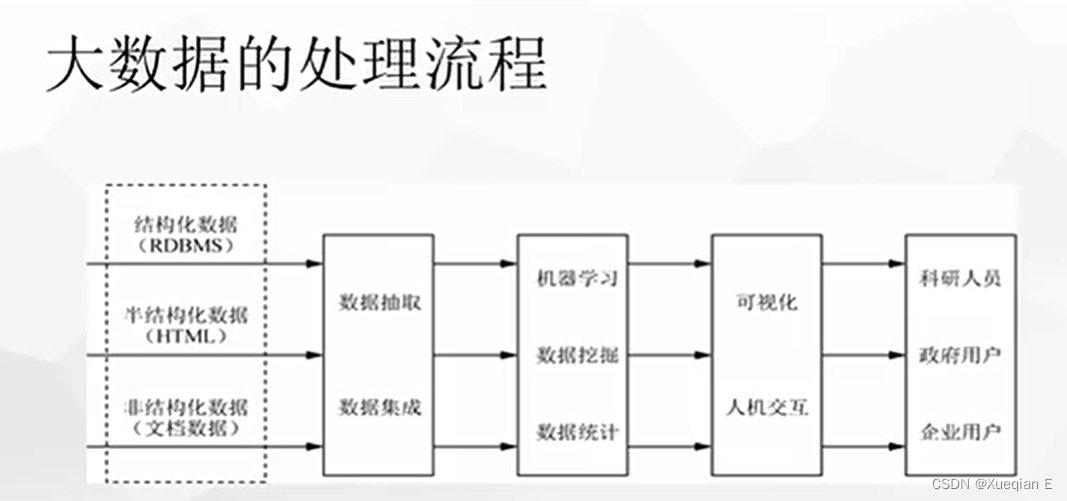
目录
2.5 调度器的实现
2.5.1 概观
2.5.2 数据结构
2.5.3 处理优先级
2.5.3.1 nice和prior
2.5.3.2 vruntime
2.5.3.3 weight权重
2.5.4 核心调度器
2.5 调度器的实现
调度器的任务:
1. 执行调度策略。
2. 执行上下文切换。
无论用户态抢占,还是内核态抢占,最终都调用schedule()函数,执行调度操作,实现进程切换。
调度分为:主动调用,周期调度
1. 主动调用:schedule()

2. 周期调度:时钟中断调用
一个进程一直while(1)不睡眠地执行任务,就是通过时钟中断,来调度其他进程的。
2.5.1 概观
CFS:完全公平调度器,调度器的一种。
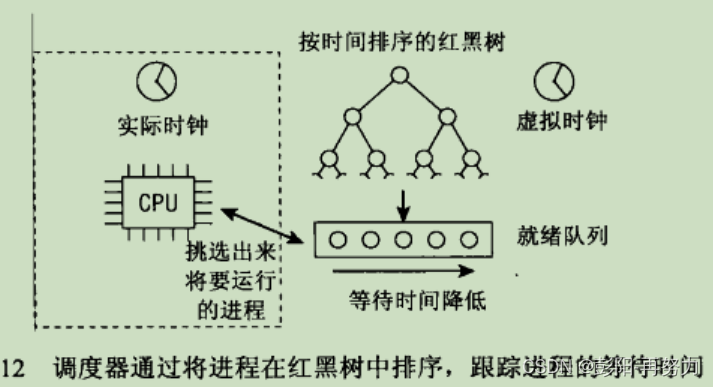
红黑树上不是task_struct,而是task_struct中的se成员,即调度实体。
调试:
#cat /proc/sched_debug 内容很多
2.5.2 数据结构
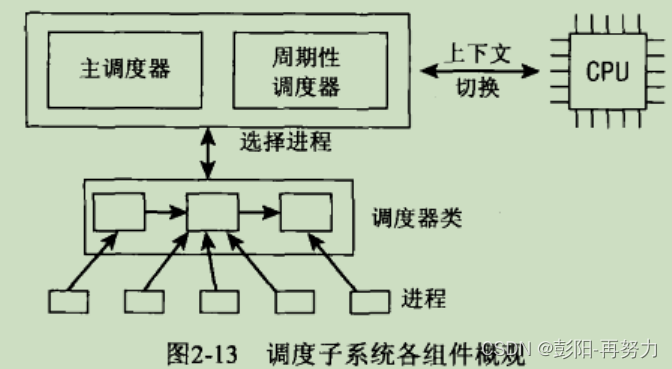
每个进程只能属于一个调度器。
常用调度器:
CFS:完全公平调度器,用于普通进程。
实时调度器:用于实时进程。
每种调度器通常都要实现:
主调度器:scheduler
周期调度器:scheduler tick
struct task_struct {
int prio; //调度器最终参考值,通常等于normal_prio(除非临时提高优先级RT_mutex)
int normal_prio; // CFS通过static_prio计算,RT通过rt_priority计算
int static_prio; //用于普通进程,范围100-139
unsigned int rt_priority; //用于实时进程,范围0-99
struct sched_class *sched_class; //所属调度器类
struct sched_entity se; //调度实体,不是指针
unsigned int policy; //SCHED_NORMAL/SCHED_IDLE /SCHED_BATCH /SCHED_RR/SCHED_FIFO
cpumask_t cpus_allowed; 该进程可在哪些CPU上运行
}
static_prio:用于普通进程,系统启动时分配,可通过nice命令修改,否则一直不变。调度器类有:
CFS:
完全公平调度器。
struct sched_class fair_sched_class 普通进程使用
RT:
实时调度器
struct sched_class rt_sched_class 实时进程使用
STOP:
struct sched_class stop_sched_class
IDLE:
struct sched_class idle_sched_class
每种调度器类有各自策略policy:
CFS:
SCHED_NORMAL:默认策略。
SCHED_IDLE:CPU空闲时才允许进程,优先级较低。如后台任务
SCHED_BATCH:批处理任务。
RT:
SCHED_RR:基于时间片轮询。
SCHED_FIFO:任务一直运行,直到它自己主动放弃CPU。
struct sched_class { //每种调度器都要实现下列函数指针
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task) (struct rq *rq,struct task_struct *prev);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);
void (*migrate_task_rq)(struct task_struct *p, int next_cpu);
void (*set_cpus_allowed)(struct task_struct *p, const struct cpumask *newmask);
void (*rq_online)(struct rq *rq);
void (*rq_offline)(struct rq *rq);
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
};enqueue_task:将进程加入到就绪队列中。
dequeue_task:从就绪队列中删除进程。
yield_task:主动放弃CPU,如CFS中会把调度实体放在红黑树最右端。
pick_next_task:根据调度策略从就绪队列中选择下一个要执行的任务。
check_preempt_curr:检查当前运行的进程是否应该被抢占,以便让更高优先级的进程运行。
select_task_rq:多核系统中,为进程选择合适CPU。
set_curr_task:更新当前正运行进程的调度信息。如修改调度策略,更新统计信息。
task_tick:系统周期性时钟中断时调用。用于更新进程的运行时间和统计信息。
struct rq { //运行队列,即就绪队列,每个CPU都有一个。
unsigned long nr_running; //该CPU就绪的进程总数,包括cfs,RT就绪队列中进程
unsigned long cpu_load[5]; //数组,1 分钟、5 分钟、15 分钟等5个平均负载数据。
struct load_weight load; //该CPU可运行进程的权重总和,用于多处理器负载均衡。
struct cfs_rq cfs; //cfs就绪队列
struct rt_rq rt; //rt就绪队列
struct task_struct *curr; //该CPU正运行的进程
u64 clock;
int cpu; //该就绪队列所属CPU
}idle、stop调度类的就绪队列管理方式不同,所以struct rq中没有idle,stop的子就绪队列。
每个CPU都有自身就绪队列,定义方法:
DECLARE_PER_CPU(struct rq, runqueues);
一个进程在同一时刻只能在一个CPU的struct rq中。
如何知道一个进程运行在哪个CPU?
task_struct -> stack得到thread_info,thread_info存储当前运行的CPU
struct thread_info {
__u32 cpu;
}相关API:
返回指定CPU的就绪队列:
struct rq *rq = cpu_rq(cpu);
返回当前CPU的就绪队列:
struct rq *rq = this_rq();
#define this_rq() (&__get_cpu_var(runqueues))
返回当前进程所在CPU的就绪队列:
task_rq(p)
返回当前CPU正运行的进程:
cpu_curr(cpu)
调度实体:
struct sched_entity { //调度实体,调度系统中代表一个进程,被task_struct包含
struct load_weight load; 负载权重
struct rb_node run_node; 用于把调度实体连接到CFS就绪队列的红黑树
unsigned int on_rq; 该调度实体是否在就绪队列上
u64 exec_start; 当前实体上次被调度执行的时间
u64 sum_exec_runtime; 当前实体总的执行时间,update_curr函数会周期更新
u64 vruntime; 虚拟运行时间,用于在红黑树中排队,决定调度先后顺序
u64 prev_sum_exec_runtime;
//sum_exec_runtime - prev_sum_exec_runtime就是进程本次在CPU上执行的时间。
struct cfs_rq *cfs_rq; 当前调度实体属于的cfs_rq
u64 nr_migrations; 迁移次数。多核中,可能因为负载均衡而迁移到其它CPU上。
};通过se的struct rb_node run_node成员,把进程挂在红黑树上,被调度器从树的左边往右依次调度。
struct task_struct {
struct sched_entity se;
}CFS调度类的yield_task_fair,enqueue_entity,entity_tick函数指针都会调用update_curr函数
update_curr函数:
用于计算和更新vruntime。
2.5.3 处理优先级
2.5.3.1 nice和prior
nice命令:
作用:更改普通进程的优先级(对应static_prior),不能用于实时进程。
nice值范围:-20到19。
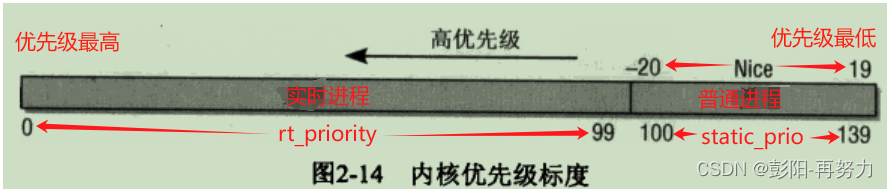
优先级范围:
0-139:0的优先级最高。
0-99:实时进程的优先级。
100-139:普通进程的优先级
static_prio = nice值+120
默认nice值为0,默认static_prio=120
struct task_struct {
int static_prio; //静态优先级,普通进程,范围100-139,对应nice值-20 到19
unsigned int rt_priority; //实时进程的优先级,范围0-99
int normal_prio; // CFS通过static_prio计算,RT通过rt_priority计算
int prio;
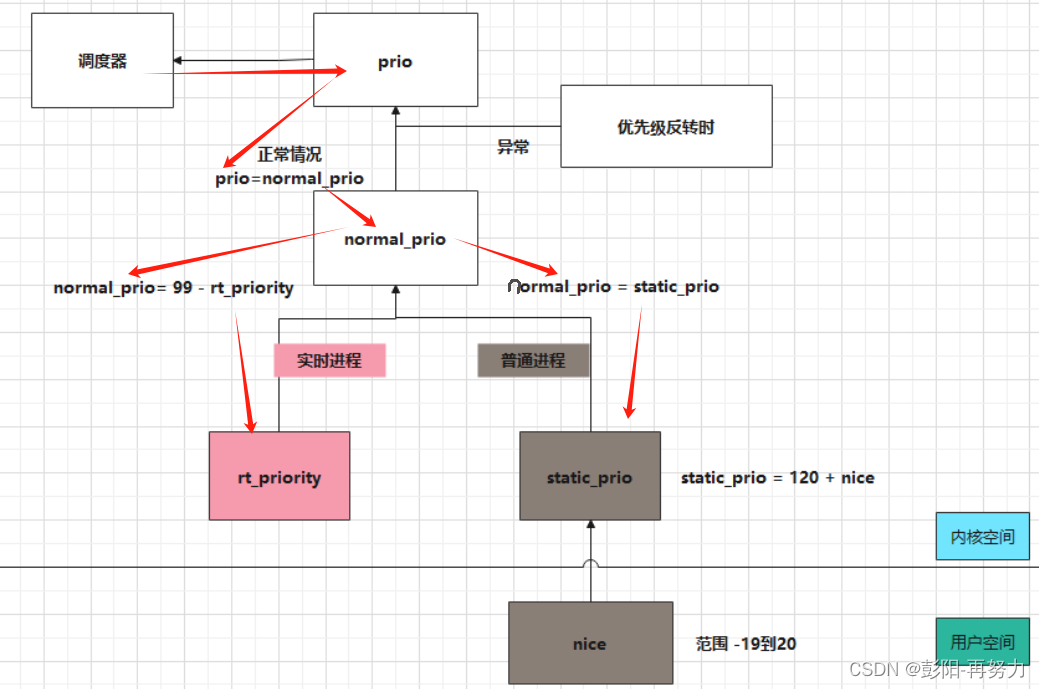
}task_struct->static_prio:
静态优先级,即普通进程的优先级。
值范围:100-139,默认值为120。
计算:static_prio = NICE_TO_PRIO(nice); //即static_prio = nice+120
修改:可通过nice命令或sched_setscheduler函数修改。
task_struct->rt_priority:
实时优先级,即实时进程的优先级。
值范围:0-99
task_struct->normal_prio:
普通优先级。
普通进程:normal_prio = static_prio
实时进程:normal_prio = 99 - rt_priority
task_struct->prio:
动态优先级。调度器最终使用。
计算:通常直接等于normal_prio。
特殊情况:
优先级反转:低优先级进程A使用RT_mutex上锁后,高优先级进程B等待该锁,此时A进程临时拥有B进程的高优先级,可让A尽早执行,尽早释放锁。此时prio就不等于normal_prio。
总结如下图:
修改普通进程的nice,可影响运行时间比例。
应用层nice -> prio - > weight -> 最终得到进程可运行时间比例。
2.5.3.2 vruntime
struct sched_entity {
u64 vruntime;
}普通进程的CFS调度器使用,而实时进程不用vruntime。
vruntime:表示进程虚拟运行时间。
进程的vruntime值作用:
决定了在CFS红黑树中的位置,树的最左端节点的vruntime最小。
CFS调度器选择红黑树最左进程调度。
为什么叫虚拟运行时间?
根据nice把实际运行时间放大缩小。
计算方法:vruntime += delta_exec * NICE_0_LOAD / weight
delta_exec: 最近一次实际执行时间。
NICE_0_LOAD:固定值。nice值为0对应的权重值
weight:当前进程的nice值对应的权重值。
下节讲如何查找nice对应权重weight。
sum_exec_runtime更新:
curr->se.sum_exec_runtime += delta_exec;
撤销CPU时,prev_exec_runtime = sum_exec_runtime
sum_exec_runtime不清0,一直递增。
CFS起初为进程分配相同的vruntime,子进程会继承父进程的vruntime。
当一个进程进入内核空间执行系统调用或发生中断时,自动将处理器的状态信息(包括通用寄存器、程序计数器PC、栈指针SP等)保存到当前进程的内核栈中的pt_regs结构体中。
因为寄存器不一样,所以不同CPU架构定义的struct pt_regs不一样。
x86架构:
struct pt_regs {
unsigned long ebx;
unsigned long ecx;
unsigned long edx;
unsigned long esi;
unsigned long edi;
unsigned long ebp;
unsigned long eax;
unsigned long xds;
unsigned long xes;
unsigned long orig_eax;
unsigned long eip;
unsigned long xcs;
unsigned long eflags;
unsigned long esp; 栈指针
unsigned long xss;
};ARM架构:
struct pt_regs {
long uregs[18];
};
#define ARM_cpsr uregs[16]
#define ARM_pc uregs[15]
#define ARM_lr uregs[14]
#define ARM_sp uregs[13]
#define ARM_ip uregs[12]
#define ARM_fp uregs[11]
#define ARM_r10 uregs[10]
#define ARM_r9 uregs[9]
#define ARM_r8 uregs[8]
#define ARM_r7 uregs[7]
#define ARM_r6 uregs[6]
#define ARM_r5 uregs[5]
#define ARM_r4 uregs[4]
#define ARM_r3 uregs[3]
#define ARM_r2 uregs[2]
#define ARM_r1 uregs[1]
#define ARM_r0 uregs[0]
#define ARM_ORIG_r0 uregs[17]2.5.3.3 weight权重
实时进程的权重比普通进程更高。
struct sched_entity { //被task_struct包含
struct load_weight load;
}
struct load_weight {
unsigned long weight; 权重,用来确定进程运行时间比例
unsigned long inv_weight; 权重倒数,方便做除法计算
};根据进程prio值计算weight和inv_weight:
void set_load_weight(struct task_struct *p)
{
int prio = p->static_prio - MAX_RT_PRIO; //MAX_RT_PRIO=100
struct load_weight *load = &p->se.load;
load->weight = prio_to_weight[prio]; 数组
load->inv_weight = prio_to_wmult[prio]; 数组
}通过prio_to_weight数组把prio转换为weight,而weight最终影响CPU运行时间比例。
static const int prio_to_weight[40] = { //将nice值转化为prio后,作为数组index。
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
}; 数组nice/prio差1,se的weight相差大约1.25倍,即CPU时间比例相差1.25倍。进程加入CPU就绪队列时,把该进程权重加入CPU就绪队列总权重中。
进程从CPU就绪队列移除时,就从CPU就绪队列总权重减去该进程权重。
const struct sched_class fair_sched_class = {
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
}
enqueue_task_fair
-> enqueue_entity
-> update_load_add(&cfs_rq->load, se->load.weight);CPU进程总权重用于多CPU间负载均衡。
参数:/proc/sys/kernel/sched_latency_ns
即调度延迟,或调度周期,就绪队列的所有进程在该周期内至少有运行一次。
单位:纳秒。
默认值:24000000,24毫秒
举例:调度延迟是24毫秒,如果有4个进程,则每个进程可执行6毫秒。
参数:/proc/sys/kernel/sched_min_granulariry_ns
即调度最小粒度,每次调度后进程至少执行的时间。
单位:纳秒。
默认值:3000000,3毫秒
参数:/proc/sys/kernel/sched_nr_latency
含义:一个调度延迟周期内可处理的最大进程数。
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
计算一个进程se在本轮调度周期应分得的真实运行时间。
计算公式:
进程的时间片= (调度周期 ×(进程se权重 / CFS运行队列中进程权重总和))
__sched_period函数:
作用:获取调度周期值,即sysctl_sched_latency = /proc/sys/kernel/sched_latency_ns
nice prior weight总结图:

2.5.4 核心调度器
核心调度器分为:
周期性调度器:scheduler_tick
主调度器:scheduler
周期性调度器:scheduler_tick
时钟周期性调度器,根据HZ自动调用。如果为了省电,可关闭该调度器。
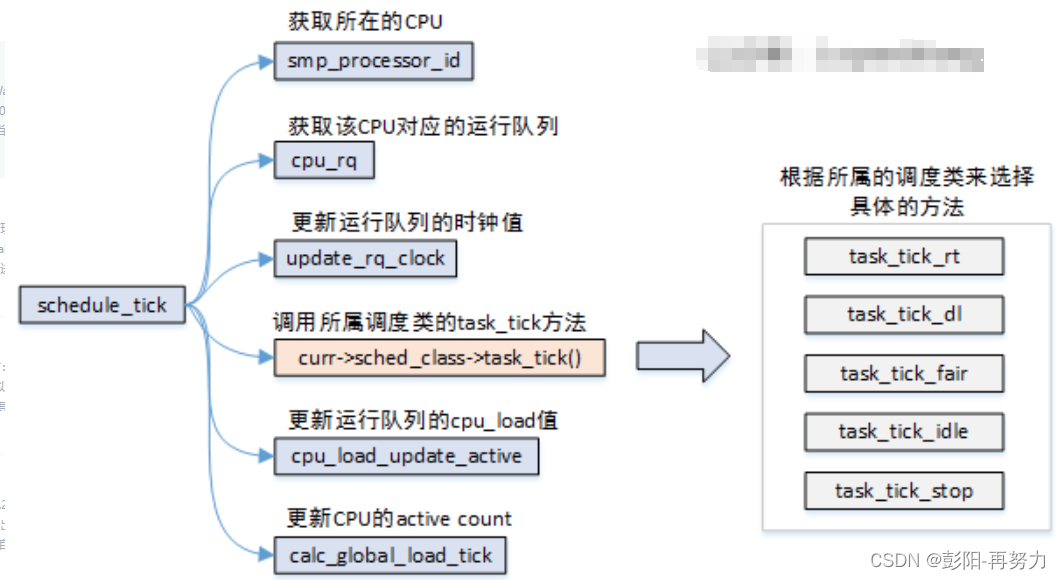
任务:
1 更新调度器clock。
2. 更新当前runqueue的clock。用于辅助计算进程上次调度运行时长
3. 执行不同调度类中的task_tick回调函数。
curr->sched_class->task_tick(rq, curr);
周期任务有:
CFS会更新进程vruntime
如果进程已执行足够时间或更高优先级的进程需运行时,当前进程应立即让出CPU,此时可给该进程thread_info中flag设置TIF_NEED_RESCHED标志位。
4. 更新该就绪队列的CPU load。
注意:周期性调度器scheduler_tick不会去主动调度其他进程,而是为当前进程设置TIF_NEED_RESCHED标志位,tick时钟中断返回时检测到设置了该标志位,则调度其他进程。
__sched前缀修饰的变量或函数:
存储在对应elf文件中.sched.text段,当coredump时可忽略.sched.text相关调用。
主调度器:scheduler
1. preempt_disable( );
关闭内核抢占
2. pick_next_task:
选择下一个进程
3. context_switch:
进程上下文切换,包含:
switch_mm : 加载新地址空间,更新页表,刷出TLB(若是内核线程,无需刷出TLB)
switch_to: 从进程thread_info中保存的信息,恢复CPU寄存器,内核栈等。
进程的寄存器内容,进入内核态时保存在它的内核栈中。
内核抢占:
即是否让出CPU,让别的进程执行。
如何判断需要抢占?
检查进程thread_info的flags成员是否设置TIF_NEED_RESCHED,若设置,则让出CPU。
scheduler和scheduler_tick函数都会根据需要设置TIF_NEED_RESCHED标志。并在下一个抢占点到来时检查该标志,调度其他进程,完成抢占操作。
抢占点:
中断处理程序的返回到内核态,如时钟中断。
系统调用结束返回用户空间。
不允许抢占:响应慢,吞吐高。
允许抢占:响应快,吞吐低。
浪费部分CPU在进程切换,所以导致吞吐低。
ARM中:
struct thread_info {
unsigned long flags;
int preempt_count;
}flags的TIF_NEED_RESCHED标志:
是否让出CPU,让其他进程抢占。
preempt_count:一个计数器。
大于 0 时:即当前进程在临界区或执行关键操作,禁止其他更高优先级的任务抢占当前线程。
等于0:表示允许抢占。
举例:
spin_lock函数将preempt_count+1
spin_unlock函数preempt_count-1
一个进程用spin_lock上锁后,不允许其他进程无法抢占当前进程。
每次内核前函数检查preempt_count值。
惰性FPU:如果没有使用扩充寄存器(如浮点寄存器),不会保存和恢复。
举例:A进程使用了浮点寄存器,切换到B进程,但B进程未使用,不替换寄存器值,节省恢复寄存器时间。