【图像分类】【深度学习】图像分类评价指标
文章目录
- 【图像分类】【深度学习】图像分类评价指标
- 前言
- 二分类评价指标
- Accuracy(准确率/精度)
- Precision(精确率/查准率)
- Recall(召回率/查全率)
- F1-Score
- AUC-ROC曲线(Area Under the Curv-Receiver Operating Characteristic Curve)
- 二分类的案例
- 多分类评价指标
- Accuracy(准确率/精度)
- macro指标
- micro指标
- Kappa指标(科恩的卡帕系数)
- 多分类的案例
- 总结
前言
随着深度学习的发展,特别是卷积神经网络(CNNs)在图像领域的成功应用,开发出了许多用于图像分类的复杂模型。然而,为了确保这些模型能够在实际应用中有效工作,并能与其它模型进行比较,需要一套标准的评价指标来衡量模型性能,了解模型的表现,并且根据具体的应用指导模型改进。
评价指标通常涵盖多个方面,从不同维度评估模型的优劣,从而让模型构建者能够全面了解模型的性能。同时,依据任务的具体偏向和要求,按照重点关注的指标支持对模型进行有效的取舍和优化,对于提升模型性能和适用性具有重要意义。
常用的分类模型评价指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及F1分数(F1-Score)。通过综合分析这些指标,不仅可以更精确地衡量模型的表现,还能根据实际应用场景的需求,做出更加明智的决策。这样无论是提升模型的整体性能,还是针对特定需求优化模型,都变得更加有据可依。
【图像分类】【深度学习】系列学习文章目录
二分类评价指标
在探究不同评价指标前,先定义计算指标的基本值:
- True Positives,TP: 实际为正例,且被预测为正例的样本数;
- False Positives,FP: 实际为负例,但被预测为正例的样本数;
- True Negatives,TN: 实际为正例,但被预测为反例的样本数;
- False Negatives,FN: 实际为负例,但被预测为反例的样本数。
这些基本值有点难理解,其实这里分开理解就好了:第二项Positives/Negatives预测器对样本的预测,即我觉得是正例还是反例;第一项True/False是根据真实标签对预测结果作出的判断,预测对了还是错了。
Accuracy(准确率/精度)
对于给定的数据,预测正确的样本数占总样本数的比例:
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
Accuracy = \frac{{TP + TN}}{{TP + TN + FP + FN}}
Accuracy=TP+TN+FP+FNTP+TN
博主感觉很多分类网络几乎主要关注Accuracy这个指标。
缺点:在数据集极其不平衡时,如正负样本数目差别很大,正样本999个,负样本1个,直接把所有的样本都预测为正, 准确率为99.9 %,但是此分类模型完全无意义。
Precision(精确率/查准率)
分类正确的正样本个数占所有预测判定为正样本个数的比例:
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision = \frac{{TP}}{{TP + FP}}
Precision=TP+FPTP
通俗来讲,就是在预测器判定为正样本的结果中有多少真正的正样本。
Recall(召回率/查全率)
分类正确的正样本个数占实际正样本个数的比例:
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall= \frac{{TP}}{{TP + FN}}
Recall=TP+FNTP
通俗的讲,就是在所有样本中有多少正样本被找到。
F1-Score
精确率Precision和召回率Recall的调和平均数,是综合考虑精确率与召回率的一种指标:
F
1
_
S
c
o
r
e
=
2
1
P
r
e
c
i
s
i
o
n
+
1
R
e
c
a
l
l
=
2
×
P
r
e
c
i
s
i
o
n
×
R
e
c
a
l
l
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
=
2
T
P
2
T
P
+
F
P
+
F
N
F1\_Score = \frac{2}{{\frac{1}{{Precision}} + \frac{1}{{Recall}}}} = \frac{{2 \times Precision \times Recall}}{{Precision + Recall}} = \frac{{2TP}}{{2TP + FP + FN}}
F1_Score=Precision1+Recall12=Precision+Recall2×Precision×Recall=2TP+FP+FN2TP
认为召回率和精度同等重要,最大为 1,最小为 0。
当类别不均衡,F1-Score是比Accuracy更好的指标。
AUC-ROC曲线(Area Under the Curv-Receiver Operating Characteristic Curve)
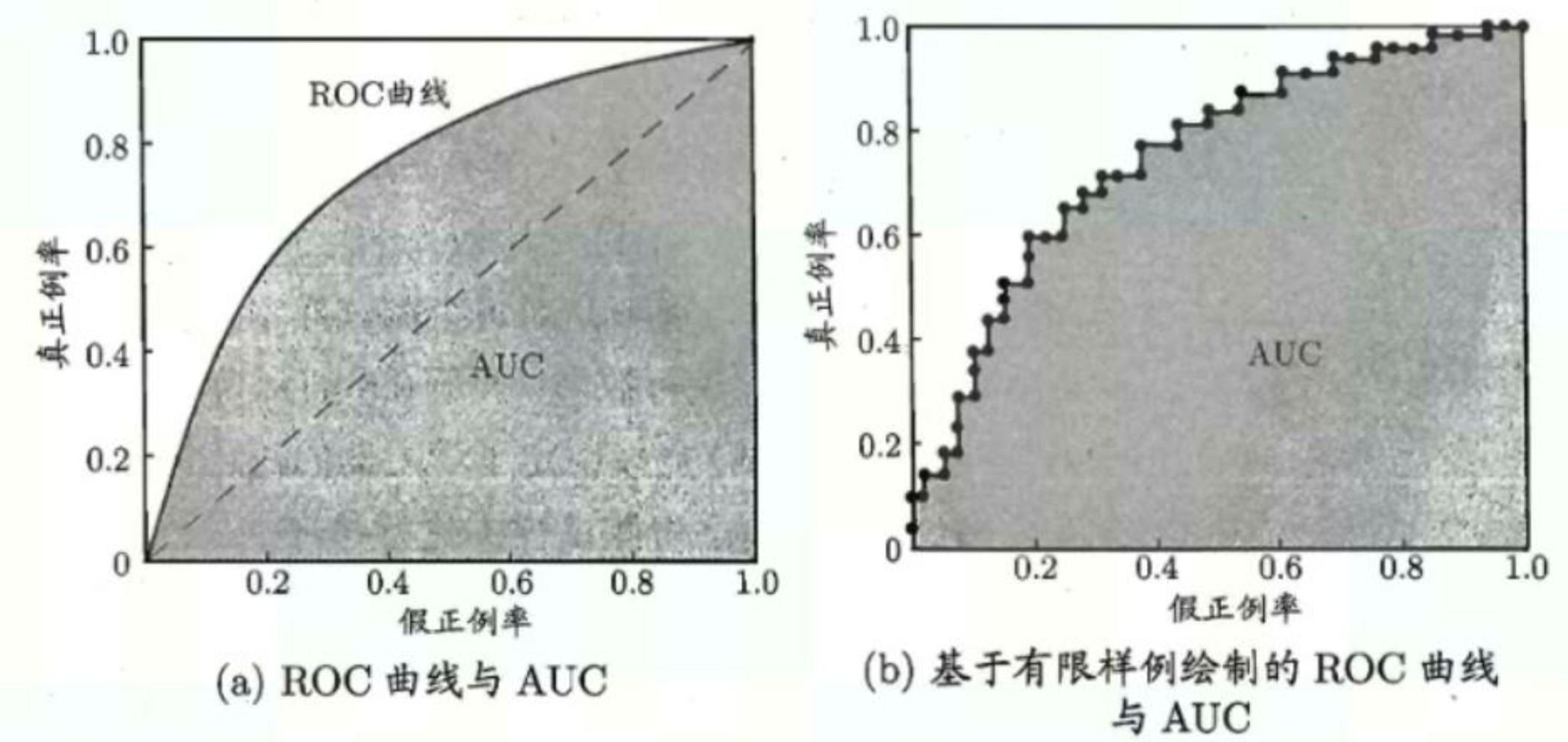
ROC曲线以假正率(False Positive Rate, FPR)为横轴,真正率(True Positive Rate, TPR)为纵轴。通过绘制TPR与FPR在不同阈值下的变化来实现这一点。
FPR: 指在所有实际为负类的样本中,被错误地识别为正类的比例:
F
P
R
=
F
P
N
=
F
P
F
P
+
T
N
FPR = \frac{{FP}}{N} = \frac{{FP}}{{FP + TN}}
FPR=NFP=FP+TNFP
TPR: 即召回率,指在所有实际为正类的样本中,被正确识别出来的比例:
T
P
R
=
T
P
P
=
T
P
T
P
+
F
N
TPR = \frac{{TP}}{P} = \frac{{TP}}{{TP+ FN}}
TPR=PTP=TP+FNTP
ROC 曲线有四个关键点:
- (0,0)点:FPR=TPR=0,表示分类器预测所有的样本都为负样本;
- (1,1)点:FPR=TPR=1,表示分类器预测所有的样本都为正样本;
- (0,1)点:FPR=0,TPR=1,此时FN=0且FP=0,表示最优分类器,所有的样本都被正确分类;
- (1,0)点:FPR=1,TPR=0,此时TP=0且TN=0,表示最差分类器,有所得样本都被错误分类。
ROC 曲线越接近左上角,表示该分类器的性能越好:若一个分类器的ROC曲线被另一个分类器的曲线完全“包住”,则可断言后者的性能优于前者;若两个学习器的 ROC 曲线发生交叉,则难以断言两者孰优孰劣,此时需要比较ROC曲线下的面积AUC(Area Under ROC Curve)。
AUC 的意义: 分类器将正样本预测为正例的概率TPR大于将负样本预测为正例的概率FPR。
当一个分类器倾向于给予正样本比负样本更高的预测概率时,说明模型在某种程度上捕捉到了数据中正样本和负样本之间的差异特征。这种特性使得模型在进行二分类任务时更为有效。
根据AUC的意义推导出其计算公式:
A
U
C
=
∑
i
=
0
P
∑
j
=
0
N
I
(
P
i
,
N
j
)
P
×
N
AUC = \frac{{\sum\limits_{{\rm{i = 0}}}^P {\sum\limits_{j = 0}^N {I\left( {{P_i},{N_j}} \right)} } }}{{P \times N}}
AUC=P×Ni=0∑Pj=0∑NI(Pi,Nj)
P
P
P为正样本数量,
N
N
N为负样本数量。
P
i
P_i
Pi为正样本预测得分,即将正样本预测为正例的概率;
N
j
N_j
Nj为负样本预测得分,即将负样本预测为正例的概率。其中:
I
(
P
i
,
N
j
)
=
{
1
0.5
0
P
i
>
N
j
P
i
=
N
j
P
i
<
N
j
}
I\left( {{P_i},{N_j}} \right) = \left\{ {\begin{array}{ccc} 1\\ {0.5}\\ 0 \end{array}\begin{array}{ccc} {{P_i} > {N_j}}\\ {{P_i} = {N_j}}\\ {{P_i} < {N_j}} \end{array}} \right\}
I(Pi,Nj)=⎩
⎨
⎧10.50Pi>NjPi=NjPi<Nj⎭
⎬
⎫
可以理解为区分正类和负类的能力,AUC 的有效范围是
(
0.5
,
1
]
(0.5,1]
(0.5,1] ,当AUC越大,表示区分正负类的能力越强。
- AUC=1:在任何阈值下分类器全部识别所有类别,完美分类器(几乎不可能实现);
- 0.5<AUC<1:优于随机预测,这也是实际作用中大部分分类器所处的状态;
- AUC=0.5:相当于随机预测,此时分类器不可用;
- AUC<0.5:总是比随机预测更差(二分类总不能比随机差);
AUC对正负样本不均衡问题不敏感,当测试集中的正负样本比例分布变化时,特别适用于评估二分类器的性能。
二分类的案例
现在有一个模型对人的体检指标进行是否有肿瘤的判断,这很显然是一个二分类的任务,结果只有是和否两种。
| 样本ID | 样本标签 | 预测概率 |
|---|---|---|
| 1 | 正 | 0.95 |
| 2 | 正 | 0.86 |
| 3 | 负 | 0.70 |
| 4 | 正 | 0.65 |
| 5 | 正 | 0.55 |
| 6 | 负 | 0.53 |
| 7 | 负 | 0.52 |
| 8 | 负 | 0.43 |
| 9 | 正 | 0.42 |
| 10 | 负 | 0.35 |
当阈值为0.5时,即大于0.5预测为正,小于0.5预测为负。预测标签的情况如下表所示:
| 样本ID | 样本标签 | 预测概率 | 预测标签 |
|---|---|---|---|
| 1 | 正 | 0.95 | 正 |
| 2 | 正 | 0.86 | 正 |
| 3 | 负 | 0.70 | 正 |
| 4 | 正 | 0.65 | 正 |
| 5 | 正 | 0.55 | 正 |
| 6 | 负 | 0.53 | 正 |
| 7 | 负 | 0.52 | 正 |
| 8 | 负 | 0.43 | 负 |
| 9 | 正 | 0.42 | 负 |
| 10 | 负 | 0.35 | 负 |
上述的案例表或许有点绕,利用混淆矩阵来表达上述模型判断的结构较为直观:
| 预测值正例 | 预测值负例 | |
|---|---|---|
| 真实值正例 | 4 | 1 |
| 真实值负例 | 3 | 2 |
计算出对应的评价指标:
A
c
c
u
r
a
c
y
=
4
+
2
4
+
1
+
3
+
2
=
0.6
Accuracy = \frac{{4 + 2}}{{4 + 1 + 3 + 2}}=0.6
Accuracy=4+1+3+24+2=0.6
P
r
e
c
i
s
i
o
n
=
4
4
+
3
≈
0.57
Precision = \frac{{4}}{{4+ 3}}\approx 0.57
Precision=4+34≈0.57
R
e
c
a
l
l
=
T
P
R
=
4
4
+
1
=
0.8
Recall = TPR = \frac{4}{{4 + 1}}=0.8
Recall=TPR=4+14=0.8
F
1
_
S
c
o
r
e
=
8
8
+
3
+
1
≈
0.67
F1\_Score = \frac{{8}}{{8 + 3 + 1}}\approx 0.67
F1_Score=8+3+18≈0.67
F
P
R
=
3
3
+
2
=
0.6
FPR = \frac{{3}}{{3 + 2}}=0.6
FPR=3+23=0.6
阈值为0.5时ROC曲线的点为
(
0.6
,
0.8
)
(0.6,0.8)
(0.6,0.8)。
那么阈值分别是1.0,0.75, 0.5,0.25,0.0时,预测标签的情况如下表所示:
| 样本ID | 样本标签 | 预测概率 | 预测标签(1.0) | 预测标签(0.75) | 预测标签(0.5) | 预测标签(0.25) | 预测标签(0.0) |
|---|---|---|---|---|---|---|---|
| 1 | 正 | 0.95 | 负 | 正 | 正 | 正 | 正 |
| 2 | 正 | 0.86 | 负 | 正 | 正 | 正 | 正 |
| 3 | 负 | 0.70 | 负 | 负 | 正 | 正 | 正 |
| 4 | 正 | 0.65 | 负 | 负 | 正 | 正 | 正 |
| 5 | 正 | 0.55 | 负 | 负 | 正 | 正 | 正 |
| 6 | 负 | 0.53 | 负 | 负 | 正 | 正 | 正 |
| 7 | 负 | 0.52 | 负 | 负 | 正 | 正 | 正 |
| 8 | 负 | 0.43 | 负 | 负 | 负 | 正 | 正 |
| 9 | 正 | 0.42 | 负 | 负 | 负 | 正 | 正 |
| 10 | 负 | 0.35 | 负 | 负 | 负 | 正 | 正 |
混淆矩阵来表达上述模型判断:
| 预测值正例 | 预测值负例 | |
|---|---|---|
| 真实值正例 | 0/2/4/5/5 | 5/3/1/0/0 |
| 真实值负例 | 0/0/3/5/5 | 5/4/2/0/0 |
因此,ROC曲线的点分别是
(
0.0
,
0.0
)
(0.0,0.0)
(0.0,0.0),
(
0.0
,
0.4
)
(0.0,0.4)
(0.0,0.4),
(
0.6
,
0.8
)
(0.6,0.8)
(0.6,0.8),
(
1.0
,
1.0
)
(1.0,1.0)
(1.0,1.0),
(
1.0
,
1.0
)
(1.0,1.0)
(1.0,1.0)。
A
U
C
=
0.76
AUC=0.76
AUC=0.76
计算Accuracy、Precision、Recall以及F-Score的python代码:
import numpy as np
# 示例数据:预测得分和真实标签
labels = np.array([1, 1, 0, 1, 1, 0, 0, 0, 1, 0])
predictions = np.array([0.95, 0.86, 0.70, 0.65, 0.55, 0.53, 0.52, 0.43, 0.42, 0.35])
thresholds = np.array([0.5]) # 获取不同的阈值
def calculate_metrics(predictions, labels, thresholds):
metrics_list = []
for threshold in thresholds:
# 根据当前阈值将预测得分转化为二分类预测
binary_predictions = (predictions >= threshold).astype(int)
# 计算混淆矩阵元素
tp = np.sum((binary_predictions == 1) & (labels == 1)) # 真正例
tn = np.sum((binary_predictions == 0) & (labels == 0)) # 真负例
fp = np.sum((binary_predictions == 1) & (labels == 0)) # 假正例
fn = np.sum((binary_predictions == 0) & (labels == 1)) # 假负例
# 计算各个指标
accuracy = (tp + tn) / (tp + tn + fp + fn) if (tp + tn + fp + fn) > 0 else 0
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
f_score = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0
# 添加到列表中
metrics_list.append({
'Threshold': threshold,
'Accuracy': accuracy,
'Precision': precision,
'Recall': recall,
'F-Score': f_score
})
return metrics_list
# 计算不同阈值下的各种评价指标
metrics_list = calculate_metrics(predictions, labels, thresholds)
# 输出结果
for metrics in metrics_list:
print(f"Threshold: {metrics['Threshold']:.2f}, "
f"Accuracy: {metrics['Accuracy']:.2f}, "
f"Precision: {metrics['Precision']:.2f}, "
f"Recall: {metrics['Recall']:.2f}, "
f"F-Score: {metrics['F-Score']:.2f}")
计算ROC的python代码:
import numpy as np
labels = np.array([1, 1, 0, 1, 1, 0, 0, 0, 1, 0])
predictions = np.array([0.95, 0.86, 0.70, 0.65, 0.55, 0.53, 0.52, 0.43, 0.42, 0.35])
thresholds = np.array([0.0, 0.25, 0.5, 0.75, 1.0]) # 获取不同的阈值
def calculate_roc_points(predictions, labels, thresholds):
fpr_list = [] # 假正类率列表
tpr_list = [] # 真正类率列表
for threshold in thresholds:
# 根据当前阈值将预测得分转化为二分类预测
binary_predictions = (predictions >= threshold).astype(int)
# 计算混淆矩阵元素
tp = np.sum((binary_predictions == 1) & (labels == 1)) # 真正例
tn = np.sum((binary_predictions == 0) & (labels == 0)) # 真负例
fp = np.sum((binary_predictions == 1) & (labels == 0)) # 假正例
fn = np.sum((binary_predictions == 0) & (labels == 1)) # 假负例
# 计算假正类率(FPR)和真正类率(TPR)
fpr = fp / (fp + tn) if fp + tn > 0 else 0
tpr = tp / (tp + fn) if tp + fn > 0 else 0
# 添加到列表中
fpr_list.append(fpr)
tpr_list.append(tpr)
return fpr_list, tpr_list
# 计算不同阈值下的ROC点
fpr_list, tpr_list = calculate_roc_points(predictions, labels, thresholds)
# 输出结果
for i, threshold in enumerate(thresholds):
print(f"Threshold: {threshold:.2f}, FPR: {fpr_list[i]:.2f}, TPR: {tpr_list[i]:.2f}")
计算AUC的python代码:
import numpy as np
labels = np.array([1, 1, 0, 1, 1, 0, 0, 0, 1, 0])
predictions = np.array([0.95, 0.86, 0.70, 0.65, 0.55, 0.53, 0.52, 0.43, 0.42, 0.35])
# 根据标签分离正类和负类的预测得分
positive_scores = predictions[labels == 1]
negative_scores = predictions[labels == 0]
# 手动计算 Mann-Whitney U 统计量
def mannwhitneyu_manual(positive_scores, negative_scores):
n1 = len(positive_scores) # 正类样本数量
n2 = len(negative_scores) # 负类样本数量
# 初始化 U 统计量
U = 0
# 遍历所有正类和负类样本对,统计正类得分大于负类得分的次数
for pos_score in positive_scores:
for neg_score in negative_scores:
if pos_score > neg_score:
U += 1
elif pos_score == neg_score: # 如果相等,则加 0.5(处理平局)
U += 0.5
return U, n1, n2
# 计算 U 统计量
U_statistic, n1, n2 = mannwhitneyu_manual(positive_scores, negative_scores)
# 计算 AUC
auc = U_statistic / (n1 * n2)
# 输出结果
print(f"Mann-Whitney U 统计量: {U_statistic}")
print(f"AUC 值: {auc}")
多分类评价指标
Accuracy(准确率/精度)
与二分类相同,预测正确的样本数占总样本数的比例:
A
c
c
u
r
a
c
y
=
预测正确的样本数量
总的样本数量
Accuracy = \frac{{预测正确的样本数量}}{{总的样本数量}}
Accuracy=总的样本数量预测正确的样本数量
macro指标
类比二分类指标,大体原则是每类计算对应指标,再求平均:
- macro-Precision(宏精确率/ 宏查准率)公式:
m a c r o _ P = 1 n ∑ 1 n P i macro\_P = \frac{1}{{\rm{n}}}\sum\limits_1^{\rm{n}} {{P_i}} macro_P=n11∑nPi - macro-Recall(宏召回率/宏查全率)公式:
m a c r o _ R = 1 n ∑ 1 n R i macro\_R = \frac{1}{n}\sum\limits_1^n {{R_i}} macro_R=n11∑nRi - macro-F1公式:
m a c r o _ F 1 = 2 1 m a c r o _ P + 1 m a c r o _ R = 2 ∗ m a c r o _ P ∗ m a c r o _ R m a c r o _ P + m a c r o _ R macro\_F1 = \frac{2}{{\frac{1}{{macro\_P}} + \frac{1}{{macro\_R}}}} = \frac{{2*macro\_P*macro\_R}}{{macro\_P + macro\_R}} macro_F1=macro_P1+macro_R12=macro_P+macro_R2∗macro_P∗macro_R
micro指标
与macro指标不同,micro指标先求多个类别的 T P TP TP、 F P FP FP、 T N TN TN以及 F N FN FN,再计算对应均值。最后二分类的方式计算对应指标:
- micro-Precision(微精确率/ 微查准率)公式:
m i c r o _ P = T P ‾ T P ‾ + F P ‾ micro\_P = \frac{{\overline {TP} }}{{\overline {TP} + \overline {FP} }} micro_P=TP+FPTP - micro-Recall(微召回率/微查全率)公式:
m i c r o _ R = T P ‾ T P ‾ + F N ‾ micro\_R = \frac{{\overline {TP} }}{{\overline {TP} + \overline {FN} }} micro_R=TP+FNTP - micro-F1公式:
m i c r o _ F 1 = 2 1 m i c r o _ P + 1 m i c r o _ R = 2 × m i c r o _ P × m i c r o _ R m i c r o _ P + m i c r o _ R = 2 T P ‾ 2 T P ‾ + F P ‾ + F N ‾ micro\_F1 = \frac{2}{{\frac{1}{{micro\_P}} + \frac{1}{{micro\_R}}}} = \frac{{2{\rm{ \times }}micro\_P{\rm{ \times }}micro\_R}}{{micro\_P + micro\_R}} = \frac{{2\overline {TP} }}{{2\overline {TP} + \overline {FP} + \overline {FN} }} micro_F1=micro_P1+micro_R12=micro_P+micro_R2×micro_P×micro_R=2TP+FP+FN2TP
Kappa指标(科恩的卡帕系数)
用于一致性检验的指标,可用于衡量分类的效果,取值范围在
[
−
1
,
1
]
[-1,1]
[−1,1],不仅考虑了预测标签与真实标签之间的简单一致程度,还考虑了由于随机性而可能产生的偶然一致性。计算公式如下:
κ
=
p
o
−
p
e
1
−
p
e
\kappa = \frac{{{p_o} - {p_{\rm{e}}}}}{{1 - {p_{\rm{e}}}}}
κ=1−pepo−pe
其中:
p
o
=
预测正确的样本数
样本总数
{p_o} = \frac{{预测正确的样本数}}{{样本总数}}
po=样本总数预测正确的样本数
p
o
=
∑
i
n
类别
i
真实标签数
×
类别
i
预测标签数
样本总数
2
=
∑
i
n
第
i
行元素之和
×
第
i
列元素之和
矩阵所有元素和
2
{p_o} = \frac{{\sum\nolimits_i^n {类别i真实标签数×类别i预测标签数} }}{{样本总数}^2}=\frac{{\sum\nolimits_i^n {第i行元素之和×第i列元素之和} }}{{矩阵所有元素和}^2}
po=样本总数2∑in类别i真实标签数×类别i预测标签数=矩阵所有元素和2∑in第i行元素之和×第i列元素之和
- 如果Kappa等于1,则表示完全一致;
- 如果Kappa接近0甚至为负数,则意味着观察到的一致性几乎等同于或者低于随机水平,这通常表明模型性能较差;
- 在0到1之间的值则表示不同程度的部分一致性,值越大代表一致性越好。
在多分类问题中,Kappa系数能够更好地处理类别不平衡的问题,比单纯准确率Accuracy更为严格和可靠的性能度量。
多分类的案例
在实际应用中,往往更多的任务为多分类任务,现有一个家畜分类任务,对含有牛、羊、猪的图像进行分类(每个图片中只有一个类型的物体),其中牛的图片有 1748、羊的图片有 1558、猪的图片有 1473。同样利用混淆矩阵展示模型的分类结果:
| 预测的牛 | 预测的羊 | 预测的猪 | |
|---|---|---|---|
| 真实的牛 | 1494 | 119 | 135 |
| 真实的羊 | 195 | 1244 | 119 |
| 真实的马 | 223 | 124 | 1126 |
计算出对应的评价指标:
A
c
c
u
r
a
c
y
=
1494
+
1244
+
1126
1748
+
1558
+
1473
≈
0.81
Accuracy = \frac{{1494+1244+1126}}{{1748+1558+1473}}\approx 0.81
Accuracy=1748+1558+14731494+1244+1126≈0.81
m
a
c
r
o
_
P
=
1494
1912
+
1244
1487
+
1126
1380
3
≈
0.8113
macro\_P = \frac{{\frac{{1494}}{{1912}} + \frac{{1244}}{{1487}} + \frac{{1126}}{{1380}}}}{3} \approx 0.8113
macro_P=319121494+14871244+13801126≈0.8113
m
a
c
r
o
_
R
=
1494
1748
+
1244
1558
+
1126
1473
3
≈
0.8059
macro\_R= \frac{{\frac{{1494}}{{1748}} + \frac{{1244}}{{1558}} + \frac{{1126}}{{1473}}}}{3} \approx 0.8059
macro_R=317481494+15581244+14731126≈0.8059
m
a
c
r
o
_
F
1
=
2
×
0.8113
×
0.8059
0.8113
+
0.8059
≈
0.8076
macro\_F1= \frac{{2×0.8113×0.8059}}{{0.8113+0.8059}}\approx 0.8076
macro_F1=0.8113+0.80592×0.8113×0.8059≈0.8076
m
i
c
r
o
_
P
=
1494
+
1244
+
1126
3
1494
+
1244
+
1126
3
+
418
+
243
+
254
3
≈
0.8085
micro\_P = \frac{{\frac{{1494 + 1244 + 1126}}{3}}}{{\frac{{1494 + 1244 + 1126}}{3} + \frac{{418 + 243 + 254}}{3}}} \approx 0.8085
micro_P=31494+1244+1126+3418+243+25431494+1244+1126≈0.8085
m
i
c
r
o
_
R
=
1494
+
1244
+
1126
3
1494
+
1244
+
1126
3
+
254
+
314
+
347
3
≈
0.8085
micro\_R= \frac{{\frac{{1494 + 1244 + 1126}}{3}}}{{\frac{{1494 + 1244 + 1126}}{3} + \frac{{254 + 314 + 347}}{3}}} \approx 0.8085
micro_R=31494+1244+1126+3254+314+34731494+1244+1126≈0.8085
m
i
c
r
o
_
F
1
=
2
×
1494
+
1244
+
1126
3
2
×
1494
+
1244
+
1126
3
+
418
+
243
+
254
3
+
254
+
314
+
347
3
≈
0
.
8085
micro\_F1 = \frac{{2{\rm{ \times }}\frac{{1494 + 1244 + 1126}}{3}}}{{2{\rm{ \times }}\frac{{1494 + 1244 + 1126}}{3} + \frac{{{\rm{418 + 243 + 254}}}}{3} + \frac{{{\rm{254 + 314 + 347}}}}{3}}} \approx {\rm{0}}{\rm{.8085}}
micro_F1=2×31494+1244+1126+3418+243+254+3254+314+3472×31494+1244+1126≈0.8085
因为:
p
o
≈
0.8085
{p_o} \approx0.8085
po≈0.8085,
p
e
≈
0.3368
{p_e}\approx0.3368
pe≈0.3368:
κ
=
p
o
−
p
e
1
−
p
e
=
0.8085
−
0.3368
1
−
0.3368
≈
0.7113
\kappa = \frac{{{p_o} - {p_{\rm{e}}}}}{{1 - {p_{\rm{e}}}}}=\frac{{{0.8085} - {0.3368}}}{{1 - {0.3368}}}\approx0.7113
κ=1−pepo−pe=1−0.33680.8085−0.3368≈0.7113
计算macro的python代码:
# 数据
true_counts = {'牛': 1748, '羊': 1558, '猪': 1473}
correct_counts = {'牛': 1494, '羊': 1244, '猪': 1126}
confusion_matrix = {
'牛': {'牛': 1494, '羊': 119, '猪': 135},
'羊': {'牛': 195, '羊': 1244, '猪': 119},
'猪': {'牛': 223, '羊': 124, '猪': 1126},
}
# 计算 Precision、Recall 和 F1 Score
precision = {}
recall = {}
f1_score = {}
for cls in true_counts.keys():
# 精确率 (Precision) = TP / (TP + FP)
tp = confusion_matrix[cls][cls] # 真正例 (True Positive)
fp = sum(confusion_matrix[other_cls][cls] for other_cls in true_counts if other_cls != cls) # 假正例 (False Positive)
precision[cls] = tp / (tp + fp) if (tp + fp) > 0 else 0
# 召回率 (Recall) = TP / (TP + FN)
fn = sum(confusion_matrix[cls][other_cls] for other_cls in true_counts if other_cls != cls) # 假负例 (False Negative)
recall[cls] = tp / (tp + fn) if (tp + fn) > 0 else 0
# F1 分数 = 2 * (Precision * Recall) / (Precision + Recall)
f1_score[cls] = 2 * precision[cls] * recall[cls] / (precision[cls] + recall[cls]) if (precision[cls] + recall[cls]) > 0 else 0
# 计算 Macro 平均值
macro_precision = sum(precision.values()) / len(precision)
macro_recall = sum(recall.values()) / len(recall)
macro_f1 = sum(f1_score.values()) / len(f1_score)
# 输出结果
print(f"Macro Precision: {macro_precision:.4f}")
print(f"Macro Recall: {macro_recall:.4f}")
print(f"Macro F1 Score: {macro_f1:.4f}")
计算micro的python代码:
# 数据
true_counts = {'牛': 1748, '羊': 1558, '猪': 1473}
correct_counts = {'牛': 1494, '羊': 1244, '猪': 1126}
confusion_matrix = {
'牛': {'牛': 1494, '羊': 119, '猪': 135},
'羊': {'牛': 195, '羊': 1244, '猪': 119},
'猪': {'牛': 223, '羊': 124, '猪': 1126},
}
# 初始化全局统计量
global_tp = 0 # 全局真正例 (True Positive)
global_fp = 0 # 全局假正例 (False Positive)
global_fn = 0 # 全局假负例 (False Negative)
# 计算全局 TP、FP 和 FN
for cls in true_counts.keys():
tp = confusion_matrix[cls][cls] # 当前类别的真正例
fp = sum(confusion_matrix[other_cls][cls] for other_cls in true_counts if other_cls != cls) # 当前类别的假正例
fn = sum(confusion_matrix[cls][other_cls] for other_cls in true_counts if other_cls != cls) # 当前类别的假负例
global_tp += tp
global_fp += fp
global_fn += fn
# 计算 Micro 指标
micro_precision = global_tp / (global_tp + global_fp) if (global_tp + global_fp) > 0 else 0
micro_recall = global_tp / (global_tp + global_fn) if (global_tp + global_fn) > 0 else 0
micro_f1 = 2 * micro_precision * micro_recall / (micro_precision + micro_recall) if (
micro_precision + micro_recall) > 0 else 0
# 输出结果
print(f"Micro Precision: {micro_precision:.4f}")
print(f"Micro Recall: {micro_recall:.4f}")
print(f"Micro F1 Score: {micro_f1:.4f}")
计算Kappa的python代码:
# 数据
true_counts = {'牛': 1748, '羊': 1558, '猪': 1473}
correct_counts = {'牛': 1494, '羊': 1244, '猪': 1126}
confusion_matrix = {
'牛': {'牛': 1494, '羊': 119, '猪': 135},
'羊': {'牛': 195, '羊': 1244, '猪': 119},
'猪': {'牛': 223, '羊': 124, '猪': 1126},
}
# 总样本数
total_samples = sum(true_counts.values())
# 计算观察到的一致率(Po)
correct_predictions = sum(confusion_matrix[cls][cls] for cls in true_counts.keys())
Po = correct_predictions / total_samples
# 计算期望的一致率(Pe)
Pe = sum((sum(confusion_matrix[cls].values()) / total_samples) *
(sum(row[cls] for row in confusion_matrix.values()) / total_samples)
for cls in true_counts.keys())
# 计算Kappa系数
if Pe == 1:
kappa = 1 # 避免除以零的情况
else:
kappa = (Po - Pe) / (1 - Pe)
# 输出结果
print(f"Po: {Po:.4f}")
print(f"Pe: {Pe:.4f}")
print(f"Kappa: {kappa:.4f}")
总结
尽可能简单、详细的介绍了图像二分类和多分类的评价指标。