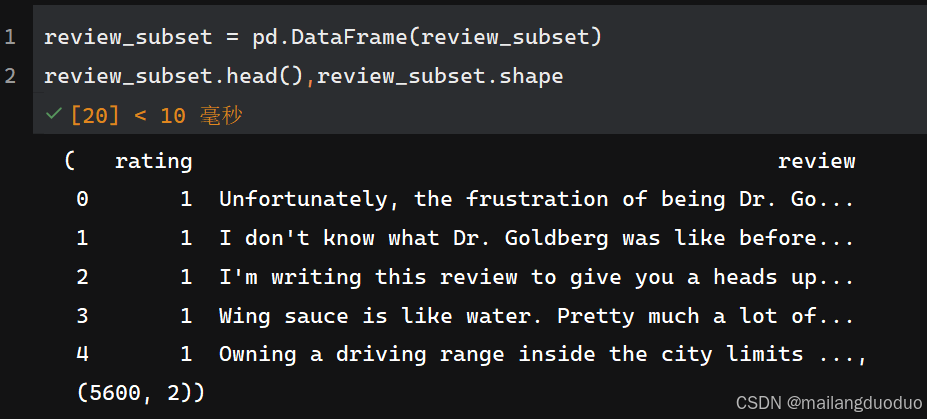
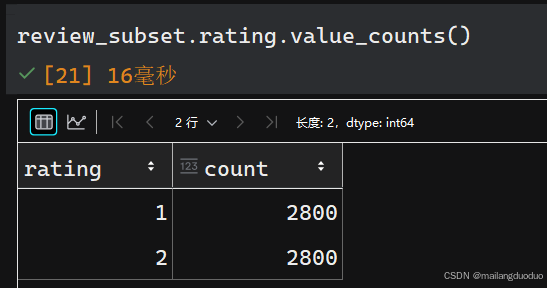
共计两个类别,每个类别均有2800条数据。
1.3划分数据集
首先,将两个类别的数据分别使用两个列表进行保存。代码如下:
by_rating = collections.defaultdict(list)
for _, row in review_subset.iterrows():
by_rating[row.rating].append(row.to_dict())
因为该过程包括了打乱顺序,为了保证结果的可重复性,因此设置了随机种子。这里划分的训练集:验证集:测试集=0.70:0.15:0.15,同时为了区分数据,增加了一个属性split,该属性共有三种取值,分别代表训练集、验证集、测试集。
import numpy as np
final_list = []
np.random.seed(1000)
for _, item_list in sorted(by_rating.items()):
np.random.shuffle(item_list)
n_total = len(item_list)
n_train = int(0.7 * n_total)
n_val = int(0.15 * n_total)
n_test = int(0.15 * n_total)
for item in item_list[:n_train]:
item['split'] = 'train'
for item in item_list[n_train:n_train+n_val]:
item['split'] = 'val'
for item in item_list[n_train+n_val:n_train+n_val+n_test]:
item['split'] = 'test'
final_list.extend(item_list)
同理为了可视化方便,将其转化为DataFrame类型,代码如下:
final_reviews = pd.DataFrame(final_list)
final_reviews.head()
运行结果:
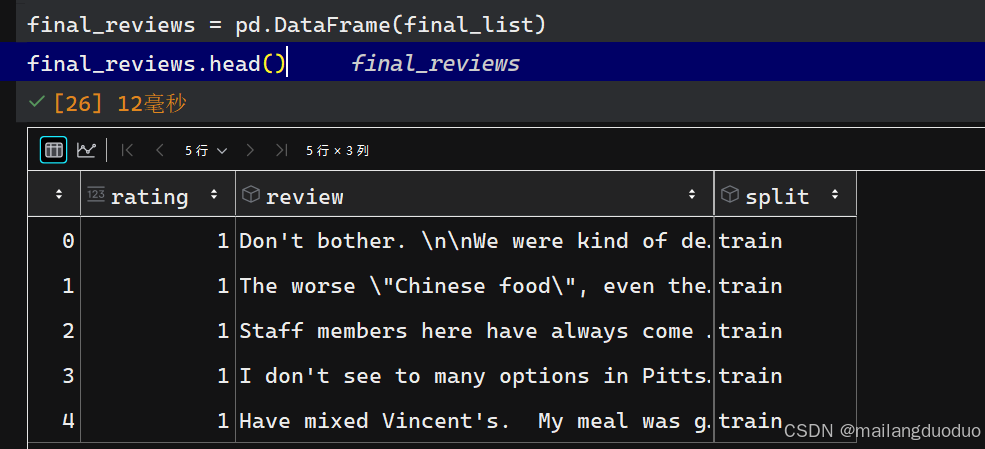
从上述结果可以看到,每条数据中还是有很多无意义的字符,如\,因此希望将其过滤掉,这就需要对数据进行清洗。
1.4数据清洗
这里为了将无意义的字符去除掉,自然就会想到正则表达式,用于匹配指定格式的字符串。具体操作代码如下:
import re
def preprocess_text(text):
text = text.lower()
text = re.sub(r"([.,!?])", r" \1 ", text)
text = re.sub(r"[^a-zA-Z.,!?]+", r" ", text)
return text
final_reviews.review = final_reviews.review.apply(preprocess_text)
这里对上述代码进行解释:
\1:指的是被匹配的字符,该段代码的功能是将匹配到的标点符号前后均加一个空格。- 第二个正则表达式:将除表示的字母及标点符号,其他符号均使用空格替代。
运行结果:
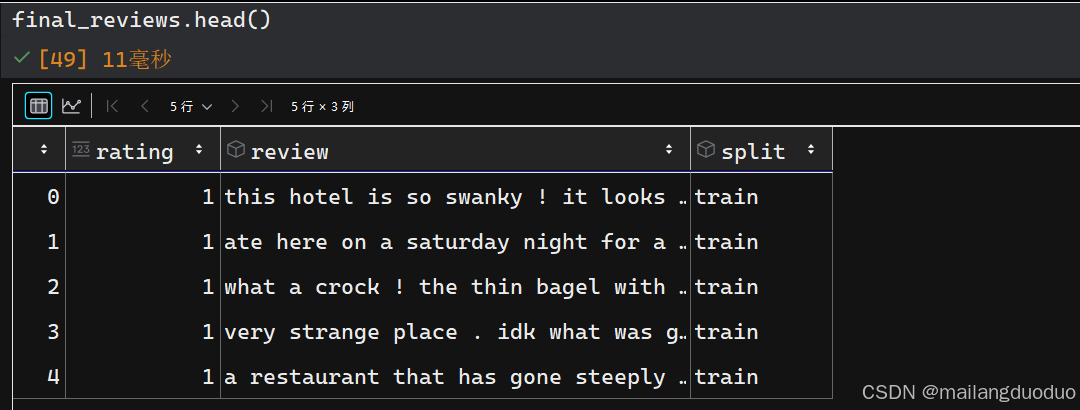
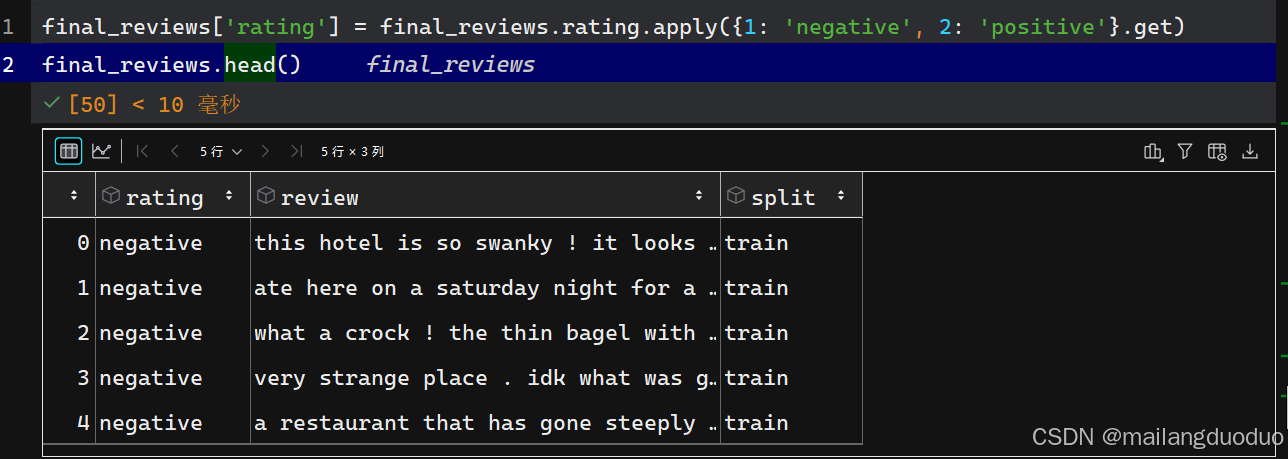
这里为了更好的展示数据,将rating属性做了更改,替换为negative和positive,
代码如下:
final_reviews['rating'] = final_reviews.rating.apply({1: 'negative', 2: 'positive'}.get)
final_reviews.head()
运行结果:
1.5数据保存
至此数据预处理基本完成,这里将处理好的数据进行保存。
final_reviews.to_csv('data/yelp/reviews_with_splits_lite_new.csv', index=False)
在输入模型前,总不能是一个句子吧,因此需要将每个样本中的review表示为向量化。
2.样本的向量化表征
2.1词汇表
这里定义了一个 Vocabulary 类,用于处理文本并提取词汇表,以实现单词和索引之间的映射。具体代码如下:
class Vocabulary(object):
"""处理文本并提取词汇表,以实现单词和索引之间的映射"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
参数:
token_to_idx (dict): 一个已有的单词到索引的映射字典
add_unk (bool): 指示是否添加未知词(UNK)标记
unk_token (str): 要添加到词汇表中的未知词标记
"""
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
"""返回一个可序列化的字典"""
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
"""从一个序列化的字典实例化 Vocabulary 类"""
return cls(**contents)
def add_token(self, token):
"""根据传入的单词更新映射字典。
参数:
token (str): 要添加到词汇表中的单词
返回:
index (int): 该单词对应的整数索引
"""
if token in self._token_to_idx:
index = self._token_to_idx[token]
else:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
"""向词汇表中添加一组单词
参数:
tokens (list): 一个字符串单词列表
返回:
indices (list): 一个与这些单词对应的索引列表
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
"""查找与单词关联的索引,若单词不存在则返回未知词索引。
参数:
token (str): 要查找的单词
返回:
index (int): 该单词对应的索引
注意:
`unk_index` 需要 >=0(即已添加到词汇表中)才能启用未知词功能
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""返回与索引关联的单词
参数:
index (int): 要查找的索引
返回:
token (str): 该索引对应的单词
异常:
KeyError: 若索引不在词汇表中
"""
if index not in self._idx_to_token:
raise KeyError("索引 (%d) 不在词汇表中" % index)
return self._idx_to_token[index]
def __str__(self):
"""返回表示词汇表大小的字符串"""
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
"""返回词汇表中单词的数量"""
return len(self._token_to_idx)
这里对该类中方法体做以下解释:
__init__构造方法:若token_to_idx为 None,则初始化为空字典。_idx_to_token是索引到单词的映射字典,通过_token_to_idx反转得到。若add_unk为 True,则调用add_token 方法添加未知词标记,并记录其索引。to_serializable 方法:返回一个字典,包含_token_to_idx、_add_unk和_unk_token,可用于序列化存储。from_serializable: 是类方法,接收一个序列化的字典,通过解包字典参数创建 Vocabulary 类的实例。add_token 方法:用于向词汇表中添加单个单词。若单词已存在,返回其索引;否则,分配一个新索引并更新两个映射字典。add_many 方法:用于批量添加单词列表,返回每个单词对应的索引列表。lookup_token 方法:根据单词查找对应的索引。若单词不存在且unk_index大于等于 0,则返回 unk_index;否则,返回单词的索引。lookup_index 方法:根据索引查找对应的单词。若索引不存在,抛出 KeyError 异常。__str__ 方法返回一个字符串,显示词汇表的大小。__len__ 方法:返回词汇表中单词的数量。
2.2向量化
此处定义了 ReviewVectorizer 类,其作用是协调词汇表(Vocabulary)并将其投入使用,主要负责把文本评论转换为可用于模型训练的向量表示。具体代码如下:
class ReviewVectorizer(object):
""" 协调词汇表并将其投入使用的向量化器 """
def __init__(self, review_vocab, rating_vocab):
"""
参数:
review_vocab (Vocabulary): 将单词映射为整数的词汇表
rating_vocab (Vocabulary): 将类别标签映射为整数的词汇表
"""
self.review_vocab = review_vocab
self.rating_vocab = rating_vocab
def vectorize(self, review):
"""为评论创建一个压缩的独热编码向量
参数:
review (str): 评论文本
返回:
one_hot (np.ndarray): 压缩后的独热编码向量
"""
# 初始化一个长度为词汇表大小的全零向量
one_hot = np.zeros(len(self.review_vocab), dtype=np.float32)
# 遍历评论中的每个单词
for token in review.split(" "):
# 若单词不是标点符号
if token not in string.punctuation:
# 将向量中对应单词索引的位置置为 1
one_hot[self.review_vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, review_df, cutoff=25):
"""从数据集的 DataFrame 实例化向量化器
参数:
review_df (pandas.DataFrame): 评论数据集
cutoff (int): 基于词频过滤的阈值参数
返回:
ReviewVectorizer 类的一个实例
"""
# 创建评论词汇表,添加未知词标记
review_vocab = Vocabulary(add_unk=True)
# 创建评分词汇表,不添加未知词标记
rating_vocab = Vocabulary(add_unk=False)
# 添加评分标签到评分词汇表
for rating in sorted(set(review_df.rating)):
rating_vocab.add_token(rating)
# 统计词频,若词频超过阈值则添加到评论词汇表
word_counts = Counter()
for review in review_df.review:
for word in review.split(" "):
if word not in string.punctuation:
word_counts[word] += 1
for word, count in word_counts.items():
if count > cutoff:
review_vocab.add_token(word)
return cls(review_vocab, rating_vocab)
@classmethod
def from_serializable(cls, contents):
"""从可序列化的字典实例化 ReviewVectorizer
参数:
contents (dict): 可序列化的字典
返回:
ReviewVectorizer 类的一个实例
"""
# 从可序列化字典中恢复评论词汇表
review_vocab = Vocabulary.from_serializable(contents['review_vocab'])
# 从可序列化字典中恢复评分词汇表
rating_vocab = Vocabulary.from_serializable(contents['rating_vocab'])
return cls(review_vocab=review_vocab, rating_vocab=rating_vocab)
def to_serializable(self):
"""创建用于缓存的可序列化字典
返回:
contents (dict): 可序列化的字典
"""
return {'review_vocab': self.review_vocab.to_serializable(),
'rating_vocab': self.rating_vocab.to_serializable()}
这里对该类中方法体做以下解释:
__init__方法:类的构造方法,接收两个 Vocabulary 类的实例:
review_vocab:将评论中的单词映射为整数。
rating_vocab:将评论的评分标签映射为整数。vectorize 方法:将输入的评论文本转换为压缩的独热编码向量。具体操作为:
首先创建一个长度为词汇表大小的全零向量 one_hot。
遍历评论中的每个单词,若该单词不是标点符号,则将向量中对应单词索引的位置置为 1。
最后返回处理好的独热编码向量。from_dataframe类方法:用于从包含评论数据的 DataFrame 中实例化ReviewVectorizer。具体操作为:
创建两个Vocabulary实例,review_vocab添加未知词标记,rating_vocab不添加。
遍历数据框中的评分列,将所有唯一评分添加到 rating_vocab 中。
统计评论中每个非标点单词的出现频率,将出现次数超过 cutoff 的单词添加到 review_vocab 中。
最后返回 ReviewVectorizer 类的实例。from_serializable 方法:从一个可序列化的字典中实例化ReviewVectorizer。
从字典中提取review_vocab和rating_vocab对应的序列化数据,分别创建 Vocabulary 实例。
最后返回 ReviewVectorizer 类的实例。to_serializable 方法:创建一个可序列化的字典,用于缓存 ReviewVectorizer 的状态。调用 review_vocab 和 rating_vocab 的 to_serializable 方法,将结果存储在字典中并返回。
2.3自定义数据集
该数据集继承Dataset,具体代码如下:
class ReviewDataset(Dataset):
def __init__(self, review_df, vectorizer):
"""
参数:
review_df (pandas.DataFrame): 数据集
vectorizer (ReviewVectorizer): 从数据集中实例化的向量化器
"""
self.review_df = review_df
self._vectorizer = vectorizer
# 从数据集中筛选出训练集数据
self.train_df = self.review_df[self.review_df.split=='train']
# 训练集数据的数量
self.train_size = len(self.train_df)
# 从数据集中筛选出验证集数据
self.val_df = self.review_df[self.review_df.split=='val']
# 验证集数据的数量
self.validation_size = len(self.val_df)
# 从数据集中筛选出测试集数据
self.test_df = self.review_df[self.review_df.split=='test']
# 测试集数据的数量
self.test_size = len(self.test_df)
# 用于根据数据集划分名称查找对应数据和数据数量的字典
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
# 默认设置当前使用的数据集为训练集
self.set_split('train')
@classmethod
def load_dataset_and_make_vectorizer(cls, review_csv):
"""从文件加载数据集并从头创建一个新的向量化器
参数:
review_csv (str): 数据集文件的路径
返回:
ReviewDataset 类的一个实例
"""
review_df = pd.read_csv(review_csv)
# 从数据集中筛选出训练集数据
train_review_df = review_df[review_df.split=='train']
return cls(review_df, ReviewVectorizer.from_dataframe(train_review_df))
@classmethod
def load_dataset_and_load_vectorizer(cls, review_csv, vectorizer_filepath):
"""加载数据集和对应的向量化器。
用于向量化器已被缓存以便重复使用的情况
参数:
review_csv (str): 数据集文件的路径
vectorizer_filepath (str): 保存的向量化器文件的路径
返回:
ReviewDataset 类的一个实例
"""
review_df = pd.read_csv(review_csv)
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(review_df, vectorizer)
@staticmethod
def load_vectorizer_only(vectorizer_filepath):
"""一个静态方法,用于从文件加载向量化器
参数:
vectorizer_filepath (str): 序列化的向量化器文件的路径
返回:
ReviewVectorizer 类的一个实例
"""
with open(vectorizer_filepath) as fp:
return ReviewVectorizer.from_serializable(json.load(fp))
def save_vectorizer(self, vectorizer_filepath):
"""使用 JSON 将向量化器保存到磁盘
参数:
vectorizer_filepath (str): 保存向量化器的文件路径
"""
with open(vectorizer_filepath, "w") as fp:
json.dump(self._vectorizer.to_serializable(), fp)
def get_vectorizer(self):
"""返回向量化器"""
return self._vectorizer
def set_split(self, split="train"):
"""根据数据框中的一列选择数据集中的划分
参数:
split (str): "train", "val", 或 "test" 之一
"""
self._target_split = split
self._target_df, self._target_size = self._lookup_dict[split]
def __len__(self):
"""返回当前所选数据集划分的数据数量"""
return self._target_size
def __getitem__(self, index):
"""PyTorch 数据集的主要入口方法
参数:
index (int): 数据点的索引
返回:
一个字典,包含数据点的特征 (x_data) 和标签 (y_target)
"""
row = self._target_df.iloc[index]
# 将评论文本转换为向量
review_vector = \
self._vectorizer.vectorize(row.review)
# 获取评分对应的索引
rating_index = \
self._vectorizer.rating_vocab.lookup_token(row.rating)
return {'x_data': review_vector,
'y_target': rating_index}
def get_num_batches(self, batch_size):
"""根据给定的批次大小,返回数据集中的批次数量
参数:
batch_size (int): 批次大小
返回:
数据集中的批次数量
"""
return len(self) // batch_size
def generate_batches(dataset, batch_size, shuffle=True,
drop_last=True, device="cpu"):
"""
一个生成器函数,封装了 PyTorch 的 DataLoader。
它将确保每个张量都位于正确的设备上。
"""
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict
这里不对代码进行解释了,关键部分已添加注释。
2.4备注
上述代码可能过长,导致难以理解,其实就是一个向量化表征的思想。上述采用的思想就是基于词频统计的,将整个训练集上的每条评论数据使用split(" ")分开形成若干个token,统计这些token出现的次数,将频次大于cutoff=25的token加入到词汇表中,并分配一个编码,其实就是索引。样本中的每条评论数据应该怎么表征呢,其实就是一个基于上述创建的词汇表的独热编码,因此是一个向量。
至此样本的向量化表征到此结束。接着就到定义模型,进行训练了。
结语
为了避免博客内容过长,这里就先到此结束,后续将接着上述内容进行阐述!同时本项目也是博主接触的第一个NLP领域的项目,如有不足,请批评指正!!!
备注:本案例代码参考本校《自然语言处理》课程实验中老师提供的参考代码