任务
你想将一些数据做持久化处理,而且也想体验一下BerkeleyDB数据库的简洁和高效。
解决方案
如果以前在你的计算机中安装过 BerkeleyDB,Python标准库附带的bsddb包(以及可选的 bsddb3,用于访间Berkeley DBrelease 3.2数据库)可以被用来作为 Berkeley DB接口。为了得到 bsddb 或者 bsddb3,如果没有bsddb 的话,应当在 import 声明的时候使用 try/exception:
try:
from bsddb import db#先试试release 4
except ImportError:
from bsddb3 import db#没有,再试试release 3
print db.DB_VERSION_STRING
#输出,示例:sleepycat Software:Berkeley DB 4.1.25:(December 19,2002)
为了创建一个数据库,我们要初始化一个 db.DB 对象,然后向它的 open方法传入适当的参数并调用之,如下:
adb = db.DB()
adb.open('db_filename', dbtype = db.DB_HASH, flags = db.DB_CREATE)
当你想创建一个数据库时,db.DB_HASH 是几种可以选择的访问方法中的一种,一个很常见的选择是 db.DB_BTREE,使用 B+树访问(如果你想以排序的方式获取记录,这很方便)。也可以选择构建一个内存数据库,不使用任何持久化文件,只要将None作为文件名和第一个参数传递给 open 方法即可。
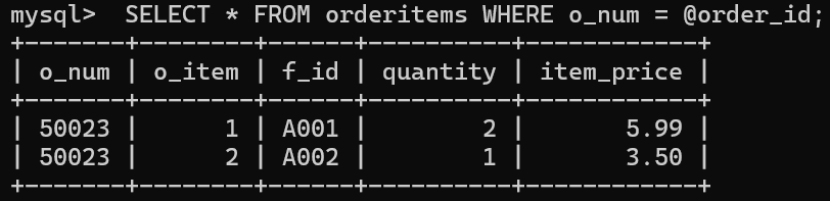
一旦有了一个打开的 db.DB 实例,你就可以添加记录了。每条记录由两个字符串构成键和数据:
for i,w in enumerate('some words for example'.split( )):
adb.put(w,str(i))
可以通过数据库的游标访问记录:
def irecords(curs):
record = curs.first()
while record:
yield record
record = curs.next()
for key,data in irecords(adb.cursor()):
print 'key = %r,data = %r' %(key,data)
#输出(the order may vary):
# key = 'some', data = '0'
# key = 'example', data = '3'
# key = 'words', data = '1'
# key = 'for', data = '2'
做完之后,需要关闭数据库:
adb.close()
以后,在同一个或其他的Python程序中,可以给新创建的db.DB 实例的open 方法传递同样的文件名,再次打开该数据库:
the_same_db = db.DB()
the_same_db.open('db_filename')
然后用同样的方式继续工作:
the_same_db.put('skidoo',23')#添加一条记录
the_same_db.put('words','sweet')#替换一条记录
for key,data in irecords(the_same_db.cursor()):
print 'key=%r,data=%r'%(key,data)
#输出(the order may vary):
# key='some',data='0'
# key='example',data='3'
# key='words',data='sweet'
# key='for',data='2'
# key='skidoo',data='23'
再次提醒,在所有操作结束之后不要忘记关闭数据库:
the_same_db.close()
讨论
Berkeley DB 是一个流行的开源数据库。它不支持SQL,但却很容易使用,并提供了优异的性能,如果你希望掌控全局的话,它给了你充分的自由来控制所发生的一切,可以通过大量的选项、标志以及方法来完成控制。除了Python,我们也可以通过其他语言来访问 Berkeley DB:比如,可以用 Python 程序完成一些修改和查询,然后再使用一个独立的C程序,使用相同的基本开源库(可以从Sleepycat 下载),对同样的数据库做同样的事情。
Python 标准库模块shelve 可以使用 Berkeley DB 作为它的数据库引擎,就像它使用cPickle 进行序列化操作一样。然而,如果记录都是由 pickle.dumps 产生的串,而这些串对于除 Python 之外的任何语言来说都是很难处理的数据,那你将无法用其他语言访问Berkeley DB数据库文件。通过bsddb直接访问 Berkeley DB,数据库引擎能够提供很多高级的功能,而这些都是 shelve无法提供的。
数据库还是 pickle,或者两者都用?
pickle 和 marshal,以及数据库系统如 Berkeley DB 或关系型数据库,它们的应用场合有很大不同,但是仍然有一些重叠的地方
pickle(以及 marshal)本质上是序列化处理:将Python 对象转变成可以传输或者储存的 BLOB,之后可以由另一方接收或者恢复。序列化的数据是被用来重建Pythor对象的,基本上也只能被 Python 应用程序访问。而针对对象或对象的一部分的搜索和选择操作,pickle 不能提供任何支持
数据库(Berkeley DB,关系型数据库,以及其他类型)本质上是以数据为核心的:可以保存或者获取成组的基本类型的数据(大多是字符串和数字),还能够得到很多有关选取和搜索(对于关系型数据,这种支持可以说是海量的)以及跨语言的支持。数据库对于将 Python 对象序列化成数据或者从数据中反序列化出Python 对象一无所知。
数据库和序列化这两种方式也可以被混用。可以用 pickle 将 Python 对象序列化成字节码,然后用数据库储存,或者反过来。但 Python 标准库 shelve 模块只是在一个很底层的层面工作,比如,它可以借助 pickle 来完成序列化和反序列化,或使用bsddb来作为底层的数据库引擎。因此,不要认为两种方式是一种“竞争的”关系——而应该认为两者是一种互相补充的关系。
举个例子,如解决方案中的代码所示,创建一个带有db.DB_HASH 访间方式的数据库我们可以获得最大的效率,不过,你可能也注意到了,用生成器irecords 列出所有的记录时,哈希算法使得记录以一种随机的和无法预测的顺序排列。如果你想以一种排序的方式访问记录,应该使用 db.DB_BTREE方法。BerkeleyDB支持很多高级功能,如事务,可以直接访问数据库来获得这种功能,而不是试图通过anydbm 或者shelve 来访问。
更多的关于 Python 标准库 bsddb 包的详细文档,请参看 http://pybsddb.sourceforge.netbsddb3.html。而关于BerkeleyDB本身的文档、下载以及其他资料,请访问http://www.sleepycat.com。