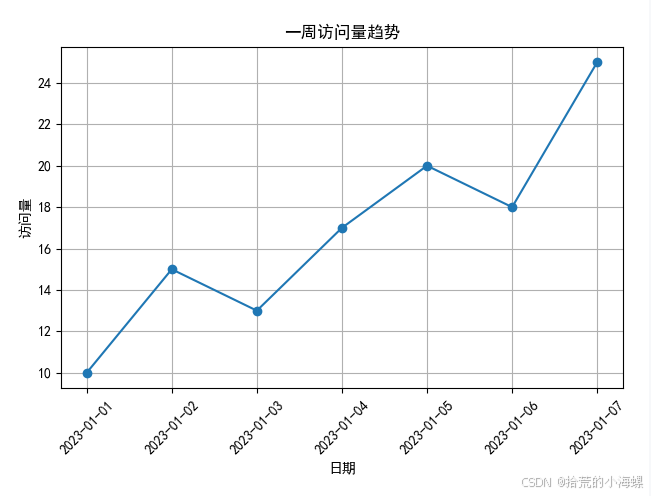
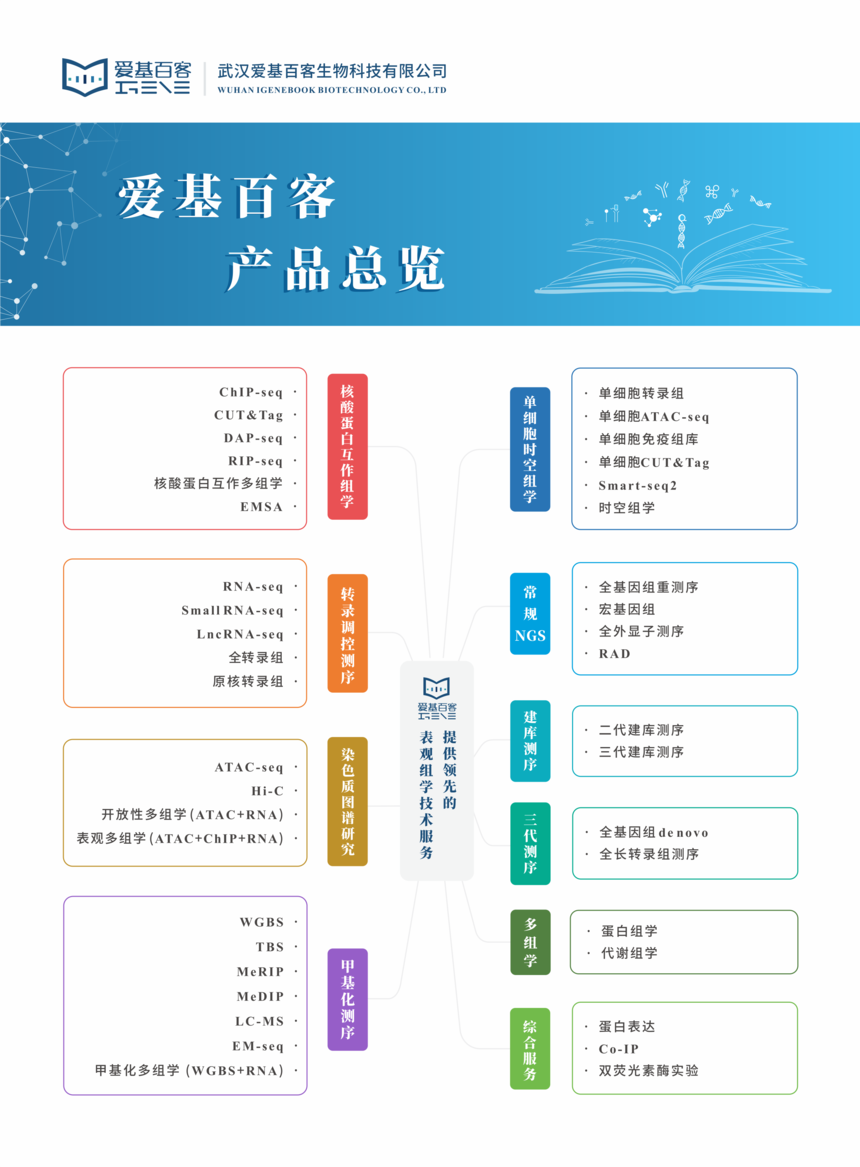
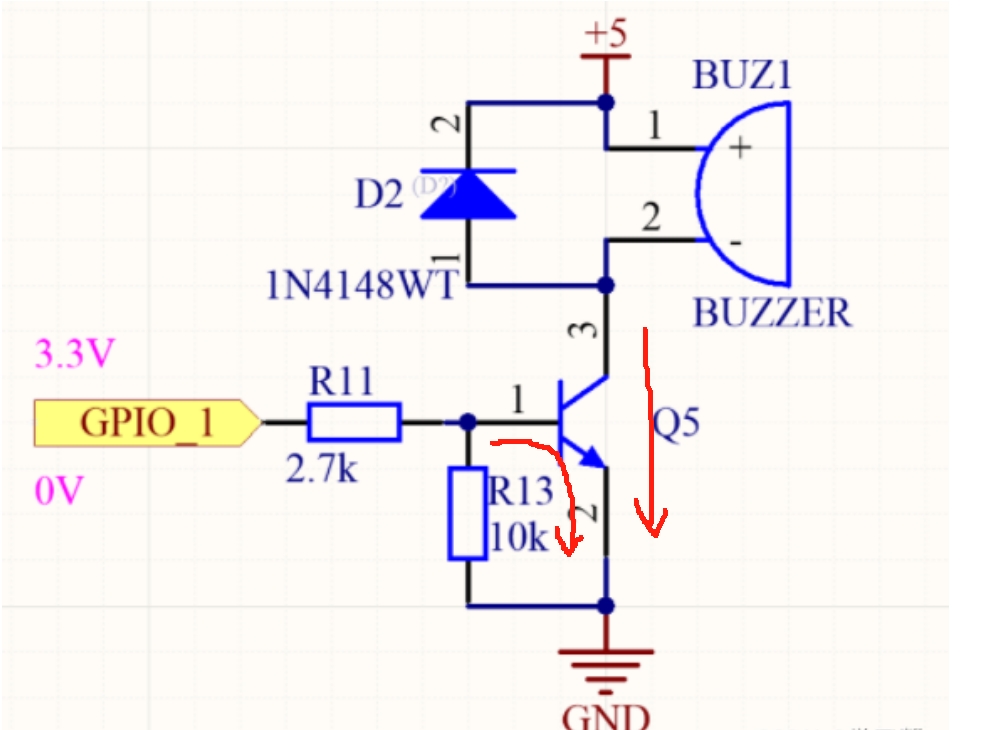
# 定义路由,分类书籍列表
@category_bp.route('/filters')
def category_book_list():
# 1.获取参数:page/pagesize/category_id/words/order
page = request.args.get('page',1,int)
pagesize = request.args.get('pagesize',10,int)
category_id = request.args.get('category_id',0,int)
# 字数类型说明:0表示所有,1表示50万字以下,2表示50~100万字,3表示100万字以上
words = request.args.get('words',-1,int)
# 排序条件说明:1表示按热度,2表示按收藏
order = request.args.get('order',1,int)
# 参数判断
if not category_id:
return jsonify(msg='缺少分类id'),400
# 2.根据分类条件category_id,查询数据,查询书籍大分类数据
categories = BookBigCategory.query.get(category_id)
# 3.判断查询结果,根据大分类数据,使用关系引用,获取二级分类数据
# 使用列表推导式,使用set集合
seconds_id = set([i.cate_id for i in categories.second_cates])
# 4.根据分类数据,查询书籍表,获取分类范围内的书籍数据
# -----过滤查询:保存的是查询结果对象,因为,后续需要对数据进行再次查询的操作
query = Book.query.filter(Book.cate_id.in_(seconds_id))
# 5.根据字数条件words查询书籍数据
# -----1表示50万字以下,2表示50~100万字,3表示100万字以上
if words == 1:
query = query.filter(Book.word_count < 500000)
elif words == 2:
query = query.filter(Book.word_count.between(500000,1000000))
elif words == 3:
query = query.filter(Book.word_count > 1000000)
# 6.根据排序条件order,按照最热、收藏数量进行排序查询
# -----1表示按热度,2表示按收藏
if order == 1:
query = query.order_by(Book.heat.desc())
elif order == 2:
query = query.order_by(Book.collect_count.desc())
else:
return jsonify(msg='错误的排序选项'),400
# 7.对查询结果进行分页处理,paginate
# -----paginate函数表示分页:返回结果为分页的对象
# 第一个参数表示页数,第二个参数表示每页的条目数,第三个参数False表示分页异常不报错
paginate = query.paginate(page,pagesize,False)
# items表示获取分页后的数据、page表示当前页数、
# pages表示每页数据条目数total表示分页的总页数
books_list = paginate.items
items = []
# 8.遍历分页数据,获取每页数据、总页数
for item in books_list:
items.append({
'id':item.book_id,
'title':item.book_name,
'introduction':item.intro,
'author':item.author_name,
'state':item.status,
'category_id':item.cate_id,
'category_name':item.cate_name,
'imgURL':'
})
# 9.转成json,返回数据
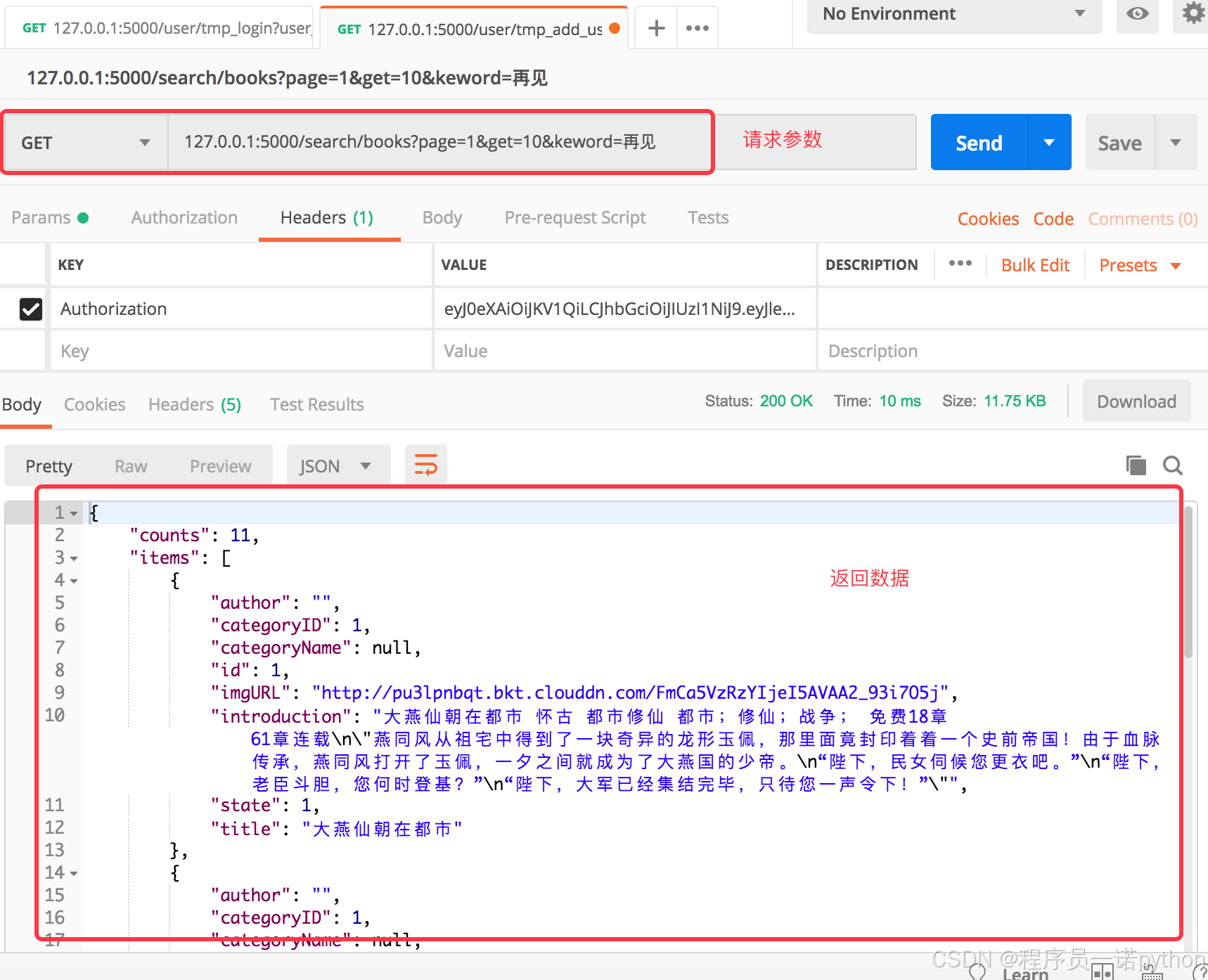
data = {
'counts':paginate.total,
'pagesize':pagesize,
'pages':paginate.pages,
'page':paginate.page,
'items':items
}
return jsonify(data)