27. 移除元素 - 力扣(LeetCode)

思路一: 创建新的数组,遍历原数组,将不为val的值放到新数组当中。空间复杂度不为O(1)
思路二:双指针法
我们设置两个指针src(源数据)和dst(目标数据)分别指向数组的第一个位置,如果src指向的数值是我们要删除的数据,那么src++,如果src要的数据不是我们要删除的数据,那么把src的数据赋值给dst,并让src++,dst++。
int removeElement(int* nums, int numsSize, int val) {
int src,dst;
src=dst=0;
while(src<numsSize)//numsSize表示数组的长度
{
if(nums[src]==val)
{
src++;
}
else
{
nums[dst]==nums[src];
dst++;
src++;
}
return dat;//此时dst的值就是新数组的有效长度
}
}88. 合并两个有序数组 - 力扣(LeetCode)
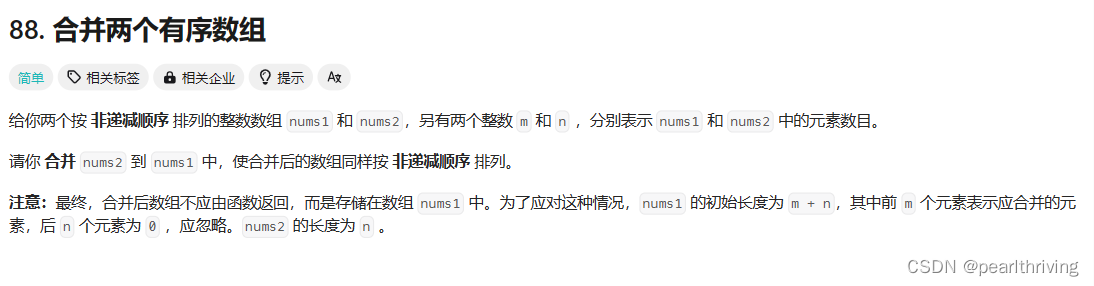
思路一:将num2中数据依次放入到num1数组的后面,用排序算法对num1进行排序
思路二:
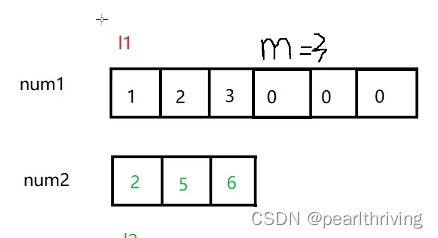
l1和l2进行比较。
思路三:
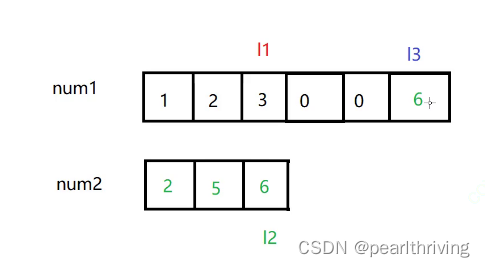
从后往前比大小:比谁大,谁大谁就往后放
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n) {
//nums1Size:nums1数组的长度
//nums2Size:nums2数组的长度
int l1=m-1;
int l2=n-1;
int l3=m+n-1;
while(l1>=0&&l2>= 0)//只要有一个条件为假,就跳出循环
{
if(nums1[l1]<nums2[l2])
{
nums1[l3--]=nums2[l2--];
}
else
{
nums1[l3--]=nums1[l1--];
}
}
//出了循环有两种情况:l1大于等于0或者l2大于等于0,不存在l1和l2同时大于等于0的情况
//只需要处理一种情况,那就是l2大于等于0,说明l2中的数据还没有完全放入num1中
while(l2>=0)
{
nums1[l3--]=nums2[l2--];
}
//此时nums1中包含了nums2中的数据,num1为升序数组
}我们需要有一个定义链表的节点的结构,并且将它们连接在一起,就成了链表。
SList.h
typedef int SLDataType;
struct SListNode
{
SLDataType data;
struct SListNode*next;//指向下一节点的指针
}SLTNode;
void SLTPrint(SLTNode*phead);
void SLTPushBack(SLTNode* phead,SLTDataType x);
void SLTPushFront(SLTNode* phead,SLTDataType x);SList.c
void SLTPrint(SLTNode* phead)
{
SLTNode*pcur=phead;
while(pcur)
{
printf("%d->",pcur->data);
pcur=pur->next;
}
printf("\n");
}
//申请新的节点
SLTNode*SLTBuyNode(SLTDataType x)
{
SLTNode*newnode=(SLTNode*)malloc(sizeof(SLTNode));
if(newnode==NULL)
{
perror("malloc fail!");
exit(1);//异常退出,正常退出为0
}
newnode->data=x;
newnode->next=NULL;
return newnode;
}
//尾插
void SLTPushBack(SLTNode**phead,SLTDataType x)
{
assert(pphead);
SLTNode*newnode=SLTBuyNode(x);//在创建 空间之前判断空间是否够用
if(phead==NULL)//处理空链表和非空链表两种情况
{
phead=newnode;
}
else
{
//找尾
SLNode*ptail=phead;
while(ptail->next)
{
ptail=ptail->next;//ptail指向的就是尾结点
}
ptail->next=newnode;//完成了尾插的动作
}
}
//头插
void SLTPushFront(SLTNode**phaed,SLTDataType x)
{
assert(pphead);
STNode*newnode=SLBuyNode(x);
newnode->next=*phead;
*pphead=newnode;
}
//尾删
void SLTPopBack(SLTNode**pphead)
{
assert(pphead&&*pphead);//链表不能为空
//链表只有一个节点
if((*pphead)->next==NULL)//->优先级高于*
{
free(*pphead);
*pphead=NULL;
}
else{//链表有多个节点
SLTNode*prev=*pphead;
SLTNode*ptail=*pphead;
while(ptail->next)
{
prev=ptail;
ptail=ptail->next;
}
free(ptail);
ptail=NULL;
prev->next=NULL;
}
}
//头删
void SLPopFront(SLTNode**pphead)
{
//链表不能为空
assert(pphead&&*pphead);//链表不能为空
SLTNode*next=(*pphead)->next;//->优先级高于*
free(*pphead);
*pphead=next;
}
//查找
SLTNode* SLTFind(SLTNode* phead,SLTDataType x)
{
SLTNode*pcur=phead;
while(pcur)//等价于pcur不等于空
{
if(pcur->data==x)
{
return pcur;
}
pcur=pcur->next;
}
return pcur;
}
//在指定位置之前插入数据
void SLTInsert(SLTNode**pphead,SLTNode*pos,SLTDataType x)
{
assert(pphead&&*pphead);//如果没有这个数据,就不能插入数据
assert(pos);
//在指定位置之前插入数据
//找pos指针的前一个节点
STNode*newnode=SLBuyNode(x);
if(pos==*pphead)
{
SLTPushFront(pphead,x);
}
else
{
SLTNode*prev=*pphead;//初始情况下指向第一个节点
while(prev->next!=pos)
{
prev=prev->next;
}
// 把prev newnode pos三者连接在一起
newnode->next=pos;
pre->next=newnode;
}
}
//在指定位置之后插入数据
void SLTInsertAfter(SLTNode**pphead,SLTNode*pos,SLTDataType x)
{
assert(pos);
STNode*newnode=SLBuyNode(x);
newnode->next=pos->next;
pos->next=newnode;
}
//删除pos节点
void SLTErase(SLTNode** pphead,SLTNode*pos)
{
assert(pphead&&*pphead);//链表不能为空
assert(pos);
if(pos==*pphead)
{
SLTNode* next=(*pphead)->next;//先把头结点的下一个节点储存起来
free(*pphead);
*pphead=next;//或者直接采用SLTPopFront(pphead);
}
else
{
SLTNode*prev=*pphead;
while(prev->next!=pos)
{
prev=prev->next;
}
free(pos);
pos=NULL;
}
}
//删除pos之后的节点
void SLTEraseAfter(SLTNode* pos)
{
assert(pos&&pos->next);
SLTNode*del=pos->next;
pos->next=del->next;
free(del);
del=NULL;
}
//销毁链表(销毁一个一个的节点)
void SListDestory(SLTNode**pphead)
{
assert(pphead&&*pphead);
SLTNode*pcur=*pphead;
while(pcur)
{
SLTNode*next=pcur->next;
free(pcur);
pcur=next;
}
*pphead=NULL;
}
如果链表为空,不能对空指针进行解引用,代码会报错。
但是当我们运行之后发现,形参改变了,实参并没有改变。
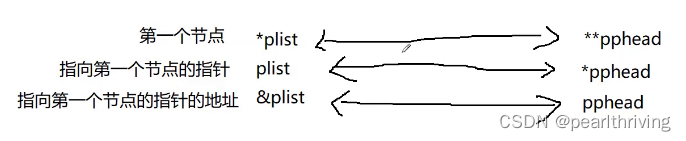
把头结点释放掉, 再把*pphead走到next指针当中。
当pos=*pphead时,走不通。
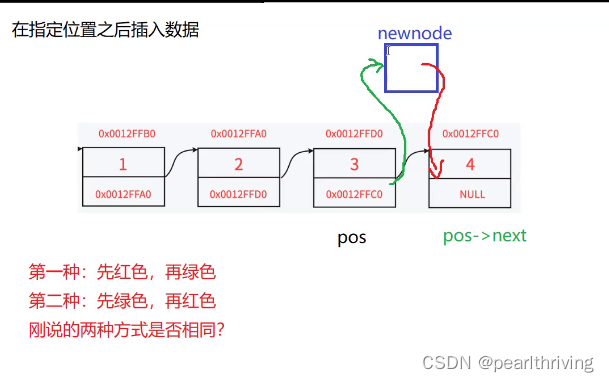
上面这两种插入节点的方式是否相同?
1 newnode->next=pos->next; pos->next=newnode;
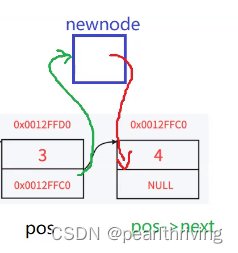
2 pos->next=newnode; newnode->next=pos->next;
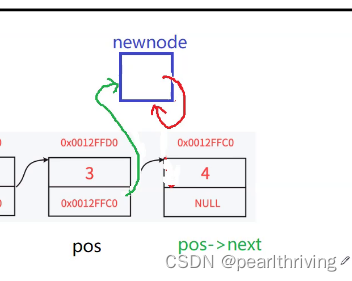
像下面这么操作,是否可行呢?
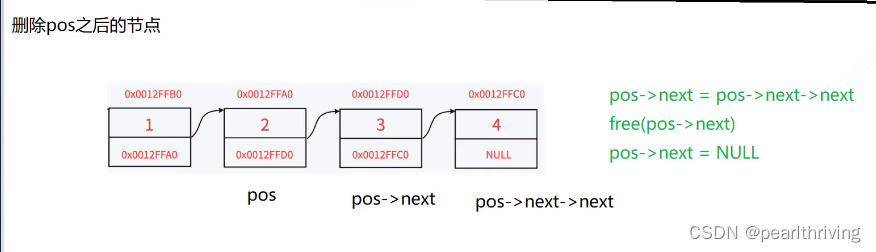
这样操作就把节点4释放了。我们可以创建一个临时变量del。
test.c
#include"SList.h"
void SListTest()
{
//链表是由一个一个的节点组成
//创建几个节点
SLNode*node1=malloc(sizeof(SLTNode));//对于节点,我们不会涉及到增容的概念,所以我们使用malloc,而不是使用realloc
node->data=1;
SLNode*node2=malloc(sizeof(SLTNode));
node->data=2;
SLNode*node3=malloc(sizeof(SLTNode));
node->data=3;
SLNode*node4=malloc(sizeof(SLTNode));
node->data=4;//创建好了4个节点,但是此时这四个节点不能相互找到
//通过每个节点里的next指针,将各个节点连接起来
node1->next=node2;
node2->next=node3;
node3->next=node4;
node4->next=NULL;
//调用链表的打印
//再定义一个节点,指向node1,然后作为实参传入
SLTNode*plist=node1;
SLTPrint(plist);
}
int main()
{
return 0;
}尾插
要找到尾结点,再把尾结点和新节点连接起来。我们让尾结点的下一节点不要指向NULL,而是指向newNode。这样就实现了尾插。
如果我们设置找到ptail的循环条件是while(ptail!=NULL),那么此时不满足。应该是ptail->next不为空。
![[CUDA 学习笔记] 矩阵转置算子优化](https://img-blog.csdnimg.cn/direct/c38345741d86487cb9bd70a1204b44a3.png)





![[方案实操|数据技术]数据要素十大创新模式(1):基于区块链的多模态数据交易服务平台](https://img-blog.csdnimg.cn/img_convert/57f84f1e0a558ca34c2abfcb40cd25c2.jpeg)