1. Kafka基础概念
1.1 什么是Kafka?
Kafka是一个分布式流处理平台,用于构建实时数据管道和流式应用。核心特点:
- 高吞吐量:每秒可处理百万级消息
- 持久化存储:消息按Topic分区存储在磁盘
- 分布式架构:支持水平扩展
- 高可用性:通过副本机制保证数据不丢失
1.2 核心组件
- Topic(主题):消息的逻辑分类,如
user_login、order_create - Partition(分区):Topic的物理分片,每个分区是有序的日志文件
- Broker(代理):Kafka集群中的服务器节点
- Producer(生产者):向Topic发送消息的应用
- Consumer(消费者):从Topic接收消息的应用
- Consumer Group(消费者组):多个消费者组成的组,共同消费Topic数据
2. Go语言操作Kafka
2.1 选择客户端库
Go语言中推荐使用confluent-kafka-go库,它基于librdkafka实现,性能优秀且功能完整:
go get -u github.com/confluentinc/confluent-kafka-go/kafka
2.2 生产者示例
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
func main() {
// 配置生产者
p, err := kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": "localhost:9092", // Kafka集群地址
"acks": "all", // 所有副本确认
"retries": 5, // 重试次数
})
if err != nil {
panic(err)
}
defer p.Close()
// 异步处理发送结果
go func() {
for e := range p.Events() {
switch ev := e.(type) {
case *kafka.Message:
if ev.TopicPartition.Error != nil {
fmt.Printf("Delivery failed: %v\n", ev.TopicPartition)
} else {
fmt.Printf("Delivered message to %v\n", ev.TopicPartition)
}
}
}
}()
// 发送消息
topic := "user_login"
for i := 0; i < 10; i++ {
value := fmt.Sprintf("Hello Kafka %d", i)
p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(value),
}, nil)
}
// 等待所有消息发送完成
p.Flush(15 * 1000) // 超时15秒
// 优雅退出
sigchan := make(chan os.Signal, 1)
signal.Notify(sigchan, syscall.SIGINT, syscall.SIGTERM)
<-sigchan
}
2.3 消费者示例
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
func main() {
// 配置消费者
c, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": "localhost:9092",
"group.id": "my-group",
"auto.offset.reset": "earliest", // 从最早的消息开始消费
})
if err != nil {
panic(err)
}
defer c.Close()
// 订阅主题
topic := "user_login"
c.SubscribeTopics([]string{topic}, nil)
// 处理信号,优雅退出
sigchan := make(chan os.Signal, 1)
signal.Notify(sigchan, syscall.SIGINT, syscall.SIGTERM)
run := true
for run {
select {
case sig := <-sigchan:
fmt.Printf("Caught signal %v: terminating\n", sig)
run = false
default:
ev := c.Poll(100) // 轮询100ms
if ev == nil {
continue
}
switch e := ev.(type) {
case *kafka.Message:
fmt.Printf("Message on %s: %s\n",
e.TopicPartition, string(e.Value))
// 手动提交偏移量
c.CommitMessage(e)
case kafka.Error:
fmt.Fprintf(os.Stderr, "%% Error: %v\n", e)
if e.Code() == kafka.ErrAllBrokersDown {
run = false
}
default:
// 忽略其他事件
}
}
}
fmt.Println("Closing consumer")
}
3. 高级特性与最佳实践
3.1 消息分区策略
Kafka通过分区实现并行处理,生产者可指定分区策略:
// 1. 轮询(默认):均匀分布消息到各分区
p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(value),
}, nil)
// 2. 基于Key哈希:相同Key的消息发到同一分区
p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Key: []byte(userID), // 根据用户ID哈希到固定分区
Value: []byte(value),
}, nil)
3.2 消费者组与分区分配
- 同一消费者组内的消费者共同消费Topic的所有分区
- 每个分区只能被组内一个消费者消费
- 消费者数量超过分区数时,多余的消费者空闲
3.3 手动提交偏移量
// 配置手动提交
config := &kafka.ConfigMap{
"bootstrap.servers": "localhost:9092",
"group.id": "my-group",
"enable.auto.commit": false, // 禁用自动提交
}
// 消费消息后手动提交
for {
msg, err := c.ReadMessage(-1) // 阻塞读取
if err == nil {
fmt.Printf("Message on %s: %s\n", msg.TopicPartition, string(msg.Value))
// 处理消息...
// 手动提交当前消息的偏移量
_, err := c.CommitMessage(msg)
if err != nil {
fmt.Printf("Failed to commit offset: %v\n", err)
}
}
}
3.4 事务处理
// 配置事务生产者
p, err := kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": "localhost:9092",
"transactional.id": "my-transactional-id",
})
if err != nil {
panic(err)
}
// 初始化事务
p.InitTransactions(10 * time.Second)
// 开始事务
p.BeginTransaction()
// 发送多条消息
p.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic1}, Value: []byte("msg1")}, nil)
p.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic2}, Value: []byte("msg2")}, nil)
// 提交事务
err = p.CommitTransaction(10 * time.Second)
if err != nil {
p.AbortTransaction(10 * time.Second) // 回滚
}
4. 企业级实战案例
4.1 异步日志处理
// 生产者:收集应用日志发送到Kafka
func LogToKafka(level, message string) {
p, _ := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": "kafka:9092"})
defer p.Close()
topic := "app_logs"
msg := &kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Key: []byte(level),
Value: []byte(message),
}
p.Produce(msg, nil)
p.Flush(2 * 1000) // 等待2秒
}
// 消费者:从Kafka读取日志并存储到Elasticsearch
func ConsumeAndIndex() {
c, _ := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": "kafka:9092",
"group.id": "log-consumer-group",
})
c.SubscribeTopics([]string{"app_logs"}, nil)
for {
msg, err := c.ReadMessage(-1)
if err == nil {
// 发送到Elasticsearch
sendToES(string(msg.Key), string(msg.Value))
}
}
}
4.2 微服务间事件驱动通信
// 订单服务:创建订单后发送事件
func CreateOrder(userID, productID string, amount float64) {
// 1. 创建订单
orderID := generateOrderID()
saveOrderToDB(orderID, userID, productID, amount)
// 2. 发送订单创建事件到Kafka
p, _ := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": "kafka:9092"})
defer p.Close()
topic := "order_created"
event := fmt.Sprintf(`{"order_id": "%s", "user_id": "%s", "amount": %.2f}`, orderID, userID, amount)
p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(event),
}, nil)
}
// 库存服务:监听订单创建事件并扣减库存
func StartInventoryService() {
c, _ := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": "kafka:9092",
"group.id": "inventory-service-group",
})
c.SubscribeTopics([]string{"order_created"}, nil)
for {
msg, err := c.ReadMessage(-1)
if err == nil {
// 解析订单事件
var orderEvent struct {
OrderID string `json:"order_id"`
UserID string `json:"user_id"`
Amount float64 `json:"amount"`
}
json.Unmarshal(msg.Value, &orderEvent)
// 扣减库存
deductInventory(orderEvent.ProductID, 1)
}
}
}
5. 性能优化与常见问题
5.1 生产者性能优化
- 批量发送:设置
batch.size和linger.ms - 压缩消息:启用
compression.type(如snappy、lz4) - 异步发送:使用回调函数处理发送结果
5.2 消费者性能优化
- 增加分区数:提高并行消费能力
- 多消费者实例:通过消费者组水平扩展
- 合理批量处理:批量拉取消息,批量提交偏移量
5.3 常见问题排查
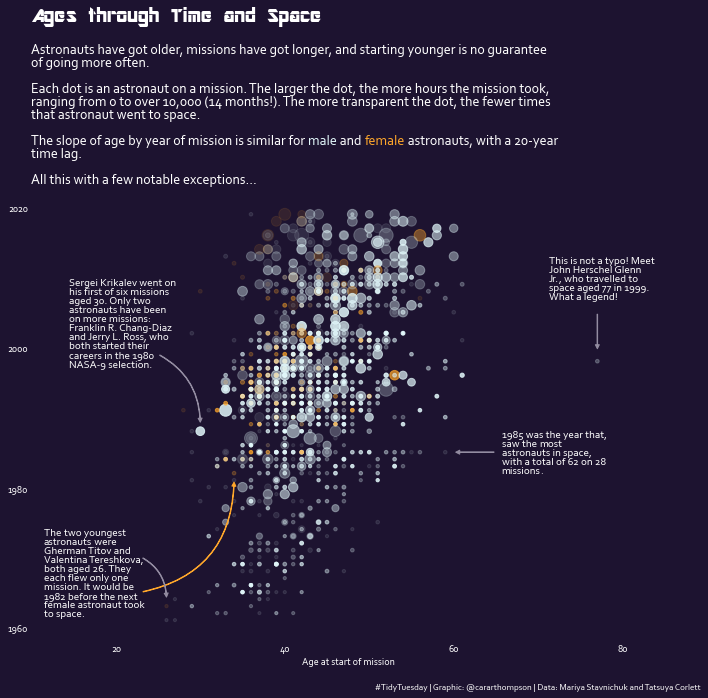
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 消息丢失 | acks配置不当、副本数不足 | 设置acks=all,确保至少2个副本 |
| 消费滞后 | 消费速度慢、分区数不足 | 增加消费者、提高处理效率、增加分区数 |
| 重复消费 | 偏移量提交时机不当 | 处理完消息后再提交偏移量,或使用事务 |
| 生产者吞吐量低 | 批处理参数不合理、网络延迟 | 增大batch.size和linger.ms,优化网络连接 |
6. 生产环境部署建议
- 多Broker集群:至少3个Broker,提高可用性
- 合理分区数:根据业务量预估,建议单个Topic分区数≥3
- 数据备份:定期备份Kafka日志
- 监控系统:集成Prometheus、Grafana监控Kafka性能
- 安全配置:启用SSL/TLS加密、SASL认证
总结:Go语言使用Kafka的最佳实践
-
生产者:
- 使用异步发送提高吞吐量
- 合理配置acks和重试次数保证消息不丢失
- 根据业务需求选择分区策略
-
消费者:
- 使用消费者组实现水平扩展
- 手动提交偏移量确保消息处理可靠性
- 处理消息失败时考虑重试或死信队列
-
性能与可靠性:
- 批量处理提高效率
- 监控关键指标(如Lag、吞吐量)
- 设计幂等消费逻辑应对重复消息
https://github.com/0voice