C++标准库不只是包含了顺序容器,还包含一些为满足特殊需求而设计的容器,它们提供简单的接口。
这些容器可被归类为容器适配器(container adapter),它们是改造别的标准顺序容器,使之满足特殊需求的新容器。
适配器:也称配置器,把一种接口转为另一种接口。
有三种标准的 容器适配器: stack(栈)、queue(队列)和priority queue(优先级队列)。 priority queue就是“根据排序准则,自动将元素排序”的队列,其所谓“下一个””元素总是拥有最高优先级。
stack栈
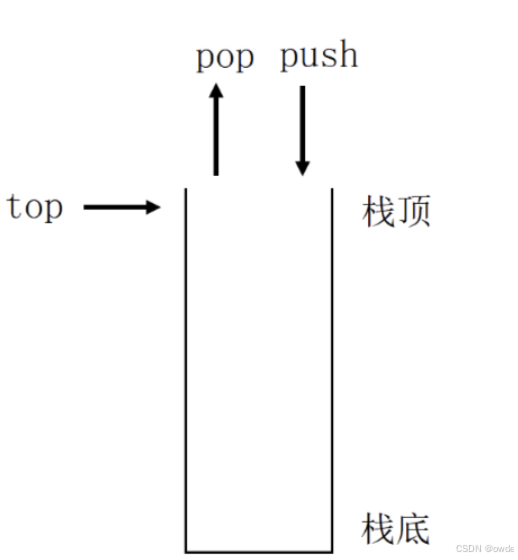
stack 栈是一种只在一端(栈顶)进行数据插入(入栈)和删除(出栈)的数据结构,它满足后进先出(LIFO)的特性。
使用push(入栈)将数据放入stack,使用pop(出栈)将元素从容器中移除。 POP PUSH栈顶TOP栈底
使用stack,必须包含头文件:
#include <stack>
在头文件中,class stack定义如下:
namespace std{
template <typename T,
typename Container = deque<T>>
class stack;
}第一个参数T代表类型,第二个参数用来定义stack内部存放数据的容器,默认为deque。之所以选择deque而非vector,是因为deque移除数据时可能会释放内存,并在插入数据需要扩容时不需要复制所有的数据。
例如,以下定义了一个元素类型为整数的 stack:
std::stack<int> st;
stack 只是很单纯地把各项操作转化为内部容器对应的函数调用。你可以使用任何支持 back()、push_back()和pop_back()成员函数的标准容器支持 stack。例如你可以使用 vector或list 来存放数据:
stack<int,vector<int>> st;//整型栈,使用vector存放数据
注意:forword_list和array不可以作为其容器
定义及初始化
#include <iostream>
#include <stack>
#include <vector>
#include <list>
using namespace std;
int main()
{
stack <char> s1;//创建一个默认的栈,最常用
stack <char, deque<char> > s2;//显示创建用deque保存数据的栈,和s1等价
stack <int, vector<int> > s3;//创建用vector保存数据的栈
stack <int, list<int> > s4;//创建用list保存数据的栈
return 0;
}先创建一个空的栈,然后往里面存放数据。
常用操作
stack栈的操作比较简单,不支持迭代器和运算符,只有几个简单的成员函数。 empty成员函数
empty成员函数
判断栈是否为空。
//判空
bool IsEmpty(PLStack ps)
{
return ps->next == NULL;
}pop成员函数
出栈函数,删除栈顶元素。
//获取栈顶元素的值,并且删除
bool Pop(PLStack ps, int* rtval)
{
assert(ps != NULL);
if (ps == NULL)
return false;
if (IsEmpty(ps))
return false;
*rtval = ps->next->date;
LSNode* p = ps->next;
ps->next = ps->next->next;
free(p);
return true;
}push成员函数
入栈函数,往栈顶添加数据。
//往栈中入数据(入栈操作)
bool Push(PLStack ps, int val)
{
assert(ps != NULL);
if (ps == NULL)
return false;
LSNode* p = (LSNode*)malloc(sizeof(LSNode));
assert(p != NULL);
p->date = val;
p->next = ps->next;
ps->next = p;
return false;
}size成员函数
返回栈的数据个数。
//获取栈中有效数据的个数
int GetLength(PLStack ps)
{
assert(ps != NULL);
if (ps == NULL)
return 0;
int count = 0;
for (LSNode* p = ps->next; p != NULL; p = p->next)
{
count++;
}
return count;
}top成员函数
返回栈顶元素的引用。
//获取栈顶元素的值,但不删除
bool GetTop(PLStack ps, int* rtval)
{
assert(ps != NULL);
if (ps == NULL)
return false;
if (IsEmpty(ps))
return false;
*rtval = ps->next->date;
return true;
}栈的实现方式
链表实现:链表实现栈则更加灵活,它不需要预先分配固定大小的内存空间,适用于栈的大小动态变化且难以预估的场景。在链表实现中,每个节点包含数据和指向下一个节点的指针。栈顶对应链表的头节点,入栈和出栈操作都在链表头部进行,时间复杂度同样为 O (1)。
.h文件
#pragma once
//链式栈
typedef struct LSNode
{
int date;
struct LSNode* next;
}LSNode, * PLStack;
//初始化
void InitStack(PLStack ps);
//往栈中入数据(入栈操作)
bool Push(PLStack ps, int val);
//获取栈顶元素的值,但不删除
bool GetTop(PLStack ps, int* rtval);
//获取栈顶元素的值,并且删除
bool Pop(PLStack ps, int* rtval);
//判空
bool IsEmpty(PLStack ps);
//获取栈中有效数据的个数
int GetLength(PLStack ps);
//清空所有的数据
void Clear(PLStack ps);
//销毁
void Destroy(PLStack ps);.cpp文件
#include "Istak.h"
#include <iostream>
#include <cassert>
using namespace std;
//初始化
void InitStack(PLStack ps)
{
assert(ps != NULL);
if (ps == NULL)
return;
ps->next = NULL;
}
//往栈中入数据(入栈操作)
bool Push(PLStack ps, int val)
{
assert(ps != NULL);
if (ps == NULL)
return false;
LSNode* p = (LSNode*)malloc(sizeof(LSNode));
assert(p != NULL);
p->date = val;
p->next = ps->next;
ps->next = p;
return false;
}
//获取栈顶元素的值,但不删除
bool GetTop(PLStack ps, int* rtval)
{
assert(ps != NULL);
if (ps == NULL)
return false;
if (IsEmpty(ps))
return false;
*rtval = ps->next->date;
return true;
}
//获取栈顶元素的值,并且删除
bool Pop(PLStack ps, int* rtval)
{
assert(ps != NULL);
if (ps == NULL)
return false;
if (IsEmpty(ps))
return false;
*rtval = ps->next->date;
LSNode* p = ps->next;
ps->next = ps->next->next;
free(p);
return true;
}
//判空
bool IsEmpty(PLStack ps)
{
return ps->next == NULL;
}
//获取栈中有效数据的个数
int GetLength(PLStack ps)
{
assert(ps != NULL);
if (ps == NULL)
return 0;
int count = 0;
for (LSNode* p = ps->next; p != NULL; p = p->next)
{
count++;
}
return count;
}
//清空所有的数据
void Clear(PLStack ps)
{
Destroy(ps);
}
//销毁
void Destroy(PLStack ps)
{
LSNode* p;
while (ps->next != NULL)
{
p = ps->next;
ps->next = p->next;
free(p);
}
}栈的应用场景
1.表达式求值
在数学表达式求值中,栈发挥着关键作用。例如,对于后缀表达式(逆波兰表达式),我们可以利用栈来高效地计算结果。后缀表达式将运算符放在操作数之后,避免了括号带来的优先级判断复杂性。计算时,从左到右扫描后缀表达式,遇到操作数就将其入栈,遇到运算符则从栈中弹出相应数量的操作数进行运算,并将结果入栈。最终,栈顶元素即为表达式的计算结果。以表达式 “3 4 + 2 *” 为例,计算过程如下:
扫描到 3,入栈,栈:[3]
扫描到 4,入栈,栈:[3, 4]
扫描到 +,弹出 4 和 3,计算 3 + 4 = 7,将 7 入栈,栈:[7]
扫描到 2,入栈,栈:[7, 2]
扫描到 *,弹出 2 和 7,计算 7 * 2 = 14,将 14 入栈,栈:[14]
最终结果为 14
2.括号匹配
在编译器和文本编辑器中,常常需要检查代码中的括号是否正确匹配,如圆括号、方括号和花括号。利用栈可以轻松解决这个问题。当遇到左括号时,将其入栈;遇到右括号时,从栈中弹出对应的左括号进行匹配。如果在匹配过程中栈为空或者匹配失败,说明括号不匹配。例如,对于字符串 “{[()]}”,处理过程如下:
遇到 {,入栈,栈:[{]
遇到 [,入栈,栈:[{, []
遇到 (,入栈,栈:[{, [, (]
遇到 ),弹出 (进行匹配,栈:[{, []
遇到 ],弹出 [进行匹配,栈:[{]
遇到 },弹出 {进行匹配,栈:[]
匹配成功
3.函数调用栈
在程序执行过程中,函数调用是通过栈来管理的。当一个函数被调用时,它的相关信息,如参数、局部变量和返回地址等,会被压入栈中。当函数执行完毕返回时,这些信息会从栈中弹出,程序继续执行调用函数的下一条指令。例如,在一个包含多个函数嵌套调用的程序中,栈记录了函数调用的顺序和状态,确保函数能够正确返回和继续执行。假设函数 A 调用函数 B,函数 B 又调用函数 C,栈的状态变化如下:
调用 A,A 的相关信息入栈,栈:[A]
A 中调用 B,B 的相关信息入栈,栈:[A, B]
B 中调用 C,C 的相关信息入栈,栈:[A, B, C]
C 执行完毕返回,C 的信息出栈,栈:[A, B]
B 执行完毕返回,B 的信息出栈,栈:[A]
A 执行完毕返回,A 的信息出栈,栈:[]
4.深度优先搜索(DFS)
在图论和搜索算法中,深度优先搜索常常用栈来实现。在遍历图的过程中,从起始节点开始,将其入栈。然后,每次从栈中弹出一个节点,访问该节点,并将其未访问过的邻接节点入栈,直到栈为空。这样的方式使得搜索沿着一条路径尽可能深地探索下去,直到无法继续,然后回溯到上一个节点继续探索其他路径。
5.浏览器历史记录
我们日常使用的浏览器,其历史记录功能也运用了栈的思想。当我们依次访问网页 A、B、C 时,这些网页依次被压入栈中。当我们点击 “后退” 按钮时,就相当于执行出栈操作,从栈顶弹出当前页面,回到上一个页面。例如,访问顺序为 A -> B -> C,栈的状态为 [C, B, A],点击 “后退”,C 出栈,回到 B 页面,栈变为 [B, A]
总结
栈作为一种简单而强大的数据结构,以其独特的后进先出特性,在众多领域展现出高效的应用价值。无论是复杂的算法实现,还是日常使用的软件功能,栈都默默发挥着重要作用。通过对栈的概念、操作、实现方式以及应用场景的深入学习,我们不仅掌握了一种基础的数据结构,更能在编程实践中灵活运用它来解决各种实际问题。在未来的编程之旅中,希望你能充分利用栈的优势,优化代码,提升程序的性能和效率。让我们继续探索数据结构的奇妙世界,解锁更多编程的奥秘!