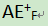Day 15
- 对鸢尾花数据集进行处理,特征可视化,贝叶斯优化随机森林,Shap解释
- 1. 导入必要的库
- 2. 设置中文字体
- 3. 加载数据集
- 4. 查看数据
- 5. 数据准备
- 6. 贝叶斯优化随机森林
- 7. 评估结果
- 8. 绘制箱形图
- 9. 绘制特征相关性热力图
- 10. SHAP模型解释
- 总结
对鸢尾花数据集进行处理,特征可视化,贝叶斯优化随机森林,Shap解释
完整代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.model_selection import train_test_split
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
iris = datasets.load_iris() # 加载鸢尾花数据集
# 将iris数据集转换为DataFrame
data = pd.DataFrame(data=np.c_[iris['data'], iris['target']],
columns=iris['feature_names'] + ['target'])
# 查看前5行数据
print(data.head())
# 数据准备
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 贝叶斯优化随机森林
from skopt import BayesSearchCV
from skopt.space import Integer
from sklearn.ensemble import RandomForestClassifier
# 定义搜索空间
search_space = {
'n_estimators': Integer(50, 200),
'max_depth': Integer(5, 30),
'min_samples_split': Integer(2, 10),
'min_samples_leaf': Integer(1, 4)
}
# 初始化贝叶斯优化
bayes_search = BayesSearchCV(
estimator=RandomForestClassifier(random_state=42),
search_spaces=search_space,
n_iter=50,
cv=5,
scoring='accuracy',
n_jobs=-1
)
# 执行优化
bayes_search.fit(X_train, y_train)
# 评估结果
best_model = bayes_search.best_estimator_
y_pred = best_model.predict(X_test)
print("\n最佳参数:", bayes_search.best_params_)
print("\n分类报告:")
print(classification_report(y_test, y_pred))
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
# 绘制前六个特征的箱形图
plt.figure(figsize=(15, 10))
features = data.columns[:6] # 获取前六个特征名
for i, feature in enumerate(features):
plt.subplot(2, 3, i+1) # 2行3列布局
sns.boxplot(data=data, y=feature)
plt.title(f'{feature} 箱形图')
plt.tight_layout() # 自动调整子图间距
plt.show()
# 绘制特征相关性热力图
plt.figure(figsize=(10, 8))
corr = data.corr()
sns.heatmap(corr, annot=True, cmap='coolwarm', center=0)
plt.title('特征相关性热力图')
plt.tight_layout()
plt.show()
# SHAP模型解释
import shap
# 初始化解释器
explainer = shap.TreeExplainer(best_model)
# 计算SHAP值
shap_values = explainer.shap_values(X_test)
# 特征重要条形图
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values, X_test, plot_type="bar", show=False)
plt.title("特征重要性条形图")
plt.tight_layout()
plt.show()
# 蜂巢图
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values, X_test, show=False)
plt.title("特征影响蜂巢图")
plt.tight_layout()
plt.show()
这段代码是一个完整的机器学习流程,包括数据加载、预处理、模型训练(使用贝叶斯优化的随机森林)、模型评估、结果可视化(箱形图、热力图、SHAP解释)等步骤。以下是对代码的详细解释:
1. 导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.model_selection import train_test_split
import seaborn as sns # 基于matplotlib的高级绘图库
import warnings
warnings.filterwarnings("ignore")
numpy:用于数学运算。pandas:用于数据处理和分析。matplotlib.pyplot:用于绘图。sklearn.datasets:用于加载数据集。sklearn.metrics:用于评估模型性能。sklearn.model_selection:用于数据分割。seaborn:用于绘制更美观的统计图形。warnings:用于忽略警告信息。
2. 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
- 设置Matplotlib的字体为黑体,以确保中文可以正常显示。
- 确保负号可以正常显示。
3. 加载数据集
iris = datasets.load_iris() # 加载鸢尾花数据集
data = pd.DataFrame(data=np.c_[iris['data'], iris['target']],
columns=iris['feature_names'] + ['target'])
- 使用
sklearn.datasets加载鸢尾花数据集。 - 将数据集转换为
pandas.DataFrame,方便后续操作。
4. 查看数据
print(data.head())
- 打印数据集的前5行,查看数据结构。
5. 数据准备
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- 将特征和目标变量分开。
- 使用
train_test_split将数据集分为训练集和测试集,测试集占20%。
6. 贝叶斯优化随机森林
from skopt import BayesSearchCV
from skopt.space import Integer
from sklearn.ensemble import RandomForestClassifier
search_space = {
'n_estimators': Integer(50, 200),
'max_depth': Integer(5, 30),
'min_samples_split': Integer(2, 10),
'min_samples_leaf': Integer(1, 4)
}
bayes_search = BayesSearchCV(
estimator=RandomForestClassifier(random_state=42),
search_spaces=search_space,
n_iter=50,
cv=5,
scoring='accuracy',
n_jobs=-1
)
bayes_search.fit(X_train, y_train)
- 使用
BayesSearchCV进行贝叶斯优化,优化随机森林的超参数。 - 定义搜索空间,包括
n_estimators(树的数量)、max_depth(树的最大深度)、min_samples_split(分裂内部节点所需的最小样本数)、min_samples_leaf(叶节点最小样本数)。 - 设置优化的迭代次数为50,交叉验证为5折,评分标准为准确率,使用所有可用的CPU核心。
7. 评估结果
best_model = bayes_search.best_estimator_
y_pred = best_model.predict(X_test)
print("\n最佳参数:", bayes_search.best_params_)
print("\n分类报告:")
print(classification_report(y_test, y_pred))
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
- 使用最佳模型对测试集进行预测。
- 打印最佳参数、分类报告和混淆矩阵,评估模型性能。
8. 绘制箱形图
plt.figure(figsize=(15, 10))
features = data.columns[:6] # 获取前六个特征名
for i, feature in enumerate(features):
plt.subplot(2, 3, i+1) # 2行3列布局
sns.boxplot(data=data, y=feature)
plt.title(f'{feature} 箱形图')
plt.tight_layout()
plt.show()
- 绘制前六个特征的箱形图,查看数据的分布情况。
9. 绘制特征相关性热力图
plt.figure(figsize=(10, 8))
corr = data.corr()
sns.heatmap(corr, annot=True, cmap='coolwarm', center=0)
plt.title('特征相关性热力图')
plt.tight_layout()
plt.show()
- 计算特征之间的相关性,并绘制热力图,查看特征之间的相关性。
10. SHAP模型解释
import shap
explainer = shap.TreeExplainer(best_model)
shap_values = explainer.shap_values(X_test)
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values, X_test, plot_type="bar", show=False)
plt.title("特征重要性条形图")
plt.tight_layout()
plt.show()
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values, X_test, show=False)
plt.title("特征影响蜂巢图")
plt.tight_layout()
plt.show()
- 使用SHAP(SHapley Additive exPlanations)对模型进行解释。
- 计算SHAP值,绘制特征重要性条形图和特征影响蜂巢图,直观展示特征对模型预测的影响。
总结
这段代码完整地展示了从数据加载、预处理、模型训练、优化、评估到结果可视化的流程。通过贝叶斯优化提升了随机森林的性能,并通过SHAP解释了模型的预测结果,使整个机器学习过程更加透明和可解释。
@浙大疏锦行