- 🍨 本文為🔗365天深度學習訓練營 中的學習紀錄博客
- 🍖 原作者:K同学啊 | 接輔導、項目定制
一、理论知识储备
1. 残差网络的由来
ResNet主要解决了CNN在深度加深时的退化问题(梯度消失与梯度爆炸)。 虽然BN可以在一定程度上保持梯度的大小稳定,但当层级数加大时不但不容易收敛,还容易出现准确率饱和并迅速下降,这一下降由网络过于复杂导致。
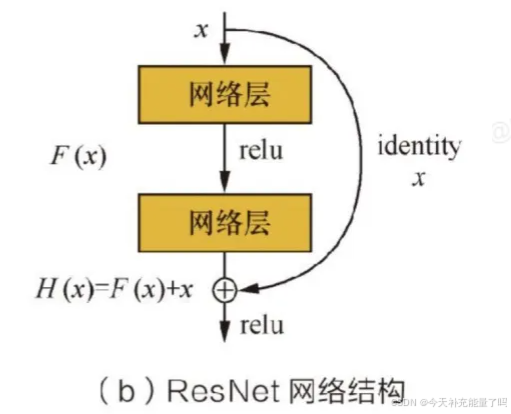
ResNet有一个额外的分支把输入直接连在输出上,使输出为分支输出+卷积输出,通过人为制造恒等映射使整个网络朝恒等映射的方向去收敛。
复杂网络通用规则:如果一个网络通过简单的手工设置参数值就可以达到想要的结果,那这种结构很容易通过训练来收敛到该结果
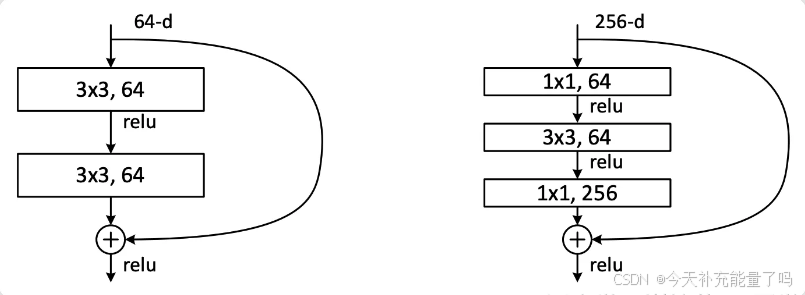
较浅的ResNet网络(左):两层残差单元包含两个相同输出通道数的3x3卷积。
较深的ResNet网络(右):先用1x1卷积进行降维,然后3x3卷积,最后用1x1升维恢复原有维度,又称bottleneck结构。
2. ResNet50
包含两个基本块:Conv Block和Identity Block
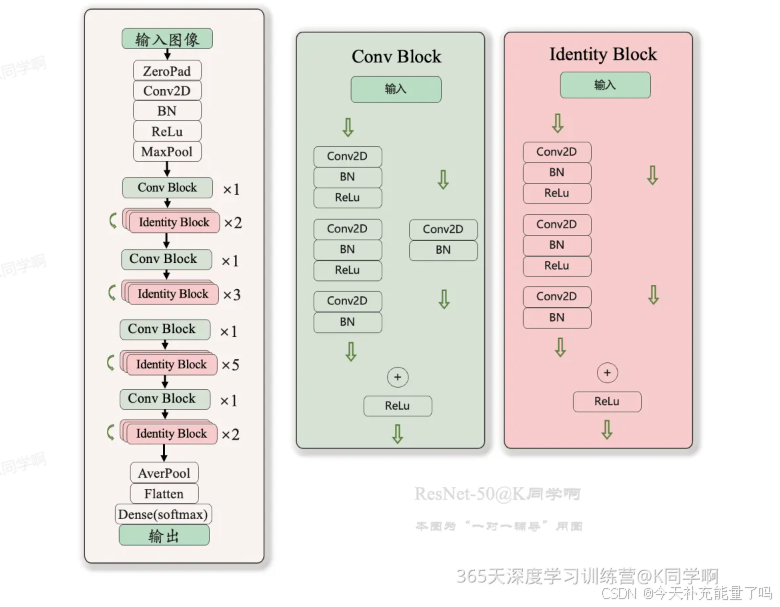
二、前期准备
1. 导入数据
import matplotlib.pyplot as plt
# set the font to SimHei to display Chinese characters
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
import os, PIL, pathlib
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers,models
data_dir = 'C:/Self_Learning/Deep_Learning/K_Codes/data/8_data/bird_photos/'
data_dir = pathlib.Path(data_dir)2. 查看数据
# Check the data
image_count = len(list(data_dir.glob('*/*.jpg')))
print('Total images:', image_count)![]()
三、数据预处理
1. 加载数据
# Load the data
batch_size = 8
img_height = 224
img_width = 224
train_ds = keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset='training',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset='validation',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
# Check the class names
class_names = train_ds.class_names
print(class_names)![]()
2. 数据可视化
# Visualize the data
plt.figure(figsize=(10, 5))
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
image = images[i].numpy().astype("uint8")
plt.imshow(image)
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()
3. 检查数据
# Check the data shape
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
4. 配置数据集
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)四、训练模型
1. 构建ResNet-50模型
# Define the ResNet50 model
def identity_block(input_tensor, kernel_size, filters, stage, block):
filters1, filters2, filters3 = filters
name_base = str(stage) + block + '_identity_block_'
x = Conv2D(filters1, (1, 1), name=name_base + 'conv1')(input_tensor)
x = BatchNormalization(name=name_base + 'bn1')(x)
x = Activation('relu', name=name_base + 'relu1')(x)
x = Conv2D(filters2, kernel_size, padding='same', name=name_base + 'conv2')(x)
x = BatchNormalization(name=name_base + 'bn2')(x)
x = Activation('relu', name=name_base + 'relu2')(x)
x = Conv2D(filters3, (1, 1), name=name_base + 'conv3')(x)
x = BatchNormalization(name=name_base + 'bn3')(x)
x = layers.add([x, input_tensor], name=name_base + 'add')
x = Activation('relu', name=name_base + 'relu4')(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)):
filters1, filters2, filters3 = filters
res_name_base = str(stage) + block + '_conv_block_res_'
name_base = str(stage) + block + '_conv_block_'
x = Conv2D(filters1, (1, 1), strides=strides, name=name_base + 'conv1')(input_tensor)
x = BatchNormalization(name=name_base + 'bn1')(x)
x = Activation('relu', name=name_base + 'relu1')(x)
x = Conv2D(filters2, kernel_size, padding='same', name=name_base + 'conv2')(x)
x = BatchNormalization(name=name_base + 'bn2')(x)
x = Activation('relu', name=name_base + 'relu2')(x)
x = Conv2D(filters3, (1, 1), name=name_base + 'conv3')(x)
x = BatchNormalization(name=name_base + 'bn3')(x)
shortcut = Conv2D(filters3, (1, 1), strides=strides, name=res_name_base + 'conv')(input_tensor)
shortcut = BatchNormalization(name=res_name_base + 'bn')(shortcut)
x = layers.add([x, shortcut], name=name_base + 'add')
x = Activation('relu', name=name_base + 'relu4')(x)
return x
def ResNet50(input_shape=(224, 224, 3), classes=1000):
img_input = Input(shape=input_shape)
x = ZeroPadding2D((3, 3))(img_input)
x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(x)
x = BatchNormalization(name='bn_conv1')(x)
x = Activation('relu')(x)
x = MaxPooling2D((3, 3), strides=(2, 2))(x)
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')
x = AveragePooling2D((7, 7), name='avg_pool')(x)
x = Flatten()(x)
x = Dense(classes, activation='softmax', name='fc1000')(x)
model = Model(img_input, x, name='ResNet50')
model.load_weights('C:/Self_Learning/Deep_Learning/K_Codes/data/8_data/ResNet50_weights_tf_dim_ordering_tf_kernels.h5', by_name=True, skip_mismatch=True)
return model
model = ResNet50()
model.summary()Model: "ResNet50"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 224, 224, 3)] 0 []
zero_padding2d_2 (ZeroPadd (None, 230, 230, 3) 0 ['input_3[0][0]']
ing2D)
conv1 (Conv2D) (None, 112, 112, 64) 9472 ['zero_padding2d_2[0][0]']
bn_conv1 (BatchNormalizati (None, 112, 112, 64) 256 ['conv1[0][0]']
on)
activation_4 (Activation) (None, 112, 112, 64) 0 ['bn_conv1[0][0]']
max_pooling2d_2 (MaxPoolin (None, 55, 55, 64) 0 ['activation_4[0][0]']
g2D)
2a_conv_block_conv1 (Conv2 (None, 55, 55, 64) 4160 ['max_pooling2d_2[0][0]']
D)
2a_conv_block_bn1 (BatchNo (None, 55, 55, 64) 256 ['2a_conv_block_conv1[0][0]']
rmalization)
2a_conv_block_relu1 (Activ (None, 55, 55, 64) 0 ['2a_conv_block_bn1[0][0]']
ation)
2a_conv_block_conv2 (Conv2 (None, 55, 55, 64) 36928 ['2a_conv_block_relu1[0][0]']
D)
2a_conv_block_bn2 (BatchNo (None, 55, 55, 64) 256 ['2a_conv_block_conv2[0][0]']
rmalization)
2a_conv_block_relu2 (Activ (None, 55, 55, 64) 0 ['2a_conv_block_bn2[0][0]']
ation)
2a_conv_block_conv3 (Conv2 (None, 55, 55, 256) 16640 ['2a_conv_block_relu2[0][0]']
D)
2a_conv_block_res_conv (Co (None, 55, 55, 256) 16640 ['max_pooling2d_2[0][0]']
nv2D)
2a_conv_block_bn3 (BatchNo (None, 55, 55, 256) 1024 ['2a_conv_block_conv3[0][0]']
rmalization)
2a_conv_block_res_bn (Batc (None, 55, 55, 256) 1024 ['2a_conv_block_res_conv[0][0]
hNormalization) ']
2a_conv_block_add (Add) (None, 55, 55, 256) 0 ['2a_conv_block_bn3[0][0]',
'2a_conv_block_res_bn[0][0]']
2a_conv_block_relu4 (Activ (None, 55, 55, 256) 0 ['2a_conv_block_add[0][0]']
ation)
2b_identity_block_conv1 (C (None, 55, 55, 64) 16448 ['2a_conv_block_relu4[0][0]']
onv2D)
2b_identity_block_bn1 (Bat (None, 55, 55, 64) 256 ['2b_identity_block_conv1[0][0
chNormalization) ]']
2b_identity_block_relu1 (A (None, 55, 55, 64) 0 ['2b_identity_block_bn1[0][0]'
ctivation) ]
2b_identity_block_conv2 (C (None, 55, 55, 64) 36928 ['2b_identity_block_relu1[0][0
onv2D) ]']
2b_identity_block_bn2 (Bat (None, 55, 55, 64) 256 ['2b_identity_block_conv2[0][0
chNormalization) ]']
2b_identity_block_relu2 (A (None, 55, 55, 64) 0 ['2b_identity_block_bn2[0][0]'
ctivation) ]
2b_identity_block_conv3 (C (None, 55, 55, 256) 16640 ['2b_identity_block_relu2[0][0
onv2D) ]']
2b_identity_block_bn3 (Bat (None, 55, 55, 256) 1024 ['2b_identity_block_conv3[0][0
chNormalization) ]']
2b_identity_block_add (Add (None, 55, 55, 256) 0 ['2b_identity_block_bn3[0][0]'
) , '2a_conv_block_relu4[0][0]']
2b_identity_block_relu4 (A (None, 55, 55, 256) 0 ['2b_identity_block_add[0][0]'
ctivation) ]
2c_identity_block_conv1 (C (None, 55, 55, 64) 16448 ['2b_identity_block_relu4[0][0
onv2D) ]']
2c_identity_block_bn1 (Bat (None, 55, 55, 64) 256 ['2c_identity_block_conv1[0][0
chNormalization) ]']
2c_identity_block_relu1 (A (None, 55, 55, 64) 0 ['2c_identity_block_bn1[0][0]'
ctivation) ]
2c_identity_block_conv2 (C (None, 55, 55, 64) 36928 ['2c_identity_block_relu1[0][0
onv2D) ]']
2c_identity_block_bn2 (Bat (None, 55, 55, 64) 256 ['2c_identity_block_conv2[0][0
chNormalization) ]']
2c_identity_block_relu2 (A (None, 55, 55, 64) 0 ['2c_identity_block_bn2[0][0]'
ctivation) ]
2c_identity_block_conv3 (C (None, 55, 55, 256) 16640 ['2c_identity_block_relu2[0][0
onv2D) ]']
2c_identity_block_bn3 (Bat (None, 55, 55, 256) 1024 ['2c_identity_block_conv3[0][0
chNormalization) ]']
2c_identity_block_add (Add (None, 55, 55, 256) 0 ['2c_identity_block_bn3[0][0]'
) , '2b_identity_block_relu4[0][
0]']
2c_identity_block_relu4 (A (None, 55, 55, 256) 0 ['2c_identity_block_add[0][0]'
ctivation) ]
3a_conv_block_conv1 (Conv2 (None, 28, 28, 128) 32896 ['2c_identity_block_relu4[0][0
D) ]']
3a_conv_block_bn1 (BatchNo (None, 28, 28, 128) 512 ['3a_conv_block_conv1[0][0]']
rmalization)
3a_conv_block_relu1 (Activ (None, 28, 28, 128) 0 ['3a_conv_block_bn1[0][0]']
ation)
3a_conv_block_conv2 (Conv2 (None, 28, 28, 128) 147584 ['3a_conv_block_relu1[0][0]']
D)
3a_conv_block_bn2 (BatchNo (None, 28, 28, 128) 512 ['3a_conv_block_conv2[0][0]']
rmalization)
3a_conv_block_relu2 (Activ (None, 28, 28, 128) 0 ['3a_conv_block_bn2[0][0]']
ation)
3a_conv_block_conv3 (Conv2 (None, 28, 28, 512) 66048 ['3a_conv_block_relu2[0][0]']
D)
3a_conv_block_res_conv (Co (None, 28, 28, 512) 131584 ['2c_identity_block_relu4[0][0
nv2D) ]']
3a_conv_block_bn3 (BatchNo (None, 28, 28, 512) 2048 ['3a_conv_block_conv3[0][0]']
rmalization)
3a_conv_block_res_bn (Batc (None, 28, 28, 512) 2048 ['3a_conv_block_res_conv[0][0]
hNormalization) ']
3a_conv_block_add (Add) (None, 28, 28, 512) 0 ['3a_conv_block_bn3[0][0]',
'3a_conv_block_res_bn[0][0]']
3a_conv_block_relu4 (Activ (None, 28, 28, 512) 0 ['3a_conv_block_add[0][0]']
ation)
3b_identity_block_conv1 (C (None, 28, 28, 128) 65664 ['3a_conv_block_relu4[0][0]']
onv2D)
3b_identity_block_bn1 (Bat (None, 28, 28, 128) 512 ['3b_identity_block_conv1[0][0
chNormalization) ]']
3b_identity_block_relu1 (A (None, 28, 28, 128) 0 ['3b_identity_block_bn1[0][0]'
ctivation) ]
3b_identity_block_conv2 (C (None, 28, 28, 128) 147584 ['3b_identity_block_relu1[0][0
onv2D) ]']
3b_identity_block_bn2 (Bat (None, 28, 28, 128) 512 ['3b_identity_block_conv2[0][0
chNormalization) ]']
3b_identity_block_relu2 (A (None, 28, 28, 128) 0 ['3b_identity_block_bn2[0][0]'
ctivation) ]
3b_identity_block_conv3 (C (None, 28, 28, 512) 66048 ['3b_identity_block_relu2[0][0
onv2D) ]']
3b_identity_block_bn3 (Bat (None, 28, 28, 512) 2048 ['3b_identity_block_conv3[0][0
chNormalization) ]']
3b_identity_block_add (Add (None, 28, 28, 512) 0 ['3b_identity_block_bn3[0][0]'
) , '3a_conv_block_relu4[0][0]']
3b_identity_block_relu4 (A (None, 28, 28, 512) 0 ['3b_identity_block_add[0][0]'
ctivation) ]
3c_identity_block_conv1 (C (None, 28, 28, 128) 65664 ['3b_identity_block_relu4[0][0
onv2D) ]']
3c_identity_block_bn1 (Bat (None, 28, 28, 128) 512 ['3c_identity_block_conv1[0][0
chNormalization) ]']
3c_identity_block_relu1 (A (None, 28, 28, 128) 0 ['3c_identity_block_bn1[0][0]'
ctivation) ]
3c_identity_block_conv2 (C (None, 28, 28, 128) 147584 ['3c_identity_block_relu1[0][0
onv2D) ]']
3c_identity_block_bn2 (Bat (None, 28, 28, 128) 512 ['3c_identity_block_conv2[0][0
chNormalization) ]']
3c_identity_block_relu2 (A (None, 28, 28, 128) 0 ['3c_identity_block_bn2[0][0]'
ctivation) ]
3c_identity_block_conv3 (C (None, 28, 28, 512) 66048 ['3c_identity_block_relu2[0][0
onv2D) ]']
3c_identity_block_bn3 (Bat (None, 28, 28, 512) 2048 ['3c_identity_block_conv3[0][0
chNormalization) ]']
3c_identity_block_add (Add (None, 28, 28, 512) 0 ['3c_identity_block_bn3[0][0]'
) , '3b_identity_block_relu4[0][
0]']
3c_identity_block_relu4 (A (None, 28, 28, 512) 0 ['3c_identity_block_add[0][0]'
ctivation) ]
3d_identity_block_conv1 (C (None, 28, 28, 128) 65664 ['3c_identity_block_relu4[0][0
onv2D) ]']
3d_identity_block_bn1 (Bat (None, 28, 28, 128) 512 ['3d_identity_block_conv1[0][0
chNormalization) ]']
3d_identity_block_relu1 (A (None, 28, 28, 128) 0 ['3d_identity_block_bn1[0][0]'
ctivation) ]
3d_identity_block_conv2 (C (None, 28, 28, 128) 147584 ['3d_identity_block_relu1[0][0
onv2D) ]']
3d_identity_block_bn2 (Bat (None, 28, 28, 128) 512 ['3d_identity_block_conv2[0][0
chNormalization) ]']
3d_identity_block_relu2 (A (None, 28, 28, 128) 0 ['3d_identity_block_bn2[0][0]'
ctivation) ]
3d_identity_block_conv3 (C (None, 28, 28, 512) 66048 ['3d_identity_block_relu2[0][0
onv2D) ]']
3d_identity_block_bn3 (Bat (None, 28, 28, 512) 2048 ['3d_identity_block_conv3[0][0
chNormalization) ]']
3d_identity_block_add (Add (None, 28, 28, 512) 0 ['3d_identity_block_bn3[0][0]'
) , '3c_identity_block_relu4[0][
0]']
3d_identity_block_relu4 (A (None, 28, 28, 512) 0 ['3d_identity_block_add[0][0]'
ctivation) ]
4a_conv_block_conv1 (Conv2 (None, 14, 14, 256) 131328 ['3d_identity_block_relu4[0][0
D) ]']
4a_conv_block_bn1 (BatchNo (None, 14, 14, 256) 1024 ['4a_conv_block_conv1[0][0]']
rmalization)
4a_conv_block_relu1 (Activ (None, 14, 14, 256) 0 ['4a_conv_block_bn1[0][0]']
ation)
4a_conv_block_conv2 (Conv2 (None, 14, 14, 256) 590080 ['4a_conv_block_relu1[0][0]']
D)
4a_conv_block_bn2 (BatchNo (None, 14, 14, 256) 1024 ['4a_conv_block_conv2[0][0]']
rmalization)
4a_conv_block_relu2 (Activ (None, 14, 14, 256) 0 ['4a_conv_block_bn2[0][0]']
ation)
4a_conv_block_conv3 (Conv2 (None, 14, 14, 1024) 263168 ['4a_conv_block_relu2[0][0]']
D)
4a_conv_block_res_conv (Co (None, 14, 14, 1024) 525312 ['3d_identity_block_relu4[0][0
nv2D) ]']
4a_conv_block_bn3 (BatchNo (None, 14, 14, 1024) 4096 ['4a_conv_block_conv3[0][0]']
rmalization)
4a_conv_block_res_bn (Batc (None, 14, 14, 1024) 4096 ['4a_conv_block_res_conv[0][0]
hNormalization) ']
4a_conv_block_add (Add) (None, 14, 14, 1024) 0 ['4a_conv_block_bn3[0][0]',
'4a_conv_block_res_bn[0][0]']
4a_conv_block_relu4 (Activ (None, 14, 14, 1024) 0 ['4a_conv_block_add[0][0]']
ation)
4b_identity_block_conv1 (C (None, 14, 14, 256) 262400 ['4a_conv_block_relu4[0][0]']
onv2D)
4b_identity_block_bn1 (Bat (None, 14, 14, 256) 1024 ['4b_identity_block_conv1[0][0
chNormalization) ]']
4b_identity_block_relu1 (A (None, 14, 14, 256) 0 ['4b_identity_block_bn1[0][0]'
ctivation) ]
4b_identity_block_conv2 (C (None, 14, 14, 256) 590080 ['4b_identity_block_relu1[0][0
onv2D) ]']
4b_identity_block_bn2 (Bat (None, 14, 14, 256) 1024 ['4b_identity_block_conv2[0][0
chNormalization) ]']
4b_identity_block_relu2 (A (None, 14, 14, 256) 0 ['4b_identity_block_bn2[0][0]'
ctivation) ]
4b_identity_block_conv3 (C (None, 14, 14, 1024) 263168 ['4b_identity_block_relu2[0][0
onv2D) ]']
4b_identity_block_bn3 (Bat (None, 14, 14, 1024) 4096 ['4b_identity_block_conv3[0][0
chNormalization) ]']
4b_identity_block_add (Add (None, 14, 14, 1024) 0 ['4b_identity_block_bn3[0][0]'
) , '4a_conv_block_relu4[0][0]']
4b_identity_block_relu4 (A (None, 14, 14, 1024) 0 ['4b_identity_block_add[0][0]'
ctivation) ]
4c_identity_block_conv1 (C (None, 14, 14, 256) 262400 ['4b_identity_block_relu4[0][0
onv2D) ]']
4c_identity_block_bn1 (Bat (None, 14, 14, 256) 1024 ['4c_identity_block_conv1[0][0
chNormalization) ]']
4c_identity_block_relu1 (A (None, 14, 14, 256) 0 ['4c_identity_block_bn1[0][0]'
ctivation) ]
4c_identity_block_conv2 (C (None, 14, 14, 256) 590080 ['4c_identity_block_relu1[0][0
onv2D) ]']
4c_identity_block_bn2 (Bat (None, 14, 14, 256) 1024 ['4c_identity_block_conv2[0][0
chNormalization) ]']
4c_identity_block_relu2 (A (None, 14, 14, 256) 0 ['4c_identity_block_bn2[0][0]'
ctivation) ]
4c_identity_block_conv3 (C (None, 14, 14, 1024) 263168 ['4c_identity_block_relu2[0][0
onv2D) ]']
4c_identity_block_bn3 (Bat (None, 14, 14, 1024) 4096 ['4c_identity_block_conv3[0][0
chNormalization) ]']
4c_identity_block_add (Add (None, 14, 14, 1024) 0 ['4c_identity_block_bn3[0][0]'
) , '4b_identity_block_relu4[0][
0]']
4c_identity_block_relu4 (A (None, 14, 14, 1024) 0 ['4c_identity_block_add[0][0]'
ctivation) ]
4d_identity_block_conv1 (C (None, 14, 14, 256) 262400 ['4c_identity_block_relu4[0][0
onv2D) ]']
4d_identity_block_bn1 (Bat (None, 14, 14, 256) 1024 ['4d_identity_block_conv1[0][0
chNormalization) ]']
4d_identity_block_relu1 (A (None, 14, 14, 256) 0 ['4d_identity_block_bn1[0][0]'
ctivation) ]
4d_identity_block_conv2 (C (None, 14, 14, 256) 590080 ['4d_identity_block_relu1[0][0
onv2D) ]']
4d_identity_block_bn2 (Bat (None, 14, 14, 256) 1024 ['4d_identity_block_conv2[0][0
chNormalization) ]']
4d_identity_block_relu2 (A (None, 14, 14, 256) 0 ['4d_identity_block_bn2[0][0]'
ctivation) ]
4d_identity_block_conv3 (C (None, 14, 14, 1024) 263168 ['4d_identity_block_relu2[0][0
onv2D) ]']
4d_identity_block_bn3 (Bat (None, 14, 14, 1024) 4096 ['4d_identity_block_conv3[0][0
chNormalization) ]']
4d_identity_block_add (Add (None, 14, 14, 1024) 0 ['4d_identity_block_bn3[0][0]'
) , '4c_identity_block_relu4[0][
0]']
4d_identity_block_relu4 (A (None, 14, 14, 1024) 0 ['4d_identity_block_add[0][0]'
ctivation) ]
4e_identity_block_conv1 (C (None, 14, 14, 256) 262400 ['4d_identity_block_relu4[0][0
onv2D) ]']
4e_identity_block_bn1 (Bat (None, 14, 14, 256) 1024 ['4e_identity_block_conv1[0][0
chNormalization) ]']
4e_identity_block_relu1 (A (None, 14, 14, 256) 0 ['4e_identity_block_bn1[0][0]'
ctivation) ]
4e_identity_block_conv2 (C (None, 14, 14, 256) 590080 ['4e_identity_block_relu1[0][0
onv2D) ]']
4e_identity_block_bn2 (Bat (None, 14, 14, 256) 1024 ['4e_identity_block_conv2[0][0
chNormalization) ]']
4e_identity_block_relu2 (A (None, 14, 14, 256) 0 ['4e_identity_block_bn2[0][0]'
ctivation) ]
4e_identity_block_conv3 (C (None, 14, 14, 1024) 263168 ['4e_identity_block_relu2[0][0
onv2D) ]']
4e_identity_block_bn3 (Bat (None, 14, 14, 1024) 4096 ['4e_identity_block_conv3[0][0
chNormalization) ]']
4e_identity_block_add (Add (None, 14, 14, 1024) 0 ['4e_identity_block_bn3[0][0]'
) , '4d_identity_block_relu4[0][
0]']
4e_identity_block_relu4 (A (None, 14, 14, 1024) 0 ['4e_identity_block_add[0][0]'
ctivation) ]
4f_identity_block_conv1 (C (None, 14, 14, 256) 262400 ['4e_identity_block_relu4[0][0
onv2D) ]']
4f_identity_block_bn1 (Bat (None, 14, 14, 256) 1024 ['4f_identity_block_conv1[0][0
chNormalization) ]']
4f_identity_block_relu1 (A (None, 14, 14, 256) 0 ['4f_identity_block_bn1[0][0]'
ctivation) ]
4f_identity_block_conv2 (C (None, 14, 14, 256) 590080 ['4f_identity_block_relu1[0][0
onv2D) ]']
4f_identity_block_bn2 (Bat (None, 14, 14, 256) 1024 ['4f_identity_block_conv2[0][0
chNormalization) ]']
4f_identity_block_relu2 (A (None, 14, 14, 256) 0 ['4f_identity_block_bn2[0][0]'
ctivation) ]
4f_identity_block_conv3 (C (None, 14, 14, 1024) 263168 ['4f_identity_block_relu2[0][0
onv2D) ]']
4f_identity_block_bn3 (Bat (None, 14, 14, 1024) 4096 ['4f_identity_block_conv3[0][0
chNormalization) ]']
4f_identity_block_add (Add (None, 14, 14, 1024) 0 ['4f_identity_block_bn3[0][0]'
) , '4e_identity_block_relu4[0][
0]']
4f_identity_block_relu4 (A (None, 14, 14, 1024) 0 ['4f_identity_block_add[0][0]'
ctivation) ]
5a_conv_block_conv1 (Conv2 (None, 7, 7, 512) 524800 ['4f_identity_block_relu4[0][0
D) ]']
5a_conv_block_bn1 (BatchNo (None, 7, 7, 512) 2048 ['5a_conv_block_conv1[0][0]']
rmalization)
5a_conv_block_relu1 (Activ (None, 7, 7, 512) 0 ['5a_conv_block_bn1[0][0]']
ation)
5a_conv_block_conv2 (Conv2 (None, 7, 7, 512) 2359808 ['5a_conv_block_relu1[0][0]']
D)
5a_conv_block_bn2 (BatchNo (None, 7, 7, 512) 2048 ['5a_conv_block_conv2[0][0]']
rmalization)
5a_conv_block_relu2 (Activ (None, 7, 7, 512) 0 ['5a_conv_block_bn2[0][0]']
ation)
5a_conv_block_conv3 (Conv2 (None, 7, 7, 2048) 1050624 ['5a_conv_block_relu2[0][0]']
D)
5a_conv_block_res_conv (Co (None, 7, 7, 2048) 2099200 ['4f_identity_block_relu4[0][0
nv2D) ]']
5a_conv_block_bn3 (BatchNo (None, 7, 7, 2048) 8192 ['5a_conv_block_conv3[0][0]']
rmalization)
5a_conv_block_res_bn (Batc (None, 7, 7, 2048) 8192 ['5a_conv_block_res_conv[0][0]
hNormalization) ']
5a_conv_block_add (Add) (None, 7, 7, 2048) 0 ['5a_conv_block_bn3[0][0]',
'5a_conv_block_res_bn[0][0]']
5a_conv_block_relu4 (Activ (None, 7, 7, 2048) 0 ['5a_conv_block_add[0][0]']
ation)
5b_identity_block_conv1 (C (None, 7, 7, 512) 1049088 ['5a_conv_block_relu4[0][0]']
onv2D)
5b_identity_block_bn1 (Bat (None, 7, 7, 512) 2048 ['5b_identity_block_conv1[0][0
chNormalization) ]']
5b_identity_block_relu1 (A (None, 7, 7, 512) 0 ['5b_identity_block_bn1[0][0]'
ctivation) ]
5b_identity_block_conv2 (C (None, 7, 7, 512) 2359808 ['5b_identity_block_relu1[0][0
onv2D) ]']
5b_identity_block_bn2 (Bat (None, 7, 7, 512) 2048 ['5b_identity_block_conv2[0][0
chNormalization) ]']
5b_identity_block_relu2 (A (None, 7, 7, 512) 0 ['5b_identity_block_bn2[0][0]'
ctivation) ]
5b_identity_block_conv3 (C (None, 7, 7, 2048) 1050624 ['5b_identity_block_relu2[0][0
onv2D) ]']
5b_identity_block_bn3 (Bat (None, 7, 7, 2048) 8192 ['5b_identity_block_conv3[0][0
chNormalization) ]']
5b_identity_block_add (Add (None, 7, 7, 2048) 0 ['5b_identity_block_bn3[0][0]'
) , '5a_conv_block_relu4[0][0]']
5b_identity_block_relu4 (A (None, 7, 7, 2048) 0 ['5b_identity_block_add[0][0]'
ctivation) ]
5c_identity_block_conv1 (C (None, 7, 7, 512) 1049088 ['5b_identity_block_relu4[0][0
onv2D) ]']
5c_identity_block_bn1 (Bat (None, 7, 7, 512) 2048 ['5c_identity_block_conv1[0][0
chNormalization) ]']
5c_identity_block_relu1 (A (None, 7, 7, 512) 0 ['5c_identity_block_bn1[0][0]'
ctivation) ]
5c_identity_block_conv2 (C (None, 7, 7, 512) 2359808 ['5c_identity_block_relu1[0][0
onv2D) ]']
5c_identity_block_bn2 (Bat (None, 7, 7, 512) 2048 ['5c_identity_block_conv2[0][0
chNormalization) ]']
5c_identity_block_relu2 (A (None, 7, 7, 512) 0 ['5c_identity_block_bn2[0][0]'
ctivation) ]
5c_identity_block_conv3 (C (None, 7, 7, 2048) 1050624 ['5c_identity_block_relu2[0][0
onv2D) ]']
5c_identity_block_bn3 (Bat (None, 7, 7, 2048) 8192 ['5c_identity_block_conv3[0][0
chNormalization) ]']
5c_identity_block_add (Add (None, 7, 7, 2048) 0 ['5c_identity_block_bn3[0][0]'
) , '5b_identity_block_relu4[0][
0]']
5c_identity_block_relu4 (A (None, 7, 7, 2048) 0 ['5c_identity_block_add[0][0]'
ctivation) ]
avg_pool (AveragePooling2D (None, 1, 1, 2048) 0 ['5c_identity_block_relu4[0][0
) ]']
flatten (Flatten) (None, 2048) 0 ['avg_pool[0][0]']
fc1000 (Dense) (None, 1000) 2049000 ['flatten[0][0]']
==================================================================================================
Total params: 25636712 (97.80 MB)
Trainable params: 25583592 (97.59 MB)
Non-trainable params: 53120 (207.50 KB)
__________________________________________________________________________________________________
2. 编译模型
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])3. 训练模型
# Train the model
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)Epoch 1/10
57/57 [==============================] - 476s 7s/step - loss: 2.3338 - accuracy: 0.4779 - val_loss: 95.4034 - val_accuracy: 0.2301
Epoch 2/10
57/57 [==============================] - 259s 5s/step - loss: 1.0860 - accuracy: 0.6438 - val_loss: 4.2480 - val_accuracy: 0.2920
Epoch 3/10
57/57 [==============================] - 247s 4s/step - loss: 0.7115 - accuracy: 0.7212 - val_loss: 0.9247 - val_accuracy: 0.6637
Epoch 4/10
57/57 [==============================] - 254s 4s/step - loss: 0.7610 - accuracy: 0.7456 - val_loss: 0.7742 - val_accuracy: 0.6903
Epoch 5/10
57/57 [==============================] - 276s 5s/step - loss: 0.5945 - accuracy: 0.7544 - val_loss: 0.6813 - val_accuracy: 0.7434
Epoch 6/10
57/57 [==============================] - 282s 5s/step - loss: 0.6199 - accuracy: 0.8053 - val_loss: 0.9435 - val_accuracy: 0.8053
Epoch 7/10
57/57 [==============================] - 252s 4s/step - loss: 0.5086 - accuracy: 0.8363 - val_loss: 1.8492 - val_accuracy: 0.5752
Epoch 8/10
57/57 [==============================] - 253s 4s/step - loss: 0.3915 - accuracy: 0.8827 - val_loss: 1.2361 - val_accuracy: 0.6018
Epoch 9/10
57/57 [==============================] - 247s 4s/step - loss: 0.5021 - accuracy: 0.8296 - val_loss: 2.4609 - val_accuracy: 0.5929
Epoch 10/10
57/57 [==============================] - 248s 4s/step - loss: 0.5328 - accuracy: 0.8186 - val_loss: 2.3554 - val_accuracy: 0.4779四、模型评估
1. Loss与Accuracy图
# Evaluate the model
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()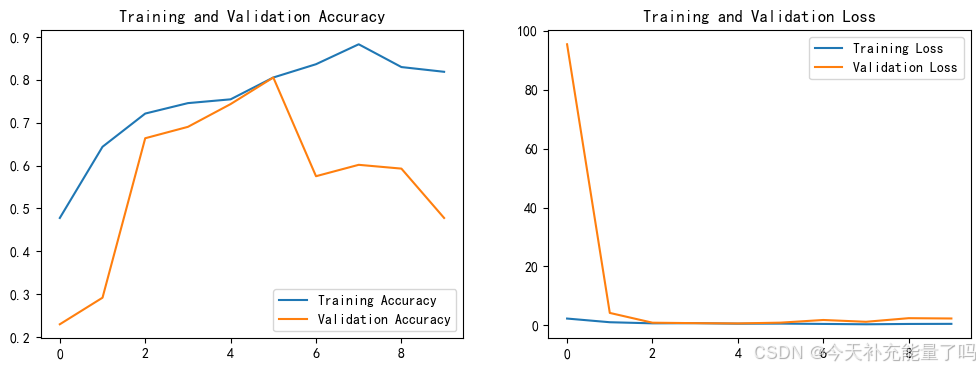
2. 预测
# Predict on new images
plt.figure(figsize=(10, 5))
for images, labels in val_ds.take(1):
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
image = images[i].numpy().astype("uint8")
plt.imshow(image)
img_array = tf.expand_dims(images[i], 0)
predictions = model.predict(img_array)
plt.title(class_names[np.argmax(predictions)])
plt.axis("off")
1/1 [==============================] - 2s 2s/step
1/1 [==============================] - 0s 145ms/step
1/1 [==============================] - 0s 157ms/step
1/1 [==============================] - 0s 166ms/step
1/1 [==============================] - 0s 137ms/step
1/1 [==============================] - 0s 126ms/step
1/1 [==============================] - 0s 144ms/step
1/1 [==============================] - 0s 162ms/step
五、Pytorch版本代码
import os
import pathlib
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import torch
from torch import nn
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
from torchvision.utils import make_grid
# Set font for Chinese labels (SimHei)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Paths
data_dir = 'C:/Self_Learning/Deep_Learning/K_Codes/data/8_data/bird_photos/'
data_dir = pathlib.Path(data_dir)
# Transforms
img_height = 224
img_width = 224
batch_size = 8
transform = transforms.Compose([
transforms.Resize((img_height, img_width)),
transforms.ToTensor()
])
# Load datasets
train_ds = datasets.ImageFolder(data_dir, transform=transform)
class_names = train_ds.classes
num_classes = len(class_names)
print("Classes:", class_names)
# Split into train and val
train_size = int(0.8 * len(train_ds))
val_size = len(train_ds) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(train_ds, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# Visualise images
def show_batch(images, labels):
img_grid = make_grid(images, nrow=4)
npimg = img_grid.numpy()
plt.figure(figsize=(10, 5))
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.title(" / ".join([class_names[label] for label in labels]))
plt.axis("off")
plt.show()
images, labels = next(iter(train_loader))
show_batch(images, labels)
# Define ResNet50 model
model = models.resnet50(pretrained=False)
model.fc = nn.Linear(model.fc.in_features, num_classes)
# Load pretrained weights if needed (optional)
# model.load_state_dict(torch.load('your_resnet50_weights.pth'))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# Loss & Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# Training loop
epochs = 10
train_acc_history = []
val_acc_history = []
train_loss_history = []
val_loss_history = []
for epoch in range(epochs):
model.train()
train_loss, train_correct = 0.0, 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
train_correct += (outputs.argmax(1) == labels).sum().item()
train_loss /= len(train_loader.dataset)
train_acc = train_correct / len(train_loader.dataset)
# Validation
model.eval()
val_loss, val_correct = 0.0, 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item() * inputs.size(0)
val_correct += (outputs.argmax(1) == labels).sum().item()
val_loss /= len(val_loader.dataset)
val_acc = val_correct / len(val_loader.dataset)
train_loss_history.append(train_loss)
val_loss_history.append(val_loss)
train_acc_history.append(train_acc)
val_acc_history.append(val_acc)
print(f"Epoch {epoch+1}/{epochs}: "
f"Train Loss {train_loss:.4f}, Acc {train_acc:.4f} | "
f"Val Loss {val_loss:.4f}, Acc {val_acc:.4f}")
# Plot training results
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_acc_history, label='Train Acc')
plt.plot(val_acc_history, label='Val Acc')
plt.legend()
plt.title('Accuracy')
plt.subplot(1, 2, 2)
plt.plot(train_loss_history, label='Train Loss')
plt.plot(val_loss_history, label='Val Loss')
plt.legend()
plt.title('Loss')
plt.show()
# Predict on validation batch
model.eval()
images, labels = next(iter(val_loader))
images = images.to(device)
outputs = model(images)
preds = outputs.argmax(1)
# Show predictions
plt.figure(figsize=(10, 5))
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
plt.imshow(images[i].cpu().permute(1, 2, 0).numpy())
plt.title(class_names[preds[i]])
plt.axis("off")
plt.show()
![[MySQL初阶]MySQL(8)索引机制:下](https://i-blog.csdnimg.cn/direct/2c4f3c1888d641ff94c68b40d9f7a20b.png#pic_center)
![Muduo网络库实现 [九] - EventLoopThread模块](https://i-blog.csdnimg.cn/direct/8f7309bbfd0b4dd79476aa4c66ddf5ca.png)