五、文件
CSV
Comma-Separated Value,逗号分割值。CSV文件以纯文本形式存储表格数据(数字和文本)。
CSV记录间以某种换行符分隔,每条记录由字段组成,字段间以其他字符或字符串分割,最常用逗号或制表符。
CSV文件第一行为表头,数据之间用逗号分割。
读取
import csv
import sys
input_file = 'D:/pythoncode/aiSelf/supplier_data.csv'
output_file = 'D:/pythoncode/aiSelf/supplier_data2.csv'
with open(input_file, 'r', newline='') as filereader:
with open(output_file, 'w', newline='') as filewriter:
header = filereader.readline()
header = header.strip()
header_list = header.split(',')
print(header_list)
filewriter.write(','.join(map(str, header_list))+'\n')
for row in filereader:
row = row.strip()
row_list = row.split(',')
print(row_list)
filewriter.write(','.join(map(str, row_list))+'\n')筛选特定行
import csv
import sys
input_file = 'D:/pythoncode/aiSelf/supplier_data.csv'
output_file = 'D:/pythoncode/aiSelf/supplier_data2.csv'
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
year = int(str(row_list[0]).strip())
cost = int(str(row_list[-1]).strip('$').replace(',',''))
if year > 2020 and cost < 5000:
filewriter.writerow(row_list)
筛选特定行
import csv
import sys
import re
input_file = 'D:/pythoncode/aiSelf/supplier_data.csv'
output_file = 'D:/pythoncode/aiSelf/supplier_data3.csv'
pattern = re.compile(r'(a2.*)')
with open(input_file, 'r', newline='', encoding='utf-8') as csv_in_file:
with open(output_file, 'w', newline='', encoding='utf-8') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
invoice_number = row_list[2]
if pattern.search(invoice_number):
filewriter.writerow(row_list)统计文件数与文件中行列数
import csv
import glob
import os
import string
import sys
pa = 'D:/pythoncode/aiSelf'
file_counter = 0
for input_file in glob.glob(os.path.join(pa,'p11*')):
row_counter = 1
with open(input_file,'r',newline='',encoding='utf-8') as csvfile:
filereader = csv.reader(csvfile)
header = next(filereader)
for row in filereader:
row_counter += 1
print('{0:s}:\t{1:d} rows \t {2:d} columns'.format(\
os.path.basename(input_file),row_counter,len(header)))
file_counter += 1
print('文件数量:{0:d}'.format(file_counter))
CSV文件数据统计
import csv
import glob
import os
import string
import sys
input_path = 'D:/pythoncode/aiSelf'
output_path = 'D:/pythoncode/aiSelf/output.txt'
output_header_list = ['file_name','total_sales','average_sales']
csv_out_file = open(output_path, 'a', newline='')
filewriter = csv.writer(csv_out_file)
filewriter.writerow(output_header_list)
for input_file in glob.glob(os.path.join(input_path, 'instruments*.csv')):
with open(input_file, 'r', newline='', encoding='utf-8') as csv_in_file:
filereader = csv.reader(csv_in_file)
output_list = []
output_list.append(os.path.basename(input_file))
header = next(filereader)
total_sales = 0.0
number_of_sales = 0.0
for row in filereader:
sale_amount = row[4]
total_sales += float(str(sale_amount).strip('$').replace(',',''))
number_of_sales += 1.0
average_sales = '{0:.2f}'.format(total_sales/number_of_sales)
output_list.append(total_sales)
output_list.append(average_sales)
filewriter.writerow(output_list)
csv_out_file.close()
Excel文件
Python处理Excel需导入xlrd和xlwt两个扩展包。
查看工作簿信息
import sys
from xlrd import open_workbook
input_file = 'D:/pythoncode/aiSelf/instruments_1.xls'
workbook = open_workbook(input_file)
print('工作簿数量:',workbook.nsheets)
for worksheet in workbook.sheets():
print('工作簿名字:', worksheet.name, '\tRows:', worksheet.nrows, '\tColumns:', worksheet.ncols)
筛选满足一定条件的行
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = 'D:/pythoncode/aiSelf/instruments_2.xls'
output_file = 'D:/pythoncode/aiSelf/p128shujufenxi356.xls'
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('Sheet1')
sale_amount_column_index = 3
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('instruments_2')
data = []
header = worksheet.row_values(0)
data.append(header)
for row_index in range(1, worksheet.nrows):
row_list = []
sale_amount = worksheet.cell_value(row_index,sale_amount_column_index)
if sale_amount > 1500.0 and sale_amount < 4500.0:
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value, workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%Y/%m/%d')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index, output_list in enumerate(data):
for element_index, element in enumerate(output_list):
output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)一组工作表的处理
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = 'D:/pythoncode/aiSelf/instruments_2.xls'
output_file = 'D:/pythoncode/aiSelf/p129shujufenxi357.xls'
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('Sheet1')
my_sheets = [0,1]
threshold = 3000.0
sales_column_index = 3
first_worksheet = True
with open_workbook(input_file) as workbook:
data = []
for sheet_index in range(workbook.nsheets):
if sheet_index in my_sheets:
worksheet = workbook.sheet_by_index(sheet_index)
if first_worksheet:
header_row = worksheet.row_values(0)
data.append(header_row)
first_worksheet = False
for row_index in range(1,worksheet.nrows):
row_list = []
sale_amount = worksheet.cell_value(row_index, sales_column_index)
if sale_amount > threshold:
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index, column_index)
cell_type = worksheet.cell_type(row_index, column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value, workbook.datemode)
date_cell = date(*date_cell[0:3].strftime('%Y%m%d'))
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index, output_list in enumerate(data):
for element_index, element in enumerate(output_list):
output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)多个工作簿的处理
六、Python标准库
数据处理的Numpy、Pandas和数据可视化的Matplotlib详见数据分析1。
datetime模块
| 常用类 | 说明 |
| date | 日期类。包括year、month、day属性 |
| time | 时间类。包括hour、minute、second、microsecond属性 |
| datetime | 时间日期类。 |
| timedelta | 时间间隔类。表示两个date、time、datetime实例之间的时间间隔 |
| tzinfo | 时区类。 |
from datetime import date
date类
date类包含对日期数据进行操作和格式化的方法。
格式化日期
| 方法 | 功能 |
| isoformat() | 返回符合ISO8601标准的YYYY-MM-DD |
| isocalender() | 返回包括三个值的元组,年份year,本年的第几周week number,weekday周一为1,周日为7 |
| isoweekday() | 返回ISO标准日期所在的星期几,周一为1,周日为7 |
| weekday() | 返回指定日期星期几,周一为0,周日为6 |
日期比较方法
| 方法 | 功能 |
| x.__eq__(y) | x是否等于y |
| x.__lt__(y) | x是否小于y |
| x.__le__(y) | x是否小于等于y |
| x.__gt__(y) | x是否大于y |
| x.__ge__(y) | x是否大于等于y |
| x.__ne__(y) | x是否不等于y |
计算日期差
| 方法 | 功能 |
| x.__sub__(y) | 计算x和y两个日期的差 |
| x.__rsub__(y) | 计算y和x两个日期的差 |
其他
| 方法 | 功能 |
| today() | 获取当前日期 |
| fromtimestamp() | 将时间戳转换为日期 |
datetime类
可以看作date类和time类的综合。它有一些专有方法。
| 方法 | 功能 |
| now() | 返回当前日期和时间 |
| date() | 返回当前日期和时间的日期部分 |
| time() | 返回当前日期和时间的时间部分 |
| combine(date对象,time对象) | 将date对象和time对象合并为datetime对象 |
时间转化与格式设置
时间对象转化为字符串用isoformat()方法。
字符串转化为时间对象用strptime()方法。
time对象
| 格式控制字符 | 说明 |
| %H | 24小时制小时数0-23 |
| %I | 12小时制小时数01-12 |
| %M | 分钟数00-59 |
| %S | 秒数00-59 |
| %p | 设置显示AM上午,PM下午 |
date对象和datetime对象
| 格式控制字符 | 说明 |
| %Y | 四位数年份0001-9999 |
| %y | 两位数年份01-99 |
| %m | 月份01-12 |
| %d | 日期01-31 |
from datetime import date
date1 = date(2025,5,1)
print(date1)
print(date1.year)
print(date1.month)
print(date1.day)from datetime import date
from datetime import datetime
date2 = date.today()
print(date2.strftime("%Y-%m-%d"))
datetime3 = datetime.now()
print(datetime3.strftime("%Y-%m-%d %H:%M:%S %p"))

math模块
数学常量:
| math.pi | 3.14159.. |
| math.e | 2.718.. |
| math.inf | 浮点正无穷大 |
| math.nan | 浮点非数字NaN值 |
数学函数:
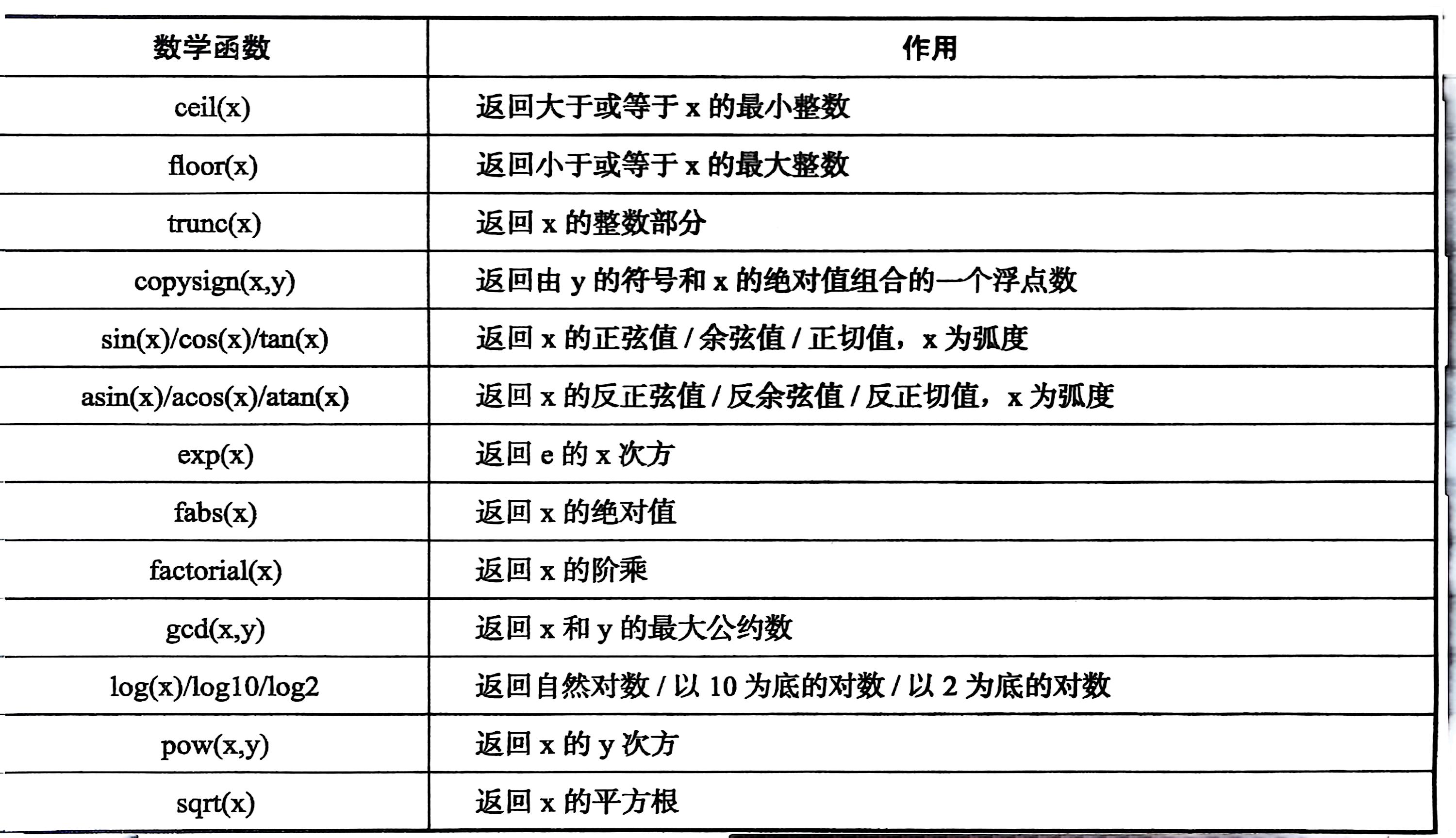
import math
print(math.ceil(3.5))
print(math.floor(3.5))
print(math.trunc(3.5))
print(math.log(math.e))random模块
import random
print('输出各种随机数')
print(random.random())
print(random.uniform(10,100))
print(random.randint(10,100))
print(random.randrange(10,100))
print(random.randrange(4,100,4))
print('返回序列中随机元素')
print(random.choice('wolf is very handsome'))
print(random.choice(['wolf', 'is', 'very', 'handsome']))
print(random.choice(('wolf', 'is', 'very', 'handsome')))
print('改变List中元素顺序')
list = ['wolf', 'is', 'very', 'handsome']
random.shuffle(list)
print(list)
print('随机种子')
random.seed(1)
print(random.random())
print(random.uniform(10,100))
print(random.randint(10,100))
print(random.randrange(10,100))
print(random.randrange(4,100,4))
如果指定种子,会使每次随机的结果相同
os模块
| os.name | 判断正在使用的平台 |
| os.environ | 查看系统环境变量 |
| os.listdir() | 指定所有目录中所有的文件名称和目录名称 |
| os.remove() | 删除指定文件 |
| os.rmdir() | 删除指定目录 |
| os.mkdir() | 创建目录 |
| os.path.isdir() | 判断指定对象是否为目录 |
| os.path.isfile() | 判断指定对象是否为文件 |
import os
if os.name == 'nt':
print('当前使用windows')
if os.name == 'posix':
print('当前使用Linux')
print('系统使用环境变量为', os.environ)
print(os.environ['HOMEPATH'])
path = '/pythoncode/'
for i in os.listdir(path):
print(i)
os.remove('D:/pythoncode/analyse/text804.txt')
print('文件删除完毕')
# os.removedirs('文件名')
# os.mkdir('一层的路径')
# os.path.isdir()用来判定对象是否为目录
# os.path.isfile()用来判定指定对象是否为文件
七、正则表达式
元字符
元字符是预先定义好的特殊字符,是用来描述其他字符的。
主要元字符
| \ | 转义符,表示转义 |
| . | 表示任意一个字符 |
| + | 表示重复1次或多次 |
| * | 表示重复0次或多次 |
| ? | 表示重复0次或1次 |
| | | 选择符号,或 |
| {} | 定义量词 |
| [] | 定义字符类 |
| () | 定义分组 |
| ^ | 表示取反,或匹配一行的开始 |
| $ | 匹配一行的结束 |
预定义字符
用于转义
| \n | 匹配换行符 |
| \r | 匹配回车符 |
| \f | 匹配一个换页符 |
| \t | 匹配一个水平制表符 |
| \v | 匹配一个垂直制表符 |
| \s | 匹配一个空格符,等价于[\t\n\r\f\v] |
| \S | 匹配一个非空格符,等价于[^\s] |
| \d | 匹配一个数字字符,等价于[0-9] |
| \D | 匹配一个非数字字符,等价于[^0-9] |
| \b | 匹配单词的开始或结束,单词的分布符为空格、标点符号或换行 |
| \w | 匹配任意语言的字符、数字或下划线等内容。若正则表达式标志设置为ASCII,则只匹配[a-zA-Z0-9] |
| \W | 等价于[^\w] |
例如匹配一个8位数字的电话号码,可以使用
\d\d\d\d\d\d\d\d
该方法还是比较繁琐的,可以使用下面这个正则表达式代替。
\d{8}
标记开始与结束
$结束,^开始
\w+@163.com$ 以163.com结尾
^\w+@163.com 以163.com开头
匹配一组字符
正则表达式中可以用字符类定义一组字符,其中任意一个字符出现在输入字符串中即匹配成功。需注意,每次只能匹配一个字符。
定义一组字符
需要中括号[]基本元字符
想要匹配python和Python
[pP]ython
对一组字符取反
^取反
想要匹配不是阿拉伯数字
[^1234567890]
使用区间简化一组字符的定义
-
想要匹配不是阿拉伯数字
[^0-9]
所有英文字母和数字
[A-Za-z0-9]
下面这个正则表达式是0-3和6-8,不是0-36
[0-36-8]
使用量词多次匹配
元字符只能匹配显示一次字符或字符串,想要匹配多次字符或字符串,应使用量词
常用量词
| ? | 出现0次或1次 |
| * | 出现0次或多次 |
| + | 出现1次或多次 |
| {n} | 出现n次 |
| {n,m} | 至少出现n次,但不超过m次 |
| {n,} | 至少出现n次 |
匹配八位数字的电话号码,不要再用8个\d了
\d{8}
颜色有color和colour
colou?r
贪婪和非贪婪匹配
关于重复的操作,需要注意正则表达式默认使用贪婪匹配方式。
贪婪匹配是只要符合条件就会尽可能多的匹配。
转换成非贪婪匹配只要在量词后加上?
\d{5,9}
\d{5,9}?
分组
在前面的例子中,量词只能重复显示一个字符,如果想让一个字符串作为整体使用量词对其进行重复匹配,可以使用圆括号(),分组。
(123){3}匹配123123123
123{3}只会对字符3重复匹配
使用re模块处理正则表达式
Python的re模块具有正则表达式的匹配功能。使用re模块前先导入
import rePython正则表达式的语法
Python中的正则表达式是作为模式字符串使用的,也就是两侧加单引号。
例如[^a-zA-Z]应写为
'[^a-zA-Z]'部分特殊含义字母应使用反斜杠\
或在模式字符串前加上大小写字母R或r,表示原生字符串
例如\bd\w*\b应写为
r'\bd\w*\b'
# 或
'\\bd\w*\\b'匹配字符串
re模块中的match()方法、search()方法、findall()方法用于字符串匹配
match()方法从字符串开始位置匹配,在开始位置匹配成功返回Match对象,否则返回None。
re.match(pattern模式字符串, string要匹配的字符串, [flags]可选可不选标志位用于控制匹配方式如是否区分字母大小写等)
import re
mystr = ['streetwolf', 'silverwolf', 'Streetsheep', 'streetcat', 'StreetMouse', 'streetfish']
p = r'street\w+'
for i in range(len(mystr)):
m = re.match(p, mystr[i], re.I)
if m:
print(mystr[i], '开始位置', m.start(), ',结束位置', m.end(), ',跨度', m.span(), ',匹配内容', m.string)
else:
print(mystr[i], '不匹配')
with open('telephonenumber.txt', 'r', encoding='utf-8') as f:
lst = f.readlines()
number = 0
for i in range(len(lst)):
p = re.match(r'17[01]\d{8}|000',lst[i])
if p:
number = number + 1
print(number)search()方法可以在整个字符串中查找,并返回第一个匹配内容,若找到一个则匹配对象,否则匹配None。
re.search(pattern模式字符串, string要匹配的字符串, [flags]可选可不选标志位用于控制匹配方式如是否区分字母大小写等)
findall()方法用于在整个字符串中搜索所有符合正则表达式的字符串,匹配成功以列表形式返回,否则返回空列表。
re.findall(pattern模式字符串, string要匹配的字符串, [flags]可选可不选标志位用于控制匹配方式如是否区分字母大小写等)
替换字符串
sub()方法实现字符串替换
re.sub(pattern模式字符串,repl替换的字符串,string原始字符串,count模式匹配后替换的最大次数默认0替换所有匹配,flags表示位控制匹配方式)
分割字符串
split()方法分割字符串,返回列表,与字符串对象的split()方法类似
re.split(pattern,string,[maxsplit]最大拆分次数,[flags])

![[6-2] 定时器定时中断定时器外部时钟 江协科技学习笔记(41个知识点)](https://i-blog.csdnimg.cn/direct/d52834fa1bd94a1097387d25a62bee06.png)




![[免费]微信小程序医院预约挂号管理系统(uni-app+SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】](https://i-blog.csdnimg.cn/direct/6e930f3dde3c4f2bb9cf4501c8642e1c.jpeg)


