作者简介:杨嘉力,OceanBase开源内核高级工程师。
通常情况下,数据库对磁盘的占用量会随着业务的接入时间和业务数据量大增而不断上升,导致磁盘空间不足,进而发生数据无法写入、数据库无法重启等问题。这时我们就需要排查问题根源,使磁盘得以平稳运行。本文以OceanBase 开源3.x版本为例,分享磁盘问题的排查方法,希望对你有所帮助。
排查概括
磁盘问题排查通常包括两方面,一方面,排查磁盘数据 required_size 和实际数据 data size 的大小,如果required_size 比 data size要大很多,那么很可能是多版本问题;另一方面,要排查宏块使用率,如果使用率低,排查是不是宏块重用的问题。
在正式进入排查阶段前,让我们先了解排查过程中涉及的虚拟表和排查指令。
排查过程中涉及的虚拟表和相应的注意事项如下。
- __all_virtual_meta_table (确认 reqiured_size统计的是不是最后保存在磁盘的数据长度)
- __all_virtual_table_mgr (查看sstable所占用的空间)
- __all_virtual_tenant_partition_meta_table(查看租户级的required_size 和 data_size)
- __all_virtual_sys_variable
- __all_acquired_snapshot (查看需要的快照表)
涉及的排查指令如下。
- 查看压缩算法:show parameters like ‘%compress%’;
- 查看建表语句(确认使用的压缩算法):show create table xxx\G
现在让我们开始排查磁盘占用高的问题。
排查过程三步走
如果你熟悉OceanBase数据库存储架构,那么你会知道,OceanBase的数据文件由多个Memable、多个Minor SSTable及一个(或没有)Major SSTable组成。因此,在排查过程中,我们可以遵循下述的“三步走”策略进行排查。
**第一步,我们要查看某台机器的table_type 大于 0 (所有sstable)的使用情况,**输入指令如下:
select /*+ parallel(30) */ svr_ip, table_type, sum(size) / 1024 / 1024 / 1024 as size_G from __all_virtual_table_mgr where table_type > 0 group by 1,2 order by 3 desc;
从查询的结果显示(见图1),主要问题是基线(major sstable)占用大,但data_size 和 require size没匹配(见图2),可能还有多个版本。_
_
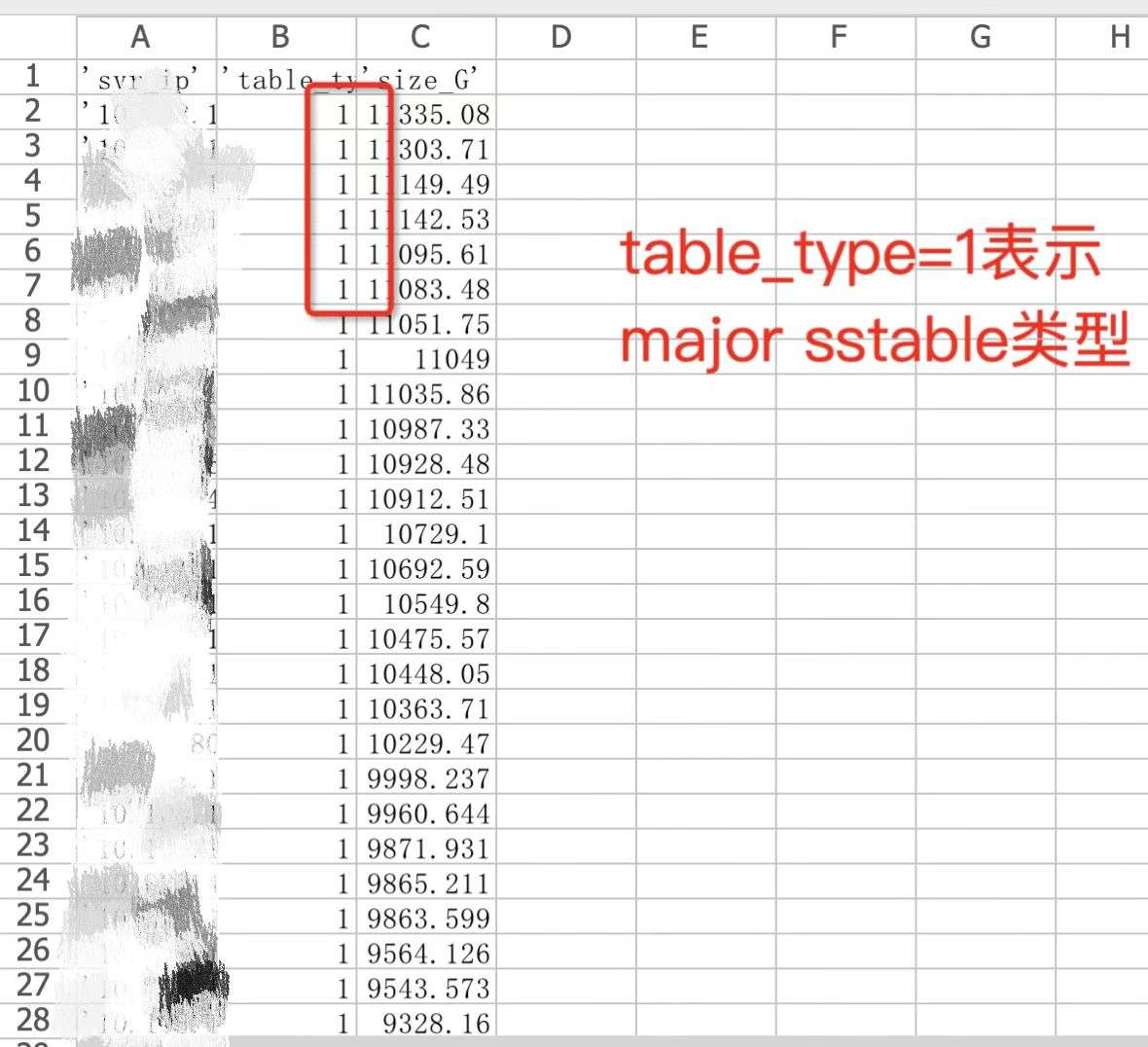
图1 查询某台机器table_type 大于 0 的使用情况的结果
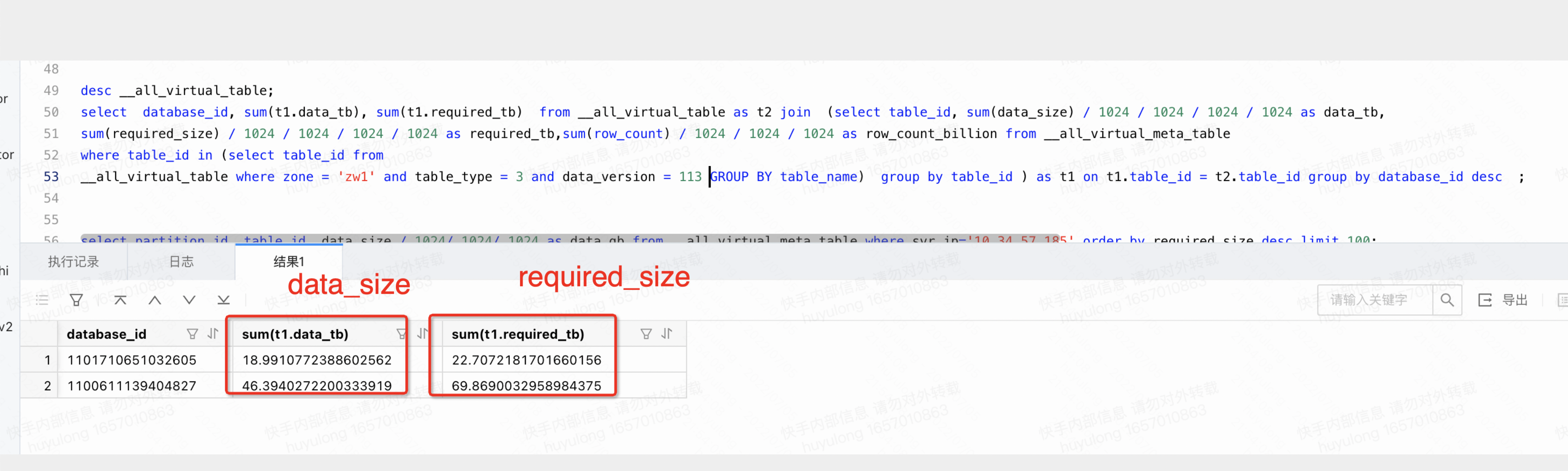
图2 data_size 和 require size没匹配
如果你不清楚table_type的所有类型,可以参考以下列表。
enum TableType {
MEMTABLE = 0,
MAJOR_SSTABLE = 1,
MINOR_SSTABLE = 2, // obsoleted type after 2.2
TRANS_SSTABLE = 3, // new table type from 3.1
MULTI_VERSION_MINOR_SSTABLE = 4,
COMPLEMENT_MINOR_SSTABLE = 5, // new table type from 3.1
MULTI_VERSION_SPARSE_MINOR_SSTABLE = 6, // reserved table type
MINI_MINOR_SSTABLE = 7,
RESERVED_MINOR_SSTABLE = 8,
MAX_TABLE_TYPE
};
摸清了问题方向和table_type的所有类型后,我们进入**第二步,排查基线数据major sstable 涉及的版本,**指令如下:
select /*+ parallel(30) */ svr_ip, version, sum(size) / 1024 / 1024 / 1024 as size_G from __all_virtual_table_mgr where table_type = 1 group by 1,2 order by 3 desc;__
__
执行结果(见图3)显示集群中保留了基线的多版本数据,而且有大量的历史版本,导致required size变大,原因可能是多版本保留位点没有推。
_

图3 基线数据major sstable 涉及版本的排查结果
此时,我们输入 select * from __all_virtual_sys_variable where name like '%undo_rete%'进行查询,查询结果见图4。
1 undo_retention 2022-06-14 20:50:15.821272 2022-06-14 20:50:15.821272 5 0 specifies (in seconds) the low threshold value of undo retention. 1 0 4294967295
1001 undo_retention 2022-06-14 20:58:07.599412 2022-06-14 20:58:07.599412 5 0 specifies (in seconds) the low threshold value of undo retention. 1 0 4294967295
1002 undo_retention 2022-06-22 18:00:03.182527 2022-06-22 18:00:03.182527 5 0 specifies (in seconds) the low threshold value of undo retention. 1 0 4294967295

图4 查询多版本保留位点的结果
为什么会保留这些版本呢,我们继续找一个svr ip分析,执行 select * from _all_virtual_table_mgr where svr_ip = xxx’ and version = 100 limit 3; 结果(见图5)显示,ip=xxx机器下存在多个索引表,由于索引表的创建需要依赖主表的snapshot_version,会hold住snapshot_version数据。因此我们要查看某个索引表的详细情况。
_

图5 svr ip分析结果
下面继续查询某个index_id下的snapshot_version版本,执行如下命令后得出图6所示结果:
select * from __all_virtual_table_mgr where svr_ip = xxx and index_id = 1101710651081814 and partition_id = 5 order by snapshot_version asc;
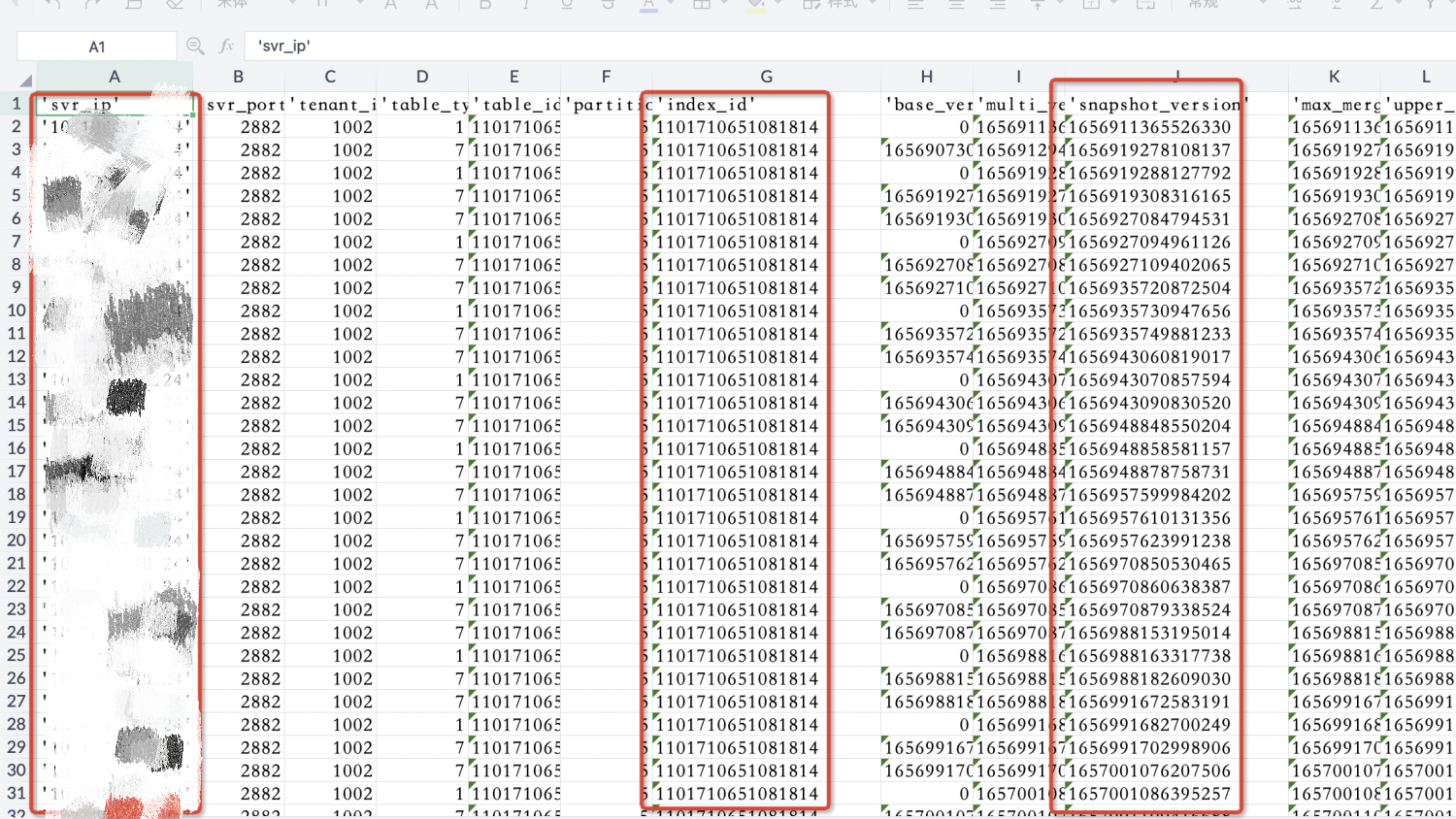
图6 查询某个index_id下的snapshot_version版本所示结果
再进一步查询,执行命令为 select * from _all_acquired_snapshot; 得出结果见图7,我们可以看到保留的snapshot快照比较多,因为合并较频繁、叠加建索引时间较久,所以需要保留多版本,故而留下来太多的major版本。
_
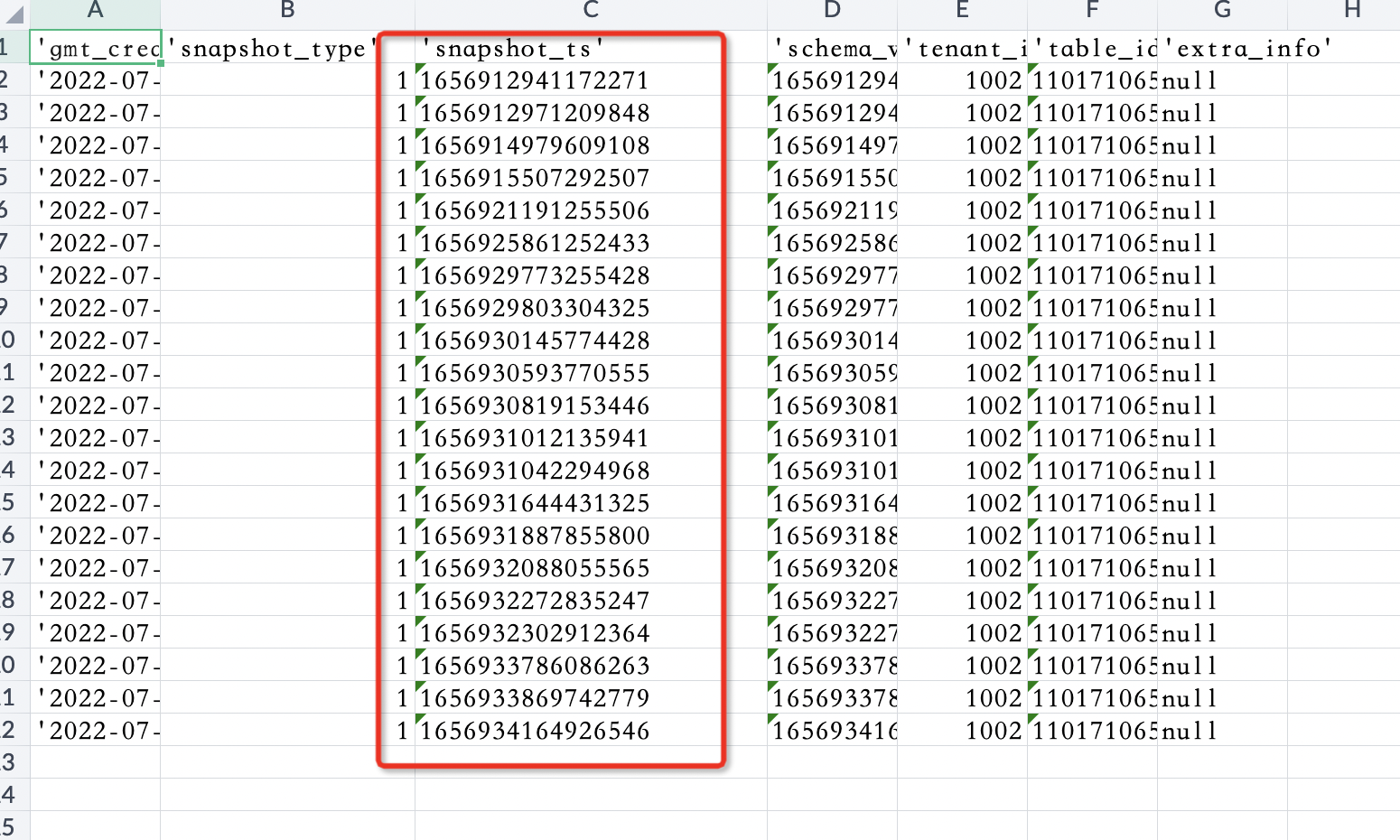
图7 snapshot快照
第三步,我们需要排查为什么保留了如此多的snapshot快照。
首先排查建索引历史任务和状态,执行命令:_all_virtual_sys_task_status,结果如图8所示。
_
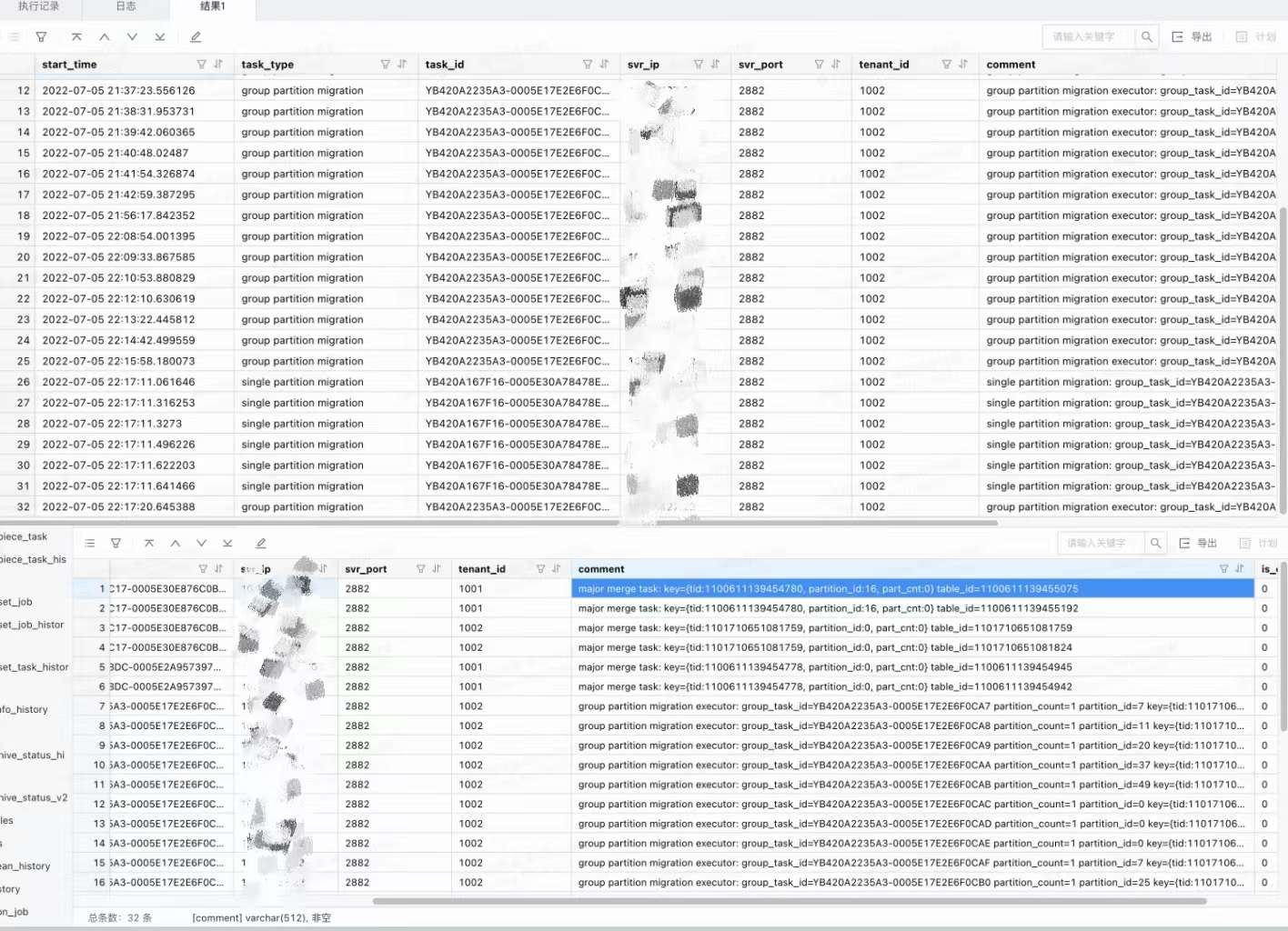
图8 排查建索引历史任务和状态
我们从图8中可以得到的信息是,命名为”1101710651081782“的表保留了两个snapshot,由于新建索引对snapshort有依赖,可能导致snapshort一直不被删除,因此我们要排查1101710651081782 table 的 index_status状态,执行命令:select table_id, index_status from __all_virtual_table where data_table_id = 1101710651081782; 结果见图9.
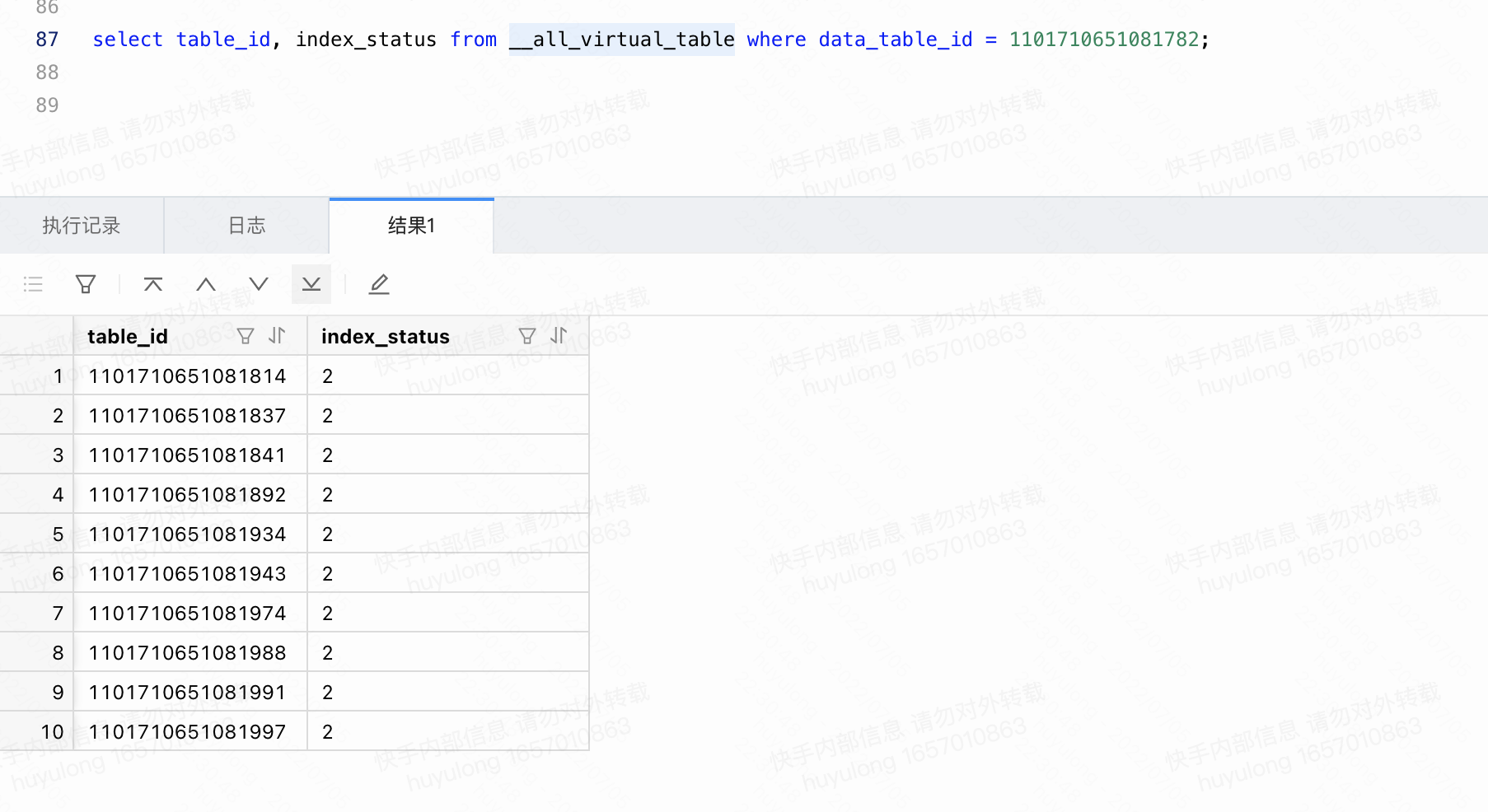
图9 1101710651081782 table 的 index_status状态
需要注意的是,图9中的table_id是指索引表的table_id,data_table_id是指主表的table_id。从此处看index_status=2,表示索引是avaliable的,理论上可以排除建索引失败导致的snapshot保留的问题。
接下来可以查看所有在__all_acquired_snapshot快照表中的table的建索引状态,排查所有在snapshot表中的table是否存在建索引异常,执行命令:select table_id, index_status from __all_virtual_table where data_table_id in (select table_id from __all_acquired_snapshot);得出结果如图10所示。
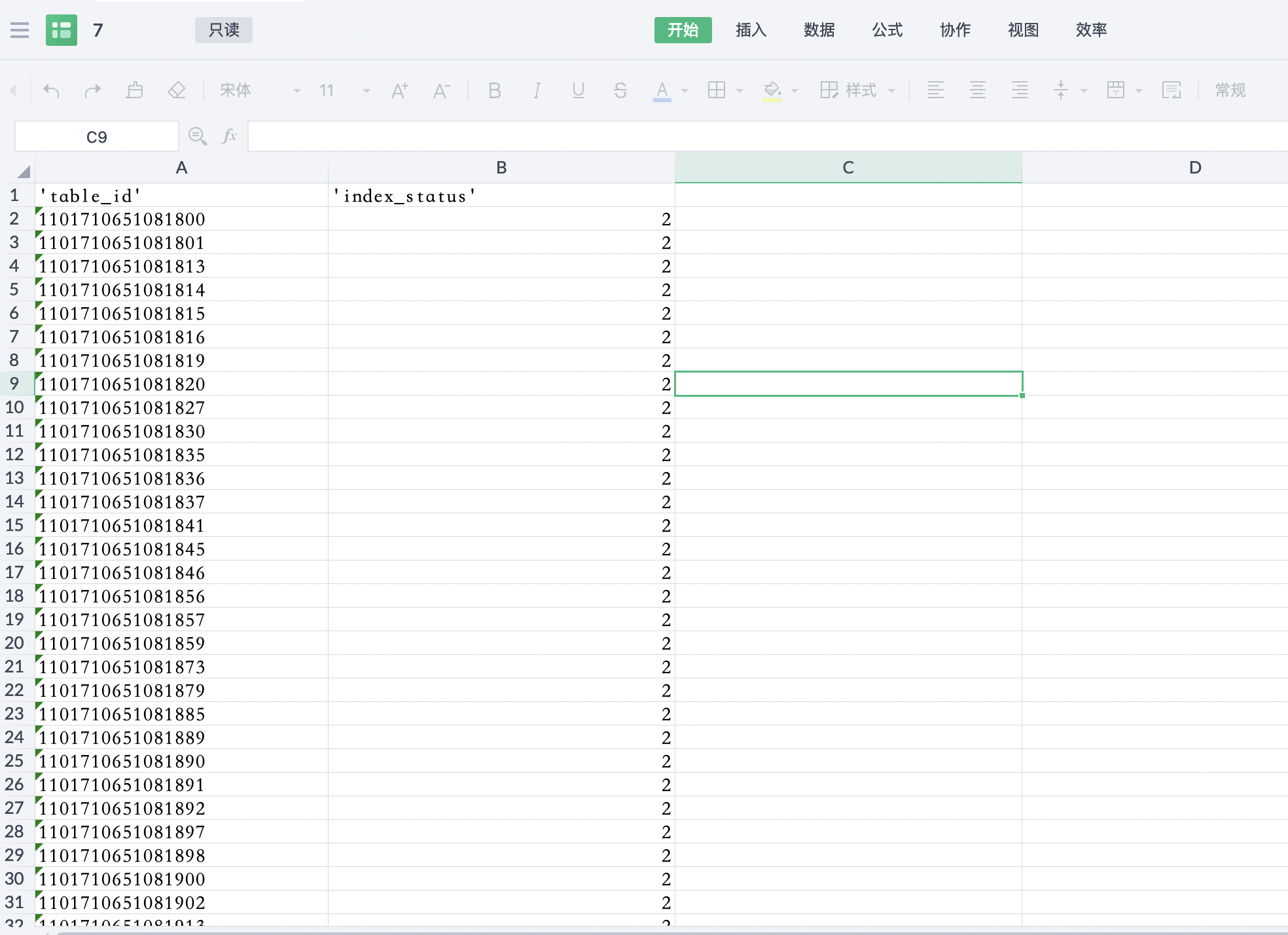
图10 所有在snapshot表中的table状态查询结果
我们结合图10中显示的查询结果与index_status的取值(如下),可以排除是新建索引失败导致的snapshot未被删除,进而导致快照点未释放,因此major merge的增多加剧了磁盘空间的占用。
enum ObIndexStatus {
// this is used in index virtual table:__index_process_info:
// means the table may be deleted when you get it
INDEX_STATUS_NOT_FOUND = 0,
INDEX_STATUS_UNAVAILABLE = 1,
INDEX_STATUS_AVAILABLE = 2,
INDEX_STATUS_UNIQUE_CHECKING = 3, // not used anymore
INDEX_STATUS_UNIQUE_INELIGIBLE = 4, // not used anymore
INDEX_STATUS_INDEX_ERROR = 5,
INDEX_STATUS_RESTORE_INDEX_ERROR = 6,
INDEX_STATUS_UNUSABLE = 7,
INDEX_STATUS_MAX = 8,
};
到此,我们的排查与分析就告一段落了,基本原因已经明确。如何解决呢?
**解决办法很简单,就是将__all_acquired_snapshot表格的记录删掉,使后台任务删除__all_acquired_snapshot的快照即可。**指令为:delete * from __all_acquired_snapshot。
但是,事情并未结束!
OceanBase集群磁盘占用异常排查
当你操作完上述三步,你发现OceanBase集群的磁盘空间占用为207TB,磁盘占用依然处于高位。这显然不符合正常情况,就需要继续定位。
排查统计方法的问题,将OceanBase集群的数据通过导入工具,从MySQL集群中导出,并从information_schema.tables汇总的所有非MySQL原生表的数据量看,数据量正常的情况下存储却膨胀近一倍,从create table 语句中可以明确用户已经开了压缩,在排除数据压缩的问题后,还有一个可能的原因是宏块中存在较多空间未被使用。
我们执行以下命令查看所有宏块的空间使用情况:
select /+ parallel(30) / 2count(1)/1024 as size_g, sum(occupy_size)/1024/1024/1024 as occupy_G from __all_virtual_partition_sstable_macro_info where tenant_id = 1001;
从图11显示的查询结果可见,宏块空间未满,剩余70TB。
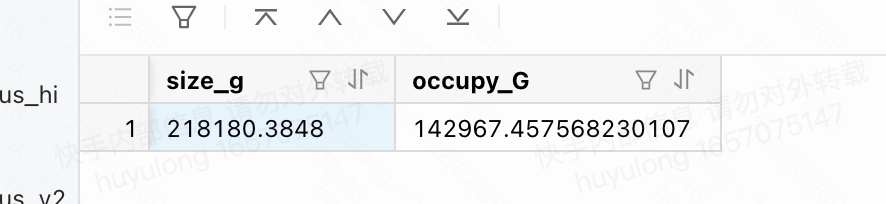
图11 宏块的空间使用情况
为什么会存在70TB如此大的宏块磁盘空间未被使用?一般情况下,做一次major merge后,存储系统会将mini sstable、minor sstable与major基线做一次全量合并,合并过程重整宏块以紧凑宏块空间,增大宏块空间利用率。因此,我们可以查询是不是基线major sstable未做合并或合并时未对宏块进行重整,导致了宏块空间使用率低的问题。在此之前,我们还需要排除下面两种mini sstable和minor sstable 宏块多造成磁盘使用高的干扰。
第一,确认有没有转储对宏块使用的影响(排查是否频繁转储生成mini sstable),命令如下:
select /+ parallel(30) / table_type, sum(size) / 1024 / 1024 / 1024 as size_G from __all_virtual_table_mgr where table_type > 0 group by 1 order by 2 desc;
排查结果如图12所示,可见磁盘空间主要被major sstable占用。
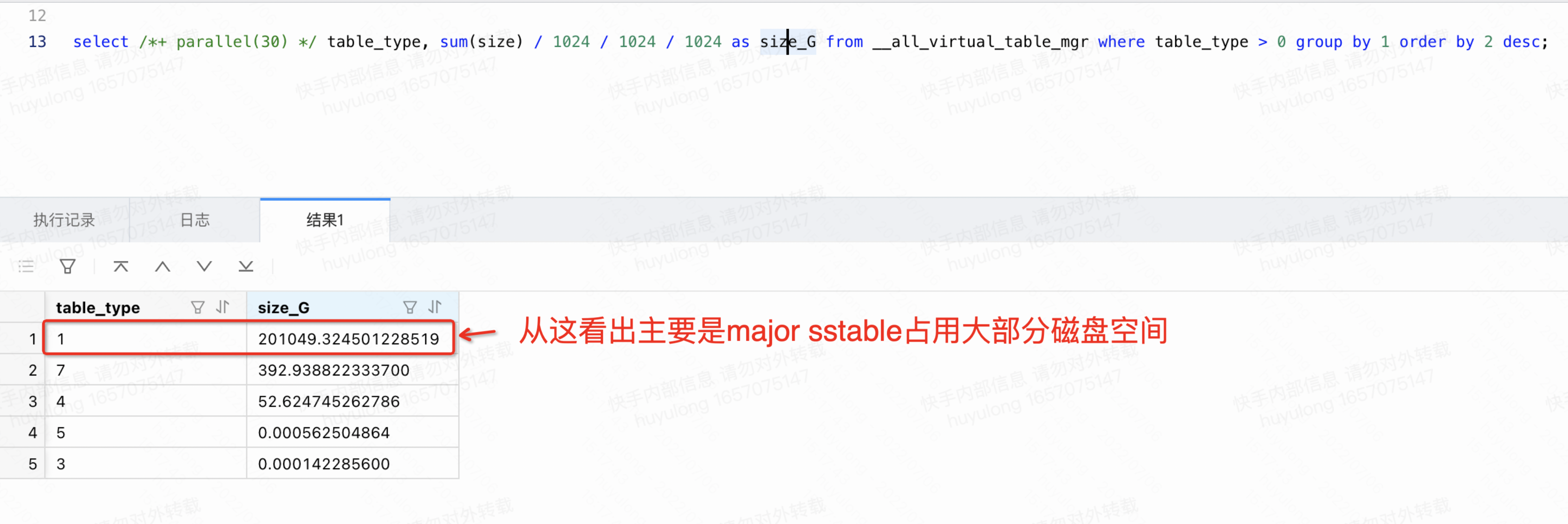
图12 排查是否频繁转储生成mini sstable的结果
第二,确认有没有多个不同版本的major (排查是否有多版本major sstable导致磁盘使用高),命令如下:
select /+ parallel(30) / version, sum(size) / 1024 / 1024 / 1024 as size_G from __all_virtual_table_mgr where table_type =1 group by 1 order by 2 desc;
排查结果见图13,从中可知,只有一个114版本的major sstable,排除多版本的影响。
_
*_

图13 排查是否有多版本major sstable导致磁盘使用高的结果
排除了mini sstable和minor sstable 宏块多造成磁盘使用高的干扰后,我们继续排查所有表中data_version=114,tenant_id=1001的sstable 宏块使用情况,命令如下:
select /*+ parallel(100) */ table_id, count(1), 2*count(1)/1024 as size_g, sum(occupy_size)/1024/1024/1024 as occupy_G from __all_virtual_partition_sstable_macro_info where data_version = 114 and tenant_id = 1001 group by 1 order by 2 desc limit 30;_
_
从排查结果(见图14)中分析,table_id为1100611139454851的宏块空间利用率很低。650/4000,不到1/7。现在我们基本可以确定是宏块空间使用率低导致的数据膨胀。
_
_
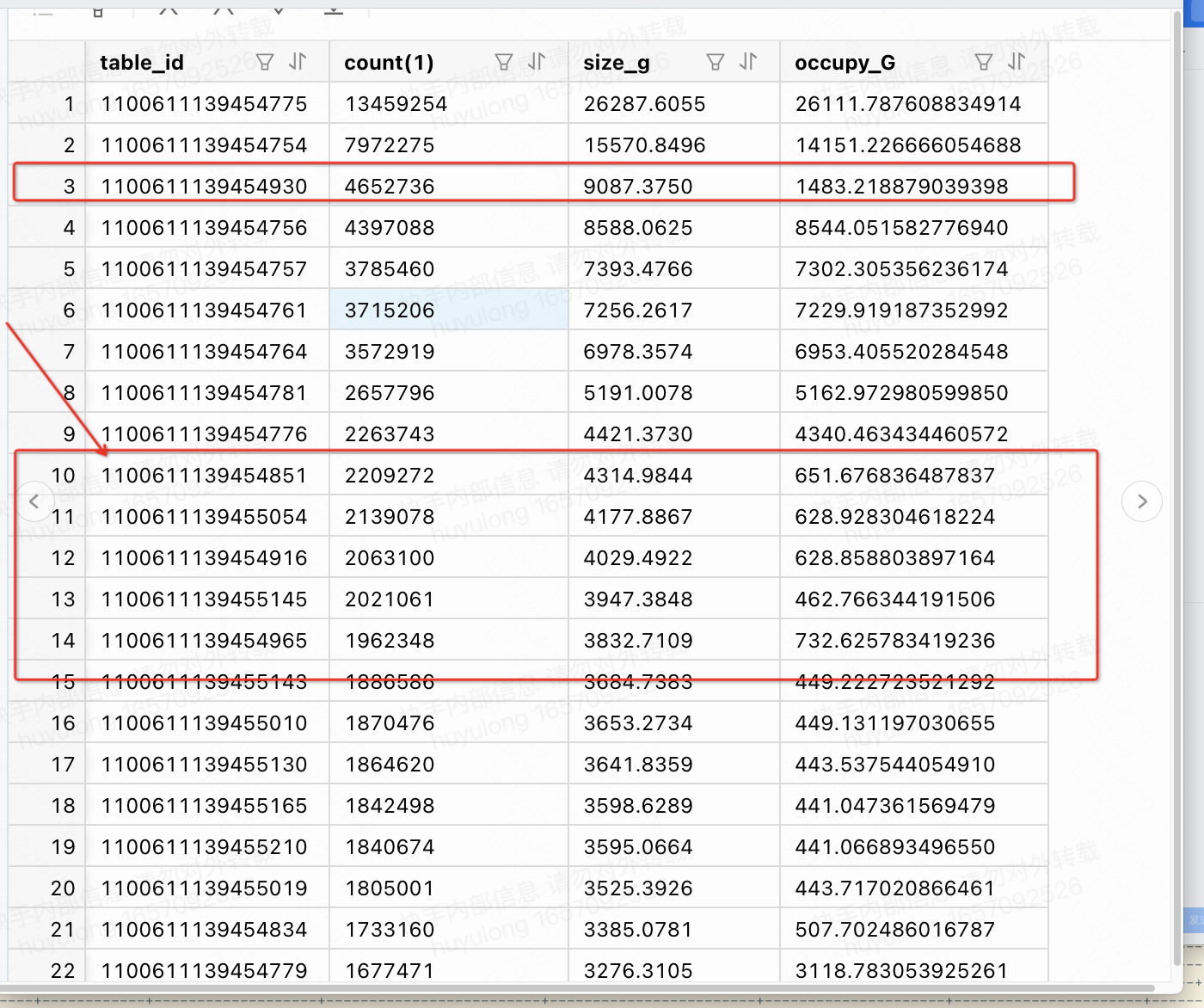
图14 所有表中data_version=114,tenant_id=1001的sstable 宏块使用情况
到此,磁盘空间膨胀(膨胀空间207TB,实际空间是140TB)的原因已经确定是索引宏块没有写满导致的。
解决办法是进行数据重整,可以修改参数 : alter table tablename set progressive_merge_num = 1, 然后执行 alter system major freeze,合并结束后,设置 progressive_merge_num = 0(以上操作仅针对磁盘放大的几张索引所在的表)。数据重整后,磁盘空间释放。
总结
总的来说,一般需要持久化的数据库系统必然需要占用磁盘空间,而磁盘占用大小取决于用户写入的数据,可以简单理解是一个线性正比关系。另外,出现不符合预期的磁盘占用情况,比如磁盘数据要比实际数据要大得多时,建议先从基础的内部表排查是否存在多版本,包括索引表的依赖版本,最后排除是否宏块利用率低导致的原因,基本就能定位问题并获得解决思路。
![[附源码]SSM计算机毕业设计中小企业人事管理系统JAVA](https://img-blog.csdnimg.cn/373bb24f0ce947d09e71d6a478758390.png)
![[附源码]Python计算机毕业设计安庆师范大学校园互助平台](https://img-blog.csdnimg.cn/d9f9f2a12fe848ed80e961536c38fb5d.png)