一、基本概念
POI:即Apache POI, 它是一个开源的 Java 库,主要用于读取 Microsoft Office 文档(Word、Excel、PowerPoint 等),修改 或 生成 Office 文档内容,保存 为对应的二进制或 XML 格式(如 .doc、.docx、.xls、.xlsx)。
书签:作用类似于图书阅读中的实体书签(bookmark),字面上就是用来标记(记住)某一页或某一段的位置。在 Word 里,你可以给文档的某个位置(文字、段落或任意元素前后)打上一个“标记”,并为它命名,在自动化处理文档时,就相当于给程序提供了一个清晰、稳定的操作目标。(利用 Apache POI 等库,可以通过书签来定位,针对该区域执行“替换”、“删除”或“插入”操作,而不必遍历整个文档或依赖复杂的坐标。)
基础概念
Docx4j:即Docx 4j,Docx指用于Microsoft Word 2007 及以后版本使用的文件格式(基于 Office Open XML,扩展名为 .docx),4j表示 "for Java",即专为 Java 设计的库。它是用于Java 的 DOCX 文档处理库,明确其核心功能是操作现代 Word 文档格式(.docx)。
(Docx4j与POI均为Java开发者提供操作Word文档的能力,但POI适合需要同时处理 .doc 和 .docx 的旧项目,具有更活跃的 Apache 社区支持,采用Apache 2.0协议。而Docx4j 适合专注于 .docx 且需要更高级功能的场景(如 PDF 转换),采用AGPLv3协议。两者在实现原理上也不同,Docx4j 将 Word 文档的 XML 结构映射为 Java 对象(通过 JAXB),代码更直观,大文件处理可能更高效(依赖 JAXB 优化)。而POI 直接操作 XML 节点,灵活性高但代码更繁琐,大文件易内存溢出(DOM 模型))
Aspose.Words:即 Aspose 公司提供的 Word 文档处理解决方案,适合企业级复杂需求,功能强大,支持 Word 文档的完整操作(格式、图表、加密、渲染为 PDF 等),需要商业许可,并且提供更好的技术支持和稳定性。
(Aspose.Words 是商业化、功能全面的 Word 操作库,它提供类似 Word 对象模型(如 Document、Paragraph),API 更直观,适合企业级应用。而POI 是开源基础工具,适合轻量级需求或预算有限的场景。另外Aspose.Words支持 .NET/Java/Cloud API,并且官方商业技术支持)
HWPF:即"Horrible Word Processor Format",直译为“糟糕的文字处理器格式”。这个名字是 Apache POI 开发者对旧版 Microsoft Word 二进制文件格式(.doc)的一种调侃式命名,原因是.doc 格式是微软私有的二进制格式,结构复杂且未完全公开,解析和操作极其困难,在逆向工程 .doc 格式时遇到了许多挑战,因此用“Horrible”形容其开发过程。
(HWPF 是 Apache POI 项目中专门用于处理 旧版 Word 文件(.doc) 的组件,属于 POI 的早期核心模块之一(与 Excel 的 HSSF 属于同一代)。尽管 HWPF 已过时,但 POI 仍保留它,主要为了向后兼容,支持遗留系统需要读取或修改旧版 .doc 文件)
XWPF :即"XML Word Processor Format",表示它处理的是基于 Office Open XML (OOXML) 格式的文档(即 .docx 文件,本质是 ZIP 压缩的 XML 文件集合,可将 .docx 重命名为 .zip 解压,观察文件内容),关键类有XWPFDocument(表示整个 .docx 文档)、XWPFParagraph(操作段落)、XWPFRun(段落中的文本片段(控制字体、样式等))、XWPFTable(操作表格)、XWPFStyles(管理样式(如标题、正文样式))等
(XWPF 基于 POI 的 POI-OOXML 子模块实现,后者提供了对 Office Open XML 格式(2007+)的底层解析支持,它与旧版 HWPF(处理 .doc 二进制格式)并列,共同覆盖 Word 文档的全版本。)
OOXML:即Office Open XML,是 Microsoft 从 Office 2007 开始引入的基于 XML 的文档格式标准,用于替代旧的二进制格式(如 .doc、.xls)。Office Open表示表示格式的开放性(由 ECMA 和 ISO 标准化,文档结构可被第三方工具解析);XML表示文档内容以 XML 文件的形式存储,本质是一个 ZIP 压缩包(可重命名为 .zip 解压查看内部结构)。
典型 OOXML 文档结构(以 .docx 为例)解压后的文件目录如下:
word/
├── document.xml # 正文内容
├── styles.xml # 样式定义
├── header1.xml # 页眉
├── footer1.xml # 页脚
├── theme/ # 主题
└── ...
_rels/ # 文件关系定义
[Content_Types].xml # 内容类型声明
具体内容结构如下:
<pkg:package> 表示整个文档包
...<pkg:part> 表示文档包包含的多个 part(部件件),例如正文、样式、关系等
<pkg:part pkg:name="/word/document.xml"> 表示 Word 文档的主体内容所在的 XML 文件
<pkg:xmlData> 表示XML 的实际数据内容,也就是文档的主体结构数据
<w:document> Word 文档的根节点
<w:body> 文档主体
...多种不同的标签
<w:p> 表示一个段落(paragraph)
...多种不同的标签
<w:pPr> 段落属性(paragraph properties)
...多种不同的标签
<w:lang> 语言设置
<w:rFonts> 字体设置
<w:ind> 段落缩进设置
<w:r> 表示一个文本运行(run)
...多种不同的标签
<w:rPr> 文本运行的属性
...多种不同的标签
<w:rFonts> 字体设置
<w:lang> 语言设置
<w:noProof>
<w:t> 表示具体的文本内容
<w:drawing> 表示绘图对象(如图片、形状)
<wp:inline> 表示内联对象
...多种不同的标签
<a:graphic> 表示图形元素
<a:graphicData> 表示图形数据
...多种不同的标签
<pic:pic> 表示图片元素
<pic:nvPicPr> 表示图片非视觉属性
<pic:blipFill> 表示图片填充
<pic:spPr> 表示图形形状属性
<wp:docPr> 表示文档属性
<wp:extent> 表示对象尺寸
<wp:effectExtent> 表示效果范围
<wp:cNvGraphicFramePr> 表示图形框架属性
<w:proofErr> 标记拼写或语法错误
<w:bookmarkStart> 表示书签的起始(可任意位置但一定成对出现。大多数位于段落内,但是也跨段落出现,还可存在于表格、页眉页脚、文档主体中)
<w:bookmarkEnd> 表示书签的结束(可任意位置,同w:bookmarkStart)
<w:tbl> 表示一个表格
<w:tblPr> 表示表格属性
<w:tblGrid> 表示表格列宽定义
...多个<w:tr>
<w:tr> 表示表格行(table row)
...多个<w:tc>
<w:tc> 表示表格单元格(table cell)
<w:tcPr> 表示单元格属性
<w:tcW> 表示单元格宽度
<w:p>(POI 基于 OOXML 标准实现,比如XWPF(用于操作 .docx)和 XSSF(用于操作 .xlsx)模块本质上是 OOXML 的高级 Java 封装。POI的操作层级根据是否进行了高级封装而不直接操作XML, 可以分为高级 API(推荐,比如使用 XWPFDocument、XWPFParagraph 等类,无需直接接触 XML)以及低级 API(直接操作 OOXML 的 XML 绑定类(如 CTP、CTR),适用于 POI 未封装的功能)。POI 屏蔽了 OOXML 的复杂性,开发者无需手动编写 XML,但是若需实现 POI 未支持的功能(如复杂图表),需直接操作 OOXML 或结合 OpenXML SDK实现)
二、操作步骤
1、引入依赖
<!-- 支持 新版 Office OOXML 格式(如 .docx、.xlsx),是操作 Word 书签的 核心依赖,并且poi-ooxml 的依赖链包含 poi、xmlbeans 等必要库,无需手动重复添加-->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.3</version>
</dependency>
<!-- 可选:旧版 Word 的附加支持(如图片、复杂格式) -->
<!-- <dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>5.2.3</version>
</dependency>-->(poi-ooxml是操作 Word 书签的 核心依赖,它包含 了XWPF(处理 .docx 文件的核心类,如 XWPFDocument),后续所有基于 .docx 的书签操作(替换、删除、插入)都依赖此模块)
2、插入word书签
这里所打的书签格式均与代码中的判断相对应,建议可直接采用本文中的书签格式方便实践
2.1、替换书签的插入
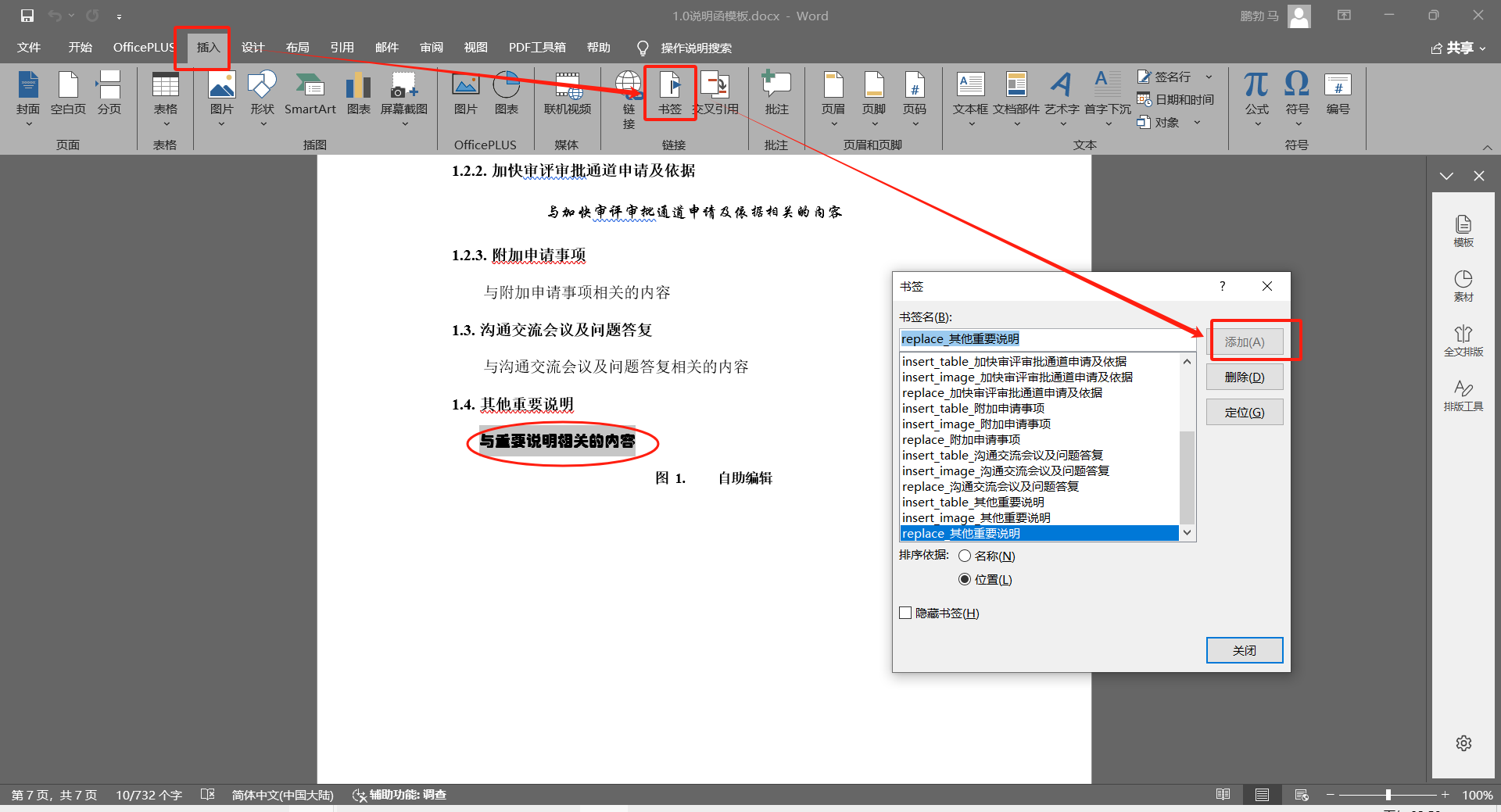
书签固定的格式为replace_xxx,它主要用于替换具有一定文本格式的文本内容,需要选中一段文本后,通过在word的菜单 插入-》书签 弹窗中,输入书签名,点击添加插入replace书签
2.2、删除书签的插入
书签固定格式为delete_数字,它主要用于删除word内容,需要选择要删除的文本内容,然后在word的菜单 插入-》书签 弹窗中,输入书签名,点击添加插入delete书签
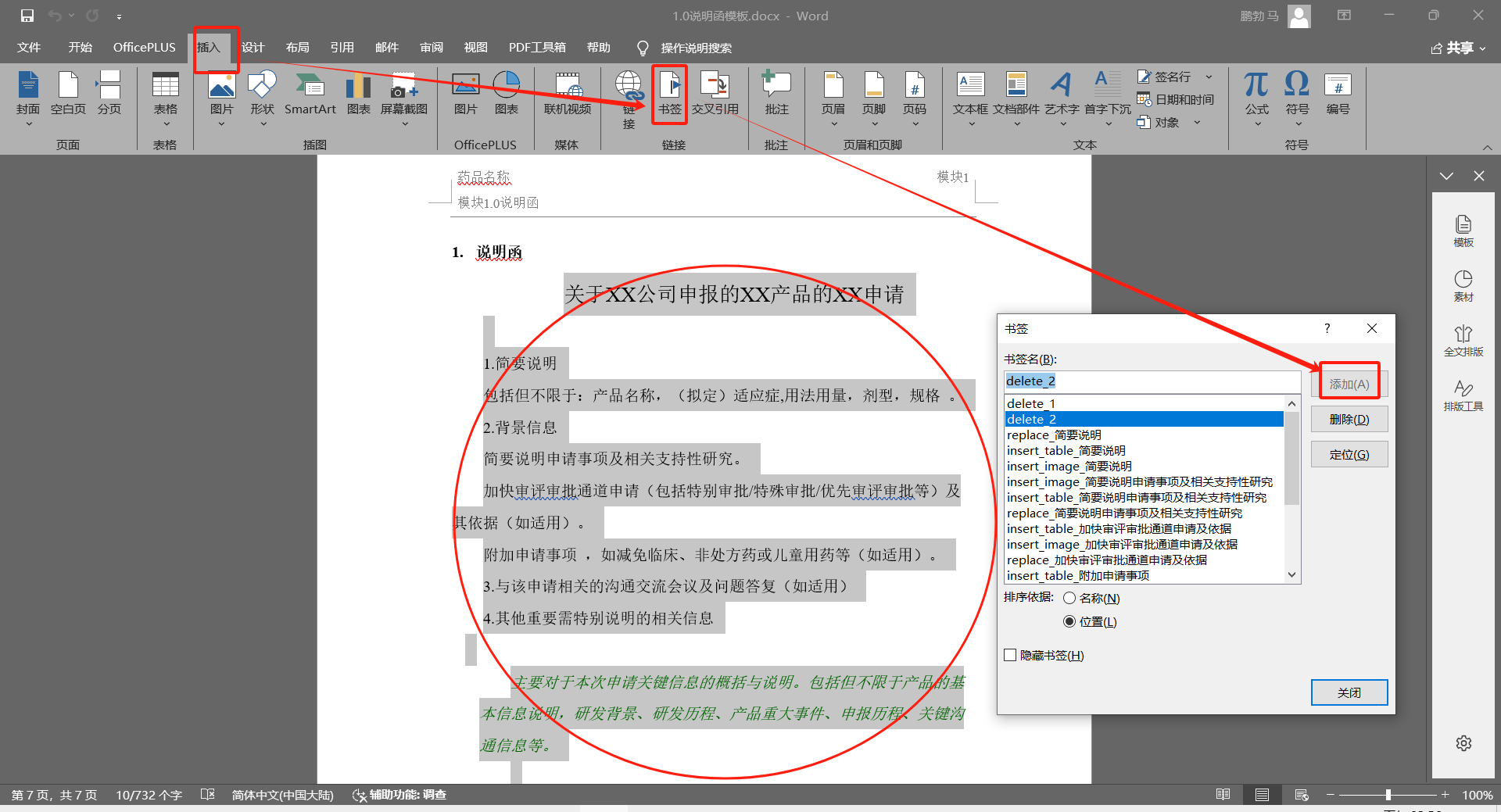
2.3、插入书签的插入
书签固定格式为insert_text_xxx、insert_image_xxx、insert_table_xxx,它主要用于插入word内容,通常对于文本会通过replace进行替换以满足文本的格式,而对于图片和表格则在代码中自定义样式插入。插入书签首先需要光标点击要插入的位置,然后直接在word的菜单 插入-》书签 弹窗中,输入书签名,点击添加插入insert书签
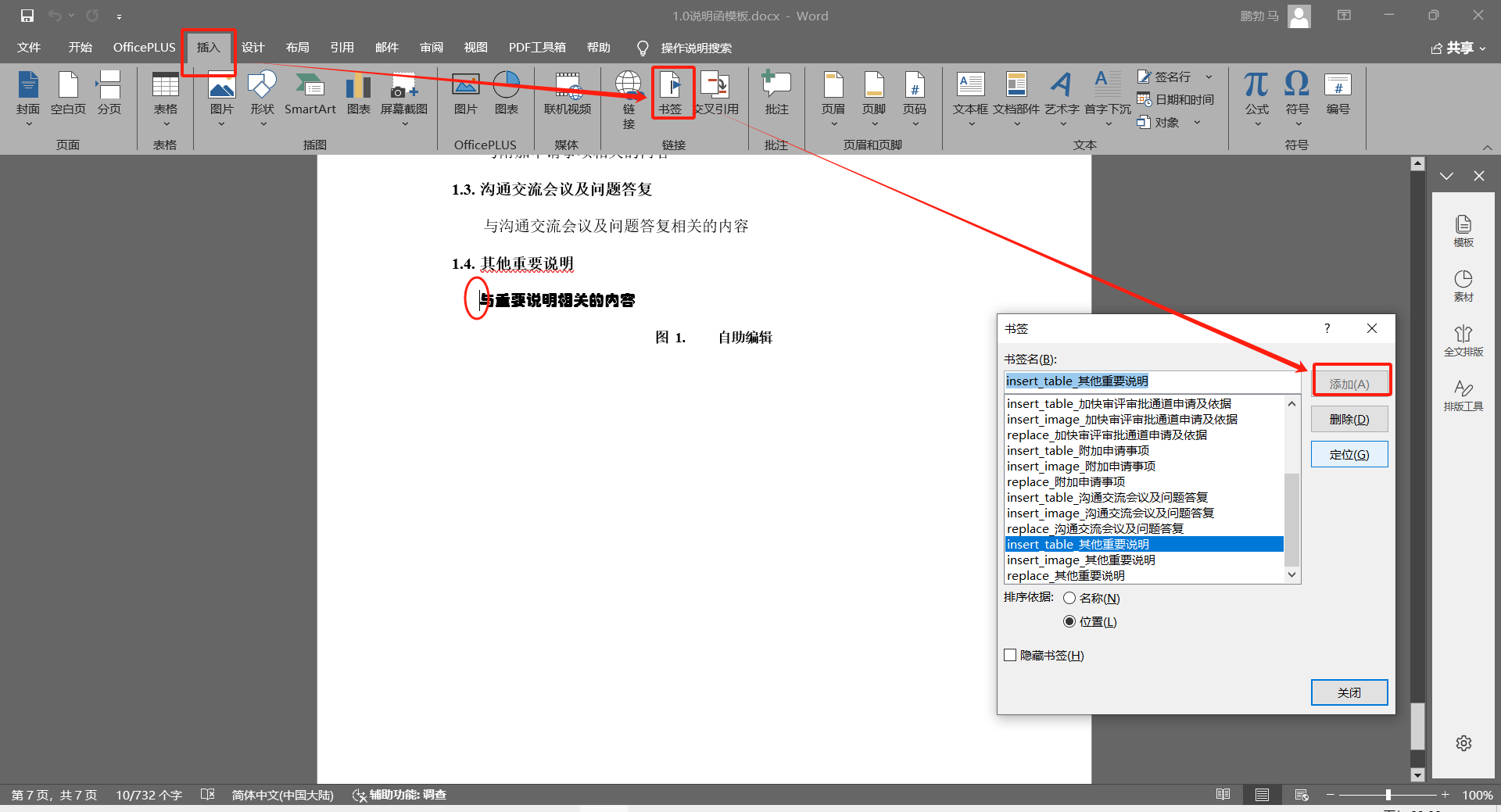
3、书签的处理
在代码中由注释可见,针对三种书签的插入有三个主要的部分,“一、replace书签的处理”部分、“二、insert书签的处理”、“三、delete书签的处理”,具体代码如下(针对OOXML中的bookmark书签,这里采用低级底层操作以真实完整获取书签位置和书签范围内的节点,因此很好的处理了一些跨段书签的情况,在多数博主相关POI操作word的文档中都未很好的考虑并处理这个问题):
/**
* 处理书签
* @param replaceBookmarkAndValue 替换书签及值
* @param insertBookmarkAndValue 插入书签及值
* @param deleteBookmarks 删除书签
* @param tempFilePath 模板文件路径
*/
public void dealWithBookMark(Map<String, String> replaceBookmarkAndValue, Map<String, String> insertBookmarkAndValue,
List<String> deleteBookmarks, String tempFilePath) {
File file = new File(tempFilePath);
try (InputStream is = Files.newInputStream(file.toPath())) {
XWPFDocument docx = new XWPFDocument(is);
// 一、replace书签的处理(针对文本)
boolean isBookmarkEnd;
Node bodyNode = docx.getDocument().getBody().getDomNode();
NodeList bodyChildNodes = bodyNode.getChildNodes();
List<String> replaceBookmarks = new ArrayList<>(replaceBookmarkAndValue.keySet());
for (String bookmark : replaceBookmarks) {
// 书签范围内完整的P标签
List<Node> inBookmarkRangePNodes = new ArrayList<>();
// 书签范围内除了完整的P标签之外,到结束标签为止,额外多余的P标签子节点(如果书签跨p,则从第0个子节点计算,不包含结束书签;如果书签不跨p,则包含起始书签,不包含结束书签)
List<Node> inBookmarkRangeExtraPChildNodes = new ArrayList<>();
isBookmarkEnd = getBookmarkSartAndEndRangeNodes(bodyChildNodes, bookmark,
replaceBookmarkAndValue.get(bookmark), inBookmarkRangeExtraPChildNodes,
inBookmarkRangePNodes);
// 删除除第一个替换内容的<w:r 节点以外的其他所有节点
if (isBookmarkEnd) {
if (!CollectionUtils.isEmpty(inBookmarkRangePNodes)) {
Node pNode = inBookmarkRangePNodes.get(0);
NodeList pNodeChildNodes = pNode.getChildNodes();
List<Node> nodes = new ArrayList<>();
for (int i = 0; i < pNodeChildNodes.getLength(); i++) {
Node node = pNodeChildNodes.item(i);
nodes.add(node);
}
deleteExtraPChildNodes(bodyChildNodes, nodes);
// 存在多个p时,除了第一个p,其他p全部删除
if (inBookmarkRangePNodes.size() > 1) {
for (int i = 1; i < inBookmarkRangePNodes.size(); i++) {
Node node = inBookmarkRangePNodes.get(i);
bodyNode.removeChild(node);
}
}
// 存在p时,额外的p子内容一定是全删除的
for (int i = 0; i < bodyChildNodes.getLength(); i++) {
Node bodyChildNode = bodyChildNodes.item(i);
for (Node pChildNode : inBookmarkRangeExtraPChildNodes) {
if (pChildNode.getParentNode() == bodyChildNode) {
bodyChildNode.removeChild(pChildNode);
}
}
}
} else {
deleteExtraPChildNodes(bodyChildNodes, inBookmarkRangeExtraPChildNodes);
}
}
}
// 二、insert书签的处理(针对文本、图片、表格)
List<String> insertBookMarks = new ArrayList<>(insertBookmarkAndValue.keySet());
for (String bookmark : insertBookMarks) {
for (XWPFParagraph paragraph : docx.getParagraphs()) {
CTP ctp = paragraph.getCTP();
List<CTBookmark> bookmarkStartList = ctp.getBookmarkStartList();
if (CollectionUtils.isEmpty(bookmarkStartList)) {
continue;
}
boolean anyMatch = bookmarkStartList.stream().map(CTBookmark::getName)
.anyMatch(item -> item.startsWith("insert"));
if (!anyMatch) {
continue;
}
Node paragraphNode = ctp.getDomNode();
NodeList childNodes = paragraphNode.getChildNodes();
for (int i = 0; i < childNodes.getLength(); i++) {
if (childNodes.item(i).getNodeName().equals("w:bookmarkStart")) {
String bookmarkValue = childNodes.item(i).getAttributes().getNamedItem("w:name").getNodeValue();
String insertValue;
int lastUnderscoreIndex = bookmark.lastIndexOf("_");
// 如果书签匹配,则获取插入值(这里匹配书签的前缀部分,用于多个内容统一位置的插入,比如insert_table_简要说明_1、insert_table_简要说明_2)
if (bookmark.substring(0, lastUnderscoreIndex).equals(bookmarkValue)) {
insertValue = insertBookmarkAndValue.get(bookmark);
} else {
continue;
}
if (bookmarkValue.startsWith("insert")) {
if (bookmarkValue.startsWith("insert_text")) {
// 在书签后插入w:r标签,并插入文本内容"插入插入插入"
// 创建 <w:r>
Document ownerDoc = childNodes.item(i).getOwnerDocument();
Element r =
ownerDoc.createElementNS("http://schemas.openxmlformats" + ".org/wordprocessingml" +
"/2006/main", "w:r");
// 创建 <w:t>
Element t =
ownerDoc.createElementNS("http://schemas.openxmlformats" + ".org/wordprocessingml" +
"/2006/main", "w:t");
t.appendChild(ownerDoc.createTextNode(insertValue));
r.appendChild(t);
// 在 bookmarkStart 后插入新建的<w:r>
Node insertBeforeNode = childNodes.item(i).getNextSibling();
if (insertBeforeNode != null) {
paragraphNode.insertBefore(r, insertBeforeNode);
childNodes = paragraphNode.getChildNodes();
}
} else if (bookmarkValue.startsWith("insert_image")) {
XWPFRun run = paragraph.createRun();
InputStream picIs = Files.newInputStream(Paths.get(insertBookmarkAndValue.get(bookmark)));
// 3. 向文档中添加图片数据,并且返回一个 relation id(内部处理好关系表和 media/* 文件)
String filename = "图片.png";
int format = XWPFDocument.PICTURE_TYPE_PNG; // 或者 PICTURE_TYPE_JPEG, etc.
run.addPicture(picIs, format, filename, Units.toEMU(350), // 宽度 200pt 转换为 EMU
Units.toEMU(200) // 高度 100pt 转换为 EMU
);
// 在 bookmarkStart 后插入新建的<w:r>
Node runNode = run.getCTR().getDomNode();
Node insertBeforeNode = childNodes.item(i).getNextSibling();
if (insertBeforeNode != null) {
paragraphNode.insertBefore(runNode, insertBeforeNode);
childNodes = paragraphNode.getChildNodes();
}
} else if (bookmarkValue.startsWith("insert_table")) {
// 1、用Jsoup解析
org.jsoup.nodes.Document htmlDoc = Jsoup.parse(insertBookmarkAndValue.get(bookmark));
org.jsoup.nodes.Element htmlTable = htmlDoc.selectFirst("table");
if (Objects.isNull(htmlTable)) {
continue;
}
Elements rows = htmlTable.select("tr");
// 2、计算表格尺寸(考虑 colspan)
int numRows = rows.size();
int maxCols = 0;
for (org.jsoup.nodes.Element rowElem : rows) {
int cols = 0;
for (org.jsoup.nodes.Element cellElem : rowElem.select("th,td")) {
int cs = cellElem.hasAttr("colspan") ? Integer.parseInt(cellElem.attr("colspan")) : 1;
cols += cs;
}
maxCols = Math.max(maxCols, cols);
}
// 3、临时在文档末尾创建一个 numRows x maxCols 的表格
XWPFTable table = docx.createTable(numRows, maxCols);
// 4、遍历行和列,填数据,处理行列合并
Map<List<Integer>, String> cellAndText = new HashMap<>();
for (int r = 0; r < numRows; r++) {
XWPFTableRow tableRow = table.getRow(r);
int cols = 0;
int mergeEndCols = 0;
boolean isMergeCols = false;
List<Integer> removeCellIndex = new ArrayList<>();
for (int c = 0; c < maxCols; c++) {
XWPFTableCell cell = tableRow.getCell(c);
if (cell != null) {
// 如果已经被行合并填过,则跳过
if (cellAndText.containsKey(Arrays.asList(r, c))) {
CTTcPr tcPr2 = cell.getCTTc().isSetTcPr() ? cell.getCTTc()
.getTcPr() : cell.getCTTc().addNewTcPr();
tcPr2.addNewVMerge().setVal(STMerge.CONTINUE);
continue;
}
// 如果处于前置的列合并范围,则删除然后跳过
if (isMergeCols && c < mergeEndCols) {
removeCellIndex.add(c);
continue;
}
// 读取的HTML表格数据
Elements selects = rows.get(r).select("th,td");
org.jsoup.nodes.Element element = selects.get(cols);
cols++;
// 设置填充内容水平居中
cell.setVerticalAlignment(XWPFTableCell.XWPFVertAlign.CENTER);
XWPFParagraph para = cell.getParagraphs().get(0);
para.setAlignment(ParagraphAlignment.CENTER);
XWPFRun run = para.createRun();
run.setText(element.text());
// 处理列合并
CTTcPr tcPr = cell.getCTTc().isSetTcPr() ? cell.getCTTc().getTcPr() : cell.getCTTc()
.addNewTcPr();
CTTblWidth tcW = tcPr.isSetTcW() ? tcPr.getTcW() : tcPr.addNewTcW();
// 设置列宽度
if (r == 0) {
Elements colgroup = htmlTable.select("colgroup");
if (!colgroup.isEmpty()) {
String width = colgroup.select("col").get(c).attr("style");
if (width.contains("%")) {
int widthPercent = Integer.parseInt(width.replace("%", "")
.replace("width:", "").replace(" ", ""));
tcW.setW(BigInteger.valueOf((long) PAGE_WIDTH_TWIPS / 100 * widthPercent));
tcW.setType(STTblWidth.DXA);
}
} else {
tcW.setW(BigInteger.valueOf(PAGE_WIDTH_TWIPS / maxCols));
tcW.setType(STTblWidth.DXA);
}
}
if (element.hasAttr("colspan")) {
int colspan = Integer.parseInt(element.attr("colspan"));
mergeEndCols = c + colspan;
tcPr.addNewGridSpan().setVal(BigInteger.valueOf(colspan));
isMergeCols = true;
} else {
mergeEndCols++;
isMergeCols = false;
}
// 处理行合并
if (element.hasAttr("rowspan")) {
int rowspan = Integer.parseInt(element.attr("rowspan"));
tcPr.addNewVMerge().setVal(STMerge.RESTART);
int nextRowNum = r + rowspan - 1;
List<Integer> cellLocation = Arrays.asList(nextRowNum, c);
String nextCellText = element.text();
cellAndText.put(cellLocation, nextCellText);
}
}
}
// 删除被行合并的单元格(列合并是由不同行的同列单元格的<w:vMerge w:val="restart"/> <w:vMerge/>控制)
removeCellIndex = removeCellIndex.stream().sorted().collect(Collectors.toList());
Collections.reverse(removeCellIndex);
removeCellIndex.forEach(tableRow::removeCell);
}
// 5、把表格插到书签所在段落的兄弟节点中(而非段落内)
CTTbl ctTbl = table.getCTTbl();
Node tblNode = ctTbl.getDomNode();
// paragraphNode 是 <w:p>,其父是 <w:body>
Node insertBefore = paragraphNode.getNextSibling();
if (insertBefore != null) {
bodyNode.insertBefore(tblNode, insertBefore);
} else {
bodyNode.appendChild(tblNode);
}
}
}
}
}
}
}
// 三、delete书签的处理(适用所有内容)
// 如果没有传入删除书签,则删除所有删除书签的内容
if(CollectionUtils.isEmpty(deleteBookmarks)){
deleteBookmarks = new ArrayList<>();
NodeList childNodes = bodyNode.getChildNodes();
for (int i = 0; i < childNodes.getLength(); i++) {
Node childNode = childNodes.item(i);
String nodeName = childNode.getNodeName();
if (nodeName.equals("w:bookmarkStart")) {
String nodeValue = childNode.getAttributes().getNamedItem("w:name").getNodeValue();
if (nodeValue.startsWith("delete")) {
deleteBookmarks.add(nodeValue);
}
}
NodeList childNodes1 = childNode.getChildNodes();
for (int j = 0; j < childNodes1.getLength(); j++) {
Node childNode1 = childNodes1.item(j);
String nodeName1 = childNode1.getNodeName();
if (nodeName1.equals("w:bookmarkStart")) {
String nodeValue = childNode1.getAttributes().getNamedItem("w:name").getNodeValue();
if (nodeValue.startsWith("delete")) {
deleteBookmarks.add(nodeValue);
}
}
}
}
}
for (String bookmark : deleteBookmarks) {
// 书签范围内完整的P标签
List<Node> inBookmarkRangePNodes = new ArrayList<>();
// 书签范围内除了完整的P标签之外,到结束标签为止,额外多余的P标签子节点(如果书签跨p,则从第0个子节点计算,不包含结束书签;如果书签不跨p,则包含起始书签,不包含结束书签)
List<Node> inBookmarkRangeExtraPChildNodes = new ArrayList<>();
isBookmarkEnd = getBookmarkSartAndEndRangeNodes(bodyChildNodes, bookmark,
replaceBookmarkAndValue.get(bookmark), inBookmarkRangeExtraPChildNodes,
inBookmarkRangePNodes);
// 待其他书签操作结束后,再进行删除操作(特别注意,书签最好独立分开打,不要存在需要同时处理的内容)
if (isBookmarkEnd) {
// body删除p节点
for (Node node : inBookmarkRangePNodes) {
bodyNode.removeChild(node);
}
// p删除子节点(无需移除段落样式,其他书签【可能是标题链接】)
for (int i = 0; i < bodyChildNodes.getLength(); i++) {
Node bodyChildNode = bodyChildNodes.item(i);
for (Node pChildNode : inBookmarkRangeExtraPChildNodes) {
if (pChildNode.getParentNode() == bodyChildNode && !pChildNode.getNodeName()
.equals("w:pPr") && !pChildNode.getNodeName().equals("w:bookmarkStart")) {
bodyChildNode.removeChild(pChildNode);
}
}
}
}
}
// 保存文件
try (OutputStream os = Files.newOutputStream(Paths.get(DOWNLOAD_FILE_PATH))) {
docx.write(os);
}
docx.close();
log.info("处理文档成功");
} catch (Exception e) {
log.error("处理文档异常", e);
}
}
/**
* 在书签范围内的额外的p子节点中,除了替换的第一个内容以外,删除书签之间的其他内容
* @param bodyChildNodes body的子节点
* @param inBookmarkRangeExtraPChildNodes 书签范围内的额外的p子节点
*/
private void deleteExtraPChildNodes(NodeList bodyChildNodes, List<Node> inBookmarkRangeExtraPChildNodes) {
// 1、收集待删除的节点(特别注意,待删除的节点必须首先通过集合匹配收集,然后再循环删除.如果在匹配过程中直接删除,则会影响循环的集合的元素,导致删除异常)
List<Node> toRemoveNodes = new ArrayList<>();
for (int i = 0; i < bodyChildNodes.getLength(); i++) {
Node bodyChildNode = bodyChildNodes.item(i);
NodeList childNodes = bodyChildNode.getChildNodes();
boolean findtarget = false;
for (int j = 0; j < childNodes.getLength(); j++) {
Node childNode = childNodes.item(j);
for (Node pChildNode : inBookmarkRangeExtraPChildNodes) {
if (pChildNode == childNode) {
// 第一个找到的wr即替换的内容,不做删除
if (childNode.getNodeName().equals("w:r")) {
if(findtarget){
toRemoveNodes.add(childNode);
}
findtarget = true;
}
}
}
}
// 只有额外p子节点时,在某个p匹配到后,则无需循环其他p节点了
if (findtarget) {
break;
}
}
// 2、循环删除多余节点
for (int i = 0; i < bodyChildNodes.getLength(); i++) {
Node bodyChildNode = bodyChildNodes.item(i);
for (Node toRemoveNode : toRemoveNodes) {
if (toRemoveNode.getParentNode() == bodyChildNode) {
bodyChildNode.removeChild(toRemoveNode);
}
}
}
}
/**
* 获取书签范围内完整的P标签,和到结束标签为止额外多余的P标签子节点
* @param bodyChildNodes body节点的子节点
* @param bookmark 目标书签名
* @param bookmarkValue 待替换的内容(当书签为replace时)
* @param inBookmarkRangeExtraPChildNodes 额外p标签子节点(如果书签跨p,则从第0个子节点计算,不包含结束书签;如果书签不跨p,则包含起始书签,不包含结束书签)
* @param inBookmarkRangePNodes 书签范围内完整的P标签
* @return 书签结束标签是否已找到
*/
private boolean getBookmarkSartAndEndRangeNodes(NodeList bodyChildNodes, String bookmark, String bookmarkValue,
List<Node> inBookmarkRangeExtraPChildNodes, List<Node> inBookmarkRangePNodes) {
boolean isBookmarkEnd;
boolean startRevord = false;
isBookmarkEnd = false;
Node startPNode = null;
int continueIndex = 0;
String bookmarkStartId = "";
boolean hasReplace = false;
for (int j = 0; j < bodyChildNodes.getLength(); j++) {
Node bodyChildNode = bodyChildNodes.item(j);
if (!startRevord) {
if (bodyChildNode.getNodeName().equals("w:bookmarkStart")) {
String bookmarkName = bodyChildNode.getAttributes().getNamedItem("w:name")
.getNodeValue();
if (bookmark.equals(bookmarkName)) {
bookmarkStartId = bodyChildNode.getAttributes().getNamedItem("w:id")
.getNodeValue();
}
String bookmarkStartId1 = bodyChildNode.getAttributes().getNamedItem("w:id")
.getNodeValue();
if (bookmarkStartId.equals(bookmarkStartId1)) {
startRevord = true;
startPNode = bodyChildNode;
}
} else if (bodyChildNode.getNodeName().equals("w:p")) {
NodeList pChildNodes = bodyChildNode.getChildNodes();
for (int k = 0; k < pChildNodes.getLength(); k++) {
Node pChildNode = pChildNodes.item(k);
if (pChildNode.getNodeName().equals("w:bookmarkStart")) {
String bookmarkName = pChildNode.getAttributes().getNamedItem("w:name")
.getNodeValue();
if (bookmark.equals(bookmarkName)) {
bookmarkStartId = pChildNode.getAttributes().getNamedItem("w:id")
.getNodeValue();
}
String bookmarkStartId1 = pChildNode.getAttributes().getNamedItem("w:id")
.getNodeValue();
if (bookmarkStartId.equals(bookmarkStartId1)) {
startRevord = true;
startPNode = bodyChildNode;
continueIndex = k;
break;
}
}
}
}
}
if (startRevord) {
// 如果与标志开始的p属于同一p,则接着坐标处理,否则新p从头处理
if (bodyChildNode.getNodeName().equals("w:p")) {
NodeList pChildNodes = bodyChildNode.getChildNodes();
int k = 0;
if (bodyChildNode == startPNode) {
k = continueIndex;
}
for (int x = k; x < pChildNodes.getLength(); x++) {
Node pChildNode = pChildNodes.item(x);
// 替换书签的赋值处理,只做一次替换
if(!hasReplace){
if (pChildNode.getNodeName().equals("w:r")) {
NodeList rChildNodes = pChildNode.getChildNodes();
for (int z = 0; z < rChildNodes.getLength(); z++) {
if (rChildNodes.item(z).getNodeName().equals("w:t")) {
rChildNodes.item(z).getChildNodes().item(0).setNodeValue(bookmarkValue);
hasReplace = true;
}
}
}
}
if (pChildNode.getNodeName().equals("w:bookmarkEnd")) {
String bookmarkEndId = pChildNode.getAttributes().getNamedItem("w:id")
.getNodeValue();
if (bookmarkStartId.equals(bookmarkEndId)) {
isBookmarkEnd = true;
break;
}
}
inBookmarkRangeExtraPChildNodes.add(pChildNode);
}
} else if (bodyChildNode.getNodeName().equals("w:bookmarkEnd")) {
String bookmarkEndId = bodyChildNode.getAttributes().getNamedItem("w:id").getNodeValue();
if (bookmarkStartId.equals(bookmarkEndId)) {
isBookmarkEnd = true;
}
}
// 如果当前P段落内不存在结束书签,则清空子节点保存,并且删除节点集合增加当前P段落节点
if (!isBookmarkEnd) {
inBookmarkRangeExtraPChildNodes.clear();
inBookmarkRangePNodes.add(bodyChildNode);
}
}
if (isBookmarkEnd) {
break;
}
}
return isBookmarkEnd;
}总结
通过POI处理书签进行内容的增删改,实际就是基于OOXML结构,通过POI进行高级或低级操作,以识别书签标签并进行内容的处理
三、额外补充
1、结合AI的落地应用
可以通过低代码开发平台创建工作流任务,通过 AI 模型根据不同的业务提纲(章节大纲、关键点清单)批量生成文案、数据分析结论、图表解读等“内容片段”。每个生成单元都可以看作是一段需要插入到模板中的内容、并且带有自己书签标识。然后维护一个标准化的 Word 模板,里面预先放置好按结构划分的书签,占位符既标记“标题”“正文”“表格”“图片”所处的位置,也约定了样式(字体、段落、缩进)。将上述对书签的处理发布为接口工具,在工作流中以供调用,最终生成word文档。但是需要注意模型生成内容具有不稳定性并且可能存在幻觉,因此可能需要增加人工校验环节以提高准确性,另外生成内容基本是md格式的内容,如果包含表格,需要使用HTML的表格才能保留行列合并,如果工作流平台是dify且生成内容包含图片,在书签的处理代码中需要根据图片url结合dify存储位置获取真实的图片流进行插入。
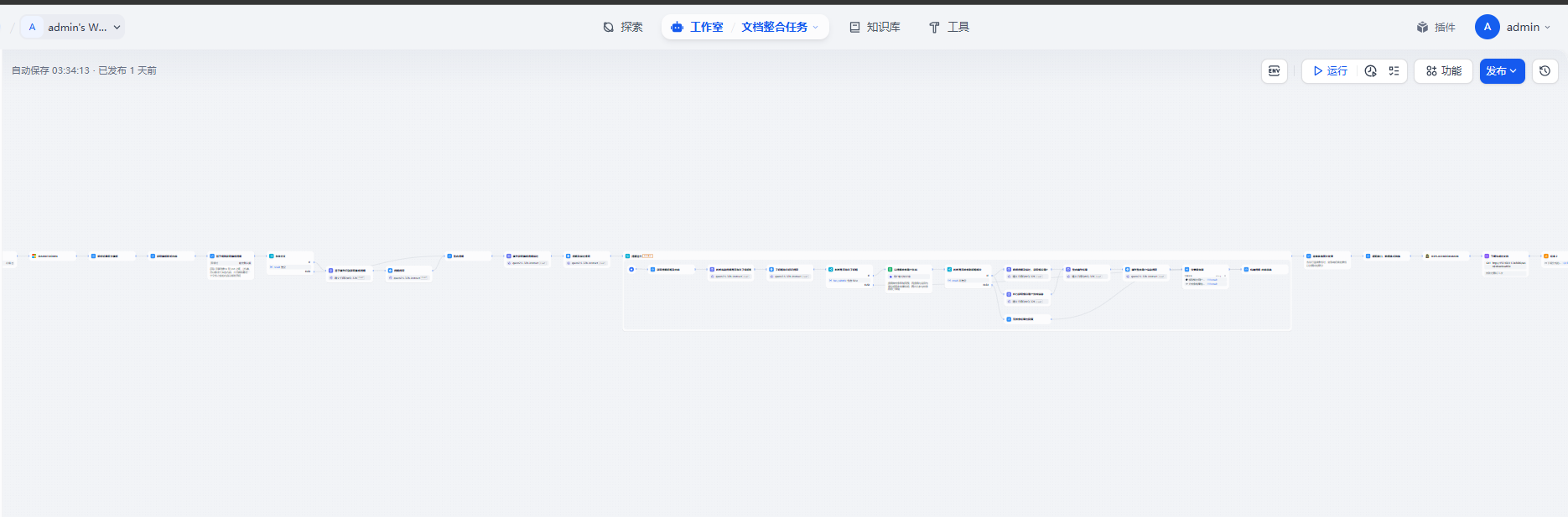
工作流的核心思路是,提取提纲及描述,然后根据提纲检索根据描述筛选,最终再进行数据结构整合,然后调用书签处理工具生成word