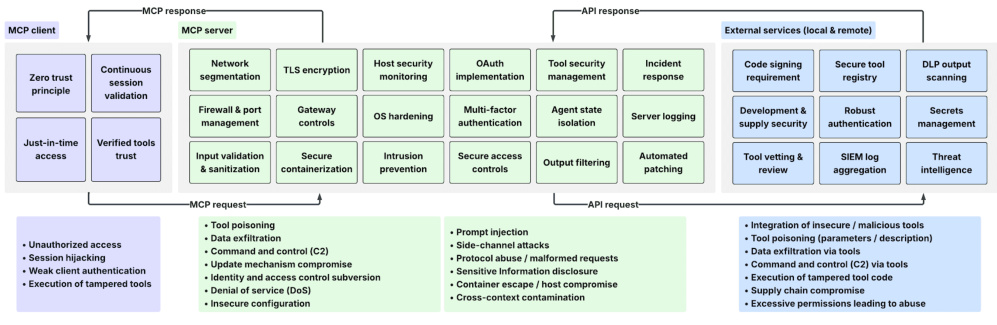
在自然语言处理(NLP)领域,文本情感分类是一项极具应用价值的任务。它能帮助企业分析用户反馈、社交媒体舆情监测等。本文将通过一段实际代码,带大家了解如何利用 PyTorch 框架和 TextRNN 模型,完成微博文本的情感分类工作,深入剖析代码背后的技术原理与实现细节。
一、环境配置与随机种子设置
import torch
import numpy as np
import load_dataset,TextRNN
from train_eval_test import train
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic=True首先导入必要的库,torch作为核心深度学习框架,提供张量运算、自动求导等功能;numpy用于数值计算。接着,通过判断系统是否支持 CUDA(NVIDIA GPU 加速)或 MPS(苹果设备的 Metal 加速),为模型和数据选择合适的运行设备,若都不支持则使用 CPU。
随机种子的设定是实验可重复性的关键。np.random.seed(1)、torch.manual_seed(1)等语句,确保每次运行代码时,随机数生成具有一致性。在模型初始化权重、数据打乱划分等随机操作中,固定的随机种子能保证结果可复现,方便对比不同实验设置的效果。
二、数据加载与处理
vocab, train_data, dev_data, test_data = load_dataset.load_dataset('simplifyweibo_4_moods.csv')
train_iter = load_dataset.DatasetIterater(train_data, 128, device)
dev_iter = load_dataset.DatasetIterater(dev_data, 128,device)
test_iter = load_dataset.DatasetIterater(test_data, 128,device)通过load_dataset.load_dataset函数加载simplifyweibo_4_moods.csv数据集,并将其划分为训练集、验证集和测试集,同时获取词汇表vocab。合理的数据划分是模型训练成功的基础,训练集用于模型参数学习,验证集辅助调整超参数、防止过拟合,测试集则评估模型的泛化能力。
DatasetIterater类负责将数据整理成模型可处理的迭代器形式。它将数据按批次(这里批次大小为 128)整理,并将数据移动到指定设备上。这种批量处理方式能充分利用设备的并行计算能力,加速训练过程,同时减少内存占用。
三、预训练词向量加载
embedding_pretrained = torch.tensor(np.load('embedding_Tencent.npz')["embeddings"].astype('float32'))
embed = embedding_pretrained.size(1) if embedding_pretrained is not None else 200代码尝试加载腾讯预训练的词向量文件embedding_Tencent.npz。预训练词向量蕴含了大量文本中的语义信息,使用预训练词向量能让模型在训练初期就具备一定的语义理解能力,减少对训练数据量的依赖,加快收敛速度。
若成功加载词向量,embed变量将设为词向量的维度;若加载失败,则默认词向量维度为 200。这种灵活的设置,使得模型在不同条件下都能正常运行。
四、模型构建与初始化
class_list = ['喜悦','愤怒','厌恶','低落']
num_classes=len(class_list)
model = TextRNN.Model(embedding_pretrained,len(vocab),embed,num_classes).to(device)定义情感类别列表class_list,包含 “喜悦”“愤怒”“厌恶”“低落” 四种情感,由此确定分类任务的类别数num_classes。
随后实例化TextRNN.Model模型,该模型接收预训练词向量、词汇表长度、词向量维度和类别数作为参数进行初始化。TextRNN 模型基于循环神经网络(RNN)结构,能够有效捕捉文本中的序列信息,适合处理具有上下文依赖的文本数据。最后将模型移动到指定设备上,为后续训练和推理做好准备。
五、模型训练与评估
train(model,train_iter, dev_iter, test_iter,class_list)调用train函数启动模型训练流程。该函数接收模型、训练数据迭代器、验证数据迭代器、测试数据迭代器和类别列表作为参数。在训练过程中,模型在训练集上进行前向传播、计算损失并反向传播更新参数;通过验证集监控模型性能,调整学习率、正则化系数等超参数;训练结束后,使用测试集对模型进行最终评估,得到准确率、精确率、召回率等指标,以此判断模型在实际应用中的效果。
总结与展望
本文通过对一段代码的详细解析,展示了基于 PyTorch 和 TextRNN 实现微博文本情感分类的全过程。从环境准备、数据处理,到模型构建与训练,每个环节都紧密相连。在实际应用中,我们可以进一步优化模型结构,如引入注意力机制;调整超参数;尝试不同的预训练词向量或预训练模型,以提升分类准确率。希望本文能为大家在 NLP 领域的学习和实践提供帮助,也欢迎大家在评论区交流探讨。