接前一篇文章:软考 系统架构设计师系列知识点之大数据设计理论与实践(1)
所属章节:
第19章. 大数据架构设计理论与实践
第1节 传统数据处理系统存在的问题
最严重的问题是系统并没有对认为错误进行工程设计,仅靠备份是不能治本的。归根结底,系统还需要限制因为人为错误导致的破坏。然而,数据永不止步,传统架构的性能被压榨至极限,检索数据的延迟和频繁的硬件错误问题逐渐使用户不可接受,在传统架构上进行继续挖掘被证明是“挤牙膏”。帮助处理海量数据的新技术和新架构开发被提上日程,以求得让企业在现代竞争中占得先机。
越来越多的开发者参与到新技术与新架构的研究探讨中,结论与成果逐渐丰硕。人们发现,当系统的用户访问量持续增加时,就需要考虑读写分离技术(Master-Slave)和分库分表技术。常见读写分离技术架构图如图19-2所示:
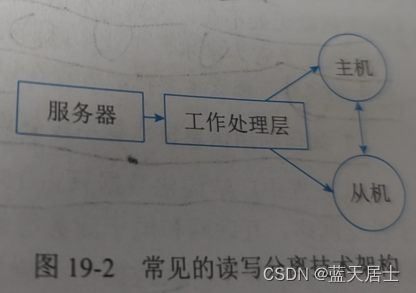
现在,数据库处理系统的架构变得越来越复杂了,相比传统的数据库,一次数据处理的过程增加了队列、分区、复制等处理逻辑。应用程序不仅仅需要了解数据的存储位置,还需要了解数据库的存储格式、数据组织结构(schema)等信息,才能访问到正确的数据。
随着技术的不断发展,商业现实也发生了变化。除了要求同一时间内可以处理的数据量提升,现代商业要求更快做出的决定更有价值。现在,Kafka、Storm、Trident、Samza、Spark、Flink、Parquet、Avro、Cloud providers等新技术成为了工程师和企业广泛采用的流行语。基于新技术,不少企业开发了自己的数据处理方式,现代基于Hadoop的Map/Reduce管道(使用Kafka、Avro和数据仓库等现代二进制格式,即Amazon Redshift,用于临时查询)如图19-3所示:

这个方式虽然看起来有其非常好的优势,但它仍然是一种传统的批处理方式,具有所有已知的缺点。主要原因是客户端的数据在批处理花费大量时间完成之前的数据处理时,新的数据已经进入而导致数据过失。
基于传统系统出现的上述问题和无数人对于新技术的渴求与探讨,“大数据”的概念被适时地提出,研究与设计大数据系统成为了新的风潮。大数据架构设计理论正是为了解决在处理海量数据时出现的种种问题,并让系统在一定的度量属性下可以接受,成为构造大数据系统的良好范式。
至此,“”的全部内容就讲解完了。更多内容请看下回。
![[C++]让C++的opencv库支持写出h264格式视频](https://img-blog.csdnimg.cn/direct/e230cca047d740929638232134f47d41.jpeg)




![NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]](https://img-blog.csdnimg.cn/img_convert/97fd17e668d92df0cb1a53031a86fb34.jpeg)