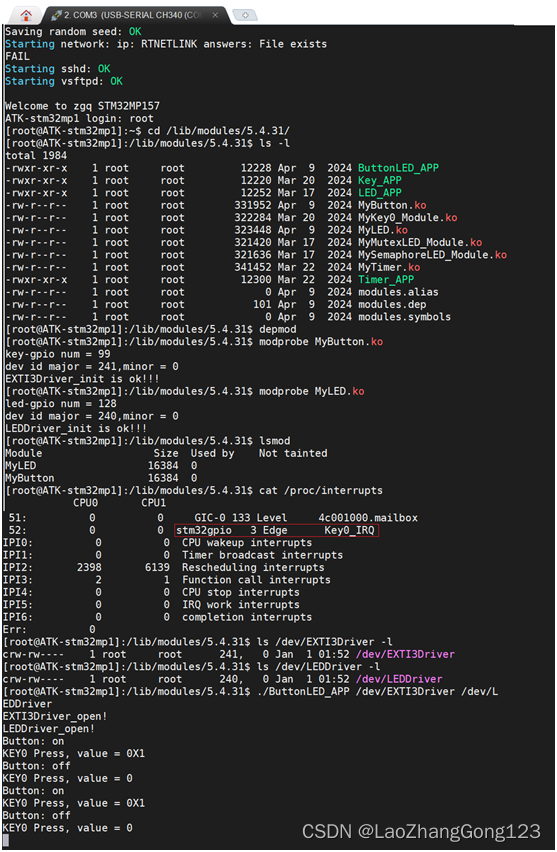
碰到的问题
上传Datafrane格式的数据到数据库 会碰见很多错误 举几个很普遍遇到的问题(主要以SqlServer举例)

这里解释下 将截断字符串或二进制数据 这个是字符长度超过数据库设置的长度
然后还有字符转int失败 或者字符串转换日期/或时间失败 这个是碰到的需要解决的最多的问题 当然仅代表个人意见和碰到的数据而言
先来看看使用pands进行上传数据库
import pandas as pd
from sqlalchemy import create_engine
# 连接数据库
# 因为本机是使用windows进行验证登录数据库 所以不需要用户和密码
data = pd.read_excel('test.xlsx')
conn = create_engine('mssql+pymssql://服务器名/数据库名')
# name为表名 dtype={} 如果数据库中未存在表 所有nvarchar将自动设置为max nvarchar(MAX)
data.to_sql(name='tablename', if_exists='append', con=conn, schema="dbo",index=False, dtype={})
conn.dispose()我们先看看如果数据存在以上出现的错误报错情况
 不能将所有错误展现出来 只会报第一次出现的错误 字符串长度过长的错误
不能将所有错误展现出来 只会报第一次出现的错误 字符串长度过长的错误

这个就是我所构建的数据 作为参照给大家看看
接下来看下其他的链接方式所报错
按照insert语句插入 这里说名下因为连接方式不一样 分为pymssql 和 pyodbc链接方式
第一种pyodbc方式连接数据库
第一种:一次性全部插入数据相当于我们的insert table values(),()
import pyodbc
import pandas as pd
# 使用pyodbc链接数据库并进行上传
data = pd.read_excel('test.xlsx')
conn = pyodbc.connect(
r'Driver={SQL Server};Server=服务器名;Database=数据库名;Trusted_Connections=yes;')
cursor = conn.cursor()
value = (tuple(i) for i in data.values)
sqlstr = "insert into {} values ({})".format('tablename',' ,'.join(['?']*len(data.columns)))
try:
a = cursor.executemany(sqlstr, value)
conn.commit()
except Exception as e:
print(e)
conn.rollback()
finally:
conn.close()报错

还是只会报一种错误
第二种一行一行插入
import pandas as pd
import pyodbc
data = pd.read_excel('test.xlsx')
columns_ = ', '.join(data.columns)
conn = pyodbc.connect(
r'Driver={SQL Server};Server=服务器名;Database=数据库名;Trusted_Connections=yes;')
cursor = conn.cursor()
# 众所周知 sqlserver inser插入对于文本数据是需要''单引号引用起来所以 我们直接读取出来的数据不可以直接使用会出错 默认为 insert tablename value (1, Jonny, None, 1, 2024-04-01) 所以会出错
# 转变形式
# 将data 进行变换
for _, row in data.iterrows():
data_item = [f"\'{row[column]}\'" for column in list(data.columns)]
sqlstr = f'''INSERT INTO tablename ({columns_}) values ({", ".join(data_item)})'''
# 注意上面','后面有一个空格 符合Sql插入的写法
try:
cursor.execute(sqlstr)
except pyodbc.Error as e:
print(e)
finally:
conn.close()报错状况

可以清楚的看到 将所有的错误都显示了出来
第二种使用pymssql进行链接数据库
import pymssql
import pandas as pd
data = pd.read_excel('test.xlsx')
conn = create_engine(r'mssql+pymssql://服务器名/数据库名')
for _, row in data.iterrows():
data_item = [f"\'{row[column]}\'" for column in list(data.columns)]
sqlstr = f'''INSERT INTO test ({columns_}) VALUES ({", ".join(data_item)})'''
try:
cursor.execute(sqlstr)
except pymssql.Error as e:
print(e)
报错情况 这里需要说明下 except pymssql.Error 和 pyodbc.Error不一样

以上为两种不同连接方式的不同报错状况
接下来是经过特殊处理查找具体报错在哪一行哪一列
数据库表属性查看
以pyodbc的报错作为主要展示 可以看到字符串长度过长报错是22001代码
这里需要说一下 获取数据库字段详细设置的代码
# 获取数据库表中的配置 包含列名、类型、nvarchar()或varchar()最大长度
import pyodbc
conn = pyodbc.connect(r'Driver={SQL Server};Server=服务器名;Database=数据库名;Trusted_Connection=yes;')
cursor = conn.cursor()
sqlstr = '''select column_name, data_type, character_maximum_length FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = '表名' '''
try:
a = cursor.execute(sqlstr)
col_attr = a.fetchall()
conn.commit()
except Exception as e:
print(e)
finally:
conn.close()
这里需要说明下 不建议使用官方的那种获取表属性方法 展示一下



这里显示的最大长度设置为100 其实表格设置的是50 会进行扩大一倍 所以为了准确判断 我们字符串是否超出此列最大设置长度不建议使用
具体报错查看
如果全部数据正确则上传 不正确则不上传并且指出具体错误到哪一行哪一列 行数是具体数据的哪一行 不是Excel的index
这里以最难的nvarchar长度举例 因为python库包装的底层代码原因 所以报错不是很清楚 查找难度会困难点
需要准备的工作
- 查找表属性
- 使用python和sqlserver上传数据
- 借用上传数据查找出错误具体内容以及具体位置
测试数据展示

Sqlserver表属性展示

# 调用要使用的python库
# 这里建议pyodbc库 原因可查看<碰到的问题>
import pyodbc
import pandas as pd
# 读取数据
data = pd.read_excel(r'D\test2.xlsx')
# 获取数据库表属性
def get_the_sqltable_attr(tablename):
conn = pyodbc.connect(r'Driver={SQL Server};Server=服务器名;Database=数据库名;Trusted_Connection=yes;')
cursor = conn.cursor()
sqlstr = f'''select column_name, data_type, character_maximum_length FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = '{tablename}' '''
try:
a = cursor.execute(sqlstr)
tab_attr = a.fetchall()
return tab_attr
conn.commit()
except Exception as e:
print(e)
finally:
conn.close()
table_attr = get_the_sqltable_attr(tablename='test')
print(table_attr)
# 取读取进来的数据进行元组化, 符合insert语句中的(column1, column2)
columns_ = ', '.join(data.columns)
print(columns_)
#连接数据库 准备上传
conn = pyodbc.connect(r'Driver={SQL Server};Server=服务器名;Database=数据库名;Trusted_Connection=yes;')
cursor = conn.cursor()
# 循环行 一行一行插入数据 速度会比to_sql慢 但是可以具体反应错误 碰到的问题有详解
for _, row in data.iterrows():
# 插入的值也要进行变换 后面我会输出 可让观察不处理的报错情况
data_item = data_item = [f"\'{row[column]}\'" for column in list(data.columns)]
sqlstr = f''' INSERT INTO 表名 ({columns_} VALUES ({', '.join(data_item)}))'''
try:
cursor.execute(sqlstr)
except pyodbc.Error as e:
if e.args[0] = '22001':
s = get_the_sqltable_attr(tablename='test')
# 因为上面的特殊处理 所以取出来的时候也会麻烦点
# 查出报错
trouble = [[s.index(i), i[0], i[2], i[1]] for i in s]
data_new = [i.split("'")[1] for i in data_item]
for i in range(len(data_new)):
if trouble[i][3] == 'nvarchar' and len(data_new[i]) > trouble[i][2] or trouble[i][3] == 'varchar' and len(data_new[i]) > trouble[i][2]:
row = int(data_item[0].split("'")[1])
column = trouble[i][1]
charter = data_new[i]
print(f'第{row}行, {column}列, 字符: {charter}字符串过长') 
现在说明下上述注释掉的为什么要将data的value进行特殊处理 {data_item = [f"\'{row[column]}\'" for column in list(data.columns)]}
如果不进行特殊处理 我们拿出来的值是

这样 insert table的value(直接传入列表)对于Sqlserver语言来说 为错
有些人可能会说直接转换为tuple() 博主亲测错误,如果为元组 里面的字符串会不带' ',但是sqlserver是需要字符串带' '
时间类型的也可以像如上处理方式一样,类型转换错误会简单点 有其他任何方法 欢迎和博主讨论 都湿手打的 如果错误了 感谢提出



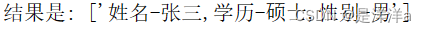









![[C++]让C++的opencv库支持写出h264格式视频](https://img-blog.csdnimg.cn/direct/e230cca047d740929638232134f47d41.jpeg)