基于LightGBM-TPE算法对交通事故严重程度的分析与可视化
原文: Analysis and visualization of accidents severity based on LightGBM-TPE
1. 引言部分
文章开篇强调了道路交通事故作为意外死亡的主要原因,引起了多学科领域的关注。分析事故严重性特征有助于明确不同风险因素与道路事故间的因果关系,从而提升道路安全。但现有研究在将数据可视化应用于交通安全调查方面存在不足。基于此,作者提出了一种结合LightGBM-TPE(Light Gradient Boosting Machine-Tree-structured Parzen Estimator)与数据可视化的分析方法,以2017年英国交通事故数据为研究对象。该方法相较于其他典型机器学习算法,在f1分数、准确率、召回率和精确率等指标上表现更优。通过LightGBM-TPE计算SHAP值,发现经度、纬度、小时和星期几是与事故严重性最密切相关的四个风险因素,可视化分析进一步验证了这一结论。研究旨在探索一种理解与评估道路交通事故特征重要性的创新方式,为改善交通安全提供建议。
2. 数据描述与预处理
2.1 数据描述
本文研究使用了 2017 年英国交通事故数据集,该数据集来源于 Kaggle 平台,包含了丰富的道路事故信息。数据集中的每一行代表一个交通事故,共提供了 34 个信息列来详细描述每个事故的各个方面。在本研究中,作者将交通事故主要分为两类,即致命事故(fatal accidents)和非致命事故(non-fatal accidents),其中非致命事故包括严重事故和轻微事故。这样的分类方式有助于研究者集中分析导致致命事故的关键因素,为改善交通安全策略提供更有针对性的建议。
研究选取了 2017 年英国发生的交通事故数据,其中致命事故有 1642 起被归类为正类案例,而非致命事故则包括 21780 起严重事故和 100308 起轻微事故,均被标记为负类案例。通过对数据集的初步统计分析,作者对数据集中的分类数据进行了描述性统计,如天气状况、道路类型、星期几、道路表面状况以及光照条件等,这些统计信息为后续的数据预处理和分析奠定了基础。
2.2 数据预处理
在将原始数据输入机器学习模型之前,数据预处理是一个关键步骤,它主要包括数据清洗和数据格式化两个部分,同时针对数据集中的类别不平衡问题进行了处理。
数据清洗
原始数据中包含了许多与事故严重性无关的信息。例如,“Did_Police_Officer_Attend_Scene_of_Accident”(是否有警官出席事故现场)这一特征对于研究事故严重性并无直接关联;“InScotland” 这一信息也因与 “Longitude”(经度)和 “Latitude”(纬度)存在冗余而被剔除。通过数据清洗,作者保留了与事故严重性密切相关的 10 个特征,这些特征可以分为以下四个类别:
- 事故位置相关特征:“Longitude”(经度)和 “Latitude”(纬度),用于定位事故发生的地理位置。
- 事故时间相关特征:“Hour”(小时)、“Month”(月份)和 “Day_of_Week”(星期几),用于分析事故发生的时刻及其潜在规律。
- 环境状况相关特征:“Light Condition”(光照条件)和 “Weather Condition”(天气状况),用于考察事故发生时的环境因素。
- 道路状况相关特征:“Speed Limit”(限速)、“Road Type”(道路类型)和 “Road Surface Condition”(道路表面状况),用于评估道路条件对事故的影响。
这些经过筛选的特征将作为模型的输入变量,而事故的严重性(致命或非致命)则作为输出变量。
数据格式化
为了使数据更适合机器学习算法的处理,作者对许多分类变量进行了独热编码(one-hot encoding)。例如,原始数据集中的 “Day_of_Week”(星期几)这一分类变量被转换为具体的每一天(如 Sunday、Friday 等),从而为算法提供更明确的信息。这种转换方式能够使模型更好地理解不同类别的特征值对事故严重性的影响,而无需依赖于变量之间的数值大小关系。
数据平衡
在交通事故数据集中,通常非致命事故的数量会远多于致命事故,这导致数据集存在类别不平衡的问题。为了解决这一问题,作者采用了合成少数过采样技术(SMOTE)。SMOTE 算法通过在少数类样本(即致命事故)周围生成新的合成样本,来平衡数据集中的正负类样本数量。相比于简单的欠采样方法,SMOTE 能够避免因减少多数类样本数量而导致的预测准确性下降问题,从而提高模型在处理不平衡数据时的性能。
综上所述,通过数据清洗、数据格式化和数据平衡等预处理步骤,作者有效地提高了数据质量,使其更适合后续的机器学习分析。这些预处理工作为确保模型的准确性和可靠性提供了重要保障,同时也为深入挖掘交通事故数据中的关键特征奠定了坚实基础。
3. 方法论
文章首先介绍了几种典型的机器学习方法,包括逻辑回归、GBDT、XGBoost、LightGBM及本文提出的LightGBM-TPE,并指出将选用预测准确率最高的模型来计算特征重要性,进而进行可视化分析。在LightGBM-TPE中,LightGBM采用基于梯度的单边采样(GOSS)和独占特征捆绑(EFB)等技术,提高了训练速度并减少了内存占用。TPE算法用于优化LightGBM的超参数,通过构建响应面模型并基于原始模型迭代收集额外数据,以找到最佳超参数组合,提升模型性能。研究中通过5折交叉验证确定了最佳超参数,包括树的最大深度(max_depth=10)、叶子数(num_leaves=246)、树的数量(n_estimators=380)和叶子中的最小数据量(min_data_in_leaf=20)。此外,文章还介绍了SHAP(SHapley Additive exPlanation)方法,用于计算每个特征对模型预测的贡献值(SHAP值),并基于此进行可视化分析,展示各特征对事故严重性的影响。
4. 结果与讨论
4.1 性能比较
在这一部分,作者对比了LightGBM-TPE与其他四种主流机器学习模型(LightGBM、逻辑回归、GBDT和XGBoost)的预测性能。对比的指标包括f1分数、准确率、召回率和精确率,而模型性能的验证则通过5折交叉验证完成。具体来说,数据集被随机分为5个连续的子集,每次将一个子集作为验证集,其余四个子集作为训练集,最终结果取五次验证的平均值。
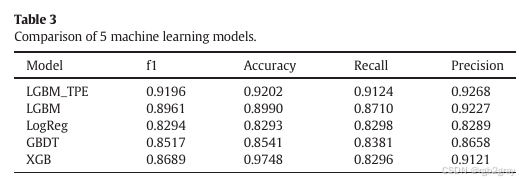
结果表明,LightGBM-TPE在精确率上表现最为优异,达到了0.9268,而在f1分数、准确率和召回率方面同样取得了最优的成绩。相比之下,GBDT在这五种机器学习方法中表现最差。基于这些结果,作者选择了LightGBM-TPE作为预测模型,用于后续的SHAP值计算和特征重要性分析。这一选择与先前研究的结论一致,即模型的预测性能越高,其计算出的特征重要性结果越可信。
4.2 特征重要性与SHAP值
为了更准确地衡量特征的重要性,作者采用了SHAP值的平均绝对值作为指标。SHAP值基于合作博弈论,能够量化每个特征对模型预测的贡献。结果显示,经度、纬度和小时是影响事故严重性的三个最关键特征,其中经度的重要性位居榜首,随后是纬度和小时。
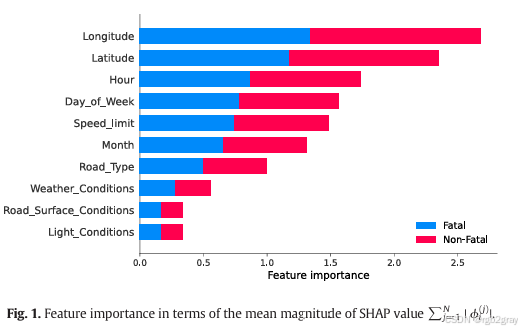
SHAP总结图进一步揭示了每个特征对预测输出的影响范围和分布情况。在总结图中,每个点代表一个事故数据,其在y轴和x轴上的位置分别对应特征值和SHAP值,颜色则表示特征值的大小。对于经度和纬度而言,SHAP值相对接近对称轴,这意味着相似的特征值可能对事故严重性产生截然相反的影响。因此,经度和纬度的组合效应比单一特征更能解释事故的严重性。而其他特征则可以独立分析其影响。此外,空间特征(经度和纬度)在LightGBM-TPE模型中占据最为重要的地位,时间特征(小时、星期几和月份)次之,而环境特征(如天气状况)对致命事故发生的影响则相对较弱。
4.3 可视化分析
基于SHAP值的可视化分析,作者深入探讨了关键特征对事故严重性的具体影响。以下是对主要特征的详细分析:
经度和纬度
- SHAP依赖图显示,随着经度的变化,SHAP值呈现出非线性趋势。特别是在经度介于-4.5到-3.5或0到1.5之间时,大多数事故的SHAP值为负,表明这些区域的致命事故相对较少。
- 图中还揭示了经度和纬度之间的复杂关系。例如,当经度约为-3.9时,纬度越高,SHAP值也越高,对应的致命事故数量也越多。
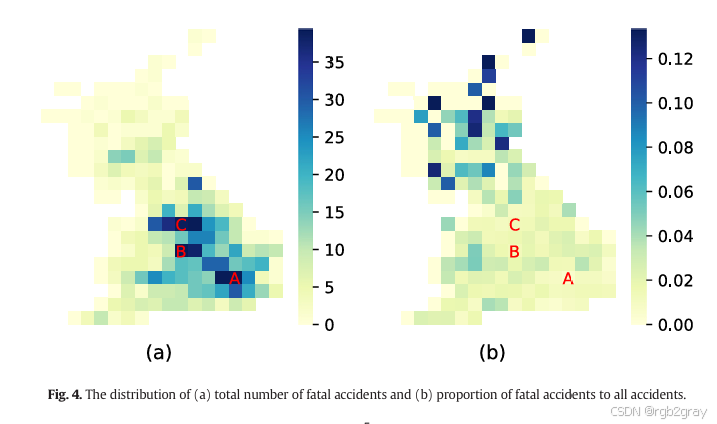
- 进一步分析英国致命事故的地理分布,作者将研究区域划分为18×20的网格,并标出了三个主要城市区域(伦敦、伯明翰以及利物浦、曼彻斯特和谢菲尔德)。结果显示,大城市的致命事故总数显著高于其他地区。然而,高纬度地区的致命事故比例却稳定在最高水平。这表明,尽管大城市的致命事故绝对数量多,但高纬度地区的事故致命比例更高,提示这些地区需要加强交通管理和控制策略。
小时和星期几
- 时间特征的分析表明,SHAP值在凌晨1:00到3:00以及7:00到8:00期间多为负值,而在凌晨3:00到4:00以及19:00到23:00期间多为正值。这表明夜间(19:00到23:00)是致命事故的高发时段。
- 凌晨3:00是一个显著的转折点,此时SHAP值大幅增加。此外,星期三的凌晨时段记录了最多的致命事故。
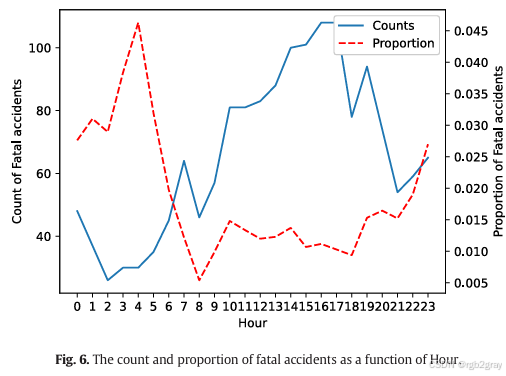
- 通过对小时特征对致命事故数量和比例的影响分析发现,致命事故数量在17:00达到峰值(约118起),而致命事故比例则在凌晨4:00达到最高点(约4.5%)。从19:00到4:00,致命事故比例呈逐步上升趋势。这表明,尽管凌晨时段的事故总数较少,但其致命性却极高。因此,作者建议英国应从夜间到凌晨实施更严格的交通管制政策。
总结
通过性能比较、特征重要性和可视化分析,作者不仅验证了LightGBM-TPE模型在预测交通事故严重性方面的优越性,还揭示了关键风险特征对事故致命性的影响机制。这些发现为城市规划者和交通管理部门提供了有价值的参考,有助于制定更有针对性的交通安全策略,特别是在高风险地理位置和时间段加强监管和控制。研究结果强调了数据可视化在理解复杂交通系统和指导政策制定中的重要作用,同时也为未来的研究方向提供了启发,例如进一步探讨制度激励对交通行为和事故演变的影响。
5. 结论
文章基于2017年英国交通事故数据,提出了一种结合LightGBM-TPE和数据可视化的混合机器学习模型,确定了经度、纬度、小时和星期几是决定事故严重性的最重要因素。研究为城市规划者提供了实际建议,例如在高纬度地区实施更有效的交通控制和管理策略,在夜间到凌晨期间加强交通管制。这项工作有助于理解重要风险因素如何影响事故严重性,并为有效控制致命事故发生提供了新方法。尽管如此,作者也指出,未来研究应深入探讨制度激励存在及其成本对交通事故演变动态的影响。
6. 其他
以下是一份基于文章的Python代码,涵盖了数据预处理、模型训练与评估、特征重要性计算及可视化等部分。在运行代码前,请确保安装了相关依赖库,如pandas、numpy、lightgbm、shap、optuna和scikit-learn等。
数据预处理部分
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from imblearn.over_sampling import SMOTE
# 加载数据
data = pd.read_csv('uk_accidents_2017.csv')
# 数据清洗:选择相关特征
features = ['Longitude', 'Latitude', 'Hour', 'Month', 'Day_of_Week', 'Light_Condition', 'Weather_Condition', 'Speed_Limit', 'Road_Type', 'Road_Surface_Condition']
target = 'Accident_Severity' # 假设目标变量列为 Accident_Severity,需根据实际数据调整
data_selected = data[features + [target]]
# 处理缺失值(如果有)
data_selected = data_selected.dropna()
# 特征分类
categorical_features = ['Day_of_Week', 'Month', 'Light_Condition', 'Weather_Condition', 'Road_Type', 'Road_Surface_Condition']
numerical_features = ['Longitude', 'Latitude', 'Hour', 'Speed_Limit']
# 独热编码
encoder = OneHotEncoder()
encoded_features = encoder.fit_transform(data_selected[categorical_features]).toarray()
encoded_features_df = pd.DataFrame(encoded_features, columns=encoder.get_feature_names_out(categorical_features))
# 合并数值特征和编码后的分类特征
X = pd.concat([data_selected[numerical_features], encoded_features_df], axis=1)
y = data_selected[target]
# 处理类别不平衡:使用SMOTE
smote = SMOTE()
X_resampled, y_resampled = smote.fit_resample(X, y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.2, random_state=42)
模型训练与评估部分
import lightgbm as lgb
from sklearn.metrics import f1_score, accuracy_score, recall_score, precision_score
# 转换为LightGBM数据格式
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
# LightGBM默认参数
params = {
'objective': 'binary', # 二分类问题
'metric': 'binary_logloss',
'boosting_type': 'gbdt',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9
}
# 使用TPE进行超参数优化
def objective(trial):
params_tpe = {
'objective': 'binary',
'metric': 'binary_logloss',
'boosting_type': 'gbdt',
'num_leaves': trial.suggest_int('num_leaves', 20, 256),
'max_depth': trial.suggest_int('max_depth', 1, 12),
'min_data_in_leaf': trial.suggest_int('min_data_in_leaf', 20, 300),
'n_estimators': trial.suggest_int('n_estimators', 10, 500),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.1),
'feature_fraction': trial.suggest_float('feature_fraction', 0.5, 1.0)
}
model = lgb.train(params_tpe, train_data, valid_sets=[test_data], early_stopping_rounds=50, verbose_eval=False)
predictions = model.predict(X_test)
preds = [1 if x > 0.5 else 0 for x in predictions]
return f1_score(y_test, preds)
import optuna
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
best_params = study.best_params
print("最佳超参数:", best_params)
# 使用最佳超参数训练模型
model = lgb.train(best_params, train_data, valid_sets=[test_data], early_stopping_rounds=50, verbose_eval=False)
# 模型评估
predictions = model.predict(X_test)
preds = [1 if x > 0.5 else 0 for x in predictions]
print("F1 Score:", f1_score(y_test, preds))
print("Accuracy:", accuracy_score(y_test, preds))
print("Recall:", recall_score(y_test, preds))
print("Precision:", precision_score(y_test, preds))
特征重要性计算与可视化部分
import shap
# 计算SHAP值
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
# 特征重要性可视化
shap.summary_plot(shap_values, X_test)
# SHAP依赖图(以经度为例)
shap.dependence_plot("Longitude", shap_values[1], X_test)