ICEdit-MoE-LoRA
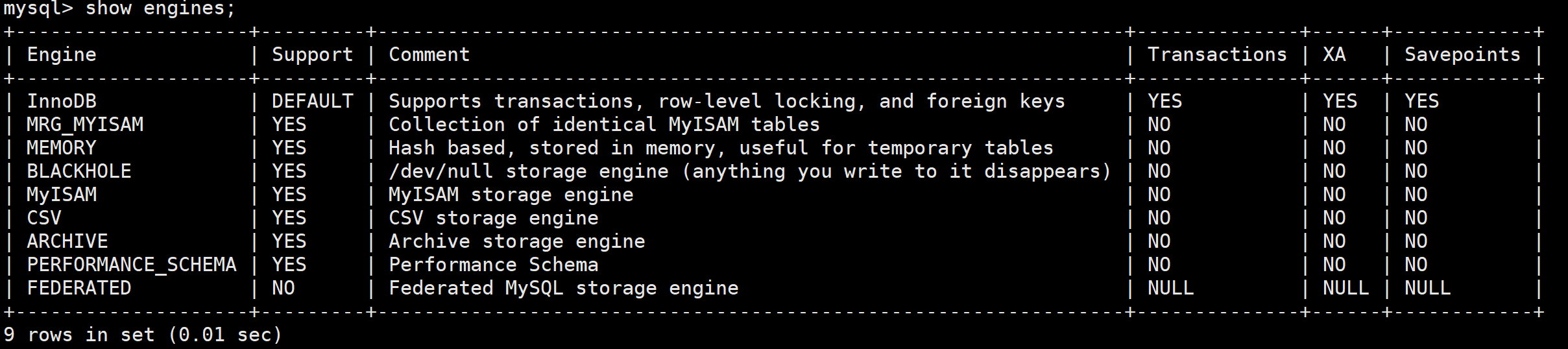
一、研究背景与目标
In-Context Edit 是一种新颖的基于指令的图像编辑方法,旨在实现与现有最佳方法相当甚至更优的编辑效果。传统图像编辑技术在处理复杂指令时存在一定局限性,尤其是在多轮编辑任务中,结果的准确性和连贯性难以保证。同时,许多高质量的图像编辑模型对硬件资源要求极高,训练和推理成本巨大,限制了其广泛应用。因此,该研究的目标是开发一种高效、低成本且易于使用的图像编辑方法,能够在有限的资源条件下达到优秀的编辑性能。
二、模型架构与方法
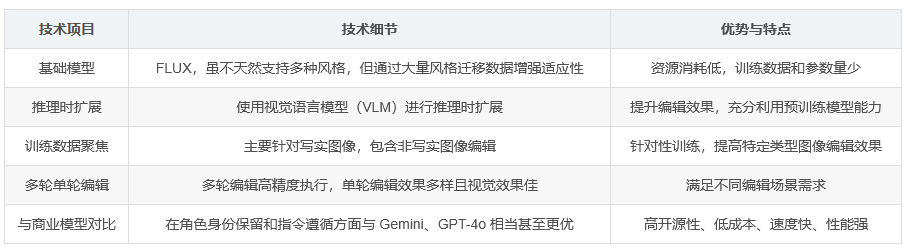
In-Context Edit 的基础模型是 FLUX。FLUX 本身并不天然支持多种风格,所以在训练数据集中包含大量风格迁移的内容,以增强模型在不同风格下的适应性。在训练过程中,研究者们采用了 0.5% 的训练数据和 1% 的参数量,相较于以往的最佳方法大幅降低了资源消耗。这种方法在一定程度上提高了模型的效率和泛化能力。
此外,该研究还提出了在推理时使用视觉语言模型(VLM)进行扩展的方法,以进一步提升图像编辑的效果。通过这种方法,可以在不大幅增加训练成本的情况下,充分利用预训练的视觉语言模型的强大能力,增强模型对图像内容的理解和编辑能力,使其能够更精准地根据指令完成各种复杂的编辑任务。
三、训练数据与效果
该模型的训练数据主要针对写实图像,所以在处理非写实图像(例如动漫或模糊图片)时,编辑的成功率会有所下降。在物体添加、颜色属性修改、风格迁移和背景更改等方面,该模型的成功率较高,但在物体移除方面成功率相对较低,这主要是由于 OmniEdit 移除数据集的质量不高所致。
四、实验与性能表现
实验表明,In-Context Edit 在多轮编辑任务中能够以高精度执行一系列操作,同时在单轮编辑中也能呈现出多样且令人印象深刻的视觉效果。与商业模型(如 Gemini 和 GPT-4o)相比,In-Context Edit 在角色身份保留和指令遵循方面表现相当甚至更优。它具有更高的开源性、更低的成本以及更快的处理速度(处理一张图像大约需要 9 秒),展现出强大的性能优势。
五、模型训练与推理资源
当前模型是在 4 块 A800 GPU 上训练的(总批次大小为 16)。未来,研究者们计划进一步扩充数据集并进行模型扩展,以发布更强大的模型版本。在推理时,编辑 512×768 的图像需要 35 GB 的 GPU 内存。对于 24 GB GPU 内存的系统(例如 NVIDIA RTX3090),可以添加“–enable-model-cpu-offload”参数来运行模型。如果本地下载了预训练权重,可以在推理过程中传递相应的参数,以确保模型正常工作。
六、使用方法与安装
在安装方面,首先需要创建并激活名为“icedit”的 Conda 环境,安装 Python 3.10 版本。然后,通过 pip 安装 requirements.txt 文件中列出的依赖项,并升级 Huggingface_hub。接着,下载预训练权重 Flux.1-fill-dev 和 ICEdit-MoE-LoRA。在进行图像编辑时,需要注意模型只能编辑宽度为 512 像素的图像,其他宽度的图像将自动调整为 512 像素。如果遇到模型未能生成预期结果的情况,可以通过改变“–seed”参数来尝试不同的结果。此外,还提供了 Gradio 演示,用户可以以更友好的方式编辑图像。
七、核心技术总结