在 K8s 中,Pod 作为工作负载的运行载体,是最为核心的一个资源对象。Pod 具有复杂的生命周期,在其生命周期的每一个阶段,可能发生多种不同的异常情况。K8s 作为一个复杂系统,异常诊断往往要求强大的知识和经验储备。结合实战经历以及 EDAS 用户真实场景的归纳,我们总结了 K8s Pod 的 13 种常见异常场景,给出各个场景的常见错误状态,分析其原因和排查思路。
一、Pod 生命周期
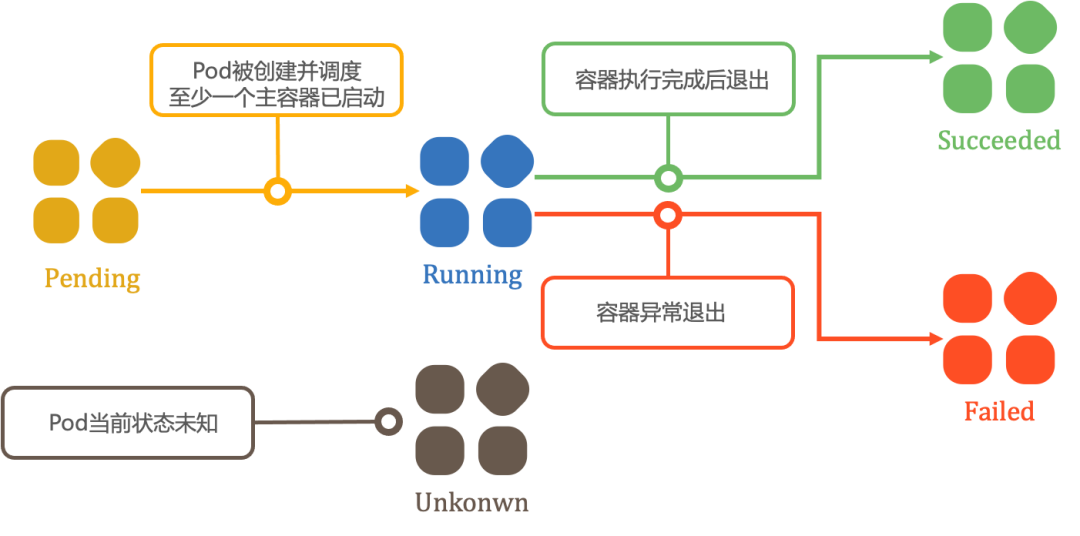
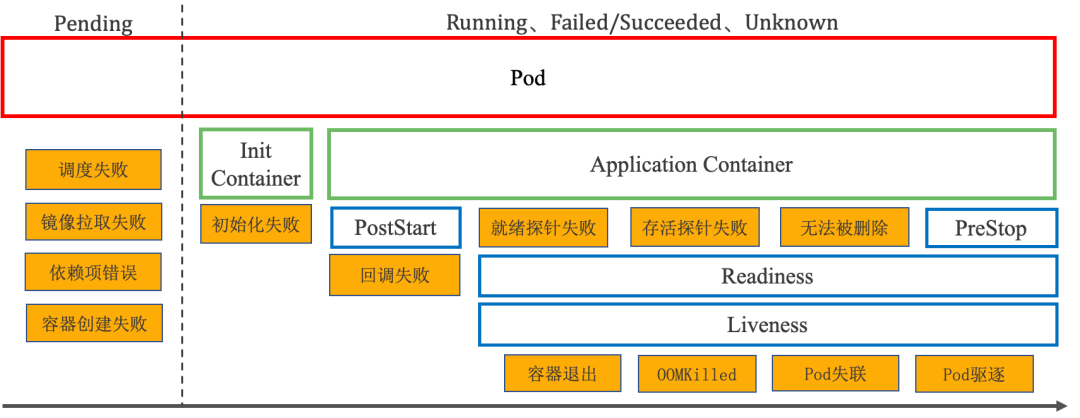
在整个生命周期中,Pod 会出现 5 种阶段(Phase)。
-
Pending:Pod 被 K8s 创建出来后,起始于 Pending 阶段。在 Pending 阶段,Pod 将经过调度,被分配至目标节点开始拉取镜像、加载依赖项、创建容器。
-
Running:当 Pod 所有容器都已被创建,且至少一个容器已经在运行中,Pod 将进入 Running 阶段。
-
Succeeded:当 Pod 中的所有容器都执行完成后终止,并且不会再重启,Pod 将进入 Succeeded 阶段。
-
Failed:若 Pod 中的所有容器都已终止,并且至少有一个容器是因为失败终止,也就是说容器以非 0 状态异常退出或被系统终止,Pod 将进入 Failed 阶段。
-
Unkonwn:因为某些原因无法取得 Pod 状态,这种情况 Pod 将被置为 Unkonwn 状态。
一般来说,对于 Job 类型的负载,Pod 在成功执行完任务之后将会以 Succeeded 状态为终态。而对于 Deployment 等负载,一般期望 Pod 能够持续提供服务,直到 Pod 因删除消失,或者因异常退出/被系统终止而进入 Failed 阶段。
Pod 的 5 个阶段是 Pod 在其生命周期中所处位置的简单宏观概述,并不是对容器或 Pod 状态的综合汇总。Pod 有一些细分状态( PodConditions ),例如 Ready/NotReady、Initialized、 PodScheduled/Unschedulable 等。这些细分状态描述造成 Pod 所处阶段的具体成因是什么。比如,Pod 当前阶段是 Pending,对应的细分状态是 Unschedulable,这就意味着 Pod 调度出现了问题。
容器也有其生命周期状态(State):Waiting、Running 和 Terminated。并且也有其对应的状态原因(Reason),例如 ContainerCreating、Error、OOMKilled、CrashLoopBackOff、Completed 等。而对于发生过重启或终止的容器,上一个状态(LastState)字段不仅包含状态原因,还包含上一次退出的状态码(Exit Code)。例如容器上一次退出状态码是 137,状态原因是 OOMKilled,说明容器是因为 OOM 被系统强行终止。在异常诊断过程中,容器的退出状态是至关重要的信息。
除了必要的集群和应用监控,一般还需要通过 kubectl 命令搜集异常状态信息。
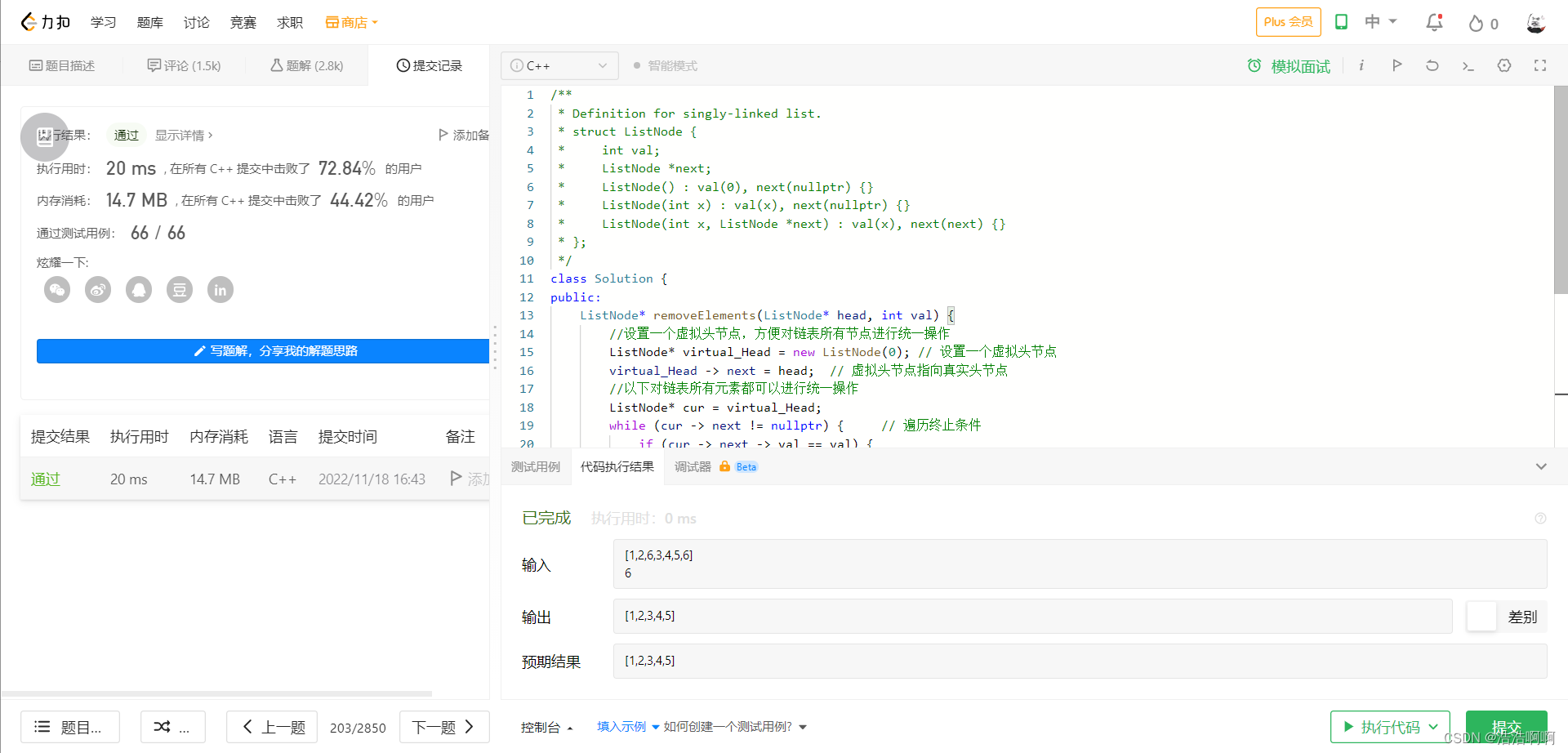
// 获取Pod当前对象描述文件
kubectl get po <podName> -n <namespace> -o yaml
// 获取Pod信息和事件(Events)
kubectl describe pod <podName> -n <namespace>
// 获取Pod容器日志
kubectl logs <podName> <containerName> -n <namespace>
// 在容器中执行命令
kubectl exec <podName> -n <namespace> -c <containerName> -- <CMD> <ARGS>二、Pod 异常场景
Pod 在其生命周期的许多时间点可能发生不同的异常,按照 Pod 容器是否运行为标志点,我们将异常场景大致分为两类:
-
在 Pod 进行调度并创建容器过程中发生异常,此时 Pod 将卡在 Pending 阶段。
-
Pod 容器运行中发生异常,此时 Pod 按照具体场景处在不同阶段。
下文将对这具体的 13 种场景进行描述和分析。
2.1、调度失败
常见错误状态:Unschedulable
Pod 被创建后进入调度阶段,K8s 调度器依据 Pod 声明的资源请求量和调度规则,为 Pod 挑选一个适合运行的节点。当集群节点均不满足 Pod 调度需求时,Pod 将会处于 Pending 状态。造成调度失败的典型原因如下:
-
节点资源不足
K8s 将节点资源(CPU、内存、磁盘等)进行数值量化,定义出节点资源容量(Capacity)和节点资源可分配额(Allocatable)。资源容量是指 Kubelet 获取的计算节点当前的资源信息,而资源可分配额是 Pod 可用的资源。Pod 容器有两种资源额度概念:请求值 Request 和限制值 Limit,容器至少能获取请求值大小、至多能获取限制值的资源量。Pod 的资源请求量是 Pod 中所有容器的资源请求之和,Pod 的资源限制量是 Pod 中所有容器的资源限制之和。K8s 默认调度器按照较小的请求值作为调度依据,保障可调度节点的资源可分配额一定不小于 Pod 资源请求值。当集群没有一个节点满足 Pod 的资源请求量,则 Pod 将卡在 Pending 状态。
Pod 因为无法满足资源需求而被 Pending,可能是因为集群资源不足,需要进行扩容,也有可能是集群碎片导致。以一个典型场景为例,用户集群有 10 几个 4c8g 的节点,整个集群资源使用率在 60%左右,每个节点都有碎片,但因为碎片太小导致扩不出来一个 2c4g 的 Pod。一般来说,小节点集群会更容易产生资源碎片,而碎片资源无法供 Pod 调度使用。如果想最大限度地减少资源浪费,使用更大的节点可能会带来更好的结果。
-
超过 Namespace 资源配额
K8s 用户可以通过资源配额(Resource Quota)对 Namespace 进行资源使用量限制,包括两个维度:
1. 限定某个对象类型(如 Pod)可创建对象的总数。
2. 限定某个对象类型可消耗的资源总数。
如果在创建或更新 Pod 时申请的资源超过了资源配额,则 Pod 将调度失败。此时需要检查 Namespace 资源配额状态,做出适当调整。
-
不满足 NodeSelector 节点选择器
Pod 通过 NodeSelector 节点选择器指定调度到带有特定 Label 的节点,若不存在满足 NodeSelector 的可用节点,Pod 将无法被调度,需要对 NodeSelector 或节点 Label 进行合理调整。
-
不满足亲和性
节点亲和性(Affinity)和反亲和性(Anti-Affinity)用于约束 Pod 调度到哪些节点,而亲和性又细分为软亲和(Preferred)和硬亲和(Required)。对于软亲和规则,K8s 调度器会尝试寻找满足对应规则的节点,如果找不到匹配的节点,调度器仍然会调度该 Pod。而当硬亲和规则不被满足时,Pod 将无法被调度,需要检查 Pod 调度规则和目标节点状态,对调度规则或节点进行合理调整。
-
节点存在污点
K8s 提供污点(Taints)和容忍(Tolerations)机制,用于避免 Pod 被分配到不合适的节点上。假如节点上存在污点,而 Pod 没有设置相应的容忍,Pod 将不会调度到该 节点。此时需要确认节点是否有携带污点的必要,如果不必要的话可以移除污点;若 Pod 可以分配到带有污点的节点,则可以给 Pod 增加污点容忍。
-
没有可用节点
节点可能会因为资源不足、网络不通、Kubelet 未就绪等原因导致不可用(NotReady)。当集群中没有可调度的节点,也会导致 Pod 卡在 Pending 状态。此时需要查看节点状态,排查不可用节点问题并修复,或进行集群扩容。
2.2、镜像拉取失败
常见错误状态:ImagePullBackOff
Pod 经过调度后分配到目标节点,节点需要拉取 Pod 所需的镜像为创建容器做准备。拉取镜像阶段可能存在以下几种原因导致失败:
-
镜像名字拼写错误或配置了错误的镜像
出现镜像拉取失败后首先要确认镜像地址是否配置错误。
-
私有仓库的免密配置错误
集群需要进行免密配置才能拉取私有镜像。自建镜像仓库时需要在集群创建免密凭证 Secret,在 Pod 指定 ImagePullSecrets,或者将 Secret 嵌入 ServicAccount,让 Pod 使用对应的 ServiceAccount。而对于 acr 等镜像服务云产品一般会提供免密插件,需要在集群中正确安装免密插件才能拉取仓库内的镜像。免密插件的异常包括:集群免密插件未安装、免密插件 Pod 异常、免密插件配置错误,需要查看相关信息进行进一步排查。
-
网络不通
网络不通的常见场景有三个:
1. 集群通过公网访问镜像仓库,而镜像仓库未配置公网的访问策略。对于自建仓库,可能是端口未开放,或是镜像服务未监听公网 IP;对于 acr 等镜像服务云产品,需要确认开启公网的访问入口,配置白名单等访问控制策略。
2. 集群位于专有网络,需要为镜像服务配置专有网络的访问控制,才能建立集群节点与镜像服务之间的连接。
3. 拉取海外镜像例如 gcr.io 仓库镜像,需配置镜像加速服务。
-
镜像拉取超时
常见于带宽不足或镜像体积太大,导致拉取超时。可以尝试在节点上手动拉取镜像,观察传输速率和传输时间,必要时可以对集群带宽进行升配,或者适当调整 Kubelet 的 --image-pull-progress-deadline 和 --runtime-request-timeout 选项。
-
同时拉取多个镜像,触发并行度控制
常见于用户弹性扩容出一个节点,大量待调度 Pod 被同时调度上去,导致一个节点同时有大量 Pod 启动,同时从镜像仓库拉取多个镜像。而受限于集群带宽、镜像仓库服务稳定性、容器运行时镜像拉取并行度控制等因素,镜像拉取并不支持大量并行。这种情况可以手动打断一些镜像的拉取,按照优先级让镜像分批拉取。
2.3、依赖项错误
常见错误状态:Error

在 Pod 启动之前,Kubelet 将尝试检查与其他 K8s 元素的所有依赖关系。主要存在的依赖项有三种:PersistentVolume、ConfigMap 和 Secret。当这些依赖项不存在或者无法读取时,Pod 容器将无法正常创建,Pod 会处于 Pending 状态直到满足依赖性。当这些依赖项能被正确读取,但出现配置错误时,也会出现无法创建容器的情况。比如将一个只读的持久化存储卷 PersistentVolume 以可读写的形式挂载到容器,或者将存储卷挂载到/proc 等非法路径,也会导致容器创建失败。
2.4、容器创建失败
常见错误状态:Error
Pod 容器创建过程中出现了错误。常见原因包括:
-
违反集群的安全策略,比如违反了 PodSecurityPolicy 等。
-
容器无权操作集群内的资源,比如开启 RBAC 后,需要为 ServiceAccount 配置角色绑定。
-
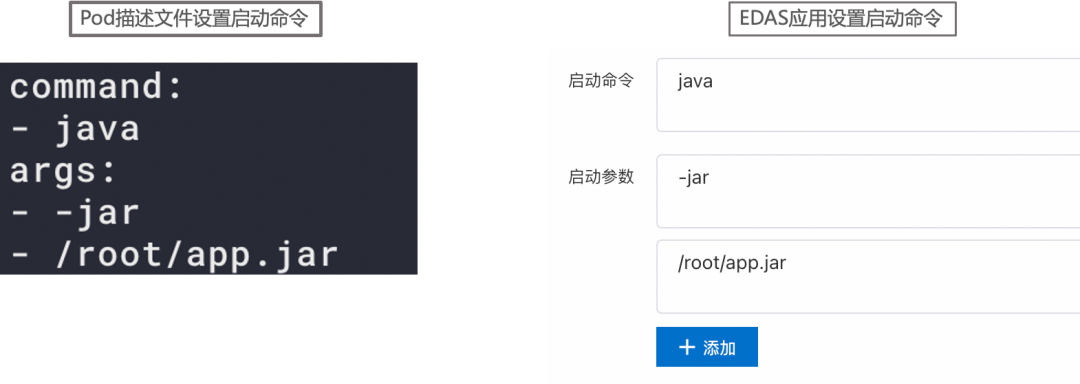
缺少启动命令,Pod 描述文件和镜像 Dockerfile 中均未指定启动命令。
-
启动命令配置错误。Pod 配置文件可以通过 command 字段定义命令行,通过 args 字段给命令行定义参数。启动命令配置错误的情况非常多见,要格外注意命令及参数的格式。正确的填写方式可参考:
2.5、初始化失败
常见错误状态:CrashLoopBackOff
K8s 提供 Init Container 特性,用于在启动应用容器之前启动一个或多个初始化容器,完成应用程序所需的预置条件。Init container 与应用容器本质上是一样的,但它们是仅运行一次就结束的任务,并且必须在执行完成后,系统才能继续执行下一个容器。如果 Pod 的 Init Container 执行失败,将会 block 业务容器的启动。通过查看 Pod 状态和事件定位到 Init Container 故障后,需要查看 Init Container 日志进一步排查故障点。
2.6、回调失败
常见错误状态:FailedPostStartHook 或 FailedPreStopHook 事件
K8s 提供 PostStart 和 PreStop 两种容器生命周期回调,分别在容器中的进程启动前或者容器中的进程终止之前运行。PostStart 在容器创建之后立即执行,但由于是异步执行,无法保证和容器启动命令的执行顺序相关联。如果 PostStart 或者 PreStop 回调程序执行失败,常用于在容器结束前优雅地释放资源。如果 PostStart 或者 PreStop 回调程序执行失败失败,容器将被终止,按照重启策略决定是否重启。当出现回调失败,会出现 FailedPostStartHook 或 FailedPreStopHook 事件,进一步结合容器打出的日志进行故障排查。
2.7、就绪探针失败
常见错误状态:容器已经全部启动,但是 Pod 处于 NotReady 状态,服务流量无法从 Service 达到 Pod
K8s 使用 Readiness Probe(就绪探针)来确定容器是否已经就绪可以接受流量。只有当 Pod 中的容器都处于就绪状态时,K8s 才认定该 Pod 处于就绪状态,才会将服务流量转发到该容器。一般就绪探针失败分为几种情况:
-
容器内应用原因:健康检查所配置规则对应的端口或者脚本,无法成功探测,如容器内应用没正常启动等。
-
探针配置不当:写错检查端口导致探测失败;检测间隔和失败阈值设置不合理,例如每次检查间隔 1s,一次不通过即失败;启动延迟设置太短,例如应用正常启动需要 15s,而设置容器启动 10s 后启用探针。
-
系统层问题:节点负载高,导致容器进程 hang 住。
-
CPU 资源不足:CPU 资源限制值过低,导致容器进程响应慢。
需要特别说明的是,对于微服务应用,服务的注册和发现由注册中心管理,流量不会经过 Service,直接从上游 Pod 流到下游 Pod。然而注册中心并没有如 K8s 就绪探针的检查机制,对于启动较慢的 JAVA 应用来说,服务注册成功后所需资源仍然可能在初始化中,导致出现上线后流量有损的情况。对于这一类场景,EDAS 提供延迟注册和服务预热等解决方案,解决 K8s 微服务应用上线有损的问题。
2.8、存活探针失败
常见错误状态:CrashLoopBackOff
K8s 使用 Liveness Probe(存活探针)来确定容器是否正在运行。如果存活态探测失败,则容器会被杀死,随之按照重启策略决定是否重启。存活探针失败的原因与就绪探针类似,然而存活探针失败后容器会被 kill 消失,所以排障过程要棘手得多。一个典型的用户场景是,用户在压测期间通过 HPA 弹性扩容出多个新 Pod,然而新 Pod 一启动就被大流量阻塞,无法响应存活探针,导致 Pod 被 kill。kill 后又重启,重启完又挂掉,一直在 Running 和 CrashLoopBackOff 状态中振荡。微服务场景下可以使用延迟注册和服务预热等手段,避免瞬时流量打挂容器。如果是程序本身问题导致运行阻塞,建议先将 Liveness 探针移除,通过 Pod 启动后的监控和进程堆栈信息,找出流量涌入后进程阻塞的根因。
2.9、容器退出
常见错误状态:CrashLoopBackOff
容器退出分为两种场景:
-
启动后立即退出,可能原因是:
1. 启动命令的路径未包含在环境变量PATH中。
2. 启动命令引用了不存在的文件或目录。
3. 启动命令执行失败,可能因为运行环境缺少依赖,也可能是程序本身原因。
4. 启动命令没有执行权限。
5. 容器中没有前台进程。容器应该至少包含一个 long-running 的前台进程,不能后台运行,比如通过nohup这种方式去启动进程,或是用 tomcat 的 startup.sh 脚本。
对于容器启动后立即退出的情况,通常因为容器直接消失,无法获取其输出流日志,很难直接通过现场定位问题。一个简易的排查方式是,通过设置特殊的启动命令卡住容器(比如使用 tail -f /dev/null),然后进到容器中手动执行命令看看结果,确认问题原因。
-
运行一段时间后退出,这种情况一般是容器内 1 进程 Crash 或者被系统终止导致退出。此时首先查看容器退出状态码,然后进一步查看上下文信息进行错误定位。这种情况发生时容器已经删除消失,无法进入容器中查看日志和堆栈等现场信息,所以一般推荐用户对日志、错误记录等文件配置持久化存储,留存更多现场信息。几种常见的状态码如下:

2.10、OOMKilled
常见错误状态:OOMKilled
K8s 中有两种资源概念:可压缩资源(CPU)和不可压缩资源(内存,磁盘 )。当 CPU 这种可压缩资源不足时,Pod 只会“饥饿”,但不会退出;而当内存和磁盘 IO 这种不可压缩资源不足时,Pod 会被 kill 或者驱逐。因为内存资源不足/超限所导致的 Pod 异常退出的现象被称为 Pod OOMKilled。K8s 存在两种导致 Pod OOMKilled 的场景:
-
Container Limit Reached,容器内存用量超限
Pod 内的每一个容器都可以配置其内存资源限额,当容器实际占用的内存超额,该容器将被 OOMKilled 并以状态码 137 退出。OOMKilled 往往发生在 Pod 已经正常运行一段时间后,可能是由于流量增加或是长期运行累积的内存逐渐增加。这种情况需要查看程序日志以了解为什么 Pod 使用的内存超出了预期,是否出现异常行为。如果发现程序只是按照预期运行就发生了 OOM,就需要适当提高 Pod 内存限制值。一个很常见的错误场景是,JAVA 容器设置了内存资源限制值 Limit,然而 JVM 堆大小限制值比内存 Limit 更大,导致进程在运行期间堆空间越开越大,最终因为 OOM 被终止。对于 JAVA 容器来说,一般建议容器内存限制值 Limit 需要比 JVM 最大堆内存稍大一些。
-
Limit Overcommit,节点内存耗尽
K8s 有两种资源额度概念:请求值 Request 和限制值 Limit,默认调度器按照较小的请求值作为调度依据,保障节点的所有 Pod 资源请求值总和不超过节点容量,而限制值总和允许超过节点容量,这就是 K8s 资源设计中的 Overcommit(超卖)现象。超卖设计在一定程度上能提高吞吐量和资源利用率,但会出现节点资源被耗尽的情况。当节点上的 Pod 实际使用的内存总和超过某个阈值,K8s 将会终止其中的一个或多个 Pod。为了尽量避免这种情况,建议在创建 Pod 时选择大小相等或相近的内存请求值和限制值,也可以利用调度规则将内存敏感型 Pod 打散到不同节点。
2.11、Pod 驱逐
常见错误状态:Pod Evicted
当节点内存、磁盘这种不可压缩资源不足时,K8s 会按照 QoS 等级对节点上的某些 Pod 进行驱逐,释放资源保证节点可用性。当 Pod 发生驱逐后,上层控制器例如 Deployment 会新建 Pod 以维持副本数,新 Pod 会经过调度分配到其他节点创建运行。对于内存资源,前文已经分析过可以通过设置合理的请求值和限制值,避免节点内存耗尽。而对于磁盘资源,Pod 在运行期间会产生临时文件、日志,所以必须对 Pod 磁盘容量进行限制,否则某些 Pod 可能很快将磁盘写满。类似限制内存、CPU 用量的方式,在创建 Pod 时可以对本地临时存储用量(ephemeral-storage)进行限制。同时,Kubelet 驱逐条件默认磁盘可用空间在 10%以下,可以调整云监控磁盘告警阈值以提前告警。
2.12、Pod 失联
常见错误状态:Unkonwn
Pod 处于 Unkonwn 状态,无法获取其详细信息,一般是因为所在节点 Kubelet 异常,无法向 APIServer 上报 Pod 信息。首先检查节点状态,通过 Kubelet 和容器运行时的日志信息定位错误,进行修复。如果无法及时修复节点,可以先将该节点从集群中删除。
2.13、无法被删除
常见错误状态:卡在 Terminating
当一个 Pod 被执行删除操作后,却长时间处于 Terminating 状态,这种情况的原因有几种:
-
Pod 关联的 finalizer 未完成。首先查看 Pod 的 metadata 字段是否包含 finalizer,通过一些特定上下文信息确认 finalizer 任务具体是什么,通常 finalizer 的任务未完成可能是因为与 Volume 相关。如果 finalizer 已经无法被完成,可以通过 patch 操作移除对应的 Pod 上的 finalizer 完成删除操作。
-
Pod 对中断信号没有响应。Pod 没有被终止可能是进程对信号没有响应,可以尝试强制删除 Pod。
-
节点故障。通过查看相同节点上的其他 Pod 状态确认是否节点故障,尝试重启 Kubelet 和容器运行时。如果无法修复,先将该节点从集群中删除。
三、EDAS排障工具链
EDAS 对应用全生命周期的大部分异常都有沉淀和分析,降低用户学习成本,缩短排障时间。EDAS 提供一系列解决方案和工具帮助用户解决应用生命周期中的异常问题,包括应用变更前的变更预检、应用变更和运行的事件追踪可观测、应用异常时的诊断工具。
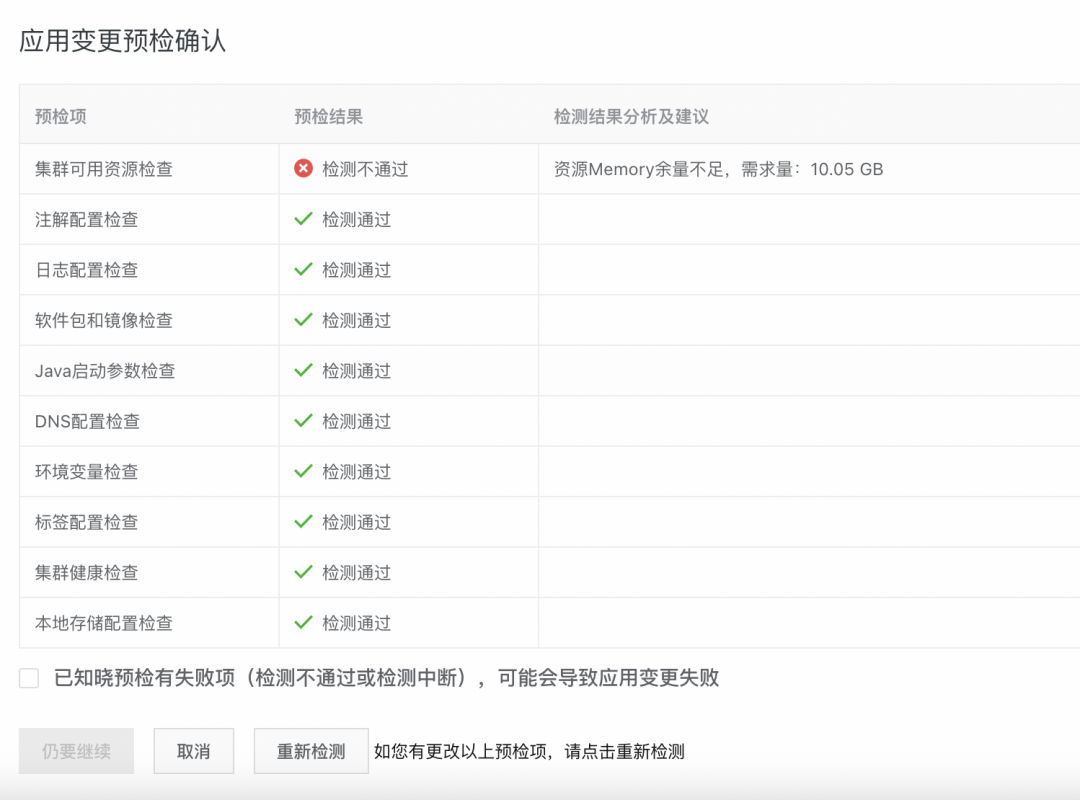
3.1、应用变更预检
EDAS 在应用变更任务下发前将经过预检环节,应用变更预检可以在应用部署前检查集群状态及变更参数是否有效,能够有效避免应用变更过程出错,降低变更风险。当前应用变更预检提供集群可用资源检查、集群健康检查、各项依赖配置检查等项目,对于非预期的预检结果给出分析和处置建议。例如对于集群资源余量不满足 Pod 调度需求的异常场景,变更预检结果将显示资源检查不通过,用户能够第一时间做出针对性调整。
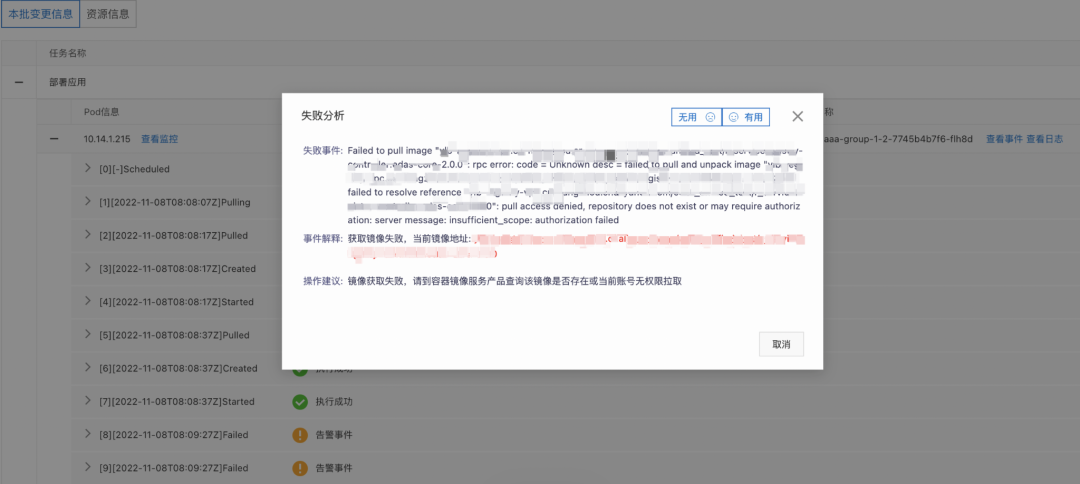
3.2、应用事件观测
EDAS 对应用生命周期中的事件进行追踪提供可观测能力。对于应用变更过程提供完整的事项展示,让用户能够白屏观测到变更中的每一个步骤和相关上下文信息。当出现异常变更情况时,将具体的事件和相关资源信息在白屏透出,并对异常事件进行分析解读并给出操作建议。例如给 Pod 配置了容器服务仓库镜像,但并未正确配置集群免密插件,EDAS 将镜像拉取失败事件抛出,并引导用户检查镜像拉取权限。
3.3、诊断工具箱
对于异常 Pod,通常需要连接到 Pod 容器,对业务进程进行诊断,必要时候还需要对异常进行复现。EDAS 提供云原生工具箱,让用户在网页上连接 Pod 容器 Shell,并且提供 Arthas、Tcpdump 等工具,弥补镜像软件工具包的缺失。对于 Pod 已经消失、不适合在业务 Pod 进行诊断等场景,云原生工具箱提供 Pod 复制能力,根据诊断场景不同,用户可以按需选择开启诊断 Pod。
对于上文中提到的容器进程被大流量阻塞,导致 Pod 被 Liveness 打挂的场景,用户可以通过云原生工具箱,开启一个移除 Liveness 的诊断 Pod,设置全链路流量控制规则,打入一些测试流量,使用 Arthas 提供的 trace、stack、watch 等工具精准定位问题
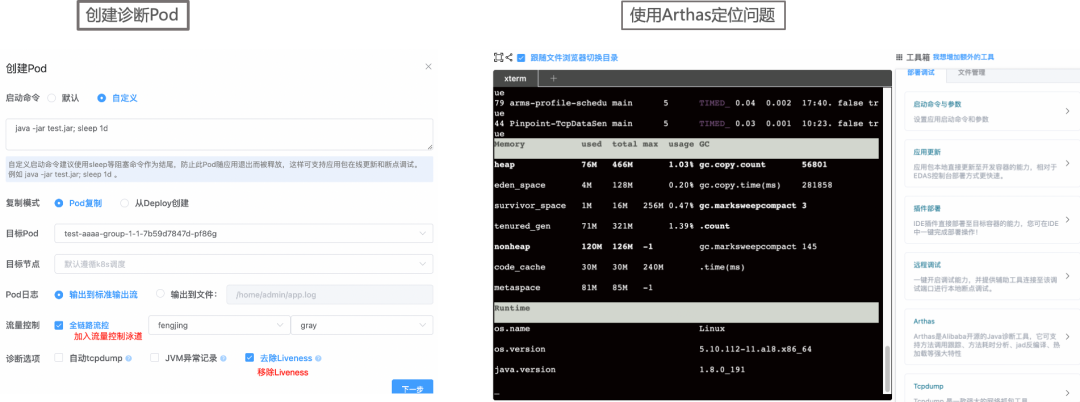
参考文档
-
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
-
Managing Compute Resources for Containers
-
Configure Quality of Service for Pods - Kubernetes
-
https://docs.docker.com/engine/reference/commandline/pull/#concurrent-downloads
-
https://developer.aliyun.com/article/1066441
-
https://alibaba.github.io/arthas


![[附源码]java毕业设计乒乓球俱乐部管理系统](https://img-blog.csdnimg.cn/5951e63798284ee1a8ca88ad1878b918.png)