前言
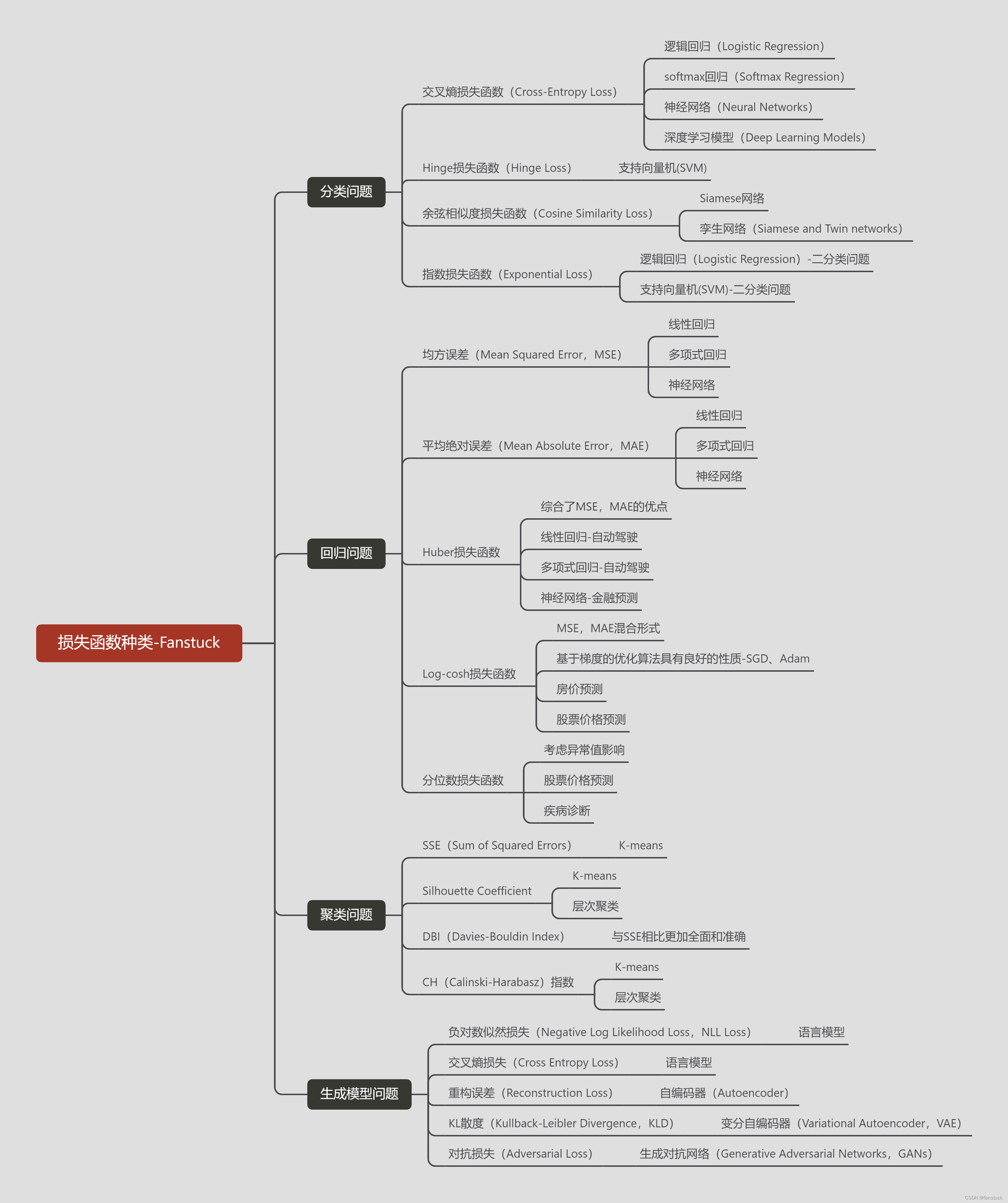
损失函数无疑是机器学习和深度学习效果验证的核心检验功能,用于评估模型预测值与实际值之间的差异。我们学习机器学习和深度学习或多或少都接触到了损失函数,但是我们缺少细致的对损失函数进行分类,或者系统的学习损失函数在不同的算法和任务中的不同的应用。因此有必要对整个损失函数体系有个比较全面的认识,方便以后我们遇到各类功能不同的损失函数有个清楚的认知,而且一般面试以及论文写作基本都会对这方面的知识涉及的非常深入。故本篇文章将结合实际Python代码实现损失函数功能,以及对整个损失函数体系进行深入了解。
博主专注建模四年,参与过大大小小数十来次数学建模,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。此专栏的目的就是为了让零基础快速使用各类数学模型、机器学习和深度学习以及代码,每一篇文章都包含实战项目以及可运行代码。博主紧跟各类数模比赛,每场数模竞赛博主都会将最新的思路和代码写进此专栏以及详细思路和完全代码。若你渴望突破数学建模的瓶颈,不要错过笔者精心打造的专栏。愿你能在这里找到你所需要的灵感与技巧,为你的建模之路添砖加瓦。
一、回归问题损失函数概述
回归问题的损失函数在机器学习和统计建模中起到了至关重要的作用。它们用于衡量模型的预测值与真实值之间的差异,从而指导模型的训练和优化过程。回归问题损失函数的功能和具体作用为:
衡量模型性能: 损失函数用于量化模型在训练数据上的性能。它提供了一个具体的数值,反映了模型对训练数据的拟合程度。
指导参数优化: 模型的目标是通过调整参数来最小化损失函数的值。优化算法(如梯度下降)使用损失函数的梯度信息来更新模型参数,使其逐步逼近最优值。
处理过拟合和欠拟合: 损失函数可以帮助识别模型是否存在过拟合或欠拟合问题。如果损失函数在训练集上较低但在验证集上较高,可能表示模型过拟合。
权衡精度和偏差: 不同的损失函数可以在精度(accuracy)和偏差(bias)之间进行权衡。例如,平方损失函数(MSE)偏向于优化精度,而绝对损失函数(MAE)对异常值更具鲁棒性。
对异常值的敏感度: 不同的损失函数对异常值的敏感程度不同。例如,MSE对异常值更敏感,因为它对大误差给予更高的惩罚。
定制化问题: 不同的损失函数可以适用于不同的问题和场景。例如,对于分位数回归问题,可以使用Quantile Loss。
指导模型选择和评估: 选择合适的损失函数有助于确定适用于特定问题的最佳模型,并用于评估模型的性能。
在优化中的约束条件: 某些损失函数具有特定的数学性质,可以在优化问题中引入约束条件,以确保模型具有特定的行为或性质。
回归问题的损失函数在训练和优化过程中起到了引导和评估的关键作用,帮助模型学习并提升对真实数据的拟合能力。选择合适的损失函数是建立有效回归模型的重要一步。
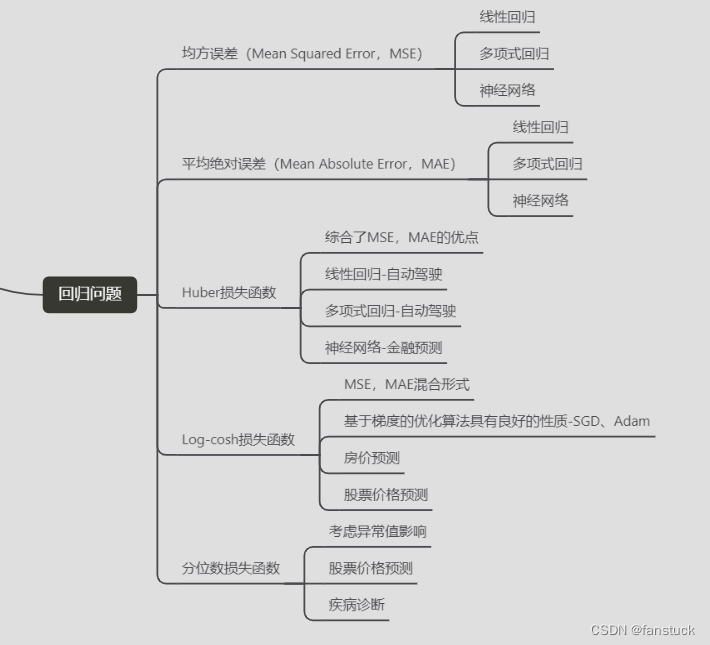
二、均方误差(Mean Squared Error, MSE)
均方误差(Mean Squared Error, MSE)是回归问题中常用的损失函数之一,它用于衡量模型的预测值与真实值之间的差异程度。其计算方式如下:
-
对于每个样本 i,计算预测值与真实值的差值:yᵢ - ȳ
-
对差值进行平方操作,以消除正负差异:(yᵢ - ȳ)²
-
对所有样本的平方差值求平均:
M S E = 1 / n ∗ Σ ( y i − y ˉ ) 2 MSE = 1/n * Σ(yᵢ - ȳ)² MSE=1/n∗Σ(yi−yˉ)2
其中:
- n 表示样本数量。
- yᵢ 是真实值。
- ȳ 是模型预测的值。
均方误差计算的实质是对每个样本的预测误差进行平方,然后求取所有样本的平均值。这样做的目的是为了放大大误差,使其在计算中得到更大的权重,从而更加关注模型对于极端情况的拟合程度。
MSE的特点包括:
- 对大误差敏感: 由于采用了平方操作,MSE会对大误差给予更大的惩罚,因此在训练过程中,模型会更加努力地降低大误差。
- 连续可导: MSE是一个光滑、连续可导的函数,这使得它在优化算法中的使用相对容易。
- 受异常值影响: MSE对异常值比较敏感,因为它会放大异常值的影响。
均方误差(Mean Squared Error, MSE)通常适用于以下回归算法和场景:
- 线性回归: MSE 是线性回归中最常用的损失函数之一。线性回归的目标是最小化预测值与真实值的均方误差。
- 多项式回归: 当采用多项式拟合数据时,MSE可以用来衡量模型对数据的拟合程度。
- 任何需要对预测误差进行均衡考虑的场景: 如果在预测误差的分布中,不希望偏向过高或过低的误差,而希望对所有误差给予相对均等的关注,那么MSE是一个合适的选择。
- 要求模型对大误差更加敏感的场景: MSE对大误差敏感,因此在需要模型更加关注大误差的情况下,MSE是一个合适的损失函数。
- 需要连续可导损失函数的场景: MSE是一个连续可导的函数,这使得它在优化算法中的使用相对容易。
- 要求在异常值影响下进行稳健拟合的场景: 由于MSE对异常值比较敏感,因此在训练数据中存在一些异常值,但又不希望这些异常值过度影响模型拟合时,可以考虑使用Huber损失,它在一定程度上抗干扰能力更强。
均方误差适用于大多数需要对预测误差进行均衡考虑的回归问题,特别是在数据分布相对均匀且没有特别要求的情况下,MSE是一个直观且有效的选择。然而,在存在异常值或对预测误差的分布有特殊要求时,可能需要考虑其他类型的损失函数。Python实现:
import numpy as np
def mean_squared_error(y_true, y_pred):
"""
计算均方误差(Mean Squared Error, MSE)
参数:
y_true : array-like, 实际值的数组
y_pred : array-like, 预测值的数组
返回:
mse : float, 均方误差值
"""
n = len(y_true)
mse = np.sum((y_true - y_pred)**2) / n
return mse
使用示例:
# 示例数据
y_true = np.array([3, -0.5, 2, 7])
y_pred = np.array([2.5, 0.0, 2, 8])
# 计算均方误差
mse = mean_squared_error(y_true, y_pred)
print(f"均方误差为: {mse}")
输出的均方误差为:0.375
三、平均绝对误差(Mean Absolute Error, MAE)
平均绝对误差(Mean Absolute Error, MAE)是回归问题中常用的损失函数之一,它用于衡量模型的预测值与真实值之间的平均绝对差异程度。
具体计算方法如下:
-
对于每个样本 i,计算预测值与真实值的差值的绝对值:|yᵢ - ȳ|
-
对所有样本的绝对差值求平均:
M A E = 1 / n ∗ Σ ∣ y i − y ˉ ∣ MAE = 1/n * Σ|yᵢ - ȳ| MAE=1/n∗Σ∣yi−yˉ∣
其中:- n 表示样本数量。
- yᵢ 是真实值。
- ȳ 是模型预测的值。
MAE的计算方式将所有样本的绝对误差进行平均,相较于均方误差(MSE)它对于异常值更具有鲁棒性,因为它不会对误差进行平方,不会放大异常值的影响。MAE的特点包括:
- 对异常值的鲁棒性: MAE相对于MSE来说,对异常值更具有鲁棒性,因为它不会放大异常值的影响。
- 平均绝对差异度量: MAE直接测量了预测值与真实值之间的平均绝对差异,提供了一个直观的度量。
- 不可导性: 与MSE不同,MAE在零点附近不可导,这可能会在某些优化算法中带来一些挑战。
平均绝对误差是一个直观且鲁棒的损失函数,特别适用于对异常值不希望过分敏感的回归问题场景。然而,在需要对大误差给予更大的惩罚或者对预测误差的分布有特殊要求时,可能需要考虑其他类型的损失函数。平均绝对误差(Mean Absolute Error, MAE)一般适用于以下回归算法和场景:
- 线性回归: MAE 可以用于衡量线性回归模型的拟合程度,特别是当对异常值不希望过分敏感时,MAE是一个合适的选择。
- 决策树回归: 决策树模型的分裂准则通常使用MAE来衡量节点的纯度,因此在评估决策树模型时,MAE也是一个自然的选择。
- 支持向量回归(SVR): MAE 可以用于支持向量回归中,衡量模型的预测值与真实值之间的平均绝对差异程度。
- K近邻回归(K-Nearest Neighbors Regression): 在K近邻回归中,可以使用MAE作为衡量模型性能的指标。
- 集成学习方法(如随机森林、梯度提升树等): MAE 可以用于集成学习模型中,作为评估模型性能的指标。
- 需要对异常值不敏感的场景: 当在训练数据中存在一些异常值,但又不希望这些异常值过度影响模型拟合时,可以考虑使用MAE。
- 不可导损失函数的情况: MAE 是一个非光滑的损失函数,相较于均方误差(MSE),它在零点附近不可导,因此可以在某些优化算法中提供额外的选择。
Python实现:
import numpy as np
def mean_absolute_error(y_true, y_pred):
"""
计算平均绝对误差(Mean Absolute Error, MAE)
参数:
y_true : array-like, 实际值的数组
y_pred : array-like, 预测值的数组
返回:
mae : float, 平均绝对误差值
"""
n = len(y_true)
mae = np.sum(np.abs(y_true - y_pred)) / n
return mae
使用示例:
# 示例数据
y_true = np.array([3, -0.5, 2, 7])
y_pred = np.array([2.5, 0.0, 2, 8])
# 计算平均绝对误差
mae = mean_absolute_error(y_true, y_pred)
print(f"平均绝对误差为: {mae}")
输出的平均绝对误差为: 0.5
四、Huber损失函数
Huber损失函数是一种用于回归问题的损失函数,它是均方误差(MSE)和平均绝对误差(MAE)的折中。它的概念是在MSE对异常值过于敏感而MAE对所有误差都给予相同权重的情况下,Huber损失引入了一个超参数 δ,通过这个参数来平衡对大误差的处理方式。
Huber损失的计算原理如下:
-
对于每个样本 i,计算预测值与真实值的差值:yᵢ - ȳ。
-
根据差值的绝对值与 δ 的大小,分两种情况计算损失:
-
如果 |yᵢ - ȳ| ≤ δ,损失是差值的平方的一半,即
L ( δ , y i − y ˉ ) = 0.5 ( y i − y ˉ ) 2 L(δ, yᵢ - ȳ) = 0.5(yᵢ - ȳ)² L(δ,yi−yˉ)=0.5(yi−yˉ)2 -
如果 |yᵢ - ȳ| > δ,损失是 δ(|yᵢ - ȳ| - 0.5δ) ,即
L ( δ , y i − y ˉ ) = δ ∣ y i − y ˉ ∣ − 0.5 δ 2 L(δ, yᵢ - ȳ) = δ|yᵢ - ȳ| - 0.5δ² L(δ,yi−yˉ)=δ∣yi−yˉ∣−0.5δ2 -
对所有样本的损失求平均:
H u b e r L o s s = 1 / n ∗ Σ L ( δ , y i − y ˉ ) Huber Loss = 1/n * ΣL(δ, yᵢ - ȳ) HuberLoss=1/n∗ΣL(δ,yi−yˉ)
-
其中:
- n 表示样本数量。
- yᵢ 是真实值。
- ȳ 是模型预测的值。
- δ 是Huber损失的参数,用来控制损失函数的平均绝对误差和均方误差之间的权衡。较大的 δ 使得损失函数在大误差处更接近MSE,较小的 δ 使得损失函数更接近MAE。
Huber损失的特点包括:
- 对异常值的鲁棒性: 与MSE相比,Huber损失对异常值更具鲁棒性,因为它在 |yᵢ - ȳ| 大于 δ 时的损失相对较小。
- 平滑性: Huber损失是一个平滑的损失函数,对于梯度下降等优化算法比MAE更易处理。
- 根据 δ 的选择,可以在MSE和MAE之间平衡损失的特性。
Huber损失函数一般适用于以下回归算法和场景:
- 线性回归: Huber损失可以用于线性回归模型,特别是当数据集中存在一些可能影响模型拟合的离群值时。
- 支持向量回归(SVR): 在支持向量回归中,Huber损失可以用作损失函数,它允许对大误差的处理方式相对灵活。
- 梯度提升回归(Gradient Boosting Regression): Huber损失可以用于梯度提升树等集成学习方法中,作为评估模型性能的指标。
- 岭回归(Ridge Regression)和Lasso回归(Lasso Regression): 当使用岭回归或Lasso回归等正则化方法时,可以考虑使用Huber损失以提高模型对异常值的稳健性。
- 需要对异常值不敏感的场景: 当在训练数据中存在一些异常值,但又不希望这些异常值过度影响模型拟合时,可以考虑使用Huber损失。
- 需要在平均绝对误差和均方误差之间平衡损失的场景: Huber损失允许根据问题的具体需求,在平均绝对误差和均方误差之间进行权衡。
Huber损失适用于需要在对大误差的处理方式上相对灵活、同时又希望对异常值不过分敏感的回归问题场景。它提供了一个折中的选择,可以平衡平均绝对误差和均方误差的特性。Python实现:
import numpy as np
def huber_loss(y_true, y_pred, delta=1.0):
"""
计算Huber损失函数
参数:
y_true : array-like, 实际值的数组
y_pred : array-like, 预测值的数组
delta : float, Huber损失的超参数,默认为1.0
返回:
huber_loss : float, Huber损失值
"""
error = y_true - y_pred
huber_loss = np.mean(np.where(np.abs(error) < delta, 0.5 * error**2, delta * (np.abs(error) - 0.5 * delta)))
return huber_loss
使用示例:
# 示例数据
y_true = np.array([3, -0.5, 2, 7])
y_pred = np.array([2.5, 0.0, 2, 8])
# 计算Huber损失
huber_loss_value = huber_loss(y_true, y_pred, delta=1.0)
print(f"Huber损失为: {huber_loss_value}")
输出的Huber损失为: 0.1875。
五、Log-cosh损失函数
Log-cosh(对数双曲余弦)损失函数是一种用于回归问题的损失函数,它对于异常值具有一定的鲁棒性,并且相对于均方误差(MSE)在大误差处的惩罚较小。Log-cosh 损失函数的计算原理如下:
-
对于每个样本 i,计算预测值与真实值的差值:yᵢ - ȳ。
-
计算对数双曲余弦的值:
l o g ( c o s h ( y i − y ˉ ) ) log(cosh(yᵢ - ȳ)) log(cosh(yi−yˉ))
其中 cosh 是双曲余弦函数。 -
对所有样本的损失值求平均:
L o g − c o s h L o s s = 1 / n ∗ Σ l o g ( c o s h ( y i − y ˉ ) ) Log-cosh Loss = 1/n * Σlog(cosh(yᵢ - ȳ)) Log−coshLoss=1/n∗Σlog(cosh(yi−yˉ))
其中:
- n 表示样本数量。
- yᵢ 是真实值。
- ȳ 是模型预测的值。
相比于均方误差(MSE):
- Log-cosh 对大误差的惩罚更小,因为在大误差处的 log-cosh 值的增长速度相对较慢。
- Log-cosh 对异常值相对较为鲁棒,它在异常值处的损失相对较小,不会像 MSE 那样受到异常值的影响。
Log-cosh 损失函数的特点包括:
- 对异常值的鲁棒性: 相比于均方误差,Log-cosh 损失函数对异常值更为鲁棒。
- 平滑性: Log-cosh 损失函数是一个平滑的函数,对于梯度下降等优化算法比 MAE 更易处理。
- 相对于 MSE 对大误差的惩罚更小。
Log-cosh(对数双曲余弦)损失函数一般适用于哪种回归算法和场景:
- 神经网络回归: 在深度学习中,Log-cosh损失可以用作神经网络回归任务的损失函数,尤其是在需要对异常值相对鲁棒的情况下。
- 深度学习模型: Log-cosh损失可用于各种深度学习模型,如多层感知器、卷积神经网络(CNN)、循环神经网络(RNN)等。
- 需要在异常值和大误差处平衡损失惩罚的场景: Log-cosh相对于均方误差(MSE)在大误差处的惩罚更小,同时对异常值相对较鲁棒,适用于需要在异常值和大误差处平衡损失惩罚的情况。
- 需要一个平滑的损失函数的场景: Log-cosh是一个平滑的函数,对于梯度下降等优化算法更容易处理,因此适用于需要光滑损失函数的情况。
- 需要较小的数值范围的输出: Log-cosh可以保证输出的范围相对较小,这在某些应用中可能是一个优点。
Python实现:
import numpy as np
def log_cosh_loss(y_true, y_pred):
"""
计算对数双曲余弦损失函数
参数:
y_true : array-like, 实际值的数组
y_pred : array-like, 预测值的数组
返回:
log_cosh_loss : float, 对数双曲余弦损失值
"""
error = y_true - y_pred
log_cosh_loss = np.mean(np.log(np.cosh(error)))
return log_cosh_loss
使用示例:
# 示例数据
y_true = np.array([3, -0.5, 2, 7])
y_pred = np.array([2.5, 0.0, 2, 8])
# 计算对数双曲余弦损失
log_cosh_loss_value = log_cosh_loss(y_true, y_pred)
print(f"对数双曲余弦损失为: {log_cosh_loss_value}")
输出结果对数双曲余弦损失为: 0.1685024610998955,Log-cosh损失函数适用于需要在异常值和大误差处平衡损失惩罚的回归问题场景,尤其是在深度学习模型中的回归任务中,可以作为一个有效的损失函数选择。
六、分位数损失函数
分位数损失函数(Quantile Loss)是一种用于回归问题的损失函数,它用于衡量模型对不同分位数的预测误差情况。分位数损失函数可以帮助模型更好地适应不同分布下的数据。具体来说,分位数损失函数的计算原理如下:
-
对于每个样本 i,设分位数为 q(0 < q < 1),计算预测值与真实值的差值:yᵢ - ȳ。
-
根据差值的正负和分位数 q 的大小,分两种情况计算损失:
-
如果 yᵢ ≥ ȳ,损失是:
( 1 − q ) ∗ ( y i − y ˉ ) (1 - q) * (yᵢ - ȳ) (1−q)∗(yi−yˉ) -
如果 yᵢ < ȳ,损失是:
q ∗ ( y ˉ − y i ) q * (ȳ - yᵢ) q∗(yˉ−yi)
-
-
对所有样本的损失值求平均:
Q u a n t i l e L o s s = 1 / n ∗ Σ Quantile Loss = 1/n * Σ QuantileLoss=1/n∗Σ
其中:- n 表示样本数量。
- yᵢ 是真实值。
- ȳ 是模型预测的值。
- q 是分位数的设定值,决定了在预测值高于真实值时和低于真实值时的惩罚程度。
分位数损失函数的特点包括:
-
适应性: 分位数损失允许模型在不同分布下的数据中进行适应,通过设定不同的分位数可以调整对预测误差的关注程度。
-
对高估和低估的惩罚程度可以根据分位数的选择而变化: 当 q 接近 0.5 时,对高估和低估的惩罚程度大致相等,而当 q 接近 0 或 1 时,对高估或低估的惩罚程度会相应增加。
分位数损失函数一般适用于以下回归算法和场景:
- 量化回归(Quantile Regression): 分位数损失函数是量化回归的核心,它允许模型对不同分位数的预测误差进行建模,从而可以得到不同置信水平下的预测区间。
- 金融风险评估: 在金融领域中,分位数回归可以用于评估不同置信水平下的金融风险,比如在金融投资领域中,分析投资组合的风险。
- 医学、经济学等领域的研究: 在研究中需要对不同分位数的数据进行建模,以获得关于变量分布的更全面信息。
- 需要在不同置信水平下的预测区间进行建模的场景: 在一些实际问题中,需要得到不同置信水平下的预测区间,而分位数损失函数可以提供这样的功能。
- 需要调整对高估和低估的惩罚程度的场景: 通过调整分位数的选择,可以灵活地调整对高估和低估的惩罚程度,适应不同的业务需求。
分位数损失函数特别适用于需要对不同分布下的数据进行建模,以及需要在不同置信水平下得到预测区间的回归问题场景。它提供了一种灵活的方式来调整模型对预测误差的关注程度,使得模型更适应于特定的业务需求。
Python实现代码:
import numpy as np
def quantile_loss(y_true, y_pred, q):
"""
计算分位数损失函数
参数:
y_true : array-like, 实际值的数组
y_pred : array-like, 预测值的数组
q : float, 分位数的设定值 (0 < q < 1)
返回:
quantile_loss : float, 分位数损失值
"""
error = y_true - y_pred
quantile_loss = np.mean(np.where(error >= 0, q * error, (q - 1) * error))
return quantile_loss
使用示例:
# 示例数据
y_true = np.array([3, -0.5, 2, 7])
y_pred = np.array([2.5, 0.0, 2, 8])
quantile = 0.5 # 选择分位数,例如中位数
# 计算分位数损失
quantile_loss_value = quantile_loss(y_true, y_pred, quantile)
print(f"分位数损失为: {quantile_loss_value}")
输出的分位数损失为: 0.25
这些损失函数各自具有不同的特点和适用场景,根据具体问题的需求和数据的特点,可以选择合适的损失函数来训练模型。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
le_loss
使用示例:
```python
# 示例数据
y_true = np.array([3, -0.5, 2, 7])
y_pred = np.array([2.5, 0.0, 2, 8])
quantile = 0.5 # 选择分位数,例如中位数
# 计算分位数损失
quantile_loss_value = quantile_loss(y_true, y_pred, quantile)
print(f"分位数损失为: {quantile_loss_value}")
输出的分位数损失为: 0.25
这些损失函数各自具有不同的特点和适用场景,根据具体问题的需求和数据的特点,可以选择合适的损失函数来训练模型。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。