所谓的运行队列到底长什么样子、新进程是如何被加入进来的、调度是如何选择一个新进程的、新进程又如何被切换到 CPU 上运行的,这些细节咱们都没提到。今天就来展开看看这些进程运行背后的原理。
通过今天的文章,你将对以下两个问题有个更深入的理解。
-
进程不主动释放 CPU 的话,每次调度最少能运行多久?
-
进程的 nice 值代表的是优先级吗,高优先级是否能抢占低优先级的 CPU ?
一、CPU 核的运行队列
进程创建完后需要被添加到运行队列中,那我们就来看看这个运行队列究竟是长啥样子的。
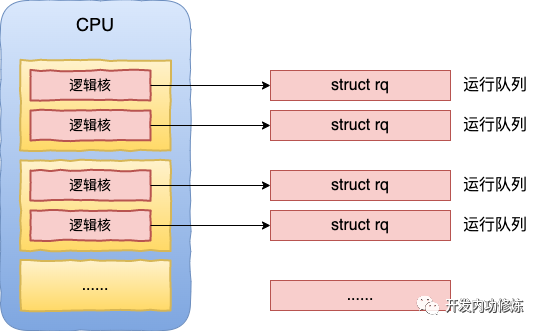
关于运行队列,我们得先从 CPU 的物理结构讲起。现代主流的服务器都是多 CPU 架构,每颗 CPU 又会包含多个物理核,每个物理核又可以超线程出多个逻辑核来供操作系统管理和使用。
拿某台线上的服务器 32 核的服务器来举例,该服务器实际上是有 2 颗 CPU,每颗 CPU 包含了 8 个物理核心。这样总共包含的是 16 个物理核。
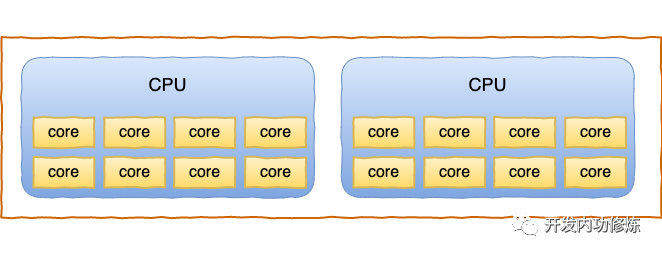
因为该服务器每个物理核心又可以当成两个超线程来用,所以通过 top 命令可以看到有 32 “核”,这里看到的核其实是逻辑核。
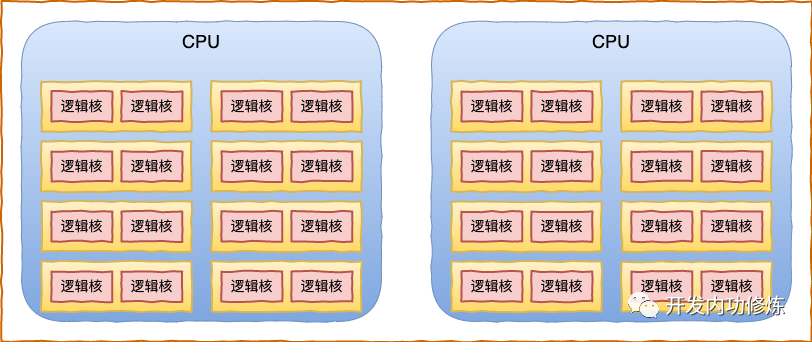
为了让每个 CPU 核(逻辑核)都能更好地参与进程任务处理,不需要考虑和其他处理器竞争的问题,也能充分利用本地硬件 Cache 来对访问加速。Linux 内核会为每个 CPU 核都分配一个运行队列,也就是 struct rq 内核对象。
内核定义是通过 DEFINE_PER_CPU 来定义 Per CPU 变量的。其中运行队列使用的是 DEFINE_PER_CPU_SHARED_ALIGNED 宏。
//file:kernel/sched/core.c
DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
DEFINE_PER_CPU_SHARED_ALIGNED 宏接收两个参数,第一参数可以理解为是数组类型,第二个参数可以理解为数组名。
//file:include/linux/percpu-defs.h
#define DEFINE_PER_CPU_SHARED_ALIGNED(type, name) \
DEFINE_PER_CPU_SECTION(type, name, PER_CPU_SHARED_ALIGNED_SECTION) \
____cacheline_aligned_in_smp
这个宏执行后的效果是初始化出来一个 runqueues 数组,在该数组中为每一个 CPU 核都配置了一个运行队列(struct rq)对象。
那么这个运行队列 struct rq 又是如何实现的呢?Linux 操作系统进程调度有多种多样的需求。例如有的需要按优先级来实时调度,只要高优先级的进程一就绪,就需要立即抢占 CPU 资源。有的不需要抢占这么频繁,对实时性要求没那么高,但需要进程公平地被分配 CPU 资源就可以了。
为了满足各种复杂的调度策略,内核在 struct rq 中实现了不同的调度类(Scheduling Class)。不同的调度需求的进程放在不同的调度类中。
//file:kernel/sched/sched.h
struct rq {
//2.1 实时任务调度器
struct rt_rq rt;
//2.2 CFS 完全公平调度器
struct cfs_rq cfs;
...
}
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
2.1 实时调度器
在实时类调度需求中,一般内核线程如 migration 一般对实时性的要求比较高,这类进程需要及时调度分配 CPU。
在这种调度算法中,优先级是最主要考虑的因素。高优先级的进程可以抢占低优先级进程 CPU 资源来运行。同一个优先级的进程按照先到先服务(SCHED_FIFO)或者时间片轮转(SCHED_RR)。
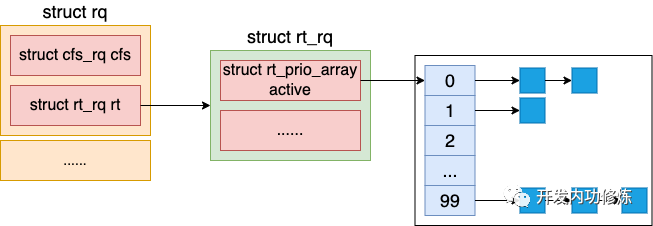
这种调度方式实现起来比较简单,只需要定义一些优先级,并为每个优先级各分配一个链表当队列即可,也叫多优先级队列。
我们来看下代码实现:
//file:kernel/sched/sched.h
struct rt_rq {
struct rt_prio_array active;
unsigned int rt_nr_running;
...
}
其中 rt_prio_array 就是多优先级队列的实现,我们来看下它的定义。
//file:kernel/sched/sched.h
struct rt_prio_array {
...
struct list_head queue[MAX_RT_PRIO];
};
其中 MAX_RT_PRIO 定义在 include/linux/sched/rt.h 文件中,它的值为 100。也就是说有 100 个对应不同优先级的队列。
//file: include/linux/sched/rt.h
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
...
2.2 完全公平调度器
Linux 主要是用来运行用户进程的。对于绝大部分的用户进程来说,对实时性的要求没那么高。如果因为优先级的问题频繁地发生抢占,进而导致过多的进程上下文切换的开销,对系统整体的性能是有不利的影响的。
所以用户进程采用的是不同的调度算法。Linux 2.6.23 之后采用了完全公平调度器(Completely Fair Scheduler,CFS)作为对用户进程的调度算法。CFS 调度器的核心思想是强调让每个进程尽量公平地分配到 CPU 时间即可,而不是实时抢占。。
举个例子,假设一个 CPU 上有两个任务需要执行,那么每个任务都将分配 50% 的 CPU 时间,以保障公平性。假如有 N 个任务,CPU 尽可能分配给每个进程 1/N 的处理时间。
公平调度算法在实现上引入了一个虚拟时间的概念。一旦进程运行虚拟时间就会增加。尽量让虚拟时间最小的进程运行,谁小了就要多运行,谁大了就要少获得 CPU。最后尽量保证所有进程的虚拟时间相等,动态地达到公平分配 CPU 的目的。
但是在数据结构的组织上,有一个小小的难点要解决。那就是当所有程序运行起来后,每一个进程的虚拟时间是不断地在变化的。如何动态管理这些虚拟时间不断在变化的进程,快速把虚拟时间最少的进程找出来。
在 CFS 调度器中采用的解决办法是使用的是红黑树来管理任务。红黑树把进程按虚拟运行时间从小到大排序。越靠树的左侧,进程的运行虚拟时间越小。越靠树的右侧,进程的运行虚拟时间就越大。这样每当想挑选可运行进程时,直接从树的最左侧选择节点就可以了。
以下是 cfs_rq 对象的定义,其中的 rb_xx 就是红黑树相关的定义。
//file:kernel/sched/sched.h
struct cfs_rq {
...
u64 min_vruntime;
struct rb_root tasks_timeline;
struct rb_node *rb_leftmost;
...
}
另外完全公平调度器实现上考虑到的两个细节这里我和大家提一下。
第一个就是照顾性能开销。
前面我们说过,进程上下文切换会导致额外的 CPU 浪费。假如被选中的进程刚运行没多久,它的虚拟时间时间就比另一个进程小了。这时候难道要马上换另一个进程处理么?出于减少频繁切换进程所带来的成本考虑,显然并不应该这样。
所以,Linux 会保证选择到的进程一个最短的运行时间,这个时间由 sched_min_granularity_ns 这个内核参数来控制。
# sysctl -a | grep min_granularity
kernel.sched_min_granularity_ns = 10000000
上面是飞哥阿里云服务器的默认配置。这表示进程至少会运行 10 ms。当然了,如果进程因为等待网络、磁盘等资源时主动放弃那另算。
第二个就是权重考量。
在实践中可能确实有进程需要多分配一点运行时间。Linux 采用的做法在是上述绝对公平算法基础上再为进程引入一个权重。
通过给每个进程设置一定的权重,各个进程按权重的比例公平地来分配 CPU 时间。如果进程的权重高,那就按比例多获得一点 CPU,权重低获得的比例就低。
这个权重就是 Linux 进程的 nice 值,也就是我们平时 top 命令结果中看到的 ni 这一列。nice 范围为 -20(最高权重)到 19(最低权重)。
现在有很多人都把 nice 理解成了优先级,这是不太恰当的。优先级强调的是抢占,高优先级比低优先级有优先获得 CPU 的权利。而用户进程中的 nice 值强调的是获取到 CPU 运行时间的比例,理解成权重更合适。
三、新进程之初始化
fork 创建时主要是调用了 copy_process 对新进程的 task_struct 进行各种初始化。在初始化的过程中,也涉及到几个进程调度相关的变量的初始化,这里我们专门来看一下。
//file:kernel/fork.c
static struct task_struct *copy_process(...)
{
...
sched_fork(p);
...
}
在创建进程 copy_process 时会调用 sched_fork 来完成调度相关的初始化。
//file:kernel/sched/core.c
void sched_fork(struct task_struct *p)
{
__sched_fork(p);
p->state = TASK_RUNNING;
if (!rt_prio(p->prio))
p->sched_class = &fair_sched_class;
...
}
在上面代码中最重要的一行是 p->sched_class = &fair_sched_class。这一行表示这个进程将会被完全公平调取策略进行调度。其中 fair_sched_class 是一个全局对象,代表完全公平调度器。它实现了调取器类中要求的添加任务队列、删除任务队列、从队列中选择进程等方法。
//file:kernel/sched/fair.c
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
...
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
...
}
另外就是把进程的虚拟运行时间初始化为 0,迁移次数初始化为 0 。
//file:kernel/sched/core.c
static void __sched_fork(struct task_struct *p)
{
p->on_rq = 0;
...
p->se.nr_migrations = 0;
p->se.vruntime = 0;
...
}文章篇幅过长,下文继续讲解





![[附源码]java毕业设计商城管理系统](https://img-blog.csdnimg.cn/7a827d9792cb45f1b2bf2ed4a8bd885b.png)