本文主要介绍使用python快速整理工程中的中文字符,为app国际化提供便利。
1. 查找Android工程中的所有中文字符串(find_chinese.py)
import os
import re
import argparse
def is_comment_line(line, file_ext):
"""
判断一行是否是注释
:param line: 代码行
:param file_ext: 文件扩展名
:return: 是否是注释行
"""
line = line.strip()
if not line:
return True
# 根据不同文件类型判断注释
if file_ext in {'.java', '.kt', '.gradle', '.kts'}:
return line.startswith('//') or line.startswith('/*') or line.endswith('*/') or line.startswith('/**')or line.startswith('*')
elif file_ext in {'.xml', '.html'}:
return line.startswith('<!--') or '<!--' in line
elif file_ext == '.py':
return line.startswith('#')
return False
def remove_xml_comments(content):
"""移除XML文件中的注释"""
return re.sub(r'<!--.*?-->', '', content, flags=re.DOTALL)
def remove_java_comments(content):
# 移除多行注释
content = re.sub(r'/\*\*(?:[^*]|\*(?!/))*\*/', '', content, flags=re.DOTALL)
# 移除单行注释
content = re.sub(r'//.*', '', content)
return content
def is_log_statement(line):
"""
判断是否是Log或Debug开头的日志语句
"""
line = line.strip()
return line.startswith(('Log.', 'LogUtils.', 'DebugLog.'))
def remove_code_comments(content, file_ext):
if file_ext in {'.java', '.kt', '.gradle', '.kts'}:
return remove_java_comments(content)
# 移除多行注释
#content = re.sub(r'/\*\*(?:[^*]|\*(?!/))*\*/', '', content, flags=re.DOTALL)
# 移除单行注释
#content = re.sub(r'//.*', '', content)
elif file_ext in {'.xml', '.html'}:
# 移除XML/HTML注释 <!-- ... -->
content = re.sub(r'<!--.*?-->', '', content, flags=re.DOTALL)
elif file_ext == '.py':
# 移除Python注释
content = re.sub(r'#.*', '', content)
return content
def find_chinese_in_files(project_dir, output_file):
"""
扫描Android工程目录,找出非strings.xml文件中的中文内容
:param project_dir: Android工程根目录
:param output_file: 输出文件路径
"""
# 匹配中文字符的正则表达式
chinese_pattern = re.compile(r'[\u4e00-\u9fa5]+')
# 排除的目录
# excluded_dirs = {'.git', '.idea', 'build', 'gradle', 'libs', 'assets', 'bin', 'gen', 'captures'}
excluded_dirs = {'.git', '.idea', 'build', 'gradle', 'libs', 'assets', 'bin', 'gen', 'captures',
'.gradle', '.kts', '.py', '.html', '.js', '.ts', '.json', '.txt'}
# 排除的文件类型
excluded_exts = {'.png', '.jpg', '.jpeg', '.gif', '.webp', '.ico', '.svg',
'.mp3', '.wav', '.ogg', '.mp4', '.avi', '.mkv',
'.pdf', '.doc', '.docx', '.xls', '.xlsx',
'.jar', '.aar', '.so', '.keystore', '.pro', '.iml', '.dex','.txt'}
# 需要检查的文件类型
included_exts = {'.xml', '.java', '.kt'}
# included_exts = {'.xml', '.java', '.kt', '.gradle', '.kts', '.py', '.html', '.js', '.ts', '.json', '.txt'}
with open(output_file, 'w', encoding='utf-8') as out_f:
for root, dirs, files in os.walk(project_dir):
# 跳过排除的目录
dirs[:] = [d for d in dirs if d not in excluded_dirs]
for file in files:
file_path = os.path.join(root, file)
rel_path = os.path.relpath(file_path, project_dir)
ext = os.path.splitext(file)[1].lower()
# 跳过strings.xml文件
if file == 'strings.xml':
continue
# 跳过排除的文件类型
if ext in excluded_exts:
continue
# 如果指定了包含的文件类型,跳过不在列表中的文件
if included_exts and ext not in included_exts:
continue
try:
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
found_chinese = []
for line_num, line in enumerate(lines, start=1):
original_line = line
line = line.strip()
# 跳过空行和注释行
if not line or is_comment_line(line, ext):
continue
# 预处理:移除注释内容
if ext == '.xml':
processed_line = remove_xml_comments(original_line)
else:
processed_line = remove_code_comments(original_line, ext)
# 如果预处理后为空,跳过
if not processed_line.strip():
continue
# 跳过空行和日志语句
if is_log_statement(processed_line):
continue
# 检查中文内容
matches = chinese_pattern.findall(processed_line)
if matches:
found_chinese.append({
'line_num': line_num,
'content': original_line.strip(),
'matches': matches
})
if found_chinese:
out_f.write(f"文件: {rel_path}\n")
for item in found_chinese:
# out_f.write(f"行号: {item['line_num']}\n")
out_f.write(f"内容: {item['content']}\n")
# out_f.write("找到的中文: " + ", ".join(item['matches']) + "\n")
out_f.write("-" * 50 + "\n")
out_f.write("\n")
except (UnicodeDecodeError, PermissionError):
# 跳过二进制文件或无权限文件
continue
except Exception as e:
print(f"处理文件 {file_path} 时出错: {str(e)}")
continue
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='扫描Android工程中的非strings.xml中文内容(排除注释,带行号)')
parser.add_argument('project_dir', help='Android工程根目录路径')
parser.add_argument('output_file', help='输出文件路径')
args = parser.parse_args()
find_chinese_in_files(args.project_dir, args.output_file)
print(f"扫描完成,结果已保存到 {args.output_file}")
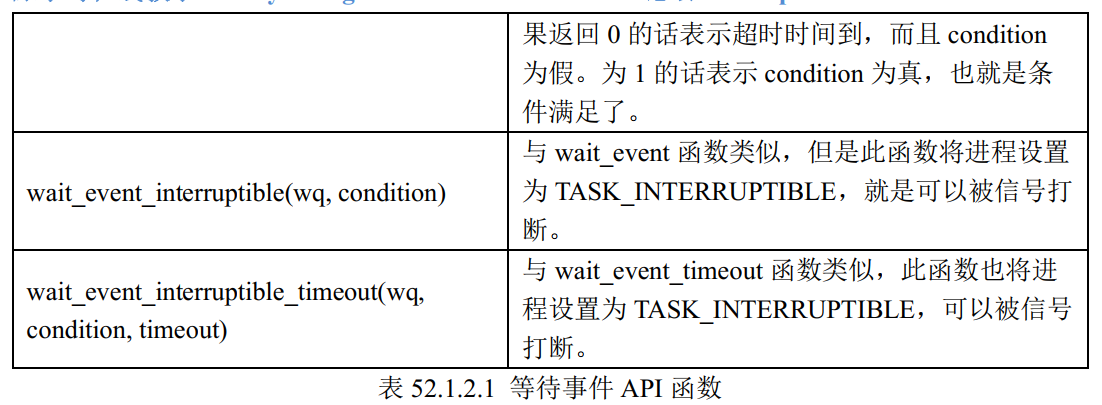
2. 将xml中的中文字符转成Execl表格输出(xml_to_excel.py)
import xml.etree.ElementTree as ET
import pandas as pd
def convert_xml_to_excel(xml_file, excel_file):
tree = ET.parse(xml_file)
root = tree.getroot()
data = []
for child in root:
if child.tag == 'string':
data.append({
'name': child.attrib['name'],
'value': child.text if child.text else ''
})
df = pd.DataFrame(data)
df.to_excel(excel_file, index=False)
# 使用示例
convert_xml_to_excel('app/src/main/res/values/strings.xml', 'strings.xlsx')
3. 具体使用
3.1.将中文提取出来
python [find_chinese.py目录] [你的工程所在的目录] [生成的txt目录(如:c:\chinese_content.txt)]
3.2. 将string.xml 转成string.xlsx,在你工程目录下执行
python [xml_to_excel.py]