- 任务:利用LSTM模型预测2017年的股票中High的走势,并与真实的数据进行比对。
- 数据:https://www.kaggle.com/datasets/princeteng/stock-predict
一、import packages|导入第三方库
import pandas as pd
import matplotlib.pyplot as plt
import datetime
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import Dataset, DataLoader
# read dataset and check it
# 读入数据并且查看
df = pd.read_csv('../input/stock-predict/IBM_2006-01-01_to_2018-01-01.csv', index_col=0)
df.index = list(map(lambda x:datetime.datetime.strptime(x, '%Y-%m-%d'), df.index))
df.head(20)
| Open | High | Low | Close | Volume | Name | |
|---|---|---|---|---|---|---|
| 2006-01-03 | 82.45 | 82.55 | 80.81 | 82.06 | 11715200 | IBM |
| 2006-01-04 | 82.20 | 82.50 | 81.33 | 81.95 | 9840600 | IBM |
| 2006-01-05 | 81.40 | 82.90 | 81.00 | 82.50 | 7213500 | IBM |
| 2006-01-06 | 83.95 | 85.03 | 83.41 | 84.95 | 8197400 | IBM |
| 2006-01-09 | 84.10 | 84.25 | 83.38 | 83.73 | 6858200 | IBM |
| 2006-01-10 | 83.15 | 84.12 | 83.12 | 84.07 | 5701000 | IBM |
| 2006-01-11 | 84.37 | 84.81 | 83.40 | 84.17 | 5776500 | IBM |
| 2006-01-12 | 83.82 | 83.96 | 83.40 | 83.57 | 4926500 | IBM |
| 2006-01-13 | 83.00 | 83.45 | 82.50 | 83.17 | 6921700 | IBM |
| 2006-01-17 | 82.80 | 83.16 | 82.54 | 83.00 | 8761700 | IBM |
| 2006-01-18 | 84.00 | 84.70 | 83.52 | 84.46 | 11032800 | IBM |
| 2006-01-19 | 84.14 | 84.39 | 83.02 | 83.09 | 6484000 | IBM |
| 2006-01-20 | 83.04 | 83.05 | 81.25 | 81.36 | 8614500 | IBM |
| 2006-01-23 | 81.33 | 81.92 | 80.92 | 81.41 | 6114100 | IBM |
| 2006-01-24 | 81.39 | 82.15 | 80.80 | 80.85 | 6069000 | IBM |
| 2006-01-25 | 81.05 | 81.62 | 80.61 | 80.91 | 6374300 | IBM |
| 2006-01-26 | 81.50 | 81.65 | 80.59 | 80.72 | 7810200 | IBM |
| 2006-01-27 | 80.75 | 81.77 | 80.75 | 81.02 | 6103400 | IBM |
| 2006-01-30 | 80.21 | 81.81 | 80.21 | 81.63 | 5325100 | IBM |
| 2006-01-31 | 81.50 | 82.00 | 81.17 | 81.30 | 6771600 | IBM |
根据日期的数据列可以大致总结,周六周日有两天不进行股价交易
# the amount of datasets
# 数据集数量
len(df)
3020
二、data processing|数据处理
def getData(df, column, train_end=-250, days_before=7, return_all=True, generate_index=False):
series = df[column].copy()
# split data
# 划分数据
train_series, test_series = series[:train_end], series[train_end - days_before:]
train_data = pd.DataFrame()
# 以七天为一个周期构建数据集和标签
for i in range(days_before):
train_data['c%d' % i] = train_series.tolist()[i: -days_before + i]
# get train labels
# 获取对应的 label
train_data['y'] = train_series.tolist()[days_before:]
# gen index
# 是否生成 index
if generate_index:
train_data.index = train_series.index[n:]
if return_all:
return train_data, series, df.index.tolist()
return train_data
# build dataloader
# 构建用于模型训练的dataloader
class TrainSet(Dataset):
def __init__(self, data):
self.data, self.label = data[:, :-1].float(), data[:, -1].float()
def __getitem__(self, index):
return self.data[index], self.label[index]
def __len__(self):
return len(self.data)
三、build model|构建模型
# build LSTM model
class LSTM(nn.Module):
def __init__(self):
super(LSTM, self).__init__()
self.lstm = nn.LSTM(
input_size=1,
hidden_size=64,
num_layers=1,
batch_first=True)
self.out = nn.Sequential(
nn.Linear(64,1))
def forward(self, x):
r_out, (h_n, h_c) = self.lstm(x, None)
out = self.out(r_out[:, -1, :])
return out
四、train model|模型训练
# 数据集建立
train_data, all_series, df_index = getData(df, 'High')
# 获取所有原始数据
all_series = np.array(all_series.tolist())
# 绘制原始数据的图
plt.figure(figsize=(12,8))
plt.plot(df_index, all_series, label='real-data')
# 归一化
train_data_numpy = np.array(train_data)
train_mean = np.mean(train_data_numpy)
train_std = np.std(train_data_numpy)
train_data_numpy = (train_data_numpy - train_mean) / train_std
train_data_tensor = torch.Tensor(train_data_numpy)
# 创建 dataloader
train_set = TrainSet(train_data_tensor)
train_loader = DataLoader(train_set, batch_size=10, shuffle=True)

4.1 train model from zero|从头开始训练模型
rnn = LSTM()
if torch.cuda.is_available():
rnn = rnn.cuda()
# 设置优化器和损失函数
optimizer = torch.optim.Adam(rnn.parameters(), lr=0.0001)
loss_func = nn.MSELoss()
for step in range(100):
for tx, ty in train_loader:
if torch.cuda.is_available():
tx = tx.cuda()
ty = ty.cuda()
output = rnn(torch.unsqueeze(tx, dim=2))
loss = loss_func(torch.squeeze(output), ty)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 10==0:
print(step, loss.cpu())
torch.save(rnn, 'model.pkl')
0 tensor(0.0756, grad_fn=<ToCopyBackward0>)
10 tensor(0.0087, grad_fn=<ToCopyBackward0>)
20 tensor(0.0024, grad_fn=<ToCopyBackward0>)
30 tensor(0.0042, grad_fn=<ToCopyBackward0>)
40 tensor(0.0078, grad_fn=<ToCopyBackward0>)
50 tensor(0.0057, grad_fn=<ToCopyBackward0>)
60 tensor(0.0001, grad_fn=<ToCopyBackward0>)
70 tensor(0.0077, grad_fn=<ToCopyBackward0>)
80 tensor(0.0027, grad_fn=<ToCopyBackward0>)
90 tensor(0.0015, grad_fn=<ToCopyBackward0>)
4.2 load model|加载训练好的模型
rnn = LSTM()
rnn = torch.load('model.pkl')
generate_data_train = []
generate_data_test = []
# 测试数据开始的索引
test_start = len(all_series)-250
# 对所有的数据进行相同的归一化
all_series = (all_series - train_mean) / train_std
all_series = torch.Tensor(all_series)
for i in range(7, len(all_series)):
x = all_series[i - 7:i]
# 将 x 填充到 (bs, ts, is) 中的 timesteps
x = torch.unsqueeze(torch.unsqueeze(x, dim=0), dim=2)
if torch.cuda.is_available():
x = x.cuda()
y = rnn(x)
if i < test_start:
generate_data_train.append(torch.squeeze(y.cpu()).detach().numpy() * train_std + train_mean)
else:
generate_data_test.append(torch.squeeze(y.cpu()).detach().numpy() * train_std + train_mean)
plt.figure(figsize=(12,8))
plt.plot(df_index[7: -250], generate_data_train, 'b', label='generate_train', )
plt.plot(df_index[-250:], generate_data_test, 'k', label='generate_test')
plt.plot(df_index, all_series.clone().numpy()* train_std + train_mean, 'r', label='real_data')
plt.legend()
plt.show()

五、test model|测试模型
DAYS_BEFORE=7
TRAIN_END=-250
plt.figure(figsize=(10,16))
plt.subplot(2,1,1)
plt.plot(df_index[100 + DAYS_BEFORE: 130 + DAYS_BEFORE], generate_data_train[100: 130], 'b', label='generate_train')
plt.plot(df_index[100 + DAYS_BEFORE: 130 + DAYS_BEFORE], (all_series.clone().numpy()* train_std + train_mean)[100 + DAYS_BEFORE: 130 + DAYS_BEFORE], 'r', label='real_data')
plt.legend()
plt.subplot(2,1,2)
plt.plot(df_index[TRAIN_END + 5: TRAIN_END + 230], generate_data_test[5:230], 'k', label='generate_test')
plt.plot(df_index[TRAIN_END + 5: TRAIN_END + 230], (all_series.clone().numpy()* train_std + train_mean)[TRAIN_END + 5: TRAIN_END + 230], 'r', label='real_data')
plt.legend()
plt.show()
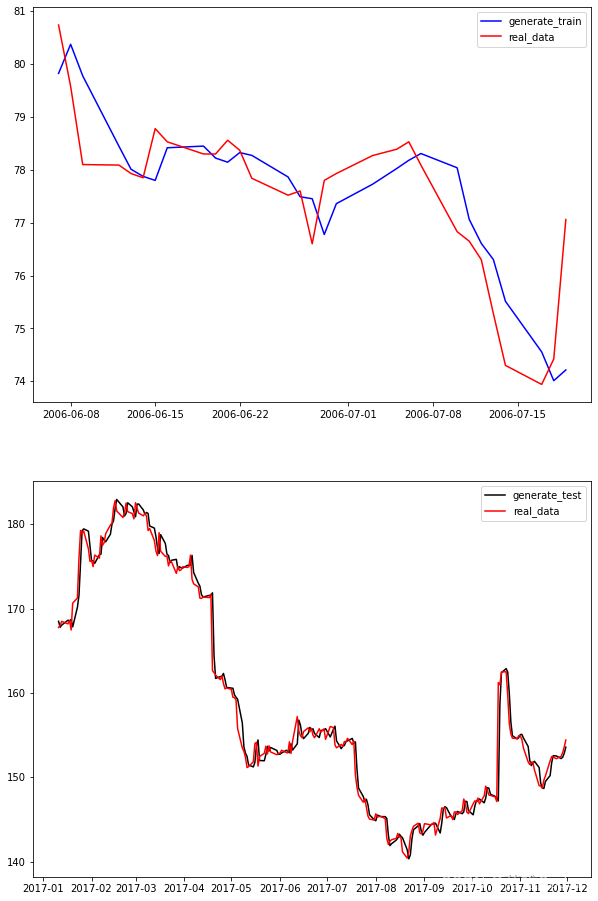
第一张图表示训练的模型在train集上的表现,第二张图表示在test上预测的表现。