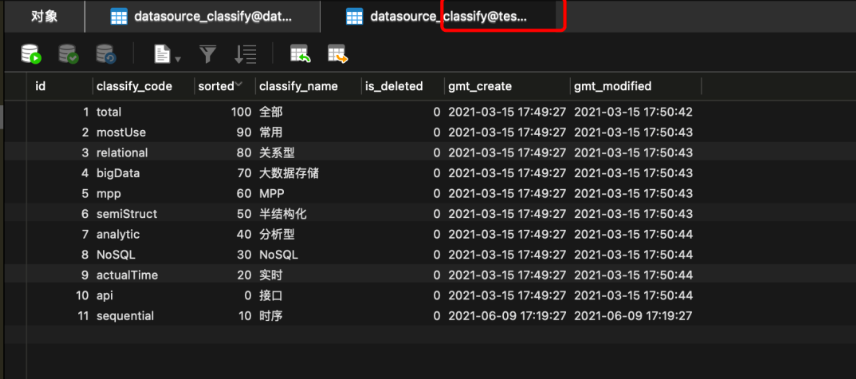
SQL实用功能手册
SQL基础复习
SQL结构化查询语言,是一种访问和处理数据库的计算机语言
- 对数据库操作
- 对表操作
- 对数据进行CRUD操作
- 操作视图、存储过程、索引
环境基础操作
- 安装mysql、启动mysql、配置环境变量
- 检查mysql版本:
mysql --version - 链接mysql :
mysql -u root -p进入环境; - 退出mysql:mysql >
exit;
-- 创建数据库
CREATE DATABASE grep_list;
-- 查看所有数据库
SHOW databases;
-- 切换数据库
USE grep_list;
-- 展示所有表
SHOW tables;
-- 删除表
DROP TABLE my_contacts;
命令大写 下划线分隔 结尾分号;字段名 使用单反引号包裹;小括号 指明 列名及数据类型等;
数据类型的选择很重要:
- Date
- DATETIME 未来
- TIMESTAMP 当下
- INT
- DEC
- VARCHAR(255)
- BLOB 方便存取 不方便操作
查看数据类型 及 某个类型:
- mysql >
help data types - mysql >
help DATE
数据类型举例:
- price 5678.12 DEC(6,2)
- 这里的两个数字表示数据库希望的浮点数格式,前者代表总位数、后者是小数点的位数;
- gender F/M CHAR(1)
- 存储预设长度为1的字符;
CRUD
NULL:
- 不可作比较,NULL代表未定义的值;创建表时,非空要求设置 NOT NULL 即可;
DEFAULT:
- 设置NOT NULL时的默认值;如,
doughnut_costDEC(3,2) NOT NULL DEFAULT 1.00
插入数据:
- values中,文本数据加单引号;
- 可以批量插入;
- 可以插入部分值,列序和值序需一致;
INSERT INTO table ( columns, column1, … ) VALUES ( ‘values1’,1,… ),( ‘values2’,2,… );
-- 省略列名时 数据需要全部插入,且与表初创时列序相同;
INSERT INTO table VALUES (’values’, …);
查询数据:
SELECT * FROM table;
SELECT field1, field2 FROM table;
WHERE子句、AND、OR综合查询;
IS NULL:
- 由于NULL不可比较,在WHERE子句中,可以使用 IS NULL 进行判断;
LIKE+通配符:
- 进行字符串匹配,比用多个OR更方便
%也是一种通配符,是实际存在于该处的字符的替身;_下划线是LIKE喜欢的第二个通配符:仅是一个未知字符的替身;可以连续使用多个;main LIKE '%juice_’ OR second LIKE '%juice%’;
IN:集合匹配
drink_name IN ('Blackthorn','Blue Moon','Oh My Gosh’);drink_name NOT IN ('Blackthorn','Blue Moon','Oh My Gosh’);
NOT:
- 注意,NOT需要放在WHERE OR 或AND的后边紧邻;
- NOT IN 是一个例外;
AND NOT second LIKE '%juice%'AND NOT amount2 BETWEEN 1 AND 2AND NOT drink_name IS NULL;
UPDATE:改变数据;
- 更新一列或多列的值,UPDATE也可以使用WHERE子句来精确地指定要更新的行;
- 在SET子句中加入多column = value组,其间以逗号分隔;
UPDATE drink_info
SET color = 'yellow'
WHERE drink_name = 'Blackthorn' AND color = 'black’;
UPDATE drink_info
SET cost = 3.5 + 1
WHERE cost = 3.5;
DELETE:删除不需要的数据;
DELETE FROM drink_info WHERE drink_name = 'Blue Moon' AND color = 'blue’;- 注意不要忘记WHERE子句,否则将会删除所有行;
- WHERE子句没有找到相符数据的时候,不会进行DELETE;
- 慎用之;
数据库设计范式
- 1NF:主键+原子性
- 2NF:没有部分函数依赖性(指非键列 不依赖于键列)
- 3NF:没有传递函数依赖性(指非键列 不依赖于其他非键列)
数据库模式:
- 1对1(放在一个表中)
- 1对N(使用外键)
- N对N(需要额外使用 连接表)
SELECT 进阶
排序,归组,对结果进行数学运算,对查询条件进行限制等
CASE检查:
- 更好的结合UPDATE语句;
- CASE中的WHEN子句和WHERE子句的用法基本相同;
- CASE检查,可以搭配 SELECT INSERT DELETE等子句;
UPDATE tablename
SET column =
CASE
WHEN column1 = someone OR column1 = sometwo
THEN newValue
WHEN column2 = someone
THEN newValue
ELSE newValue
END;
WHERE ...
ORDER BY排序:
- 先按第一列排序,结果再按第二列排序
- 反转排序结果 DESC:默认 ORDER BY的列都是按照升序排列(ASC),要降序排列的话,就在 列名 后加上DESC;
SELECT …
FROM …
WHERE …
ORDER BY columnName1,columnName2;
SUM加总:
SELECT name, SUM(cost)
FROM table
WHERE name = 'xxxx';
-- 对加总的结果进行排序:
SELECT name, SUM(cost)
FROM table
GROUP BY name
ORDER BY SUM(cost) DESC;
GROUP BY:数据归组;
- AVG函数求平均值;
- MAX、MIN函数求最大值和最小值;
- COUNT对记录计数;
DISTINCT:去重(这是个关键字,放在所有查询字段的开头)
SELECT DISTINCT sale_date
FROM table
WHERE name = ‘xx’
ORDER BY sale_date DESC;
-- 注意,SELECT DISTINCT col1,col2; mysql会将两列都去重,因此DISTINCT一般用于查询不重复记录的条数;
SELECT COUNT(DISTINCT sale_date)
FROM table
WHERE name = ‘xx’;
LIMIT限制查询结果的数量:
- 常用形式:
LIMIT 2返回2条数据LIMIT 0,2从第0个位置开始返回4条数据LIMIT 2,1返回第3条数据 (默认从0开始,只有字符串下标特殊,从1开始)
SELECT
FROM
WHERE
ORDER BY
LIMIT 2;
联接JOIN
联接都会生成一张临时的中间表;
交叉连接(cross join):笛卡尔积
- 返回每个可能行
- CROSS JOIN可以省略不写,只用逗号代替;
mysql> SELECT t.toy , b.boy
-> FROM
-> toys AS t
-> CROSS JOIN
-> boys AS b;
内连接(INNER JOIN):
- 返回两张表中相符记录
- 只有联接记录符合条件时才会返回列;
- ON也可以改用关键字WHERE;
mysql> SELECT b.boy,t.toy
-> FROM
-> boys AS b
-> INNER JOIN
-> toys AS t
-> ON b.toy_id = t.toy_id;
值得注意的是:
- ON和WHERE并不等价,尤其在LEFT JOIN和RIGHT JOIN中区别明显;
- 以左联接为例,ON是在生成临时表时使用条件,但不管ON中条件是否为真,都会返回左边表中的记录;
- WHERE则是在临时表生成之后,在对临时表进行条件过滤,此时已经没有了联接的概念,条件为假的全部过滤掉;
外联接
- 返回某张表的所有行,并且有来自另一张表的条件相符的数据;联接表的顺序尤为重要;
- 外联接一定会提供数据行,无论该行能否在另一个表中找到相匹配的行;
- 出现NULL表示没有匹配的行,如下查询的NULL表示July没有工作;
mysql> SELECT mc.last_name,mc.first_name,jc.title
-> FROM my_contacts mc LEFT OUTER JOIN job_current jc
-> ON mc.contact_id = jc.contact_id;
-- +-----------+------------+-----------+
-- | last_name | first_name | title |
-- +-----------+------------+-----------+
-- | Joy | HQ | EngineerM |
-- | Mary | DM | EngineerS |
-- | July | FM | NULL |
联合UNION
- 用来取得多张表的查询结果;
- UNION可以根据在SELECT中指定的列,把两张或更多张表的查询结果合并至一个表中;
- UNION只接受一个ORDER BY且位于语句末端,这是因为UNION已经把多个SELECT语句的查询结果串起来并进行了分组;(默认进行了GROUP BY);
- 看全部的记录,可以使用UNION ALL运算符,它会返回每个相符的记录,可以重复
mysql> SELECT title FROM job_current
-> UNION
-> SELECT title FROM job_desired
-> UNION
-> SELECT title FROM job_list;
从联合创建表:
mysql> CREATE TABLE job_titles AS
-> SELECT title FROM job_current
-> UNION
-> SELECT title FROM job_desired
-> UNION
-> SELECT title FROM job_list
子查询:
有了联接确实很好用,我们可以将多张关联的表联接成一张临时表,然后设置条件,从中查询需要的记录;但有时要问数据库的数据不只一个,或者把甲查询的结果作为乙查询的输入,这时就需要子查询了;
IN关键字:(IN、NOT IN)
SELECT mc.last_name,mc.first_name,mc.phone,jd.title
-> FROM my_contacts mc NATURAL JOIN job_desired jd
-> WHERE jd.title IN ('EngineerM','EngineerS');
结合子查询:
SELECT mc.last_name,mc.first_name,mc.phone,jd.title
-> FROM my_contacts mc NATURAL JOIN job_desired jd
-> WHERE jd.title IN (
-> SELECT title
-> FROM job_list
-> GROUP BY title
-> ORDER BY title
-> );
关联子查询
- 如果子查询可以独立运行且不会引用外层查询的任何结果,即称为非关联子查询;软件先处理内层查询,查询结果再用于外层查询的WHERE子句,但是内层查询完全不需依赖外层查询的值,它本身就是一个可以完全独立运行的查询;
- 关联子查询是指内层查询的解析需要依赖外层查询的结果;
-- 查询my_contacts表中有1项兴趣的人
select mc.last_name, mc.first_name
from my_contacts mc
where 1 = (
select count(*)
FROM contact_intrest
-- 此处子查询 依赖外层查询的结果
where contant_id = mc.contact_id
);
EXISTS与NOT EXISTS:
- 存在记录,不存在记录的意思;
- 上述示例也可以使用EXISTS关键字,写做如下关联子查询;
select mc.last_name, mc.first_name
from my_contacts mc
WHERE exists (
select 1 from contact_intrest where contant_id = mc.contact_id
);
把自联接变成子查询:
mysql> SELECT cb1.name clown ,cb2.name boss
-> FROM clown_boss cb1
-> INNER JOIN clown_boss cb2
-> ON cb1.boss_id = cb2.id;
--
mysql> SELECT cb1.name,(
-> SELECT name FROM clown_boss
-> WHERE cb1.boss_id = id
-> ) boss
-> FROM clown_boss cb1;
SQL实用功能
ORDER BY
用于对结果集进行排序
select [列] from [表]
order by [列] [DESC]|[ASC];
TOP/LIMIT
用于规定要返回的记录数
- startIndex 数据查询的起始位置
- size 要返回的数据行数
select top [number] [列] from [表]; -- sql server
select [列] from [表]
limit [startIndex], [size]; -- mysql
select [列] from [表]
where rownum <= [number];
LIKE
用在where子句中,搜索列的指定模式,如匹配字符串
- pattern 中可使用通配符加条件
- 常用通配符:
%代表0或多个字符_代表一个字符
select [列] from [表]
where [列] LIKE [pattern];
JOIN
基于表的共同字段,将两个及以上的表结合起来
- inner join 返回符合条件的数据行(连接结果 n*n)
- left join 返回符合条件的数据行 以及 左表不符合条件的行(连接结果 n*n + m)不符合条件的行的右表列会被置null;
- right join 返回符合条件的数据行 以及 右表不符合条件的行(连接结果 n*n + m)不符合条件的行的左表列会被置null;
- full join 全连接(外连接)结合了left join和right join的结果(MySQL不支持);
select [列]
from [表1]
inner join [表2]
on [表1.列] = [表2.列];
常用函数
-- 平均数
select AVG([列]) from [表];
-- 数量统计
select COUNT(*) from [表];
select COUNT(DISTINCT [列]) from [表];
-- 转换大小写
select UCASE([列]) from [表];
select LCASE([列]) from [表];
-- 文本长度
select LEN([列]) from [表];
-- 小数舍入
select ROUND([列], [小数位]) from [表];
-- 当前系统日期和时间
select NOW() from [表];
-- 获取系统当前时间
SELECT SYSDATETIME()
SELECT SYSDATETIMEOFFSET()
SELECT SYSUTCDATETIME()
SELECT CURRENT_TIMESTAMP
SELECT GETDATE()
SELECT GETUTCDATE() -- 带UTC的系统时间是世界标准时间,其他为当前时区时间
Date 和 Time 样式 CONVERT
用不同的格式显示日期/时间数据:
- data_type(length) 规定目标数据类型(带有可选的长度)
- data_to_be_converted 含有需要转换的值
- style 规定日期/时间的输出格式
CONVERT(data_type(length),data_to_be_converted,style)
| Style ID | Style 格式 |
|---|---|
| 100 或者 0 | mon dd yyyy hh:miAM (或者 PM) |
| 101 | mm/dd/yy |
| 102 | yy.mm.dd |
| 103 | dd/mm/yy |
| 104 | dd.mm.yy |
| 105 | dd-mm-yy |
| 106 | dd mon yy |
| 107 | Mon dd, yy |
| 108 | hh:mm:ss |
| 109 或者 9 | mon dd yyyy hh:mi:ss:mmmAM(或者 PM) |
| 110 | mm-dd-yy |
| 111 | yy/mm/dd |
| 112 | yymmdd |
| 113 或者 13 | dd mon yyyy hh:mm:ss:mmm(24h) |
| 114 | hh:mi:ss:mmm(24h) |
| 120 或者 20 | yyyy-mm-dd hh:mi:ss(24h) |
| 121 或者 21 | yyyy-mm-dd hh:mi:ss.mmm(24h) |
| 126 | yyyy-mm-ddThh:mm:ss.mmm(没有空格) |
| 130 | dd mon yyyy hh:mi:ss:mmmAM |
| 131 | dd/mm/yy hh:mi:ss:mmmAM |
SELECT CONVERT(varchar(100), GETDATE(), 8)
--结果:21:33:18
SELECT CONVERT(varchar(100), GETDATE(), 20)
--结果:2020-12-07 21:33:18
SELECT CONVERT(varchar(100), GETDATE(), 23)
--结果:2020-12-07
SELECT CONVERT(varchar(100), GETDATE(), 24)
--结果:21:33:18
SELECT CONVERT(varchar(100), GETDATE(), 108)
--结果:21:33:18
SELECT CONVERT(varchar(100), GETDATE(), 111)
--结果:2020/12/07
SELECT CONVERT(varchar(100), GETDATE(), 120)
--结果:2020-12-07 21:33:18
进阶日期操作函数
DATEADD
DATEADD (datepart , number , date )
| datepart | 缩写 |
|---|---|
| 年 | yy, yyyy |
| 季度 | qq, q |
| 月 | mm, m |
| 年中的日 | dy, y |
| 日 | dd, d |
| 周 | wk, ww |
| 星期 | dw, w |
| 小时 | hh |
| 分钟 | mi, n |
| 秒 | ss, s |
| 毫秒 | ms |
| 微妙 | mcs |
| 纳秒 | ns |
-- 查询上个月的今天,下个月的今天
SELECT DATEADD(month, -1, '20211208');
SELECT DATEADD(month, 1, '20211208');
DATEDIFF
时间跨度
DATEDIFF ( datepart , startdate , enddate )
-- 计算去年第一天到今天之间有多少天
SELECT DATEDIFF(DAY,'20200101','20211208')
DATEFROMPARTS
此函数返回映射到指定年、月、日值的 date 值
DATEFROMPARTS ( year, month, day )
SELECT DATEFROMPARTS ( 2021, 12, 8 ) AS Result;
-- 2021-12-08
DATENAME
DATENAME ( datepart , date )
SELECT DATENAME(year, getdate()) 'Year'
,DATENAME(month, getdate()) 'Month'
,DATENAME(day, getdate()) 'Day'
,DATENAME(weekday,getdate()) 'Weekday';
-- 2021 12 8 星期三
DATEPART
DATEPART ( datepart , date )
SELECT DATEPART(year, getdate()) 'Year'
,DATEPART(month, getdate()) 'Month'
,DATEPART(day, getdate()) 'Day'
,DATEPART(weekday,getdate()) 'Weekday';
-- 2021 12 8 4
ISDATE
如果表达式是有效的 date、time、或 datetime 值,则返回 1;否则返回 0
IF ISDATE('2021-12-08') = 1
SELECT '合法日期' Result
ELSE
SELECT '不合法日期' Result;
组合使用
-- 本月第一天
SELECT DATEADD(mm,DATEDIFF(mm,0,getdate()),0)
--2021-12-01 00:00:00.000
-- 本周星期一
SELECT DATEADD(wk,DATEDIFF(wk,0,getdate()),0)
--2021-12-06 00:00:00.000
-- 今年第一天
SELECT DATEADD(yy,DATEDIFF(yy,0,getdate()),0)
--2021-01-01 00:00:00.000
-- 下个季度第一天
SELECT DATEADD(qq,DATEDIFF(qq,-1,getdate()),0)
--2021-01-01 00:00:00.000
-- 上个月最后一天
SELECT DATEADD(dd,-DAY(getdate()),getdate())
--2021-11-30 20:14:21.850
-- 今年最后一天
SELECT DATEADD(year,DATEDIFF(year,0,DATEADD(year,1,getdate())),-1)
--2021-12-31 00:00:00.000
-- 去年同一天
SELECT DATEADD(YEAR,-1,GETDATE())
--2020-12-08 20:19:05.987
进阶字符串操作函数
CHARINDEX
在第二个字符表达式中搜索一个字符表达式,这将返回第一个表达式(如果发现存在)的开始位置
- 这是一个常用的字符搜索函数,起始下标是1,不是0
- 如果加了起始下标,会从忽略起始下标前面的字符,往后面搜索
CHARINDEX ( expressionToFind , expressionToSearch [ , start_location ] )
SELECT CHARINDEX('数据','SQL数据库开发SQL数据库开发');
-- 4
SELECT CHARINDEX('数据','SQL数据库开发SQL数据库开发',6);
-- 12
PATINDEX
返回模式在指定表达式中第一次出现的起始位置;如果在所有有效的文本和字符数据类型中都找不到该模式,则返回0;
与CHARINDEX类似;PATINDEX 的起始位置为 1;
PATINDEX ( '%pattern%' , expression )
SELECT PATINDEX('%数据库%', 'SQL数据库开发');
SELECT PATINDEX('%数_库%', 'SQL数据库开发');
CONCAT_WS
串联或联接的两个或更多字符串值生成的字符串,用第一个函数参数中指定的分隔符分隔连接的字符串值;
CONCAT_WS ( separator, argument1, argument2 [, argumentN]... )
SELECT CONCAT_WS('-','a','b',NULL,'c');
-- a-b-c
CONCAT_WS 会忽略列中的 NULL 值。 用 ISNULL 函数包装可以为 null 的列,并提供默认值; (
isnull( check_expression , replacement_value ))
STRING_AGG
- STRING_AGG 是一个聚合函数,用于提取行中的所有表达式,并将这些表达式串联成一个字符串;
- null 值会被忽略,且不会添加相应的分隔符。 若要为 null 值返回占位符,请使用 ISNULL 函数;
STRING_AGG ( expression, separator ) [ <order_clause> ]
WITH t AS (
SELECT '张三' Name,'语文' Course,89 Score
UNION ALL
SELECT '张三' ,'数学' ,91
UNION ALL
SELECT '李四' ,'语文' ,78
UNION ALL
SELECT '李四' ,'数学' ,96
)
SELECT Name,
STRING_AGG(Course,',') Course ,
STRING_AGG(Score,',') Score
FROM t
GROUP BY Name
-- 李四 语文,数学 78,96
-- 张三 数学,语文 91,89
STRING_SPLIT
- 根据指定的分隔符将字符串拆分为子字符串行
- STRING_SPLIT 输出其行包含子字符串的单列表。 输出列的名称为“value”
输出行可以按任意顺序排列。 顺序不保证与输入字符串中的子字符串顺序匹配。 可以通过在 SELECT 语句中使用 ORDER BY 子句覆盖最终排序顺序 (ORDER BY value);
当输入字符串包含两个或多个连续出现的分隔符字符时,将出现长度为零的空子字符串。 空子字符串的处理方式与普通子字符串相同。 可以通过使用 WHERE 子句筛选出包含空的子字符串的任何行 (WHERE value <> ‘’)。 如果输入字符串为 NULL,则 STRING_SPLIT 表值函数返回一个空表;
STRING_SPLIT ( string , separator )
SELECT Value FROM STRING_SPLIT('SQL-数据库-开发', '-');
-- Value
-- SQL
-- 数据库
-- 开发
WITH t AS (
SELECT 1 ID,'张三' Name,'足球,篮球,羽毛球' Hobby
UNION ALL
SELECT 2 ,'李四','足球,游泳,爬山'
)
SELECT ID, Name, Value
FROM t
CROSS APPLY STRING_SPLIT(Hobby, ',');
-- ID Name Value
-- 1 张三 足球
-- 1 张三 篮球
-- 1 张三 羽毛球
-- 2 李四 足球
-- 2 李四 游泳
-- 2 李四 爬山
返回的列不再是Hobby,而是Value,必须写成Value,否则得不到想要的结果;
STUFF
将字符串插入到另一个字符串中:
- 从第一个字符串的开始位置删除指定长度的字符;
- 然后将第二个字符串插入到第一个字符串的开始位置;
STUFF ( character_expression , start , length , replaceWith_expression )
SELECT STUFF('abcdef', 2, 3, 'ijklmn');
-- aijklmnef
REPLICATE
以指定的次数重复字符串值;
REPLICATE( string_expression ,integer_expression )
SELECT '2'+REPLICATE ('3',5)
-- 233333
FORMAT
返回使用指定格式和可选区域性格式化的值
使用 FORMAT 函数将日期/时间和数字值格式化为识别区域设置的字符串。 对于一般的数据类型转换,请使用 CAST 或 CONVERT;
SELECT FORMAT( GETDATE(), 'dd/MM/yyyy', 'zh-cn' ) AS '自定义日期'
,FORMAT(123456789,'###-##-####') AS '自定义数字';
SUBSTRING、REPLACE
字符串截取和替换
-- 字符串下标从1开始 区间[2,4]为闭区间
SELECT REPLACE('abcdefg',SUBSTRING('abcdefg',2,4),'**')
SELECT REPLACE('13512345678',SUBSTRING('13512345678',4,11),'********')
SELECT REPLACE('12345678@qq.com','1234567','******')
REVERSE
返回字符串值的逆序
SELECT REVERSE('SQL数据库开发')
查询一个表内相同纪录 HAVING
select * from HR.Employees
where title in (
select title from HR.Employees
group by title
having count(1)>1);
select * from HR.Employees
where title+titleofcourtesy in
(select title+titleofcourtesy
from HR.Employees
group by title,titleofcourtesy
having count(1)>1);
把多行SQL数据变成一条多列数据(分组统计数据)
SELECT
id,
name,
SUM(CASE WHEN quarter=1 THEN number ELSE 0 END) '一季度',
SUM(CASE WHEN quarter=2 THEN number ELSE 0 END) '二季度',
SUM(CASE WHEN quarter=3 THEN number ELSE 0 END) '三季度',
SUM(CASE WHEN quarter=4 THEN number ELSE 0 END) '四季度'
FROM test
GROUP BY id,name;
表数据复制到新表
-
语法1:
Insert INTO table(field1,field2,...) values(value1,value2,...) -
语法2:
Insert into Table2(field1,field2,...) select value1,value2,... from Table1
要求目标表Table2必须存在,由于目标表Table2已经存在,所以我们除了插入源表Table1的字段外,还可以插入常量;
- 语法3:
SELECT vale1, value2 into Table2 from Table1
要求目标表Table2不存在,因为在插入时会自动创建表Table2,并将Table1中指定字段数据复制到Table2中;
- 语法4:使用导入导出功能进行全表复制;
如果是使用【编写查询以指定要传输的数据】,那么在大数据表的复制就会有问题,因为复制到一定程度就不再动了,内存不够用,它也没有写入到表中,而使用上面3种语法直接执行是会马上刷新到数据库表中的;
mysql> CREATE TABLE drink_des
-> (
-> id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> drink_des VARCHAR(100),
-> meter INT
-> );
mysql> INSERT INTO drink_des
-> (drink_des,meter)
-> SELECT drink_des,meter FROM drink_list;
mysql> CREATE TABLE drink_des
-> (
-> id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> drink_des VARCHAR(100),
-> meter INT
-> )AS
-> SELECT drink_des,meter FROM drink_list;
AS:
- AS能把SELECT的查询结果填入新表中;
- 如果新表指定的列名与AS后的SELECT的查询列不一致/不指定,则会新创建相应的查询列名的列;
- 除此之外,AS在设置别名时也有用;
列别名AS:
- 在查询中首次使用原始列名的地方后接AS并设定要采用的别名;
SELECT saler AS si_er, sale_date AS si_date FROM drink_list
WHERE NOT saler IS NULL
ORDER BY si_date;
注意:这里的WHERE子句并不能直接使用列的别名,这是由于语句的执行顺序决定的,WHERE执行时,别名尚未生效;
表别名AS:
- 在查询首次出现表名的地方后接AS并设定别名;
- 也可以省略AS,只要别名紧跟在原始表名或列名后,就能直接设定别名;
对接服务的数据库表 如何删除大量数据?
1.关闭所有修改该表的数据服务(定时任务等);
2.查看该表的创建 sql,修改表名为“表名_copy”,重新执行生成新表;
3.执行sql向新表导入数据:
INSERT INTO table_copy SELECT
t.*
FROM
TABLE t
LEFT JOIN table_copy tc ON t.id = tc.id
WHERE
t.condition_id > 10001
AND tc.id IS NULL
LIMIT 100000;
- 左外联接
原表和新表,使用id关联; - 对
原表进行条件过滤,condition_id一般使用主键 id(自增特点)筛选出指定之间之后的数据; - 对
新表的过滤条件为 id为空,表示原表存在但新表不存在的数据; - 使用limit限制处理数量,控制在10w,保证分析型数据库同步数据的延时不会太高;(如果有必要的话)
4.执行多次直到原表中符合条件的数据全部插入到新表;
5.查看新表数据无误后,直接删除原表,然后修改 新表的表名为 原表的表名(去掉copy);
6.恢复所有该表关联的数据服务(定时任务等);
利用带关联子查询Update语句更新数据
--方法1:
Update Table1
set c = (select c from Table2 where a = Table1.a)
where c is null
--方法2:
update A
set newqiantity=B.qiantity
from A,B
where A.bnum=B.bnum
--方法3:
update
(select A.bnum ,A.newqiantity,B.qiantity from A
left join B on A.bnum=B.bnum) AS C
set C.newqiantity = C.qiantity
where C.bnum ='001'
Navicat 实用功能
- 安装Navicat:Navicat Premium;
- 连接MySQL数据库:输入主机名或IP地址,账号密码即可;
- 创建数据库
数据传输:
- 工具-》数据传输,使用‘连接’方式可以将待传输对象传输到另一个数据库,使用‘文件’的方式,则可以导出整个数据库中的对象到文件;
导出表结构:
- 右键数据库(也可以是表)‘转储SQL文件’,选择‘仅结构’;
生成数据字典:
- 右键数据库‘打印数据库’,可以将数据库中的表结构打印成PDF文件,作为一份完备的数据字典说明(内容中P代表主键,index表示索引);
生成E-R模型:
- 右键数据库‘逆向数据库到模式’,可以将当前数据库中创建的所有表,以E-R图的模型清楚的展示表之间的关联关系(主外键,表结构,关联关系);
- 还支持模型转换和模型导出:
模型转换:
- 模型转换即将该模型转换成其他数据库的模型,E-R图模式下的菜单列表,选择‘文件’-》‘模型转换’;
模型导出:
- 对转换后的模型,可以在E-R图模式下的菜单列表,选择‘工具’-》‘导出SQL’,即可得到建库代码;
模型E-R图打印:
- 对转换后的模型,可以在E-R图模式下的菜单列表,选择‘文件’-》‘打印’,即可输出图示;
索引
索引的名称,通常按命名规范以index或idx开头
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J0Op5JoR-1668753236373)(attachment:image.png)]

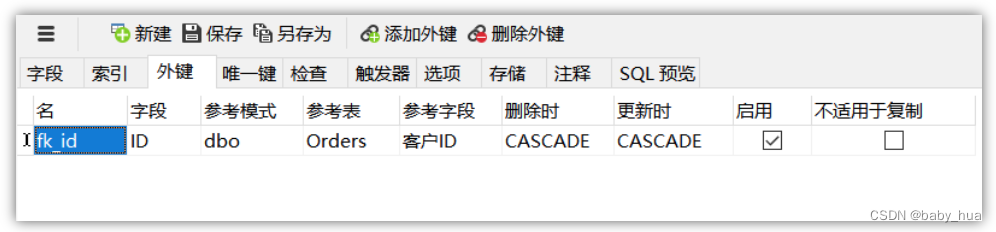
外键
外键名称,通常以fk开头
- 名:外键名称,通常以fk开头
- 字段:用来设置外键的字段
- 参考表:与之相关联的表
- 参考字段:与之相关联表中的字段
- 删除时:是否级联删除
- 更新时:是否级联更新
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w1KRPYry-1668753236375)(attachment:image.png)]
唯一键
区别于主键,唯一键具有唯一性
- 1.主键不允许空值,唯一索引允许空值
- 2.主键只允许一个,唯一索引允许多个
- 3.主键产生唯一的聚集索引,唯一索引产生唯一的非聚集索引
导入向导
右键数据库(也可以是表)‘导入向导’,引导用户导入数据到数据库对应的表:
- 在导入向导中选择要导入的文件类型;
- 目标表可以是已存在的表,也可以新建表;
- 配置源表和目标表之间的字段对应关系;
- 选择一个导入模式(直接添加,还是删除现有全部记录后重新导入等);
导出向导
右键数据库(也可以是表)‘导出向导’,将数据库里的数据进行导出:
- 选择导出文件类型;
- 选择需要导出的表;
- 选择需要导出的列;
- 附加选项:导出包含标题,遇到导出错误继续等;
视图、函数、存储过程
函数和存储过程共用模板;区别在于函数有返回值;
备份、还原、历史日志
选中已有备份,即可还原;‘工具’-》‘历史日志’