1.背景
前几天接了一个爬虫的单子,上周六已经完成这个单子,也收到了酬劳(数目还不错,哈哈哈,小喜了一下)。这个项目大概我用了两天写完了(空闲时间写的)。
2.介绍
大概要采集的数据步骤:1)输入商品名称;2)搜索供应商;3)爬取所有供应商的里所有商品数据和对应商品的交易数据;
alibaba国际淘宝API接口数据采集
链接:
https://www.alibaba.com/1.这个爬虫项目是对alibaba国际淘宝网站采集数据。
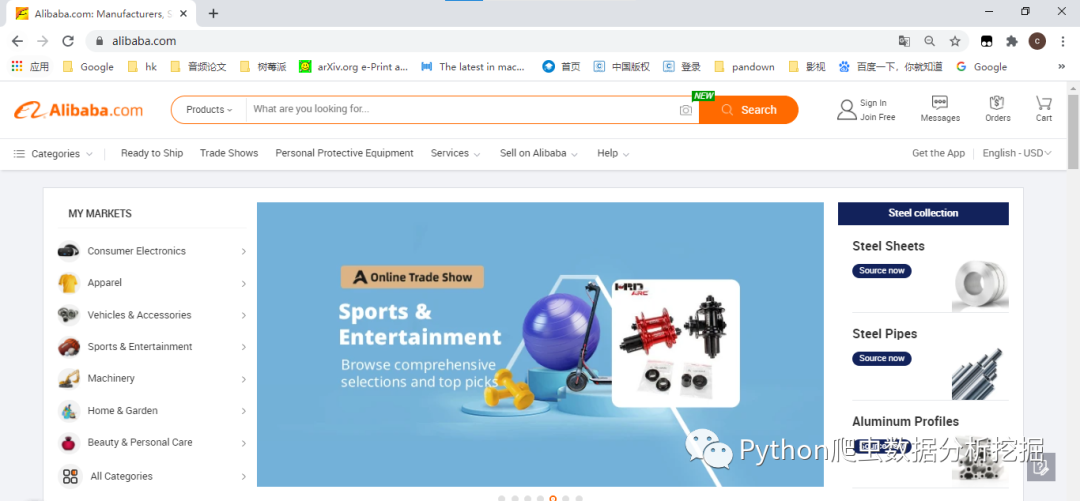
2.通过输入商品,比如:蓝牙耳机
tws+bluetooth+earphone链接
https://www.alibaba.com/trade/search?fsb=y&IndexArea=company_en&CatId=&SearchText=tws%2Bbluetooth%2Bearphone&viewtype=&tab=
3.其中某一个商家的所有商品
链接
https://bhdchina.en.alibaba.com/productlist.html?spm=a2700.shop_cp.88.30
4.对应的交易数据记录
链接
https://bhdchina.en.alibaba.com/company_profile/transaction_history.html?spm=a2700.shop_cp.13934.2.2c8f3fa0rt2lHo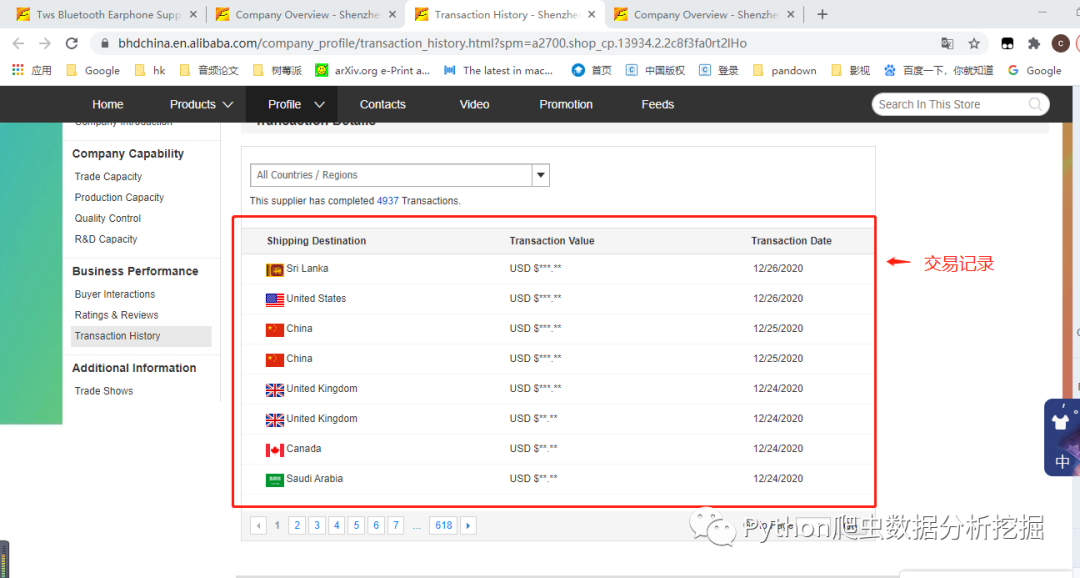
3.爬取商家信息
为什么要先爬取商家信息,因为商品数据和交易数据都是需要根据商家名称去爬取,所有先开始爬取商家信息。
导入库包
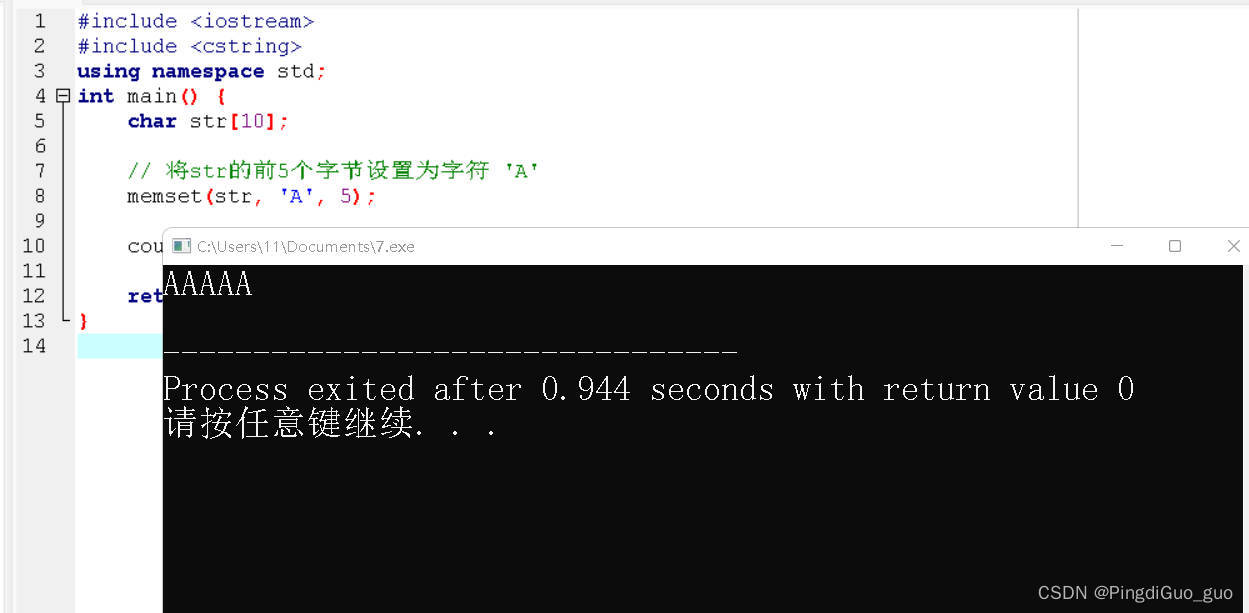
import requestsimport jsonfrom lxml import etreeimport datetimeimport xlwtimport osimport time
requests请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0'}
先看看要采集哪些字段
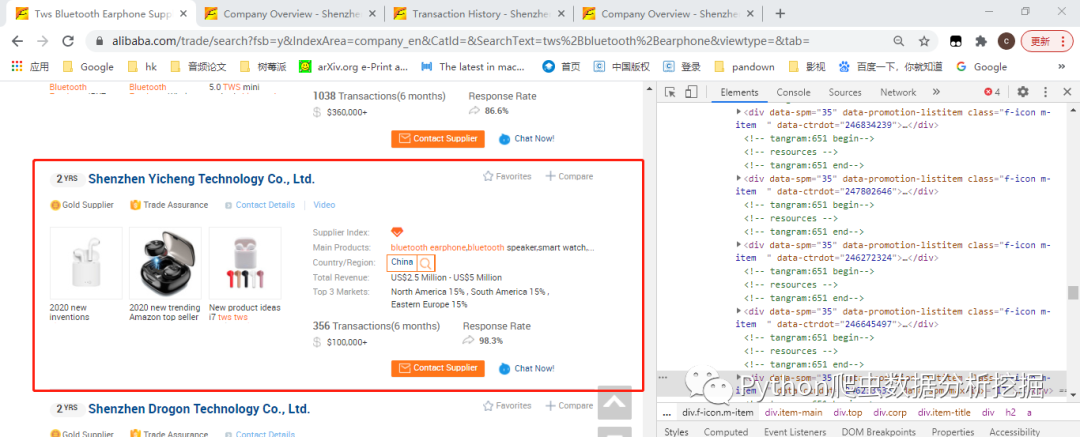
红框中的这些数据都是需要的(years,product_img,product_title,supperherf,Main Products,Country_Region,Total_Revenue,Top3_Markets,Transactions_6months,Response_Rate......)
其中supperherf是从url链接里面提取出的商家名称,后面爬取商品数据和交易数据需要用到
解析网页标签
比如名称对应的网页标签div是title ellipsis,在代码里面通过xpath可以解析到内容(这里都比较简单所以就介绍原理,小白不懂的可以看之前的文章去进行学习)
请求url数据
url = "https://www.alibaba.com/trade/search?spm=a2700.supplier-normal.16.1.7b4779adaAmpGa&page="+str(page)+"&f1=y&n=38&viewType=L&keyword="+keyword+"&indexArea=company_en"r = requests.get(url, headers=headers)r.encoding = 'utf-8's = r.text
解析字段内容
items = selector.xpath('//*[@class="f-icon m-item "]')if(len(items)>1):for item in items:try:years = item.xpath('.//*[@class="s-gold-supplier-year-icon"]/text()')print("years=" + str(years[0])+"YRS")for i in item.xpath('.//*[@class="product"]'):product_img = i.xpath('.//*[@class="img-thumb"]/@data-big')[0]product_title = i.xpath('.//a/@title')[0]product_img = str(product_img)index1 = product_img.index("imgUrl:'")index2 = product_img.index("title:")product_img = "https:"+product_img[index1 + 8:index2 - 2]print("product_img="+str(product_img))print("product_title=" + str(product_title))title = item.xpath('.//*[@class="title ellipsis"]/a/text()')print("title="+str(title[0]))supperherf = item.xpath('.//*[@class="title ellipsis"]/a/@href')[0]index1 = supperherf.index("://")index2 = supperherf.index("en.alibaba")supperherf = supperherf[index1 + 3:index2 - 1]print("supperherf=" + str(supperherf))Main_Products = item.xpath('.//*[@class="value ellipsis ph"]/@title')Main_Products = "、".join(Main_Products)print("Main Products=" + str(Main_Products))CTT = item.xpath('.//*[@class="ellipsis search"]/text()')Country_Region=CTT[0]Total_Revenue=CTT[1]Top3_Markets = CTT[2:]Top3_Markets = "、".join(Top3_Markets)print("Country_Region=" + str(Country_Region))print("Total_Revenue=" + str(Total_Revenue))print("Top3_Markets=" + str(Top3_Markets))Transactions_6months= item.xpath('.//*[@class="lab"]/b/text()')print("Transactions_6months=" + str(Transactions_6months))num = item.xpath('.//*[@class="num"]/text()')[0]print("num=" + str(num))Response_Rate = item.xpath('.//*[@class="record util-clearfix"]/li[2]/div[2]/a/text()')[0]print("Response_Rate=" + str(Response_Rate))count =count+1print("count="+str(count))print("page=" + str(page))print("------------------")
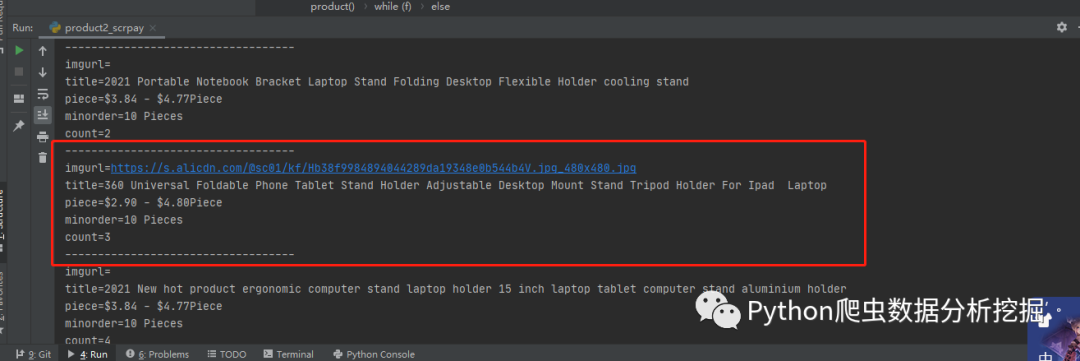
解析结果

到这里就采集完商家数据了,下面开始爬取商家商品数据
4.采集商品数据
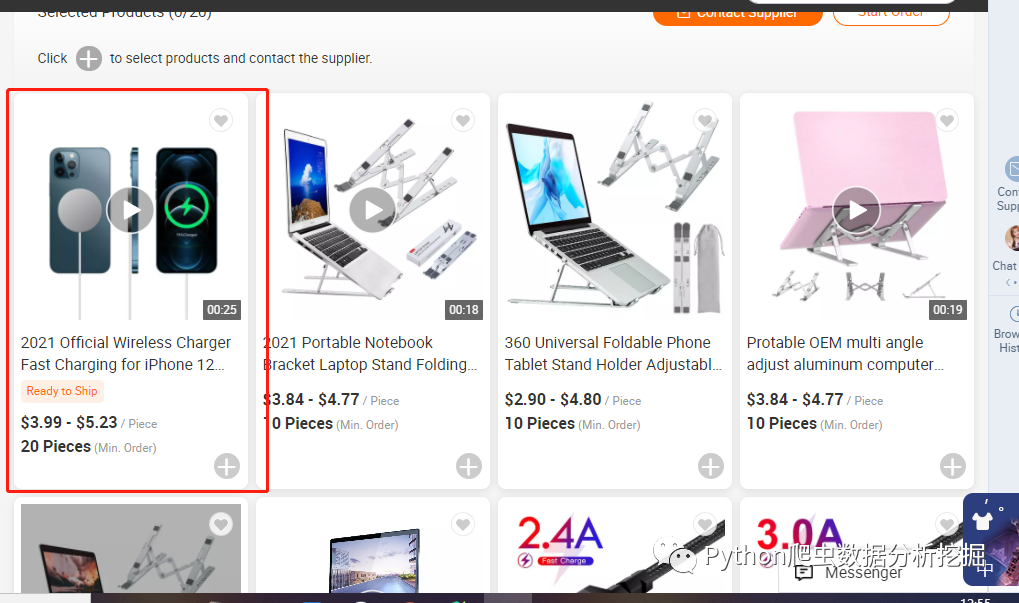
这里商品数据的内容就少了很多(商品图片imgurl,名称title,价格piece,最低价格minorder)。
解析网页标签
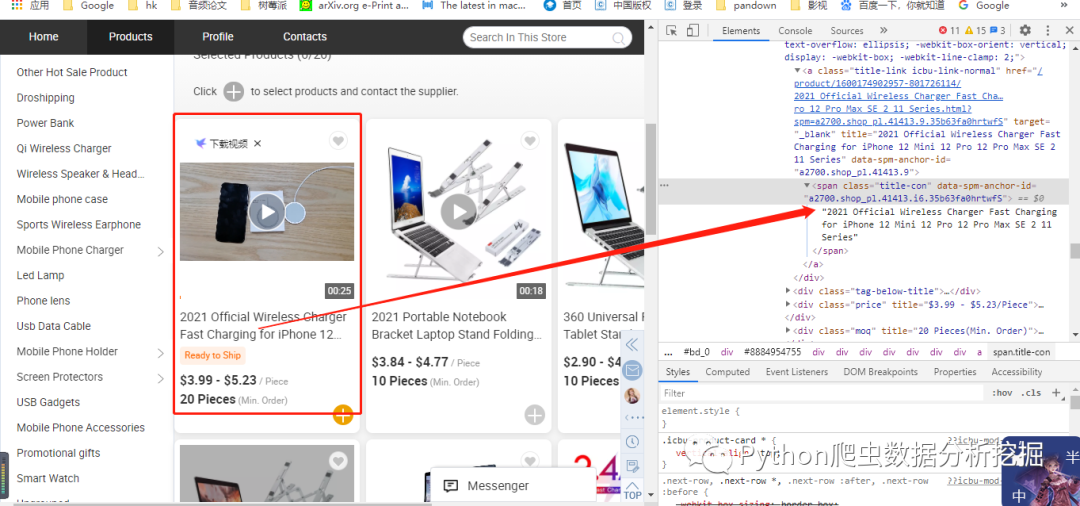
请求网页数据
url = "https://" + str(compayname) + ".en.alibaba.com/productlist-" + str(page) + ".html?spm=a2700.shop_pl.41413.41.140b44809b9ZBY&filterSimilar=true&filter=null&sortType=null"r = requests.get(url, headers=headers)r.encoding = 'utf-8's = r.text
解析标签内容
items = selector.xpath('//*[@class="icbu-product-card vertical large product-item"]')if(len(items)>1):try:for item in items:imgurl = item.xpath('.//*[@class="next-row next-row-no-padding next-row-justify-center next-row-align-center img-box"]/img/@src')title = item.xpath('.//*[@class="product-info"]/div/a/span/text()')piece = item.xpath('.//*[@class="product-info"]/div[@class="price"]/span/text()')minorder = item.xpath('.//*[@class="product-info"]/div[@class="moq"]/span/text()')print("imgurl=" + str("".join(imgurl)))print("title=" + str(title[0]))print("piece=" + str("".join(piece)))print("minorder=" + str(minorder[0]))print("count="+str(count))print("-----------------------------------")count =count+1
爬取结果