C语言-数据类型
- 0. 概念
- 表达式与语句
- 字面量常量表达式/表达式
- 1. 整型
- 有符号/无符号
- 进制数
- 原码/补码/反码
- int/char
- float/double
- 2. 字符型
- 字符型与整型
- 字符与进制数/字符型进制数
- putchar/getchar
- 转义字符
- 字符集与字符编码
- C语言字符串型
- puts/gets
- printf
- scanf
- 3. 数据运算/IO
- 基本运算
- + - * /
- / %
- ++/- -
- 关系运算
- || 或
- 运算优先级
- 数据类型转换
- int/char -- 还要再看
- 大小端/位运算
- 大小端
- 位运算
- IO
- printf
- %
- 其他转义字符与特殊字符
- prinf与缓冲区
- printf/puts
- scanf
- scanf与缓冲区
- sprintf
- 4.结构体
- 创建
- 结构体的内存对齐 -- 还没看
- 结构体数组/指针
- 结构体数组
- 结构体指针
- 5. 枚举类型
- 6. 共用体(联合体)
0. 概念
- 基本类型
- 枚举类型
只能被赋值一定的离散整数值变量
- void类型
类型说明符,表明没有可用的值
- 派生类型
指针类型、数组类型、结构类型、共用体类型和函数类型
其中:函数类型指的是函数返回值的类型
表达式与语句
表达式必须返回一个结果
语句可以没有结果
字面量常量表达式/表达式
字面量:不能改变的值,数字、字符、字符串
字面值类型:算数类型、引用和指针
常量表达式:值不会改变;且在编译过程中就能得到计算结果的表达式,字面量属于常量表达式
1. 整型
int
2或4字节,(win 4字节)
unsigned int
2或4字节
short/unsigned short
2字节
long/unsigned long
4字节
long long
8字节
超过2^31-1的初始值,要加上LL后缀
double
8字节
char
1个字节,[-128,127] 或[0,255]
unsigned char
1个字节,[0,255]
size_t
在 stdio.h / stdlib.h 头文件中使用typedef定义的数据类型,表示无符号整数,也是非负数,常用来表示整数
前缀:表示进制关系
后缀:表示有符号(默认)和无符号整型U、长整型L,大小写任意,顺序任意
有符号/无符号
当以有符号数的形式输出时,printf会读取数字所占用的内存,并把最高位作为符号位,把剩下的内存作为数值位,但是对于有符号的正数而言,最高位恰好是0,所以可以按照无符号数的形式读取,且不会有任何的数值影响
当以无符号的形式输出时,printf也会读取数字所占用的内存,并把所有的内存都作为数值位对待
进制数
0b 0B # 二进制数
0x 0X # 十六进制数
0 #八进制
注意标准编译器不支持0b的二进制写法,只是某些编译器在扩展后支持
注意printf 输出形式
整型只控制字节长度,和数值范围
进制数才是实际数值的表现形式
一个数字不管以何种进制来表示,都可以 以任意进制的形式输出,因为数字在内存中始终以二进制的形式存储
其他进制的数字在存储前都必须转换成二进制形式,而在输出前也需要反转
原码/补码/反码
原码:数值的二进制数,包括符号位
反码:正数的反码=原码
负数的犯法=符号位不动,其他位置取反补码:
正数的补码=原码
负数的补码:是反码加1
-128的补码就是1000 0000
补码 1000 0000 就表示-128 记录就可以了
深究里边,是因为符号位会被数值的高位进行多次覆盖
计算机内存中,整型一律采用补码的形式存储,因此读取整数时还要采取逆向的转换,也就是将补码转换为原码
int/char
https://blog.csdn.net/u012782268/article/details/40021887
float/double
float
4字节,32位
double
8字节,64位
对于小数默认是double类型
long double
16字节
float x=1.2 # 赋值的时候,会先从double类型转换为float类型
# 后缀
float x=1.2f # 赋值的时候直接是默认的float类型
注意所有的浮点型都是以双精度double进行运算的,即使是float类型,也要先转换成double类型
<float.h>定义了宏,可以在程序中使用这些值和其他有关实数二进制表示是的细节
#include <float.h>
FLT_MIN # 最大值
FLT_MAX # 最小值
FLT_DIG # 精度值
2. 字符型
单引号
char,unsigned char是一个字符类型,用来存放字符,但是同时也是一个整数类型,也可以用来存放整数!!!,注意取值范围
char1个字节,[-128,127]
unsigned char1个字节,[0,255]
char类型只能存储ASCII字符,不能存储其他字符,根据上面的定义,也可以存放范围以内的进制数
字符型与整型
由于
char类型只能存储ASCII字符,字符集及其编码其实本质上就是二进制数,(本质上与整型没有区别)
定义一个char类型字符,会先转换成ASCII字符对应的编码再存储
而存储一个整型的时候,不需要任何转换直接存储
由于数据类型不同,所以需要的字节位数不同,因此在存储和读取的时候占用的内存不一样,所以在读取 字符型和整型 的时候并不会有冲突
字符和整型可以互相赋值
char a=10;
int b='a';
字符与进制数/字符型进制数
字符型与进制数
由于char可以存放整型,所以可以声明和定义取值范围内的进制数
下面的例子中,就可以把char想象成整型(但是要注意取值范围)
char a=0x32 // 这相当于将整型赋值给一个字符类型
printf("%c",a) // 2
printf("%d",a) // 50 这是因为由十六进制转换为的十进制
// 与python类别
// '2'.encode().hex() # 32
// int('32',16) # 50
// chr(50) # '2'
字符型进制数
对于
char类型的字符,(由于是窄字符,且只占一个字节,所以可以使用ASCII编码),(又由于ASCII编码的结果就是一个二进制数),可以利用转义的进制数进行表示
下面的例子,就可以把其当成字节对象(字节串对象),想当于python中的bytes对象,
char a='\x31' // a是字符数值1
char b='\x61' // b是字符a
char *str1="\x31\x32\x33\x61\x62\x63" // 字符串"123abc"
// 类别python
// '123abc'.encode().hex() # '313233616263'
putchar/getchar
putchar输出字符(只能输出单个字符)
getchar接收字符
char a=getchar();
转义字符
printf("\"string\'") // "string'
字符集与字符编码
多字节字符,也叫做窄字符,变长字节存储方式
宽字符是固定字节存储方式
char类型的窄字符,使用ASCII编码
char类型的窄字符串,通常来讲是UTF8编码,(其实不同的编译器在不同的平台上编码方式不同)
wchar_t类型的宽字符或宽字符串,使用UTF16或32编码
见文档
#include <wchar.h>
wchar_t a=L'a'; // 要加一个L进行标注
// 下面两个用于输出宽字符
putwchar(a);
wprintf(a);
对于中文字符应该使用宽字符的形式,并加上前缀,加上前缀后,所有的字符都变成了宽字符的存储形式
wchar_t类型,在不同的编译器下对不同的语言使用不同的长度
#include <wchar.h>
wchar_t a=L'中'
C语言字符串型
双引号
在内存中占一块连续的内存
其实字符串数据,依靠的是数组和指针来简介的存储字符串
char s1[]="string1";
char *s2="string2"
// 初始化注意事项
// char s1[10];
// s1="hello"; // 这种不行
char *s2;
s2="world"; // 这种可以
char s1[]="string"这种方法定义的字符串所在的内存既有读取权限又有写入权限(可变),可以用于输入与输出函数,存储在全局数据区或栈区
[]可以指明字符串的长度,如果不指明则根据字符串自动推算
声明字符串的时候,如果没有初始化,(由于无法自动推算长度,只能手动指定)char s[10]
char *s1="string"这种方法定义的字符串所在的内存只有读取权限,没有写入权限(不可变),只能用于输出函数,存储在常量区
puts/gets
puts输出字符串,自动换行
gets接收字符串,与scanf的区别见下
scanf把空格作为结束的标志,gets只把换行符作为字符串结束的标志
char s[10]; // 这种方式可读可写,char* s 可读不可写
char a[10]={0};
gets(a);
printf("%s\n",a);
printf("%d\n",sizeof(a)); //10
printf
字符串类型,有两种定义方式,对应在内存中有两种 读取与写入权限
在输出时,要求字符串只需要有读取权限
char* s1="hello";
char s2[10]="world";
printf("%s\n",s1);
printf("%s\n",s2);
scanf
// char s1[10];
// s1="hello"; // 这种不行
char *s2;
s2="world"; // 这种可以
// 这种可以
char s1[10];
scanf("%s",s1);
printf("%s\n",s1);
//这种不行 , 没有写入文件
// char *s2;
// scanf("%s",&s2);
// printf("%s\n",s2);
char a[10]={0};
scanf("%s",a); // 溢出能成立,但是会报错
printf("%s\n",a);
printf("%d\n",sizeof(a)); // 只能显示开辟的内存字节数量
3. 数据运算/IO
基本运算
+ - * /
下面的例子中 由于都是
int类型,所以即使是算出了float值,也会变成int类型,只不过在printf变成了对应的格式
因此必须在先前就想好结果类型
int a=1;
int b=2;
float c;
c=a/b;
printf("%f",c); // 0.000000
重要!!!
int a=10;
int b=3;
int c=a/b;
float d=a/b;
float e=(float)a/b;
printf("%d\n",c); // 3
printf("%f\n",c); // 0.000000
printf("%d\n",d); //0
printf("%f\n",d); //3.000000
printf("%d\n",e); // 随机数
printf("%f\n",e); // 3.333
/ %
%取余运算,只能作用于整型,不能作用于浮点型注意:正负数,只根据
%左边的数值符号决定!!!
++/- -
++自增--自减
num++; // 先运算后+1
num--; // 先运算后+1
//例子
v=num++; // v=num;num+=1
关系运算
|| 或
或之前为True 后面的就不再进行判断
补充
python: 10 or 20 返回10; 0 or 20 返回20
运算优先级
关系运算符:用级别具有左结合性
逻辑运算符:同级别具有左结合性,!(非)具有右结合性;逻辑运算符的优先级 < 关系运算符
单目运算符是右结合性, *p++ 等价于 *(p++)
数据类型转换
数据类型存在强制转换
原则浮点数赋给整型:浮点数小数部分会被舍去(注意不是四舍五入)
整数赋值给浮点数,数值不变,但是会被存储到相应的浮点型变量中
所有的浮点运算都是以double类型进行的,即使运算中只有float类型,也要先转换为double类型,才能进行运算
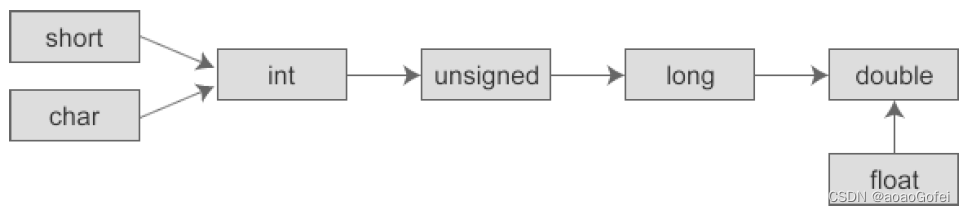
强制转换
注意,强制转换是临时性的,并不会影响数值本身的数据类型和值
(类型说明符)(表达式)
(int)(x+y)
int/char – 还要再看
int a=10;
char b='a';
printf("%c\n",b+a); // 'k'
printf("%d\n",b+a); // 107
大小端/位运算
大小端
数据低位
1234中34就是低位
大端
数据的低位放在内存的高地址上
小端
数据的低位放在内存的低地址上
位运算
位运算 是根据内存中的二进制位(补码)进行运算的,而不是数据的二进制形式
- & 与运算
用于某些位清0,某些位保留
int a=10;
printf("&x\n",a&0xff); //0xff注意在内存中的存储形式
- | 或运算
用于将某些位置1,或者保留某些位
int a=10;
printf("&x\n",a&0xff000000);
- ^ 异或运算
将某些二进制位取反
int a=10;
printf("&x\n",a^0xff000000);
- ~ 取反
全部取反
- << 左移
高位丢弃,低位补0 (根据数据位判断高低)
// 左移
9<<3
-
右移
低位丢弃,高位补0或1,数据的最高位是0,就补0;如果最高位是1,那么就补1(根据数据位判断高低)
IO
printf
https://www.runoob.com/cprogramming/c-function-printf.html – 没看完
http://c.biancheng.net/view/1793.html?from=pdf_website_1_0 – 没看
%
输出格式
%[flag][width][.percision]type
width控制输出宽度,数值不足宽度,空格补齐;数值或字符超过宽度,width不再起作用,按照数据本身宽度来输出;(例如%12f默认保留6位小数,要输出12个字符宽度);width可以用于数值、字符、字符串
.precision控制输出精度,小数位数大于precision,按照四舍五入输出;当小数位数不足precision后面补0
.precsion 与width不同,作用于整型的时候,不足宽度在左侧补0(作用于浮点数只控制小数位数);对于控制字符串输出,字符串长度大于.precision则被截断
总结,width要么补齐空格,要么不起作用;.precision对整型左侧补0或不起作用,对于浮点小数位补0或四舍五入,对于字符串被截断或不起作用
%d //十进制有符号整数
%u //十进制无符号整数
%f //float浮点数,默认保留六位小数,不足六位以0补齐,超过六位按四舍五入截断
%lf //double
%c //字符
%s //字符串
%p //指针的值
%e //指数形式的值
%x //十六进制 无符号
%lu //32位无符号整数
整型、短整型、长整型,分别有对应的printf输出形式
printf中不能输出二进制数
需要某些转换函数
一个数字不管以何种进制来表示,都可以 以任意进制的形式输出,因为数字在内存中始终以二进制的形式存储
其他进制的数字在存储前都必须转换成二进制形式,而在输出前也需要反转
有符号和无符号
当以有符号数的形式输出时,printf会读取数字所占用的内存,并把最高位作为符号位,把剩下的内存作为数值位,但是对于有符号的正数而言,最高位恰好是0,所以可以按照无符号数的形式读取,且不会有任何的数值影响
当以无符号的形式输出时,printf也会读取数字所占用的内存,并把所有的内存都作为数值位对待
因为通过格式控制符进行数值输出的时候,其实并不会检查定义的数值是有符号还是无符号数,只会按照格式控制符对数值进行特定的解释
其他转义字符与特殊字符
"\\",%%
prinf与缓冲区
通常来说,printf执行结束后数据并没有直接输出到显示器上,而是放入了缓冲区,**注意:**不同的操作系统,对于printf和缓存机制是不同的(一般是直到遇到
\n才会将缓冲区的数据输出到屏幕中)
printf/puts
puts自动换行,printf不是自动换行
scanf
从控制台读取数据
根据下面的例子,scanf会根据地址把读取到的数据写入内存
注意:多输出时的结果,除了空格外,必须严格输入
注意:超额输入的时候,不会出错,相当于位置参数(这是因为缓冲区的存在)
输入可以不是指定的类型,但是会存在数值转换的风险
scanf与缓冲区
从键盘输入的数据并没有直接交给scanf,而是放入了缓冲区中,直到回车,scanf才到缓冲区中读取数据
int a;
scanf("输入图像",&a)
// 多输入
int a,b;
scanf("%d sb %d",&a,&b) // 输入的时候,必须是'1 sb 2',不然会出错
// 超额输入
int a,b;
scanf("%d %d",&a,&b) // 输入的时候,必须是'1 2 3',不会出错,只会使用之前的内容
// 连续多输入
int a,b;
int c,d;
scanf("%d %d",&a,&b);
printf("%d sb, %d\n",a,b);
scanf("%d %d",&c,&d);
printf("%d sb, %d",c,d);
// 输入的时候,可以是 1 2 3 4 ,也能正确输出 <-- 这是因为缓存区的存在
继续读取或读取失败
int main(){
int a,b;
int c,d;
scanf("%d %d",&a,&b);
printf("%d sb, %d\n",a,b);
scanf("%d %d",&c,&d);
printf("%d sb, %d",c,d);
return 0;
}
// 输入 1 2 回车
// prinf()... 然后等待输入
// 输入 3 4 回车
// printf()... 结束
//输入 1 2 a10 (第三个是一个不符合要求的数据)
// 直接结束,上下的 c,d 显示的系统默认的初始值
int a=1;
int b=2;
scanf("%d %d",&a,&b);
printf("%d sb, %d\n",a,b);
// 输入 1 a10
// 不会出错,b输出的是初始值(和上面的例子一样)
sprintf
把格式化字符串输出到指定字符串
#include <stdio.h>
// sprintf(char*buffer,const char* format,[arg]) // 返回buffer指向的字符串的长度
// buffer 指向要被写入的字符串指针
// format 格式化字符串
// argment 任意类型数据
int a=123;
double b=456.7;
char s[10];
sprintf(s,"%d;%f",a,b);
printf("%s\n",s);
4.结构体
结构体本质上是一种数据类型
结构体中的变量或数组,叫做结构体的成员
结构体可以包含其他结构体
结构体也是一维数组,用
.获取单个成员
结构体是一种自定义的数据类型,是创建变量的模板,不占用内存空间,结构体变量则占用内存空间
结构体!=结构体变量:结构体是一种数据类型,是一种创建变量的模板,编译器不会为它分配内存空间,如int,float,char这些关键字本身不占用内存,结构体变量才是实实在在的数据,才需要内存来存储
创建
结构体是一种数据类型,可以用来定义变量
struct stu{
char* name;
int num;
}; // 注意分号
// 定义变量
struct stu stu1,stu2; // 必须加上关键字
// 在定义结构体的同时可以定义结构体变量
struct str{
char* name;
int num;
} stu1,stu2;
// 在结构体外,对成员进行赋值
stu1.name="tom";
stu1.num=12;
struct str{
char* name;
int num;
} stu1={"tom",1};
// 无结构体名,后面不能再次使用
结构体的内存对齐 – 还没看
结构体数组/指针
结构体数组
struct stu{
char* name;
int num;
}class[5];
// 声明的时候初始化
struct stu{
char* name;
int num;
}class[5]={
{"li",1},
{"w",2}
};
// 声明的时候初始化,自动推断元素个数
struct stu{
char* name;
int num;
}class[]={
{"li",1},
{"w",2}
};
// 可以在结构体外,创建结构体数组
struct stu class[]={
{"li",2},
{"wang",3}
};
// 访问数据
class[0].name;
class[1].num=2; //修改
结构体指针
struct str{
char* name;
int num;
} stu1={"tom",1};
struct stu* pstu=&stu1;
// 直接创建指针
struct str{
char* name;
int num;
} stu1={"tom",1},*pstu=&stu1;
// 使用指针获取结构体成员
(*pstu).name; // 必须加括号
pstu->name; // 直接通过结构体指针获取成员,这种方法更有效
5. 枚举类型
enum typename{var1,var2,...}
枚举值默认从0开始,后面逐渐+1
枚举列表中的标识符是常量,不能对再进行赋值,只能将varx赋值给其他变量
可以把枚举类型 类比成 宏定义 #define name var
与宏定义不同的是:宏在预处理阶段将名字替换成对应的值,枚举在编译阶段将名字替换成对应的值
varx不占用数据区(c)
enum week{Mon,Tues}; // 默认从1开始
enum week{Mon=1,Tues}; // 部分赋值,从1开始
enum week{Mon=1,Tues=2}; // 全部赋值
定义变量
// version1
enum week{Mon=1,Tues=2};
enum week a,b,c;
// version2
enum week{Mon=1,Tues=2} a,b,c;
// 对定义的变量进行赋值
enum week{Mon=1,Tues=2};
enum week a=Mon,b=Tues;
enum week{Mon=1,Tues=2} a=Mon,b=Tues;
6. 共用体(联合体)
共用体与结构体的区别
结构体的各个成员会占用不同的内存,互相之间没有影响,内存大于等于所有成员占用的内存总和 – 字节对齐的问题
共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员,内存覆盖技术,等于最长的成员占用的内存,同一时刻只保存成一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉
union data{
int n;
char ch;
double f;
}
union data a,b,c;
union data{
int n;
char ch;
double f;
}a,b,c;
// 也可以没有名称,就是之后不再被调用




![[附源码]java毕业设计朋辈帮扶系统](https://img-blog.csdnimg.cn/7ff08ce3e7a7474f91c4c1c8b5d95c0a.png)