title: Notes of System Design No.10 — Design a Web Crawler
description: ‘Design a Web Crawler’
date: 2022-05-13 18:01:58
tags: 系统设计
categories:
- 系统设计
00. What is Web Crawler?
Q :uh just for now let's just do html pages
but your web crawler should be
extensible so that in the future it can
handle other types of media
A!and um what types of protocols are we
thinking we want to be able to crawl on
the internet for
Q! let's just stick to http for now but
again it should be extensible so maybe
in the future it can handle ftp or https
etc
A !great and also i'll pull up my um
screen and i'll start writing down some
of these requirements
so we
we know we want to have all right http
we're going to handle http protocol
and we also
are handling just html files for now
but
ideally in the future we'd be able to
expand it to other types of files
and so
or other types of media
and in these
cases um
let's see maybe we could start thinking
about some of the features we'd like to
support in the web crawler
so how does
that sound to you
yeah that sounds
perfect
01.Functional Requirement

great um so some things we can think
about
first off we'll probably want something
like
we want to be able to
monitor our politeness
or our crawl rate
as we're navigating the web
in a lot of cases we don't want to over
over
use the resources of a given server or a
service
and then
on top of that
a dns query
so dns query will help us resolve the
websites faster
we'll have distributed crawling
we want to make sure that we can do this
efficiently and there's no single point
of failure where something goes down in
the system
we also want priority crawling so how do
we handle
multiple uh which sites to crawl you
know how do we rank those
and then
um
one more thing i can think of
at the top of my head is probably
duplicates
so
not continuing to
uh go over sites that we've already seen
or in the case that we're on one given
page we don't cycle through one page
over and over
because it may be
self-references or something like that
02. Non-Functional Requirement

um given
that we're gonna want to have
probably scalability since we're
processing
a lot of data and we're also going
through
millions of sites
in addition to that
we're going to want extensibility
so extensibility meaning maybe we have
this you know we talked about a
duplicate detection and
priority crawling but there could be
additional things that we'd want to
check out for in the future you know
that we can't anticipate now like
malware or security
and we want to make that easily added in
addition to these existing features
in addition to that freshness of pages
so how do we continually
renew these pages
and then
um server side rendering
so like i talked about before with
single page applications we're going to
need to render them on our site on the
server side to be able to
scan through them
otherwise they're
we're not going to be able to read it
because it'll just be a javascript
bundle
besides that
maybe we can take a look at uh like we
said before
politeness
which will be an important part
and so that'll be relating to like how
we
respect the upper limit of
the visiting frequencies that we have of
these websites because we don't want to
consume too many
um resources on those servers
so do all these goals seem okay for us
to proceed with the system design itself
piece by piece
yeah that sounds good to me



03. Assumptions

so given this feature set i'd love to
start talking about maybe the scale of
the system of how we can expand it to
you know how many users that we're going
to need for this
so
starting off
from here
so we're probably going to say that
uh let's say the internet
has probably
900 million uh
registered websites
and of those 900 million websites we can
probably estimate that 60%
of them
or
around 500 million are actually
like up and running
if they're up and running
they're also probably crawlable
or maybe they have other issues
so then
given each of those sites so we have a
total of 500 million sites
each of those
sites we can say maybe on average has a
hundred pages
and they can probably vary from anywhere
from one to two pages to let's say a
thousand pages like on something really
big like facebook or other
even facebook's probably even bigger
than that
but
100 probably is sufficient
would you agree
yes yeah that sounds good
awesome and so
given that um
we want to say
okay we have
500 million sites
100 pages per site
uh that gives us about a total of 50 billion
50 billion pages to crawl
so given 50 billion pages
we're going to also need to be able to
factor in the page size of each of these
individual pages
so maybe we can estimate these pages to
be about 120
kilobytes per page
this case
since we're just crawling for html we'll
also only need to
pull in html
as well as in some cases we need to do
javascript and css especially on like
single page applications where we'll
need to render it
before it can actually we can see the
whole site
and so
um
that will get us around
let's see 50 billion times 120
kilobytes gives us around
[Music]
what's the math there i think it's like
six petabytes
worth of storage
so
given
that um
[Music]
we can save all this and and let's say
it's like plus or minus one
tolerance of that
so given all this
information we have to store it
somewhere probably um
yeah uh
but maybe before we think about that as
well like how can we optimize this
because that's a lot of data
um and maybe one optimization we can
take a look at is uh just being able to
take out the metadata to build like some
sort of annotated index so we don't need
the complete page stored for every
single page
and in the case that we do need to have
the full page
well we can compress all of these pages
and then if we do need to
pull the full information of a page then
we can unzip it and just take a look at
the contents and
maybe we can estimate after zipping and
compressing all of that we'll get down
to half which is about three petabytes
of storage
um so does all of that seem reasonable
as far as scale
yeah sounds good to me so far

04. Define API
05. High-Level Design
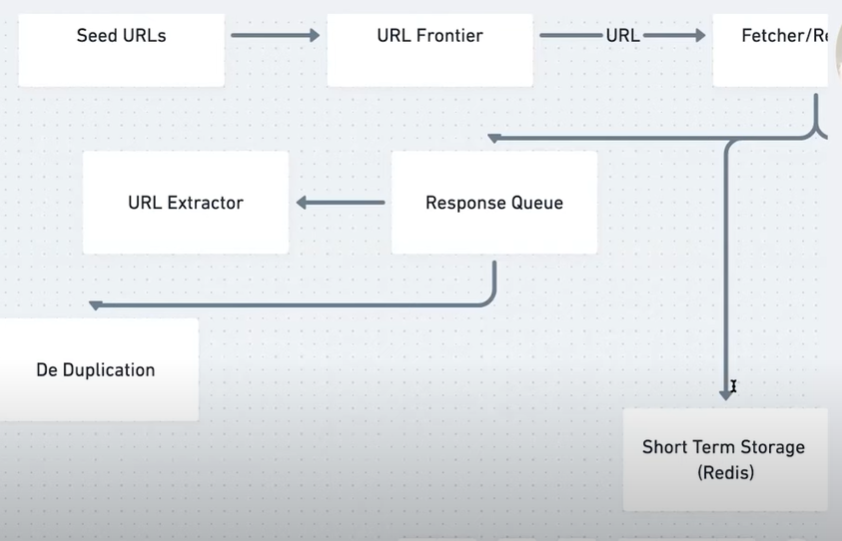
great
um so
probably the first thing that you need
in any web crawler is a way to
have a way to see
the urls
in this case
any any system is going to need to
take into account urls to be able to start the crawling
process
and
let's say we can take
in this case since we're doing html
sites
maybe our use case is like a search
engine something like google
or bing
and
in that case then we want to say crawl
the top 100 sites in every category on
the internet
so like finance
entertainment fashion blogs
all of those sort of things
and then make a list of those and
compile all that into seed urls
and so all of these urls is
basically one document that we can feed
into our next piece
which is the
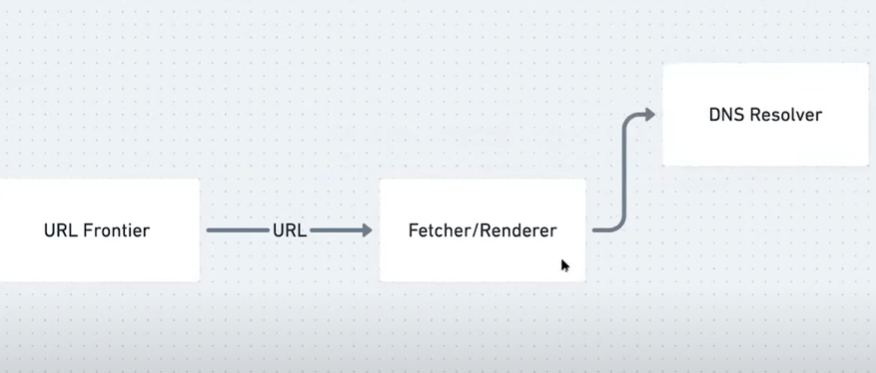
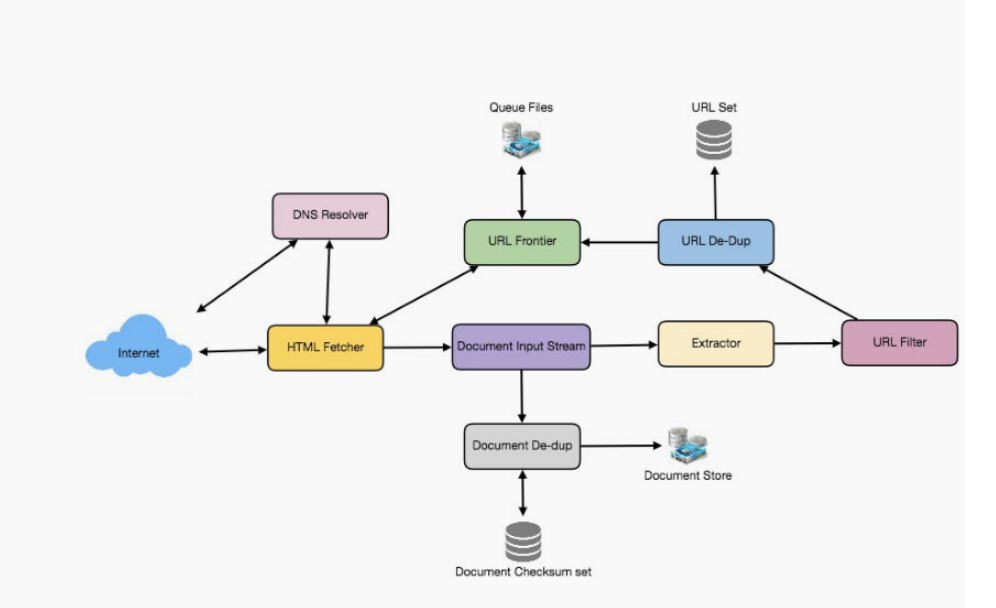
url frontier
the url frontier in this case
um essentially it's
a data structure that's built using queues
so it has
a priority and correctness built in
and
iyou want to explore
that further together like we could go
down that
but i think oh up to you yeah
oh i'd
just be curious to know what are you
prioritizing that in the url frontier
yes great so in this case like priority
it will be determined by
what do we want to in terms of urls to
be able to prioritize
um like which sites are we crawling so
in this case i would imagine we'd
probably want to prioritize based on
maybe traffic to the sites or
um you know other rankings like i think
google
has certain rankings based off of like
how many people are referencing a given
url from other urls and so that could be
let's say a priority ranking we could do
with those
if a url is also really
old we need to refresh
and it's being hit a lot
um that could
be a way we could do that
how does that
sound yeah
that all sounds really
sensible
given that okay so we have this
structure that allows us to
uh prioritize the urls to crawl
next and
returns that url
here we go call that url
pass that url to
this
and
this is going to be a fetcher or
renderer
so this is
essentially a piece in the process
that is going to
handle the fetching and rendering
which i guess makes sense in the name
what we need to do is that
in this case
we can have several of these distributed
in parallel
but
uh
each of these are implemented
we can
implement it with threads or processes
like python
has a way of
implementing uh individual
like multi-threaded systems and so we
could implement that
um
does it does that sound all right
yeah so um is the fetcher getting uh the
content of the url directly here
yeah so
i we can say maybe in each of these
components that it does
two things it's fetching as yes you're
saying
we need to be able to get the content
from the url
once this url is passed to
from the url frontier
um then
we could just immediately
call the page 、 download it
but again as we talked about before
um we would maybe end up getting routed
through a bunch of dns
or a bunch of ips so we probably need a
dns resolver to be able to fix that
um so maybe
as an intermediate step to speed up that
process we can add in a dns resolver
here
but just as you said the fetcher is
going to basically pull that page and
whatever is existing on there
and to be crawled
and if it's the case
it's just a standard html page then work
is probably done in terms of the fetcher
but
if it's a single page application which
is more and more common these days like
a lot of people are using react and
angular and other
spas then we'll probably need to use
some server-side rendering like
gatsby or next js and we can handle that
rendering on our side
and in this case uh referring to
politeness as we're going through these
individual pages
and probably be good to set the user agent to something like
a crawling name like robot where a lot of these
sites will specify names where we can
make sure to optimize or direct for
crawler traffic
gotcha so that's like a way of signaling
to the website that your uh crawling
traffic is coming from a bot rather than
a human exactly yeah
we don't want them
to get angry with us and then block us
our traffic so that'd probably be great
we have this dns resolver fetcher
renderer
now that we have all this content we
need to store it somewhere
do you have a preference of a storage
system of like s3 or
um big table or anything
um
not necessarily but i
do think you probably want some
balance of both having persistent
storage and also some short-term storage
for that processes can access
efficiently
yes yes great point i think
um we have these
like large you know
thinking of
long-term storage i was just thinking of
that but i definitely think it would be
important too here i'll add that here
think about short shorter term storage
so we can be able to access that faster
so i'll call this long term
and we can just put a placeholder like
amazon
s3 buckets
in addition to that though
um i think you're exactly right and we
definitely need
definitely need some short-term storage
and
so for that short-term storage i think
redis will probably works like some sort
of cache
um
i think there's
there's other types of cacheum like
memcache but i i think redis will be
sufficient for this
so
okay great now we can read and write
we're storing the data in these
long-term
data buckets to be able to access later
we have short-term storage and redis to
be able to quickly read process the data
so how are we going to read and process
the data so
from the fetcher we can
just call another process here
and
um
i imagine in this case we'll
need some sort of queue for all of these
responses since we're going through
so many
if we tried to do it synchronously i
think it would just slow the system down
a ton
so
um maybe we can queue up all of these uh
sent from here
as soon as we store this
we can
put this in a response in the response
queue
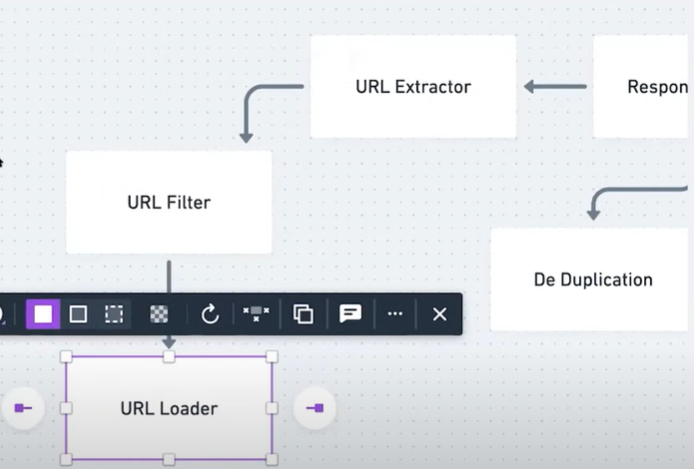
so the two services i can immediately
think of to handle that we talked about
this
are going to be the main one which is a
url extractor
and then the second one which is uh the
duplication service
um would you like me to talk about any
additional services potentially
um this looks good to me for now
um
and so
given these we have this url extractor
which
basically actually you know what i'll
start with a deduplication service
because it's pretty simple
um this
deduplication service
we have
all these urls that are in the
short term storage here
and given that um as we're going through
these we want to check if there's any
duplicates in the short term storage and
then not
extract those urls um
in terms of this url extractor
that is probably where we want to pull
urls from the page to allow the crawler
to continue diving further into that
same website or additionally leading to
other websites
most likely we'll use something like
depth first search or breadth first
search
i think from in this case when uh
in crawlers i've enjoyed breadth first
search to be able to exhaust a given
page before moving on to the next one
in addition things like if they're all
from the same domain then just
characterizing them all under one domain
and just having their relative paths
so in addition to that i guess
we could so talking or moving back to
our points here we have extensibility as
an important point
and this at right at this point is where
we can allow extensibility
so from the
response queue
we could add any
additional services we wanted to
right here to be able to
let's say we talked about
malware detection that could be a thing
where we don't probably want to download
any viruses or anything off the internet
that's going to mess up our system
so in addition to that
we can
take these urls that we've now extracted
we'll now want to start actually
reprocessing those urls because this is
just a circle or never ending cycle until we've
crawled the whole internet i guess
so
given this url extractor
um
okay we specified we talked about we
wanted just html pages
so this is
probably an important point here to
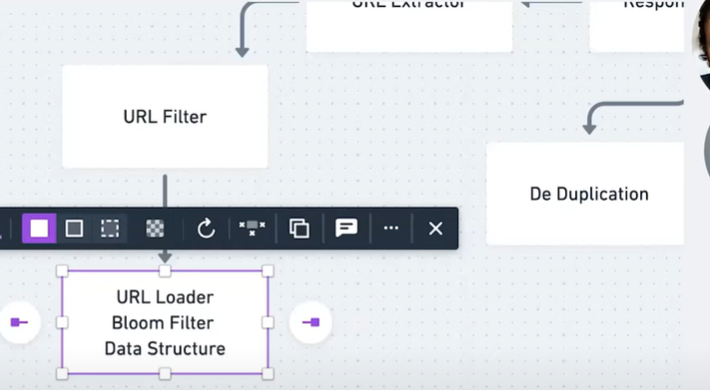
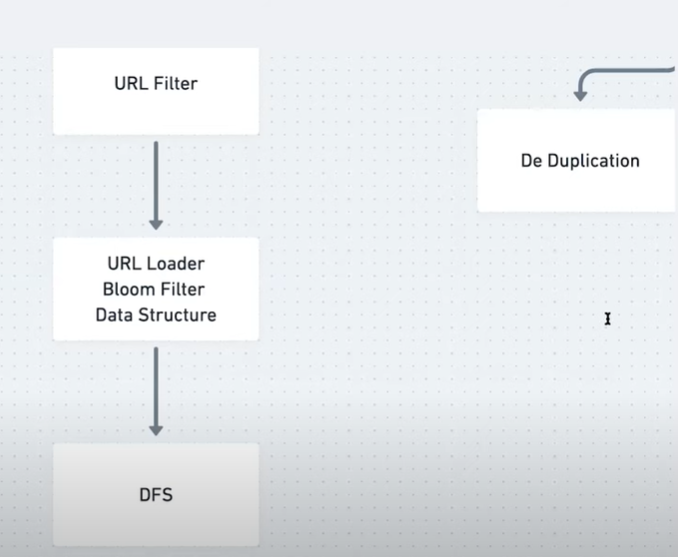
add in a url filter
so given this url filter
we've cleaned up and normalized
all these urls
and now we can give a
second check here
where
if we didn't
we've had all these filtered um we need
to do
one final check to be able to load all
these urls
so
we've in this given pass we've removed
any duplicates but what happens when we
have also duplicates that we have
already seen previously or how do we
manage yeah if we have crawled a page
but maybe we do want to crawl a page
again um how do we
check on that freshness and then save
the the new version
and so
i guess in this case we'll want a url
loader
so what does this url loader do
essentially it checks against if we've already crawled
the url
so we
probably need to build some sort of
search algorithm in this case
because it would be end time to search
the whole
database and since we are or whatever
storage system we're using and since we
have such high scale here it'll take way
too long to be able to search through
all of those to see if we already have
it
so um in this case i would probably say
we could use something called
bloom filter data structure
and
that case it essentially
the drawback of it um
it's not always correct
it sacrifices
correctness for speed
so
in this case we
we could miss some urls but
i guess
in this case that's okay because we want
we'll probably pick up those urls in
another pass
does that seem all right i
guess as a trade-off in this case
um
so given that
uh that's pretty much the well actually
we need to store all of these
so we
probably use something like nosql or
actually i would probably choose
in this case a distributed file system
to store all of these
uh different
different urls
and as i talked about
before i think we could do a use a
strategy where we have the domain name
at the top level of the file name and
then all of the
relative urls or urls tied to that
domain name
does that seem like it would be i guess
reasonable in this case
yes yeah sounds
reasonable
so now we have all of these urls saved
and crawled and if we've already crawled
them then we remove them in this case
however
or we add them here and then we don't want to pass it to the
beginning of the structure which is over
here at the url frontier
but we will want to i guess in some
cases
uh if we've already run across it we
will want to update it
in here if
maybe we can add timestamps to those to
be able to determine the freshness of
how often we have updated that or when
the last time was and those timestamps
then could be handled by the url
frontier about how they would get ranked
or prioritized to being refreshed or recrawled
so you mentioned before that politeness
was one of your design goals so how do
you ensure that your crawler is
respecting each individual website's
limitations on how much and where you
can crawl
yeah definitely so i i think in those
cases um
moving back over in this fetcher
renderer we talked about
defining the user agent
but i think yeah
we could be even more polite
using
like a
checking if the website had a robots.txt
file then we could see
the robot exclusion protocol so
basically it
would define what parts of the website
we should not crawl
and also a delay time um which i think i
mentioned before but yeah thank you for
bringing up again because uh the crawl
rate is an important factor of being
polite and i didn't go into it here but
i definitely think that
in that case we want to respect whatever
their crawl rate that they've defined
for us in that protocol









07 . Dive Deep



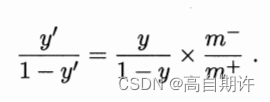




![第五届“传智杯”全国大学生计算机大赛(练习赛)传智杯 #5 练习赛] 平等的交易](https://img-blog.csdnimg.cn/cd6a646ad2ba46a2b01d738597d5cb03.png)
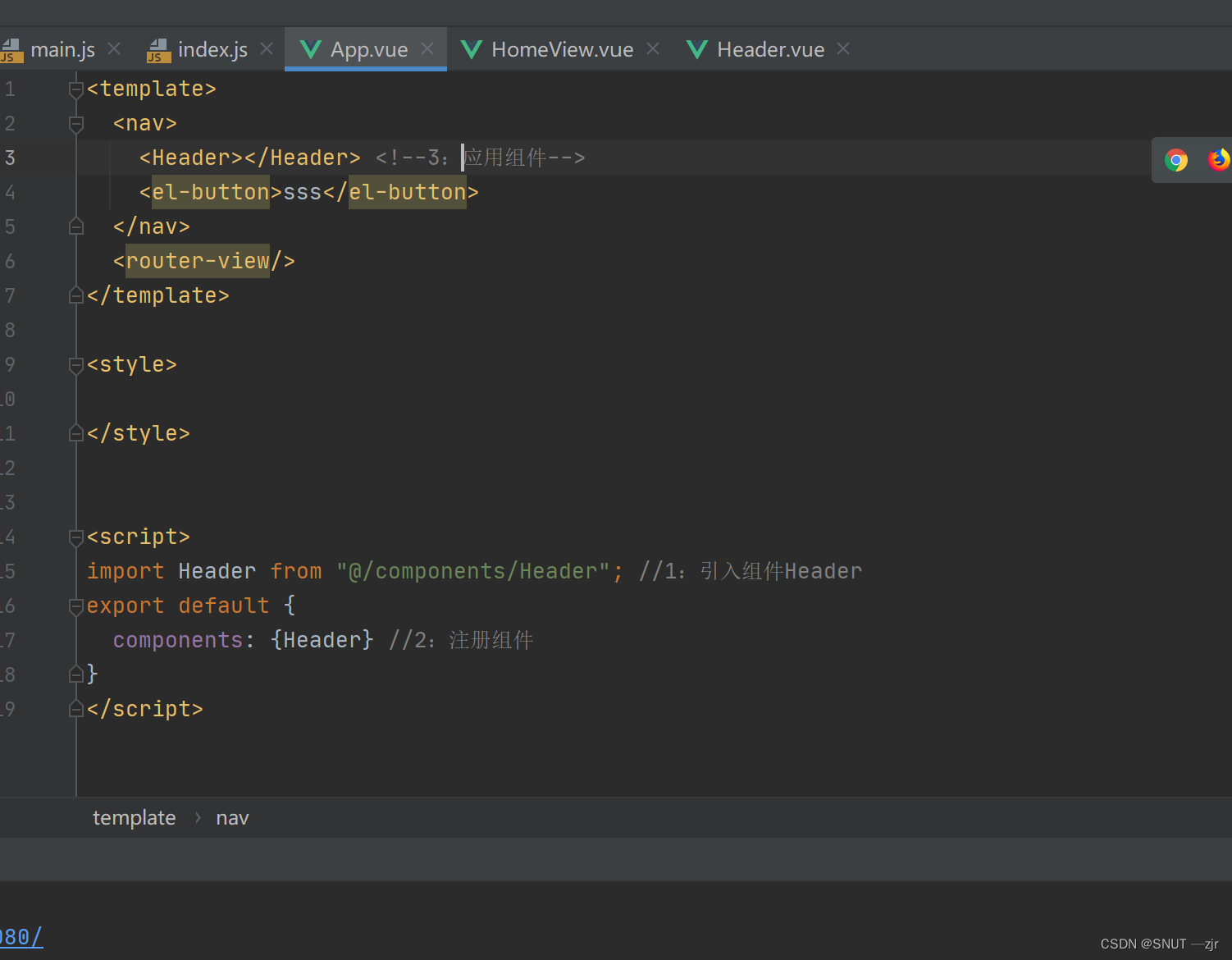
![[附源码]java毕业设计青少年计算机知识学习系统](https://img-blog.csdnimg.cn/203fa5afcbdb47febbd16c0d82806b60.png)