实现二叉查找树
- 1、二叉查找树介绍
- 2.上机要求
- 3.上机环境
- 4.程序清单(写明运行结果及结果分析)
- 4.1 程序清单
- 4.1.1 头文件 TreeMap.h 内容如下:
- 4.1.2 实现文件 TreeMap.cpp 文件内容如下:
- 4.1.3 源文件 main.cpp 文件内容如下:
- 4.2 实现展效果示
- 5.上机体会
1、二叉查找树介绍
二叉查找树(Binary Search Tree, BST)是一种特殊的二叉树,其中每个节点都包含一个键值,并且满足以下性质:
- 左子树中的所有节点的键值小于当前节点的键值。
- 右子树中的所有节点的键值大于当前节点的键值。
- 左右子树也分别是二叉查找树。
二叉查找树的优缺点
- 优点
查找、插入和删除操作的平均时间复杂度为O(log n)。
结构简单,易于实现。 - 缺点
在最坏情况下(如树退化为链表),时间复杂度会退化为O(n)。
需要额外的平衡操作(如AVL树、红黑树)来保持树的平衡,避免性能退化。 - 二叉查找树是计算机科学中一种基础且重要的数据结构,理解其原理和操作对于深入学习算法和数据结构具有重要意义。
2.上机要求
基于二叉排序树,实现插入键值对、按照关键字查询、删除记录等操作
3.上机环境
visual studio 2022
Windows11 家庭版 64位操作系统
4.程序清单(写明运行结果及结果分析)
4.1 程序清单
4.1.1 头文件 TreeMap.h 内容如下:
#pragma once
#include<iostream>
//基于二叉排序树,实现插入键值对、按照关键字查询、删除记录等操作
#define maxsize 100
using namespace std;
typedef string Key;
typedef string Val;
typedef struct TNode {
Key key;
Val val;
//struct TNode* parent;
struct TNode* lcd;
struct TNode* rcd;
}Tnode, * pTnode;
void insert(pTnode& tree, Key key, Val val); //函数插入
void TreeCreate(pTnode& tree); //创建
void Min_Order_View(pTnode tree); //由索引从小到大展示
void Max_Order_View(pTnode tree); //由索引从大到小展示
void input(pTnode& tree); //键盘插入
int gethigh(pTnode tree); //得到这一层树的高度,可以通过它得到平衡因子
void deletee(pTnode& tree, Key key); //删除
void search(pTnode tree, Key key); //查找
int getfactor(pTnode tree); //得到平衡因子,尚且没有用到,方便拓展成平衡二叉树
4.1.2 实现文件 TreeMap.cpp 文件内容如下:
#include"TreeMap.h"
void insert(pTnode& tree,Key key,Val val){
if (tree == nullptr) {
tree = new Tnode;
tree->val = val;
tree->key = key;
tree->lcd = nullptr;
tree->rcd = nullptr;
return;
}
if (key == tree->key) {
cout << "键值已经存在"; return;
}
else if (key < tree->key) {
insert(tree->lcd, key, val);
}
else {
insert(tree->rcd, key, val);
}
}
void TreeCreate(pTnode& tree) {
cout << "开始输入键值对,键值对都为q时退出>>\n";
while (1) {
Key key;
Val val;
cout << "Key>>"; cin >> key;
cout << "Val>>"; cin >> val;
if ((key == "q" || key == "Q") && (val == "q" || val == "Q"))break;
else {
insert(tree, key, val);
}
}
cout << "输入成功\n";
}
void Min_Order_View(pTnode tree){
if (tree!=nullptr) {
if (tree->lcd)Min_Order_View(tree->lcd);
cout << tree->key << "\t" << tree->val << endl;
if (tree->rcd)Min_Order_View(tree->rcd);
}
else return;
}
/**
* 该函数用于按最大顺序遍历二叉树。
* 遍历顺序为:右子树 -> 当前节点 -> 左子树。
* @param tree 指向二叉树根节点的指针。
*/
void Max_Order_View(pTnode tree) {
if (tree!=nullptr) {
if (tree->rcd) Max_Order_View(tree->rcd);
cout << tree->key << "\t" << tree->val << endl;
if (tree->lcd) Max_Order_View(tree->lcd);
}
else return;
}
/**
* 该函数用于向二叉树中插入一个新的节点。
* 用户需要输入键值和对应的值,函数会将其插入到二叉树中。
* @param tree 指向二叉树根节点的指针的引用。
*/
void input(pTnode& tree){
Key key; cout << "input key>>"; cin >> key;
Val val; cout << "input val>>"; cin >> val;
insert(tree, key, val);
cout << "finish!" << endl;
}
/**
* 该函数用于计算二叉树的高度。
* 通过递归计算左子树和右子树的高度,返回较大的高度加1。
* @param tree 指向二叉树根节点的指针。
* @return 返回二叉树的高度。
*/
int gethigh(pTnode tree) {
int hl, hr;
if (tree) {
hl = gethigh(tree->lcd);
hr = gethigh(tree->rcd);
return hl > hr ? hl + 1 : hr + 1;
}
else return 1;
}
/*
deletee 函数用于从二叉搜索树中删除具有指定键值的节点。
该函数通过递归的方式查找并删除目标节点,同时处理了多种情况,
包括删除叶子节点、只有左子树或右子树的节点,以及同时拥有左右子树的节点。
*/
void deletee(pTnode& tree, Key key){
if (tree == nullptr) {
cout << "无对应键值" << endl;
return;
}
if (key == tree->key) {
if (tree->lcd == nullptr&&tree->rcd == nullptr) {//叶子
delete tree;
tree = nullptr; //呜呜请加上这句,bug所在
cout << "OK1" << endl;
return;
}
else if (tree->lcd == nullptr && tree->rcd != nullptr) {//没有左子树
pTnode del = tree;
tree = tree->rcd;
delete del;
cout << "OK2" << endl;
return;
}
else if (tree->lcd != nullptr && tree->rcd == nullptr) {//没有右子树
pTnode del = tree;
tree = tree->lcd;
delete del;
cout << "OK3" << endl;
return;
}
else {//左右子树都有
pTnode move = tree->rcd;
while (move->lcd != nullptr)//拿到替死鬼
{
move = move->lcd;
}
tree->key = move->key;
tree->val = move->val;
delete move;
cout << "OK4" << endl;
return;
}
}
else if (key < tree->key) {
if (tree->lcd)deletee(tree->lcd, key);
}
else {
if (tree->rcd)deletee(tree->rcd, key);
}
}
/**
* @brief 在二叉搜索树中查找指定键值的节点
* 该函数递归地在二叉搜索树中查找与给定键值匹配的节点。如果找到匹配的节点,则输出该节点的键值和对应的值;如果未找到,则输出提示信息。
*/
void search(pTnode tree, Key key) {
if (tree == nullptr) {
cout << key << ":" << "不存在此键值" << endl;
return;
}
if (tree->key == key) {
cout << key << ":" << tree->val << endl;
return;
}
else if (key < tree->key) {
search(tree->lcd, key);
}
else {
search(tree->rcd, key);
}
}
int getfactor(pTnode tree){
if (tree) return(gethigh(tree->lcd) - gethigh(tree->rcd));
else return 0;
}
4.1.3 源文件 main.cpp 文件内容如下:
#include"TreeMap.h"
int main() {
pTnode tree = nullptr;
TreeCreate(tree); //创建
cout << "从小到大索引" << endl; //从小到大输出
Min_Order_View(tree);
input(tree); //增加操作
insert(tree, "my", "我的");
cout << "从大到小索引" << endl; //从大到小输出
Max_Order_View(tree);
cout << "删除操作" << endl; //删除操作
deletee(tree, "my");
Max_Order_View(tree);
cout << "查询操作" << endl; //查找操作
search(tree, "hello");
search(tree, "my");
cout<<"\nget factor:"<<getfactor(tree);
return 0;
}
4.2 实现展效果示
如左下图,输入部分:当全部是q时完成输入,可以看到,输入的索引是无序的。
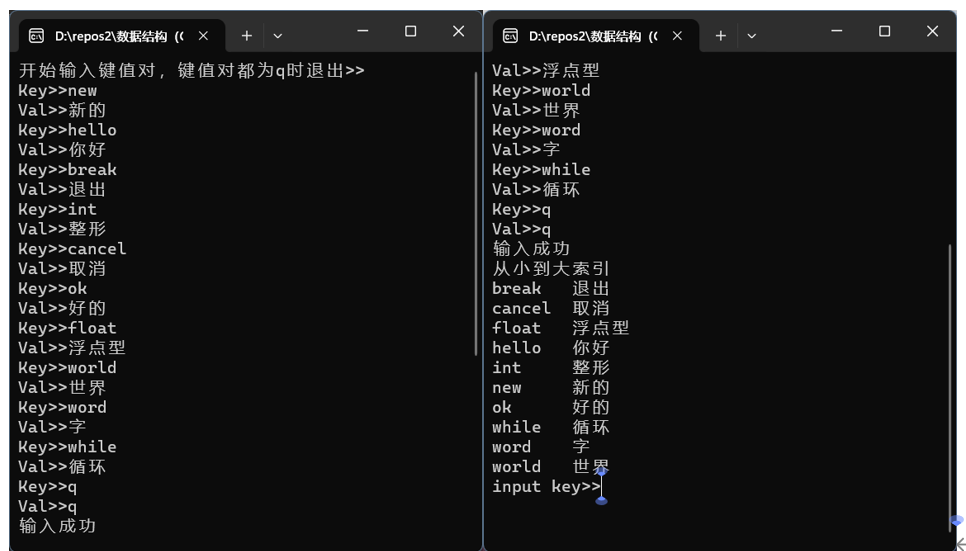
如右上图,输出部分,按照关键字大小顺序从小到大,输出了键值对,提示我们插入一条信息。
如左下图我们输入hellow 你好w,由于代码中插入 my 我的 这个记录,再次展示的记录多了两条,同时这次采用从大到小的打印方法。
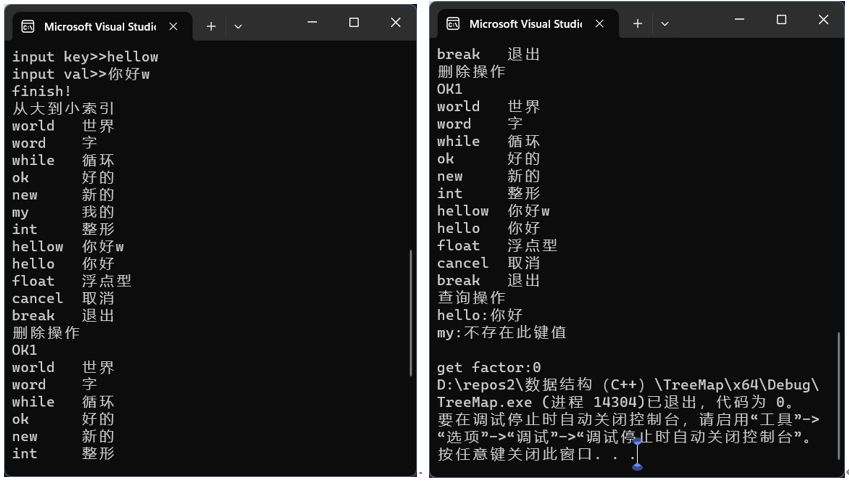
如右上图,代码中我们选择删除 my 关键字,提示OK1,表明我们删除了叶子节点,再次展示从大到小,不存在 my 节点,同时 search 操作对 hello 有效,对 my 无效。
5.上机体会
二叉查找树(Binary Search Tree,BST)是一种特殊类型的二叉树,它所有的根节点大于左子树的节点,小于右子树的节点。具有以下性质:
1、 如果左子树不为空,则左子树上的所有节点都小于根节点。
2、 如果右子树不为空,则右子树上的所有节点都大于根节点。
3、 左右子树也为搜索二叉树。
二叉查找树的常用操作有:插入、查找、删除、最大值、最小值等。
在二叉树的创建过程中,可以使用递归的方式。首先,将根节点的值设置为给定的值,然后递归地构建左子树和右子树。插入查找删除的理想时间复杂度为 O(log n),其中 n 是树的节点数。中序遍历输出二叉树则是很好的排序方法。通过实验,我们可以更加深入地理解二叉查找树的概念和性质,掌握二叉查找树的常见操作的实现方法。同时,我们也可以通过实验发现一些二叉查找树的应用场景,例如在数据库中的索引结构、文件系统中的目录结构等。需要注意的是,二叉查找树的性能高度依赖于树的平衡性。如果树的平衡性较差,可能会导致搜索效率降低。因此,在实际应用中,需要对二叉查找树进行适当的平衡调整,例如使用红黑树等自平衡二叉查找树。