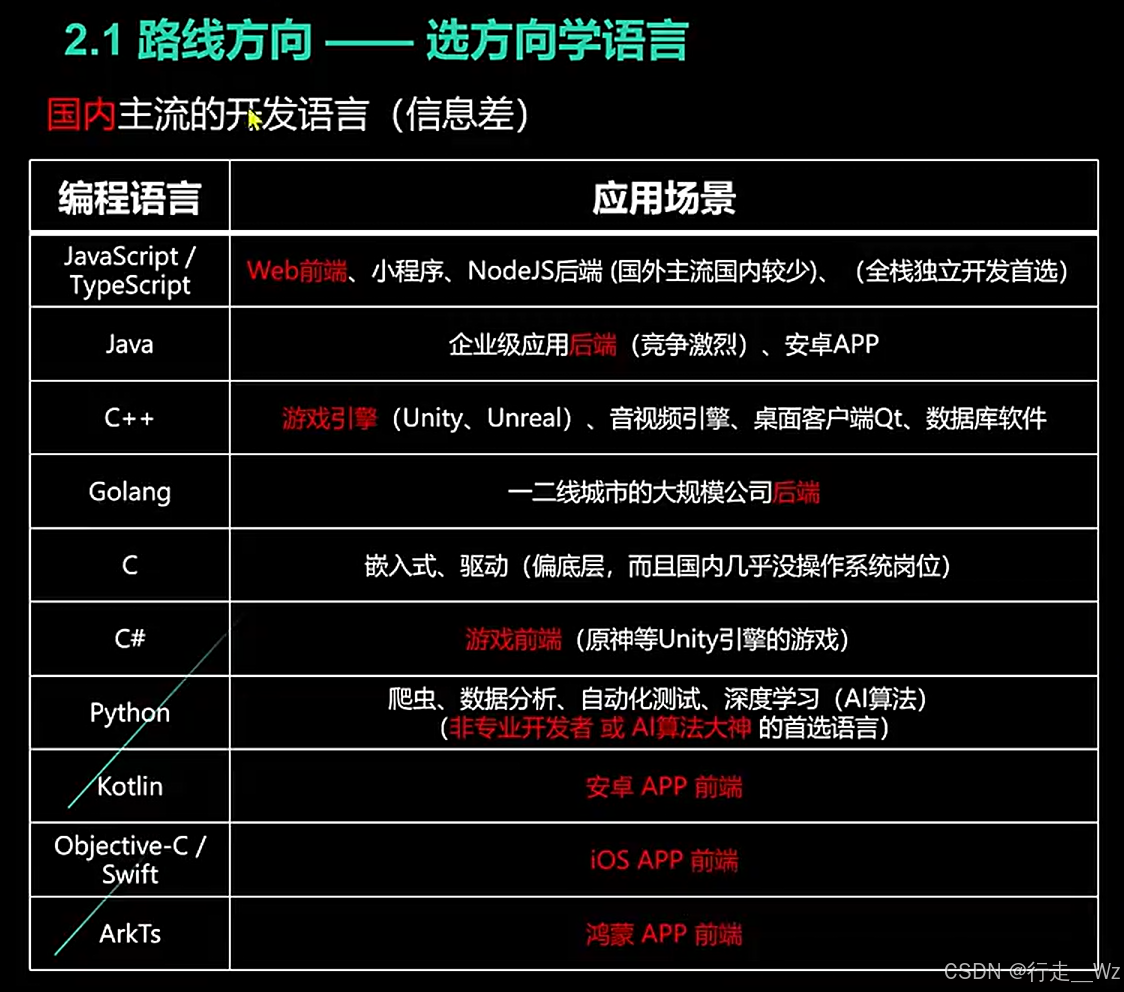
中间表达形式(IR):编译器的核心抽象层
1. IR的本质与作用
在编译原理的体系中,中间表达形式(Intermediate Representation, IR)是连接编译器前端与后端的桥梁。前端负责将源代码转换为IR,而后端则针对IR进行优化并生成目标代码。对于Java虚拟机的即时编译器(JIT)而言,其输入并非Java源代码,而是已经过静态编译的字节码。尽管字节码已剥离了高级语法糖并采用栈式计算模型,但直接将其作为优化基础仍存在局限——现代编译器依赖更适合优化的IR结构,其中最典型的便是静态单赋值(SSA)形式。
SSA IR的核心特性
静态单赋值:每个变量仅能被赋值一次,赋值后的变量不可修改。例如,传统代码中的y = 1; y = 2;在SSA中变为y1 = 1; y2 = 2;,确保每个值都有唯一的定义点。
数据流清晰化:通过唯一赋值的特性,编译器可轻松识别冗余赋值、死代码等问题。例如,未被使用的y1可直接删除,无需复杂的数据流分析。
优化友好性:SSA为常量折叠、强度削减等优化提供了理想的基础。例如,x = 4 * 1024可在编译期直接计算为x = 4096,消除运行时计算开销。
2. SSA中的Phi函数:处理控制流分支的关键
当程序存在条件分支时,不同路径对同一变量的赋值会导致后续使用时的歧义。SSA通过引入Phi函数(Φ函数)解决这一问题,该函数根据控制流的走向选择不同的变量版本。例如:
if (x > 0) {
y = 0;
} else {
y = 1;
}
x = y;在SSA中转换为:
x1 = ...;
if (x1 > 0) {
y1 = 0;
} else {
y2 = 1;
}
y3 = Phi(y1, y2); // 根据分支选择y1或y2的值
x2 = y3;Phi函数的引入确保了每个基本块出口处的变量值具有明确的定义,为后续的数据流分析和优化提供了统一的模型。
3. 从字节码到SSA IR的转换
Java字节码的栈式结构(如iload、istore指令)需要转换为基于寄存器的SSA形式。即时编译器首先构建控制流图(CFG),将每个字节码指令映射为IR节点,然后通过SSA转换算法(如GCC的ssa_opt pass)为每个变量生成唯一的版本,并在控制流交汇点插入Phi函数。这一过程并非简单的语法转换,而是结合语义分析消除歧义,例如处理异常跳转、同步块等复杂逻辑。
Sea-of-Nodes:HotSpot与Graal的IR革命
1. Sea-of-Nodes的设计哲学
HotSpot的C2编译器和GraalVM的Graal编译器采用了一种激进的SSA变体——Sea-of-Nodes IR。其核心思想是摒弃变量概念,直接以“值节点”为中心,每个节点代表一个计算结果或数据值,节点之间通过依赖关系连接,形成数据流图。
与传统SSA的区别
无变量名依赖:传统SSA仍保留变量名(如x1、y2),而Sea-of-Nodes中每个值由节点直接表示。例如,Phi(y1, y2)变为Phi(0, 1),其中0和1是具体的常量节点。
节点即值:每个计算(如加法、条件判断)都是一个节点,输入输出均为节点引用。这种设计使常量传播成为“无操作”——常量值直接作为节点存在,无需额外处理。
2. IR图的结构解析
以foo(int count)方法为例,其IR图包含以下关键元素:
-
固定节点:表示控制流的关键位置,如
Start(方法入口)、End(方法出口)、LoopBegin(循环起点)、If(条件判断)。 -
浮动节点:表示具体的计算或数据值,如
Phi节点(处理分支值合并)、+节点(加法运算)、P(n)节点(方法参数)。 -
控制流边:红色线条连接基本块,表示程序执行路径(如循环回边、条件跳转)。
-
数据流边:蓝色线条表示数据依赖,如
+节点依赖其操作数节点的值。
基本块与控制流关系
基本块是具有单一入口和出口的连续IR节点序列,其划分原则是:仅在分支指令(如if、goto)处终止。例如:
-
B0:包含方法入口和初始赋值(如sum = 0)。 -
B1:循环体的入口,包含循环条件判断(i < count)。 -
B2:循环体内部,执行sum += i并更新循环变量i。 -
B3:循环结束后的处理,如返回结果。
控制流关系通过基本块之间的跳转边表示。例如,B2执行完毕后,根据循环条件可能跳转回B1(继续循环)或进入B3(退出循环)。
3. 节点调度与依赖处理
在Sea-of-Nodes中,浮动节点的位置并非固定,需要通过节点调度算法确定其在基本块中的排列顺序,确保数据依赖和控制依赖得到满足:
数据依赖:节点A的输入依赖节点B的输出,A必须在B之后调度(如+节点依赖其操作数节点)。
控制依赖:条件判断节点(如If)的后续节点必须在其之后调度。
内存依赖:C2编译器显式记录内存读写的顺序依赖,而Graal通过固定节点(如内存访问操作)的顺序隐式处理,简化了调度逻辑。
Global Value Numbering(GVN):基于值的等价计算消除
1. GVN的核心思想
GVN是一种全局范围的公共子表达式消除(CSE)技术,其目标是识别并合并计算结果相同的节点,避免冗余计算。在Sea-of-Nodes中,每个节点代表一个唯一的值,GVN通过比较节点的类型和输入参数,判断是否为等价计算。
与传统CSE的区别
-
值比较而非语法比较:CSE依赖词法分析判断表达式是否相同(如
a * b和b * a可能被视为不同),而GVN通过语义等价性判断(结合交换律等数学性质),能识别更多等价情况。 -
全局作用域:GVN在整个IR图中搜索等价节点,而非局限于单个基本块,因此能消除跨块的冗余计算。
2. GVN的实现步骤
以代码sum = a * b; if (a > 0) sum += a * b; if (b > 0) sum += a * b;为例:
-
构建IR图:三次
a * b运算生成三个*节点(假设a和b的值未变化)。 -
节点匹配:GVN算法检测到这三个
*节点的输入参数(a和b节点)完全相同,且无内存副作用(如修改全局变量)。 -
节点合并:将三个节点合并为一个,后续引用直接指向该节点,消除重复计算。
3. 副作用处理与优化边界
GVN仅适用于无副作用的操作(如纯数学运算),对于涉及内存访问、I/O操作的节点(如array[i] = x),由于其结果可能依赖上下文,无法进行合并。即时编译器通过标记节点的副作用属性(如hasSideEffect标志)来避免错误合并,确保程序语义的正确性。
IR图的可视化与实践:以IGV工具为例
1. Ideal Graph Visualizer(IGV)简介
IGV是HotSpot C2和Graal编译器的官方IR可视化工具,支持实时查看编译过程中生成的IR图,帮助开发者理解优化细节。其主要功能包括:
-
节点层级展示:显示每个IR节点的类型、输入输出及依赖关系。
-
基本块划分:用不同颜色标注基本块,清晰呈现控制流结构。
-
优化过程追踪:观察GVN、循环展开等优化前后的IR变化。
2. 使用IGV的实践步骤
环境准备
JDK版本:Java 10+(需启用Graal编译器)。
工具下载:从OpenJDK官方仓库获取IGV,解压后运行bin/idealgraphvisualizer。
代码示例
以hash(Object input)方法为例,编译时添加参数生成IR输出:
java -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler
-XX:CompileCommand='print,CompilationTest.hash' CompilationTest可视化分析
-
节点搜索:通过方法名定位
hash方法的IR图,查看instanceof节点如何转换为类型检查节点。 -
Phi节点观察:在条件分支交汇处,查看
Phi节点如何合并不同路径的返回值。 -
GVN效果验证:对比优化前后的IR图,确认重复的
hashCode()调用是否被合并。
3. 常见IR节点解析
P(n)节点:表示方法的第n个参数,如P(0)为第一个参数input。
Iconst节点:表示常量值,如Iconst_0代表整数0。
Invoke节点:表示方法调用,如invokevirtual Object.hashCode()对应Invoke节点,输入为对象实例节点。
Sea-of-Nodes IR的优势与挑战
1. 优化能力的提升
激进优化支持:无变量名的设计使编译器能更自由地重排节点顺序,例如将循环不变量提升到循环外。
跨语言统一:GraalVM的Sea-of-Nodes IR支持多种语言(如Java、JavaScript、Rust)的编译,通过统一的节点模型实现跨语言优化。
2. 实现复杂度与性能平衡
节点爆炸问题:细粒度的节点划分可能导致IR图规模膨胀,增加内存占用和调度开销。C2通过节点合并策略(如常量折叠自动合并)缓解这一问题。
调试难度:IR节点与源代码的映射关系复杂,需借助-XX:PrintAssembly等工具结合反汇编结果定位问题。
3. 与硬件架构的协同
Sea-of-Nodes的数据流模型与现代CPU的超标量架构高度契合:
-
指令级并行:调度算法可将无依赖的节点分配到不同CPU核心并行执行。
-
寄存器分配:每个值节点天然适合寄存器分配,避免传统变量分配中的寄存器溢出问题。
总结
即时编译器的中间表达形式是连接高级语言与机器码的魔法桥梁。从SSA的严谨定义到Sea-of-Nodes的激进创新,从GVN的等价消除到IGV的可视化实践,每一项技术都凝聚着编译原理的智慧。掌握这些知识,不仅能让我们写出更易被JIT优化的代码,更能深入理解现代虚拟机的核心竞争力——这正是我们拆解Java虚拟机的终极目标。
1. IR设计的核心原则
抽象层分离:IR作为中间表示,隔离了前端的语法差异与后端的硬件特性,使编译器优化具有通用性。
优化导向:SSA和Sea-of-Nodes的设计目标是让编译器能高效实施各种优化,而非仅仅正确翻译代码。
2. 从理论到实践的桥梁
IR技术并非空中楼阁,而是实际应用于HotSpot、GraalVM等工业级JVM的核心技术。通过IGV工具,开发者可直观观察到这些技术如何将简单的Java代码转换为复杂的优化后机器码,理解“代码即数据”的编译哲学。
3. 未来发展方向
动态IR优化:结合运行时Profiling数据,动态调整IR节点的优化策略,如根据分支频率重排节点顺序。
AI驱动的IR分析:利用机器学习模型预测最优节点调度方案,进一步提升代码生成效率。
异构架构适配:针对GPU、NPU等异构设备,扩展Sea-of-Nodes模型以支持数据并行和任务并行的优化。