目录
- 1 引言
- 2 What?
- 3 How?
- 3.1 用法一、上下文数据存储
- 3.2 用法二、并发控制
- 3.2.1 场景1 主动取消
- 3.2.2 场景2 超时取消
- 3.3 用法三、创建一个空Context(emptyCtx)
- 4 Why?
- 4.1 go中的上下文思想
- 4.1.1 上下文是什么?
- 4.1.2 其他语言中上下文的应用
- 4.1.3 相比于struct存储,为什么go要把Context作为方法的第一参数?
- 4.2 go中的并发控制之道
- 4.3 原理探究
- 4.3.1 总体概览
- 4.3.2 上下文数据存储原理
- 4.3.2.1 数据写入
- 4.3.2.2 数据读取
- 4.3.3 并发控制原理
- 4.3.3.1 主动取消
- 4.3.3.2 超时取消
- 4.3.4 原理总结
- 4.1 go中的上下文思想
- 5 注意点
- 6 尾语
1 引言
在我们日常开发当中,你肯定会经常遇到这么一种写法
func doSomeThing(ctx context.Context,otherParam int){
//dosomething
}
在业务开发当中,几乎所有的方法第一个参数都是ctx,那么这个ctx到底是什么呢?
2 What?
Context是go标准库中一个重要的包,也是go并发编程中的一种重要模式。
主要有以下两种功能:
- 存储上下文数据
- 控制Goroutine的生命周期
在go官方推荐的用法中,推荐方法的第一个参数都是context.Context,不要试图把context存储起来。
Do not store Contexts inside a struct type; instead, pass a Context explicitly to each function that needs it. The Context should be the first parameter, typically named ctx:
func DoSomething(ctx context.Context, arg Arg) error {
// ... use ctx ...
}
3 How?
3.1 用法一、上下文数据存储
在业务开发中,这种场景比较常见,比如traceid的存入取出。
var key = "trace"
// DoSomeThing1 生成traceId放入
func DoSomeThing1(ctx context.Context) {
//任意生成的traceId
trace := "1sadfavsafas"
//存入trace
newCtx := context.WithValue(ctx, key, trace)
DoSomeThing2(newCtx)
}
// DoSomeThing2 取出traceid使用
func DoSomeThing2(ctx context.Context) {
//取出traceid
trace := ctx.Value(key)
//...
}
DoSomeThing1生成了一个traceid并将其放入ctx,其调用了context.WithValue方法,该方法返回一个新的包含了traceid的ctx,我们将其作为新的ctx传入后续的方法中,放入traceid的逻辑一般在中间件/框架中,我们一般不会感知。
DoSomeThing2从ctx取出traceid并使用。
3.2 用法二、并发控制
3.2.1 场景1 主动取消
newCtx, cancelFunc := context.WithCancel(ctx)
go func(c context.Context) {
for {
//利用c.Done()返回的通道来判断是否上层是否主动取消
select {
case <-c.Done():
//此时c.Err()返回error携带信息为 "context canceled"
print(" c.Err:", c.Err())
return
default:
print("doSomethings...")
}
}
}(newCtx)
//模拟做一些事情
time.Sleep(time.Millisecond * 1)
//上层主动控制取消
cancelFunc()
调用context.WithCancel来获得一个新的具备取消的newCtx和一个取消的方法cancelFunc。
后续调用goroutine时把newCtx传入。
协程中调调用Done方法获得一个通道,该通道可用于感知上层是否主动取消,从而做出一些有针对性的逻辑。
上层通过调用cancelFunc方法来取消ctx。
当然你还可以将取消原因传入
newCtx, cancelFunc := context.WithCancelCause(ctx)
go func(c context.Context) {
for {
//利用c.Done()返回的通道来判断是否上层是否主动取消
select {
case <-c.Done():
//此时c.Err()返回error携带信息为 "context canceled"
print("c.Err:", c.Err().Error())
//可以通过context.Cause来获取取消的原因
print("cause:", context.Cause(c).Error())
return
default:
print("doSomethings...")
}
}
}(newCtx)
//模拟做一些事情
time.Sleep(time.Millisecond * 1)
//上层主动控制取消
cancelFunc(errors.New("取消原因:我不想继续了"))
3.2.2 场景2 超时取消
在主动取消的基础上,context在其基础还支持另一种超时取消。
//设置超时时间
newCtx, cancelFunc := context.WithTimeout(ctx, time.Millisecond*1)
go func(c context.Context) {
for {
//利用c.Done()返回的通道来判断是否上层是否主动取消
select {
case <-c.Done():
//主动调用cancel方法返回context canceled,超时返回context deadline
print("c.Err:", c.Err().Error())
//默认情况下超时会返回context deadline exceeded,主动取消会返回context canceled
print("cause:", context.Cause(c).Error())
return
default:
print("doSomethings...")
}
}
}(newCtx)
//模拟做一些事情
time.Sleep(time.Millisecond * 1)
//可以选择主动控制取消
cancelFunc()
我们可以调用context.WithTimeout方法放入超时时间。
为了方便我们调用,context还提供了其他变种操作
newCtx, cancelFunc = context.WithTimeoutCause(ctx, time.Millisecond*1, errors.New("超时取消原因,可以通过context.Cause(c)获取"))
//指定时间超时
newCtx, cancelFunc = context.WithDeadline(ctx, time.Now().Add(time.Millisecond*1))
newCtx, cancelFunc = context.WithDeadlineCause(ctx, time.Now().Add(time.Millisecond*1), errors.New("超时取消原因,可以通过context.Cause(c)获取"))
3.3 用法三、创建一个空Context(emptyCtx)
这个我们直接看用法即可
//一般作为根节点使用,使用场景:初始化/测试
ctx:=context.Background()
//当你没想好用什么类型的context时使用
ctx=context.TODO()
4 Why?
4.1 go中的上下文思想
4.1.1 上下文是什么?
简单来说,就是在 API 之间或者函数调用之间,除了业务参数信息之外的额外信息。比如,服务器接收到客户端的 HTTP 请求之后,可以把客户端的 IP 地址和端口、客户端的身份信息、请求接收的时间、Trace ID 等信息放入到上下文中,这个上下文可以在后端的方法调用中传递。
4.1.2 其他语言中上下文的应用
其实上下文的概念在其他语言也是使用广泛,比如Java 中的ServletContext,ApplicationContext(spring框架),以及Java中的ThreadLocal 类 等等。
相对于go而言,Java上下文的作用只有一个,那就是存值。
对于存值而言,go采用的就是参数传递的方式( passed as the first argument in a method),而Java采用的就是结构体存储的方式(stored in a struct type)
4.1.3 相比于struct存储,为什么go要把Context作为方法的第一参数?
这篇官方blog其实已经给出了答案
https://go.dev/blog/context-and-structs
总结一下就是:
- 更加安全,更容易理解,不用顾虑该Context被其他地方滥用
- 作为强规范,保证在server里的每个请求都能被正常取消
4.2 go中的并发控制之道
以Java为例,Java中的线程控制往往需要一个“句柄”,才能控制线程,比如Thread.interrupt方法,他需要thread对象才能调用。
相比之下,go由于context的存在,可以很优雅的控制协程。
为了解释go中的并发控制思想,我先来看看go程序是怎么运行的
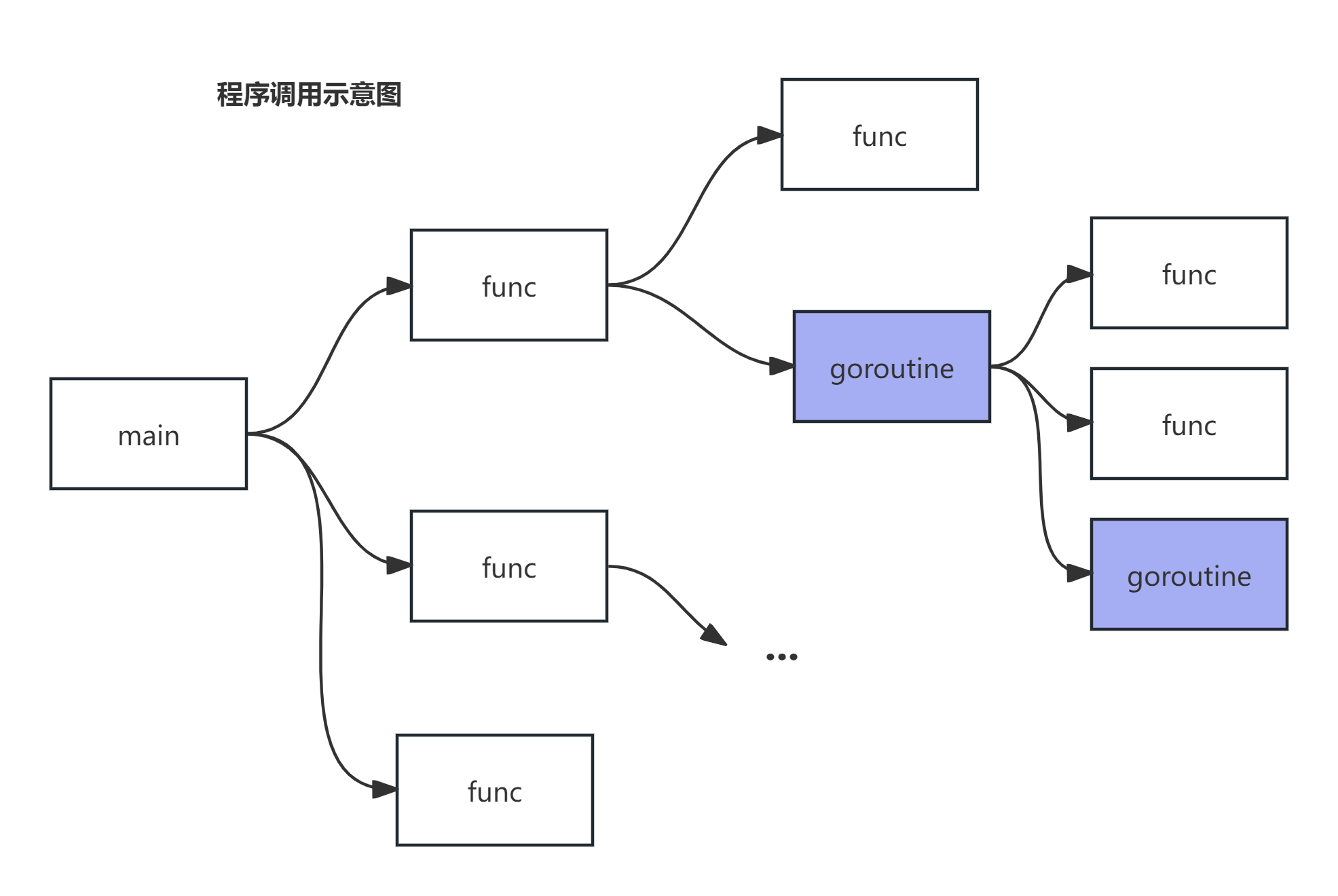
如图中所示,每个go程序都是从一个main函数出发的,由main函数开始,我们“开天辟地”,衍生出各种同步/异步的调用。但不管怎么调用,这种调用关系总呈现出一种形态——多叉树。
现在我们再来看Context的组织形式。
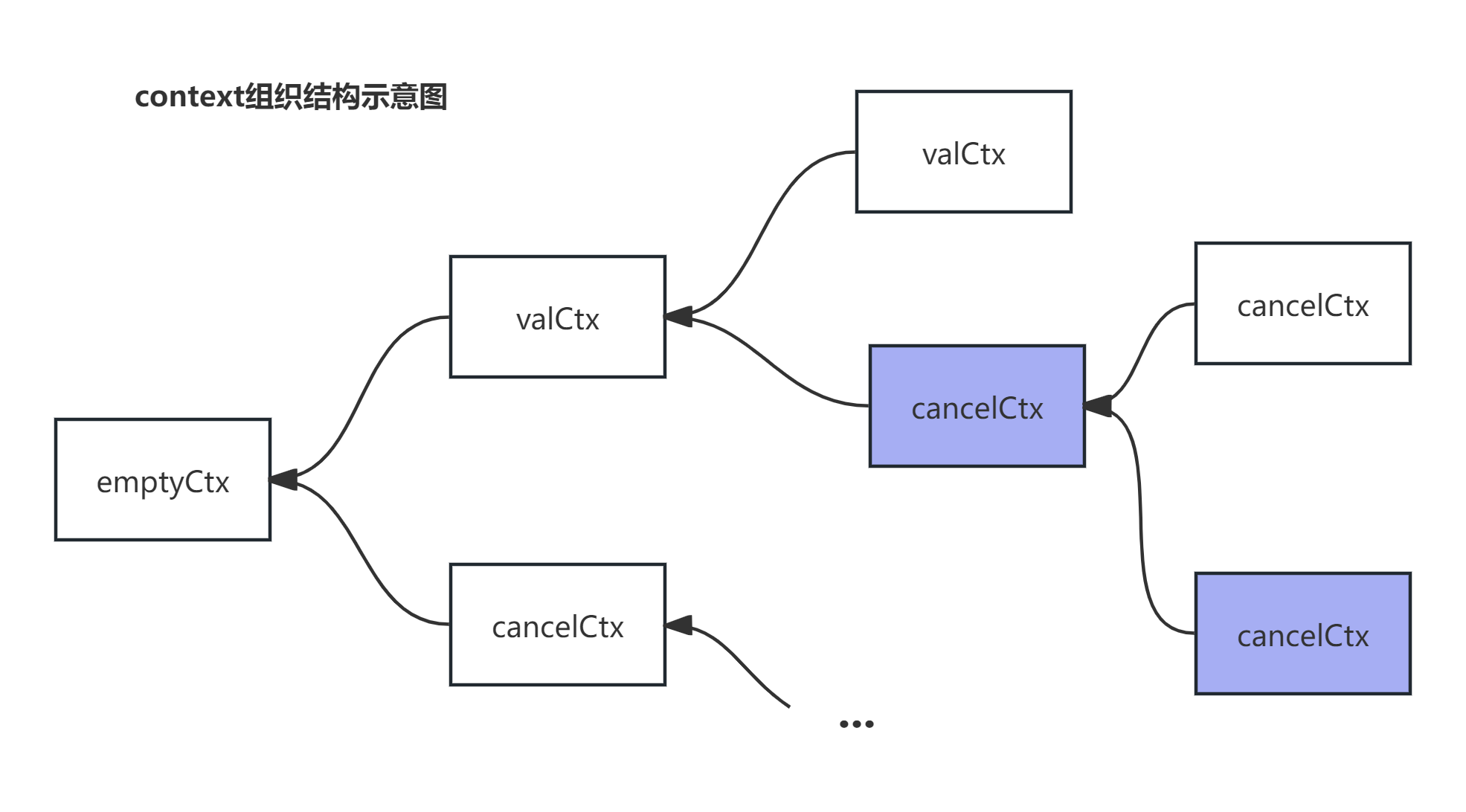
怎么样,是不是十分相似!这就是go并发控制的思想核心。
每一次/多次调用都可以抽象为一个context,它的生命周期由这个context去控制。换句话说,每个context背后都意味着一次/多次的调用。
你可以这么理解,在go的思想里,context便是协程的 “令牌”。
每个协程通过令牌状态(取消or未取消),来决定接下来的行为(继续or阻塞or退出)。
而这枚令牌只能传递给自己的“徒弟”(子节点/调用的函数),所以只有“师傅”有资格拥有这枚令牌,从而“号令”自己的“徒弟”。
对于你的“同门/师傅”,你无法将这枚令牌给他们,因为你没那个机会(context只能作为函数调用的第一个参数传递)。
当然你也有你的“师傅”(父节点),所以当你的“师傅”对你发号施令(cancel),你也得号令你的“徒弟”和你一起(调用子节点的cancel)。
4.3 原理探究
4.3.1 总体概览
首先是接口 Context
type Context interface {
//根据key返回value,可以当做map使用
Value(key any) any
//返回一个通道,用于感知ctx是否结束
Done() <-chan struct{}
//返回过期时间
Deadline() (deadline time.Time, ok bool)
//返回上下文err,一般可用于查看ctx关闭的原因(取消/超时)
Err() error
}
Context接口有四个方法,Value方法用于用法一(上下文数据存储),剩余三个方法用于用法二(并发控制)
在context包中,实现了该接口的主要结构体有三个:valueCtx、cancelCtx、timerCtx,用于实现不同的功能
type valueCtx struct {
Context
key, val any
}
type cancelCtx struct {
Context
mu sync.Mutex // protects following fields
done atomic.Value // of chan struct{}, created lazily, closed by first cancel call
children map[canceler]struct{} // set to nil by the first cancel call
err error // set to non-nil by the first cancel call
}
type timerCtx struct {
cancelCtx
timer *time.Timer // Under cancelCtx.mu.
deadline time.Time
}
可以看到每个context内部都持有一个context的指针(struct内嵌了接口),它们的组织关系实际上是一个多叉树。
这种多叉树的结构,和我们调用链非常契合,我想这也是它这么设计的原因。
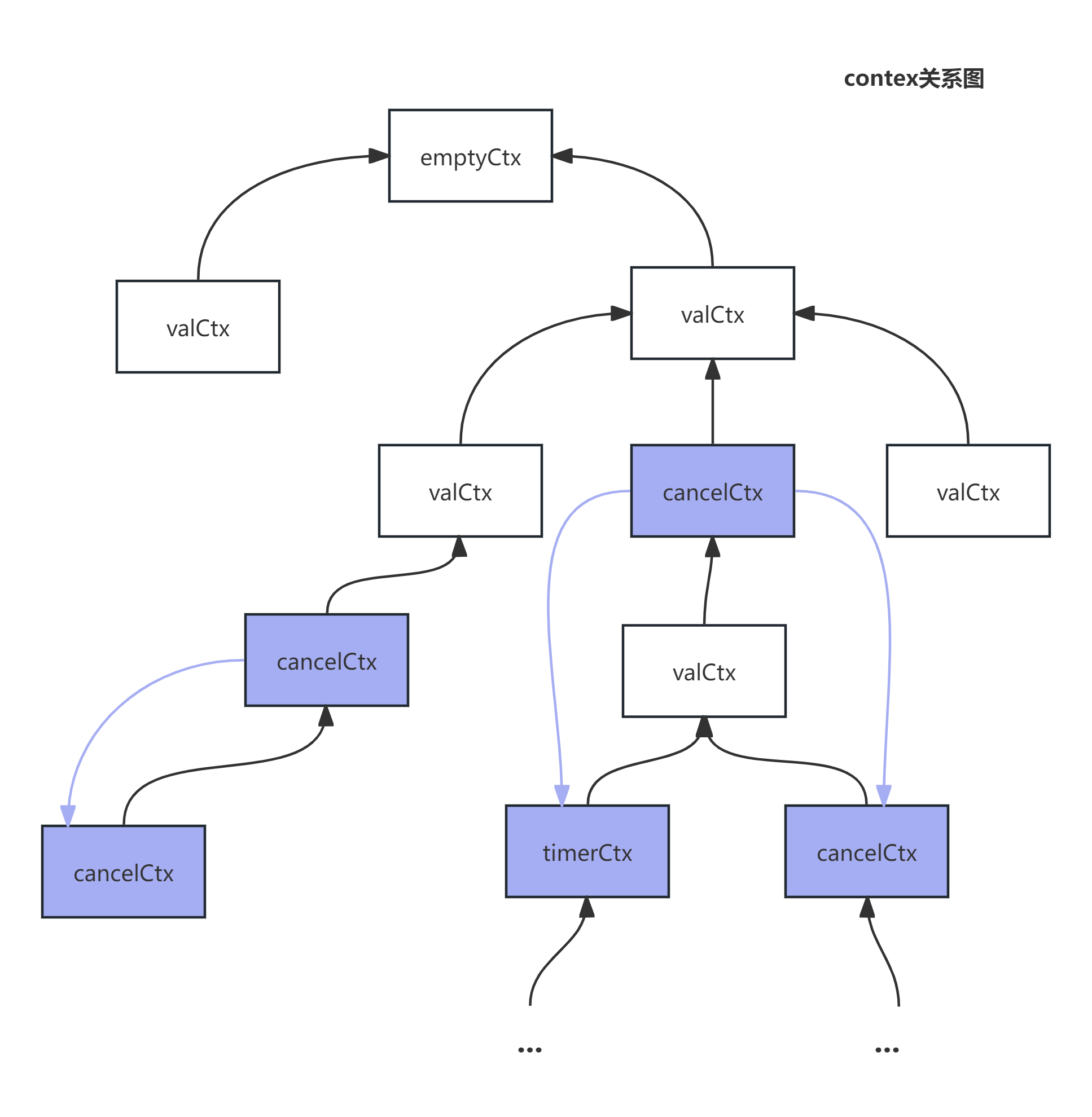
接下来你要牢记这张图,这将有利于你理解接下来的原理。
4.3.2 上下文数据存储原理
我们来细看valueCtx结构体
type valueCtx struct {
Context
key, val any
}
可以看到该struct里面内部存了key,val 键值对,而数据的存储就是这一个个key-value。
4.3.2.1 数据写入
之前用法中提到过,数据写入是通过WithValue方法写入的
func WithValue(parent Context, key, val any) Context {
if parent == nil {
panic("cannot create context from nil parent")
}
if key == nil {
panic("nil key")
}
if !reflectlite.TypeOf(key).Comparable() {
panic("key is not comparable")
}
return &valueCtx{parent, key, val}
}
可以看到,该方法返回了一个新的context,该context指向的就是原来的ctx。
实际上它就是返回了一个子节点,该子节点上存储了这次存入的key、val键值对。
这就是为什么我们调用WithValue方法后需要将返回值传入后续的方法中。
4.3.2.2 数据读取
调用ctx.Value()即可实现数据读取的操作
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}
func value(c Context, key any) any {
for {
switch ctx := c.(type) {
case *valueCtx:
if key == ctx.key {
return ctx.val
}
c = ctx.Context
case *cancelCtx:
//本次无关,先隐去...
case *timerCtx:
//本次无关,先隐去...
case *emptyCtx:
return nil
default:
return c.Value(key)
}
}
}
可以看到数据读取过程是一个不断往上找父节点的过程。当有节点的key相等时,则返回对应的val,否则不断向上查找,直到emptyCtx(一般是根节点)时返回nil。
我们重新来看这张图,
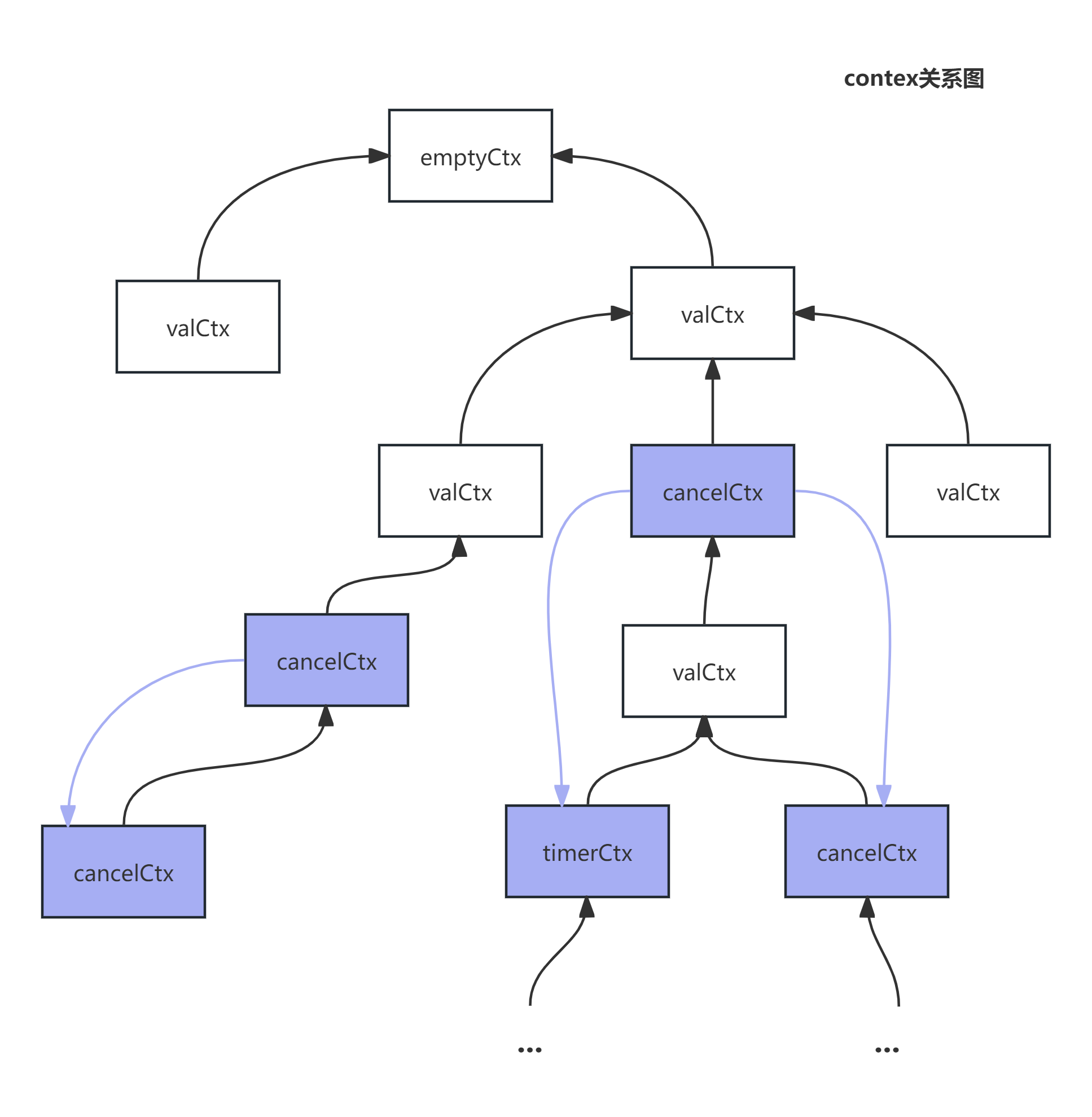
每个ctx背后都对应着一次函数调用,当前获取到的上下文数据就是父节点的上下文数据,而非后续的子节点/兄弟节点。
这天然和我们函数调用相契合。
4.3.3 并发控制原理
这里我们举两种典型用法为例子,其他变种大同小异。
4.3.3.1 主动取消
我们先来仔细看下cancelCtx结构体,
// A cancelCtx can be canceled. When canceled, it also cancels any children
// that implement canceler.
type cancelCtx struct {
Context
mu sync.Mutex // protects following fields
done atomic.Value // of chan struct{}, created lazily, closed by first cancel call
children map[canceler]struct{} // set to nil by the first cancel call
err error // set to non-nil by the first cancel call
}
其中最重要的便是children这个字段,该字段是一个map,内部存储的是该ctx下所有cancelCtx类型的子节点的指针,就好像图中紫线所示。
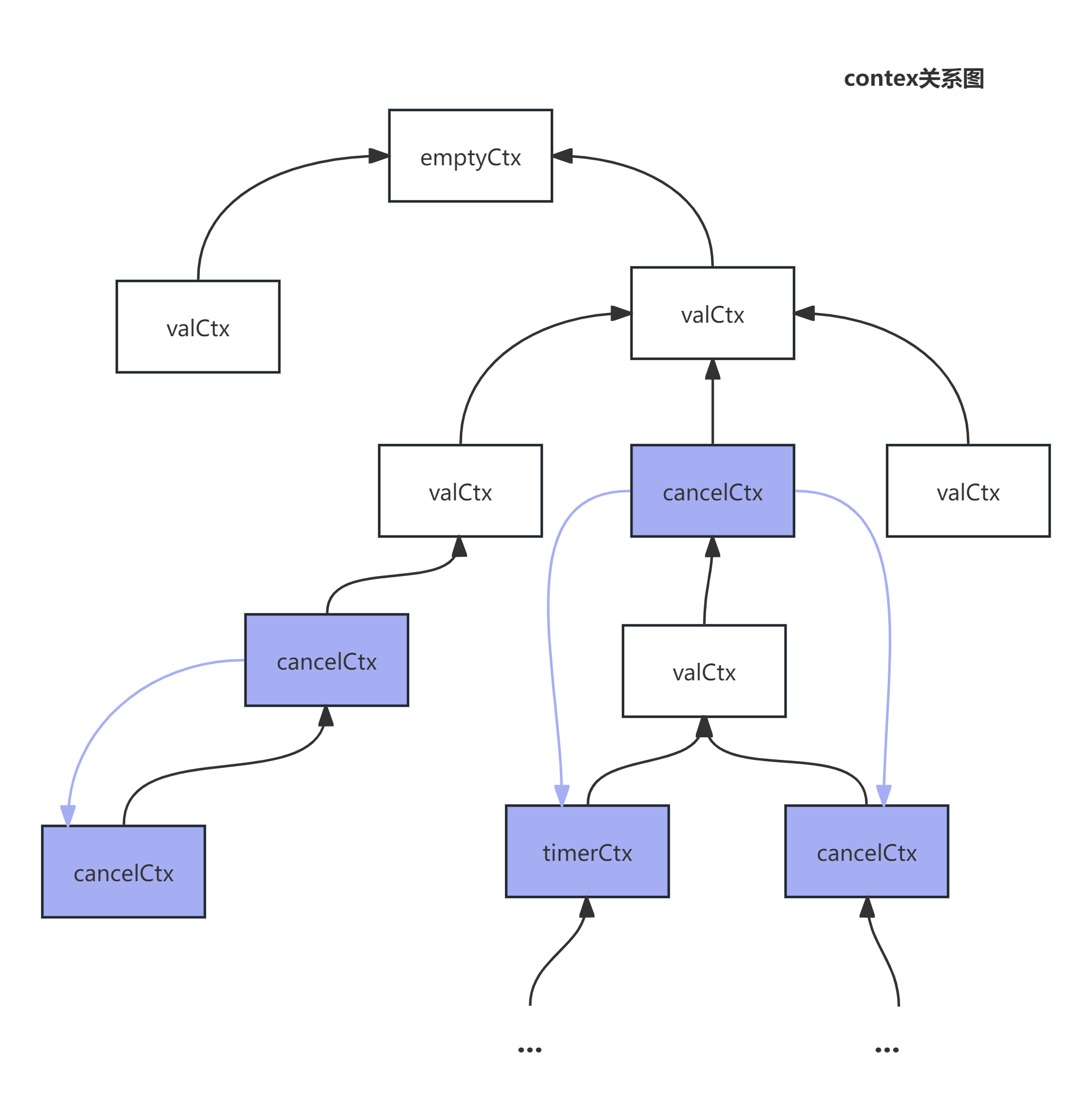
接下来我们看context.WithCancel 是如何创建cancelCtx的
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
//1.生成一个子节点结构体
c := newCancelCtx(parent)
//2.向上寻找上一个cancelCtx,和其建立联系
propagateCancel(parent, &c)
//3.放回一个匿名函数,其逻辑就是调用了取消方法
return &c, func() { c.cancel(true, Canceled) }
}
func newCancelCtx(parent Context) cancelCtx {
return cancelCtx{Context: parent}
}
cancelCtx节点生成和valCtx一样,也是生成parent的子节点,内部含一个指针执行父节点。
第二步便是propagateCancel,该函数大致逻辑就是向上寻找上一个cancelCtx,和其建立联系,以下仅展示关键代码
func propagateCancel(parent Context, child canceler) {
if p, ok := parentCancelCtx(parent); ok {
//若是找到了,则将自己加入上一个cancelCtx的children中
if p.children == nil {
p.children = make(map[canceler]struct{})
}
p.children[child] = struct{}{}
} else {
//若是自身就是那个最顶层的cancelCtx,则会开启一个协程监听父节点是否结束,如果结束则会调用cancel方法
atomic.AddInt32(&goroutines, +1)
go func() {
select {
case <-parent.Done():
child.cancel(false, parent.Err())
case <-child.Done():
}
}()
}
}
//向上找父节点,找不到返回nil,false
func parentCancelCtx(parent Context) (*cancelCtx, bool) {
p, ok := parent.Value(&cancelCtxKey).(*cancelCtx)
//省略...
}
接下来它会不断向上找上一个cancelCtx
- 若是找到了,则将自己加入上一个cancelCtx的children中
- 若是没找到,意味着自身就是那个最顶层的cancelCtx,则会开启一个协程监听父节点是否结束,如果结束则会调用cancel方法
第三步则会返回指向父节点的cancelCtx,同时返回一个匿名函数,该方法内部就调用该节点cancel函数。
接下看cancel函数
func (c *cancelCtx) cancel(removeFromParent bool, err error) {
//...
d, _ := c.done.Load().(chan struct{})
if d == nil {
c.done.Store(closedchan)
} else {
close(d)
}
for child := range c.children {
// NOTE: acquiring the child's lock while holding parent's lock.
child.cancel(false, err)
}
c.children = nil
//...
}
cancel方法主要干了两件事:
- 向done 里存入一个chan,用于通知该ctx已经结束
- 遍历调用子节点cancelCtx的cancel方法
到此,总结一下主动取消的原理:
- cancelCtx内部存了下一层cancelCtx类型的子节点指针,当cancel时它也会cancel子节点
- 调用WithCancel函数返回的是一个子节点ctx,调用过程会将自己“注册”到父节点中;没有父节点的会监听上层ctx是否Done了,当监听到父节点已经结束时,调用自身cancel函数取消
4.3.3.2 超时取消
接下来我们看timerCtx
type timerCtx struct {
cancelCtx
//计时器,用于到时间了触发cancel函数
timer *time.Timer
//到期时间
deadline time.Time
}
相信聪明的你在看到结构体的时候,就已经恍然大悟了…
可以看到timerCtx内嵌了cancelCtx,这意味着timerCtx拥有所有cancelCtx的能力,在此基础上有两个时间字段timer和deadline。
回到用法二超时取消场景,context通过WithDeadline 和 WithTimeout获取到cancelCtx,这里我们依然只保留关键代码
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) {
//...
c := &timerCtx{
cancelCtx: newCancelCtx(parent),
deadline: d,
}
//向父节点注册自己
propagateCancel(parent, c)
//...
//在deadline到来时,调用cancel函数
c.timer = time.AfterFunc(dur, func() {
c.cancel(true, DeadlineExceeded)
})
return c, func() { c.cancel(true, Canceled) }
}
其实这里只多了一个逻辑——到了Deadline时间后主动调用cancel函数,以达到超时取消的效果。
4.3.4 原理总结
context本质的数据结构是一种多叉树,它和我们函数调用关系天然契合。
在常规上下文存储数据方面,
- 每个节点都存储了key,val 键值对
- 调用参数传递的规范是context上下文不被滥用的核心
- 查找数据时,会由子节点不断向上查找
在并发控制方面,
- context可以理解为“令牌”,下游调用的生命周期通过感知“令牌”的状态来进行控制
- 当context的状态变更,也会导致子节点context状态变更,从而控制下游的调用
- 超时控制,不过是利用timer包定了个“闹钟”,到时间执行cancel函数
5 注意点
以下是我在业务开发过程中所积累的一点点经验,供大家参考
- 请求http时,如果整体时间不长,可以重新创建一个ctx来避免超时控制
- 用接口调用去触发定时任务时,建议开启协程时传入一个新的ctx,避免上层有超时控制
- 仅对传输进程和 API 边界的请求范围数据使用上下文值,而不用于将可选参数传递给函数(别把本该参数传递的参数,放在context传递,这会造成方法入参不明确)
6 尾语
本文从概念、使用、原理探究,由浅入深地讲解了go的context包,同时阐述我自己的一些理解和思考。
如有不正确的地方,欢迎指正!如有更好的建议,欢迎探讨!
其他碎碎念:
我从大学开始便有写博文的习惯,一开始是因为想记录学习,因为热爱这个专业,当然也夹杂着功利的心态。那一点点成就感让我将这个习惯一直坚持到了大学毕业。
工作之后,便开始有些懈怠,总是觉得自己的时间不够用,其实这也是一个借口,就算有时间,也不一定有动力坚持。
大学时期,想法很天真,总觉得有技术就很“厉害”。工作之后,我开始怀疑,技术是否真的有用,或者说是否真的有必要投入这么多精力去钻研,再或者说——什么是技术?
抱歉,我说的很乱,但这确实是我曾经思考迷茫的问题。
因为一些缘故,我觉得不能再这样懈怠下去,不管是什么原因,我都应该拾起曾经丢掉的一些东西,于是我迸生出一个想法,就是这个博文系列,我给它起名叫作 【石上星光】。
在这个系列中我希望写一些 有体系、高质量、更纯粹的文章,希望我能坚持下去吧。

![[方案实操|数据技术]数据要素十大创新模式(1):基于区块链的多模态数据交易服务平台](https://img-blog.csdnimg.cn/img_convert/57f84f1e0a558ca34c2abfcb40cd25c2.jpeg)