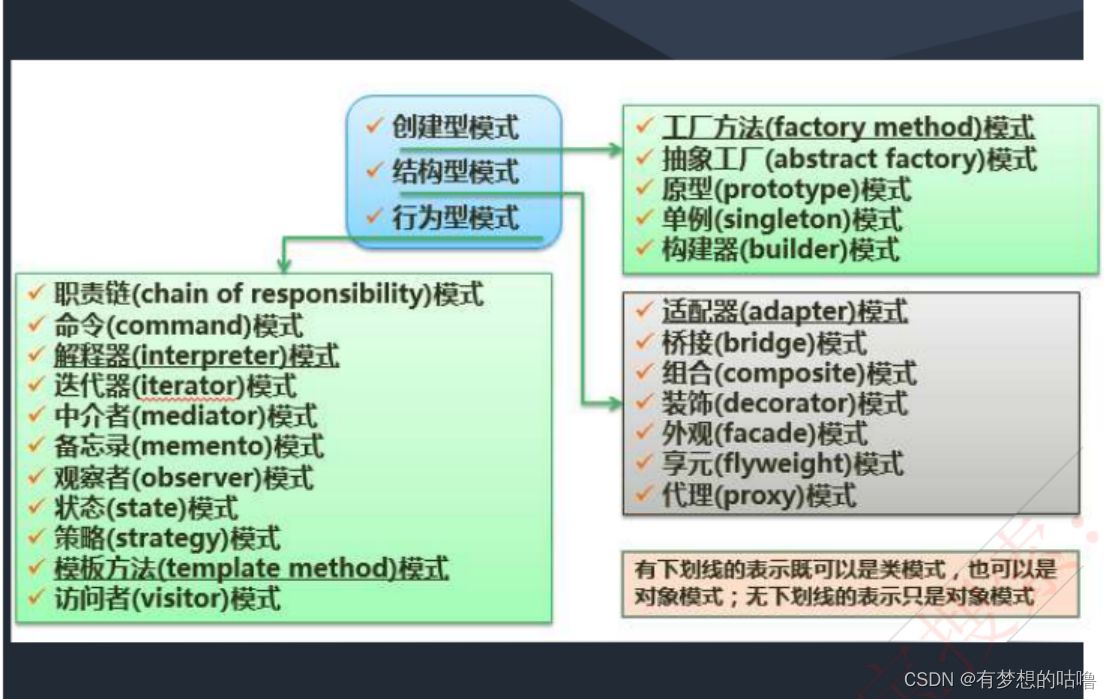
一、说明
二、逻辑回归简介
我们将以我们在线性回归中探索的想法为基础,所以如果你还没有读过那个博客,我建议你这样做。尽管 Logistic 回归的名称,但不涉及回归,它实际上是一个分类模型。分类算法用于将数据分类到特定类中。例如,将一组手写数字分类为从 0 到 9 的关联数字,或者对图像是狗还是猫进行分类。
2.1 线性分级机
遵循线性回归的相同理念,将机器学习视为几何问题,现在我们不再绘制最适合数据的线,而是绘制一条最能将数据分隔到各自类中的线。考虑下面的数据,假设紫色点代表类 1,黄点代表类 0。
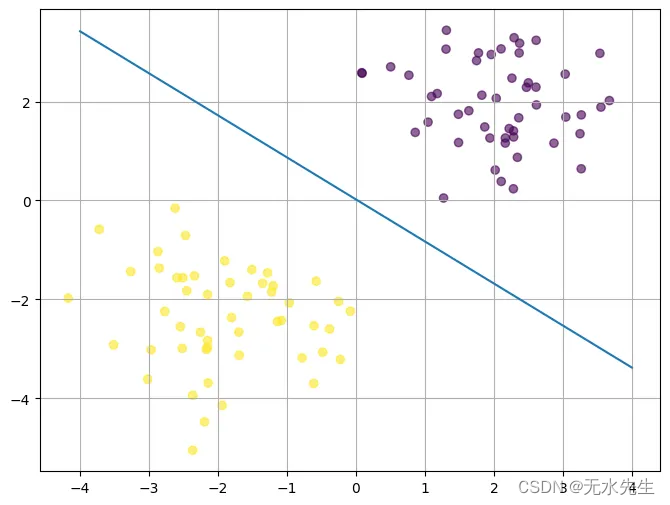
例如,这 2 个类别可能是两种不同的花种,x 轴可以是花瓣宽度,y 轴可以是花瓣长度。每个物种都有自己独特的叶子大小,与其他花不同。请记住,所有数据都是相同的,应用程序在任何环境中都是相同的。我们可以将模型解释为直线方程,但现在我们将 x 和 y 作为输入
![]()
假设我们选择线上方的紫色点
![]()
现在让我们选择线下方的黄色点
![]()
请注意,如果我们选择线上方的点,输出为负,如果我们选择线下方的点,则输出为正,这就是我们对任何新数据点进行分类的方式。如果点直接位于线上,则结果将为 0,即无类。通常,对于 D 输入,方程可以写成。
![]()
线性分类器模型
您会注意到这与线性回归相同,这就是为什么线性回归是先决条件的原因,它将使理解逻辑回归变得更加容易,因为您已经拥有使用向量、矩阵微积分和机器学习中使用的整体符号的经验。这仅仅是个开始,这个模型被称为线性分类器,我们将继续在这个模型的基础上构建 Logistic 回归模型。
2.2 神经元
在机器学习的早期,人们对尝试对人脑进行建模并创建类似于人脑的机器学习模型非常感兴趣。“感知器”算法背后的想法受到人脑神经元的启发。逻辑回归与感知器算法非常相似。
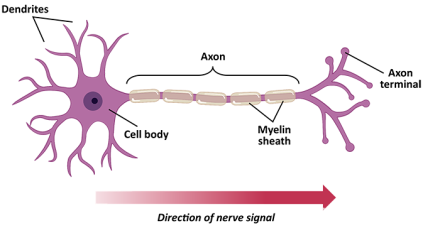
如果我们看一下人脑中的神经元,你会发现它从树突中吸收多个输入,如果动作电位足够强,它会通过轴突末端产生输出。
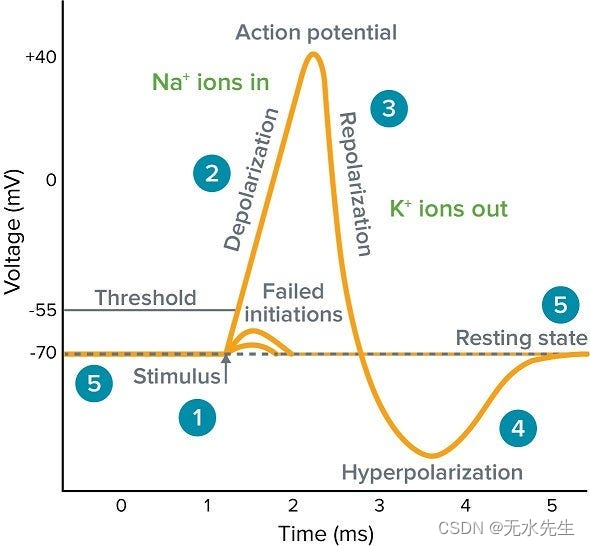
这会产生“全有或全无”行为,其中神经元仅在电压超过阈值时才触发。因此,生物神经元的输出可以是1或0,开或关。我们的逻辑回归模型从人脑神经元的结构和机制中汲取灵感,您很快就会看到。
2.3 设置模型
如果您之前对模型进行试验,您会注意到线下方的点更“正”,线上方的点更“负”,靠近线的点接近 0。当该点看起来离直线更远时,我们可以推断出它属于该类的概率增加,而属于其他类的概率减小。当点越来越接近线时,它变得更加不确定,并且属于任一类的概率变为 50/50。我们希望扩展当前的线性分类器模型,因此它输出该点属于某个类的概率。我们可以从线性分类器获取输出,并通过“激活函数”将其归一化为介于 0 和 1 之间。您可以选择多个激活函数,但现在,让我们坚持使用 sigmoid。

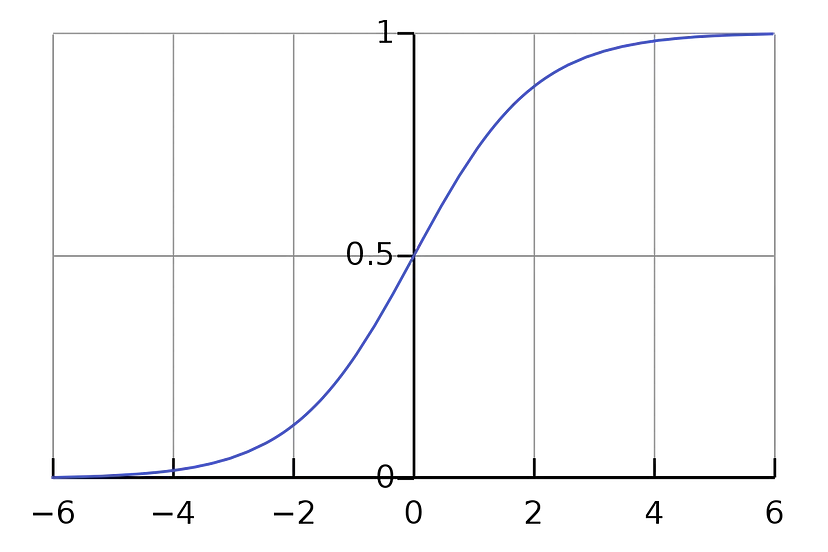
现在我们可以将模型解释为属于类别 y 的条件概率。现在不要混淆,我们使用y作为我们的“目标”,x是D输入的单个样本。
![]()
由于 x 属于 y=1 和 y=0 的概率必须加起来为 1,我们也得到
![]()
这很好,因为我们可以简单地对概率进行四舍五入以获得预测值。因此,如果属于类 1 的概率是 0.7,我们可以将其四舍五入为 1。如果属于类 1 的概率为 0.2,我们可以向下舍入得到 0 的预测。
现在我们的模型的快速可视化
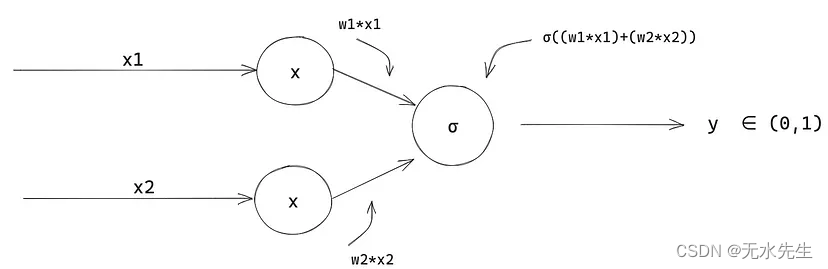
有趣的是,我们的模型看起来与生物神经元相似,您可能还想知道这是否与神经网络有关?我们正在构建的模型通常被称为神经网络的“神经元”,神经网络本质上是许多逻辑回归函数的网络。
2.4 变量回顾
当我第一次学习神经网络和逻辑回归时,最困难的事情实际上是记住所有变量的含义和大小。因此,在继续之前,让我们快速回顾一下。线性回归博客中的变量几乎相同。
- N = 样品
数 - 测量 10 个个体的重量,N=10 - D = 每个样本
的特征数 - 测量身高、体重和年龄以预测血压。D=3 - w = 大小为 Dx1 的权重矢量
- X = 大小为 NxD
的数据矩阵 - 每行都是一个样本,而每一列都是该样本的一个特征 - x = 大小为 Dx1 的单个样本
通常,大写字母表示矩阵,而小写字母表示向量。
- yn = 来自第 n 个样本的模型的单个目标标签或预测
- Y = 模型中的所有目标标签或预测作为大小为 Nx1 的向量
- tn = 第 n 个样本中的单个目标标签
- T = 所有目标标签作为大小为 Nx1 的向量
- P(y=1|x) = 我们模型的概率预测
现在,我们对 Y 有两种不同含义的原因是让我们的推导更容易编写。写P(y=1|x) 在做推导时,所以我们设置 P(y=1|x) = y 并改用 t 作为我们的目标。如果同时看到 t 和 y,假设 t=目标和 y=预测
- 误差函数 = 成本函数 = 目标函数
一般来说,我们总是会最小化我们的误差/成本函数,这是不言自明的。目标函数可能会根据上下文最小化或最大化。这只是一个微不足道的符号翻转场景,其中最小化 x² = 最大化 -x²。一旦我们探索了交叉熵和对数似然,这一点就会变得明显。
2.5 设置错误函数
现在,让我们设置一种方法来测量模型中的误差。最初的想法可能是只使用线性回归中的均方误差函数(MSE)。如果我们分解我们的问题,我们将意识到MSE函数在这种情况下并不理想。首先,MSE假设误差呈高斯分布,但是逻辑回归模型中的每个预测都遵循伯努利分布。其次,如果我们的模型对完全错误的答案非常有信心,我们希望我们的误差呈指数级增长。这不能使用MSE的二次性质进行建模。我们问题的本质是植根于概率的问题,因此选择一个源于概率的错误函数是有意义的。我们可以从信息论中借用“熵”的概念。如果你不了解信息熵,我建议你观看这个介绍这个主题的视频。
2.6 交叉熵误差
我们可以使用负对数函数来模拟我们的错误
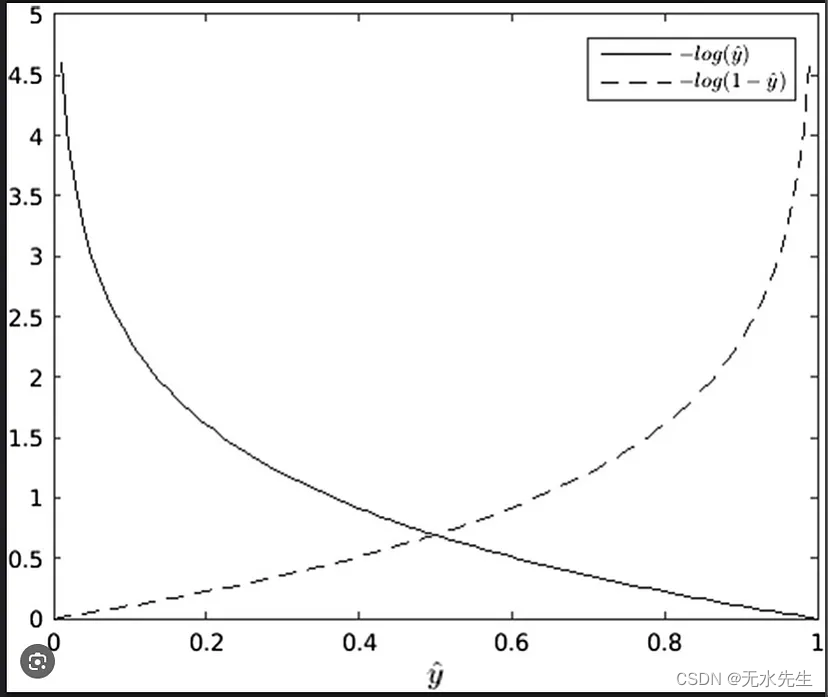
实线表示目标=1,虚线表示目标=0
当我们的预测为 1 且目标为 1 时,我们的误差为零,但误差呈指数增长,我们的模型对错误答案的置信度越高,反之亦然,如果我们的预测为 0。这被称为交叉熵误差,公式就是。
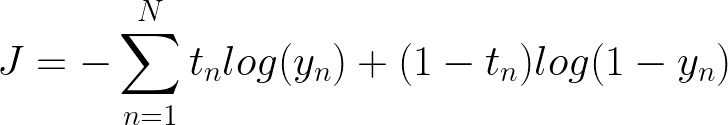
请注意,如果我们的目标是 1,其中一个日志将乘以零,反之亦然。
我们的目标是最小化这种交叉熵误差。如果现在看起来令人困惑,我们还将研究另一种使用最大似然推导此公式的方法,这将进一步巩固您的理解。
2.7 最大似然
最大似然会产生与交叉熵误差几乎相同的误差公式,但在我看来,如果您不了解熵的工作原理,与交叉熵误差函数相比,它更直观一些。此外,在进行梯度下降时,这将使推导更容易一些。
假设我们正在抛硬币,但我们不知道它是否公平。我们不知道翻转正面或反面的概率。我们掷硬币 10 次,观察到 8 个正面和 2 个反面。观察到此结果的可能性为
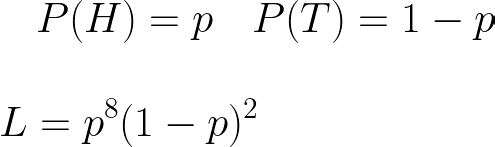
我们想弄清楚硬币的概率,使观察这些数据的可能性最大化。我们希望相对于 L 最大化 p。在这种情况下,我们将通过获取双方的对数来最大化对数可能性。为什么?最终结果仍然相同,因为对数是一个单调递增的函数(如果 a>b 则 log(a) > log(b) 也为真)。使用乘积规则对数,它将使我们的推导变得更加容易。请注意,在机器学习中,log 表示自然日志。
为了最大化对数似然,我们可以取导数并求解 p。
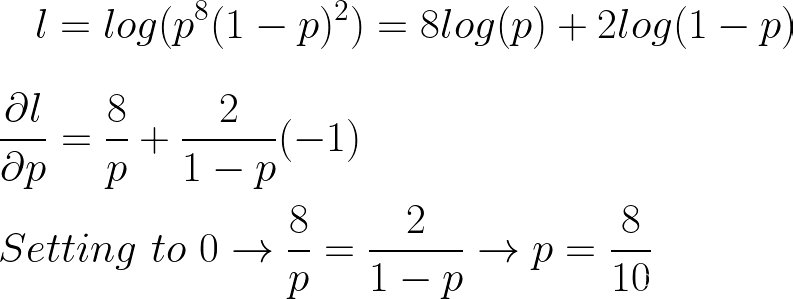
这个新的“l”=对数似然
在我们的问题中,我们对大小为 N 的数据的观察。此数据的标签是 0 和 1 的序列,而不是正面和反面。我们想计算出给定x(输入)的模型的概率,该概率使观察这些数据的可能性最大化。让我们回顾一下模型的定义。
![]()
我们的概率取决于 x!
设置问题
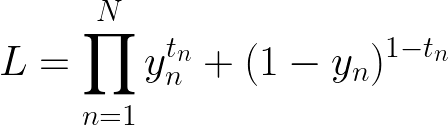
tn 是目标,因此 0 或 1
我们有一个概率乘积,迭代我们的 N 个样本。现在你会注意到为什么在这里获取日志非常有用。
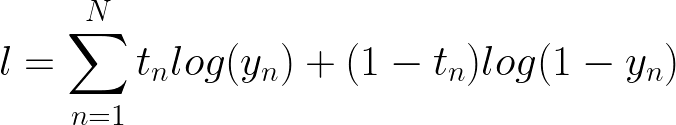
目标函数
使用对数的乘积规则,我们可以将其转换为求和而不是乘积。现在这与我们的交叉熵误差相同,只是它缺少负号。这是因为我们正在最大化对数似然,而不是最小化,就像在交叉熵误差中一样。
2.8 练习:求解重量
让我们从取交叉熵函数的导数开始,因为我们正在求解我们想要将导数 wrt 取到每个权重 w 的权重。我们的权重嵌套在一堆其他函数中,当我们遇到这种情况时,使用链式规则是有意义的。我们可以使用链式规则将导数拆分为 3 个导数。首先是取我们的交叉熵函数的导数,然后取 sigmoid 函数的导数,最后取 w 本身的导数。
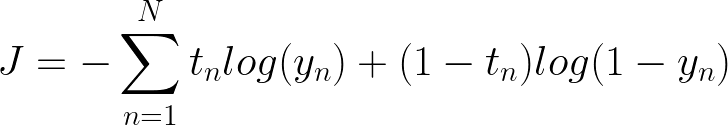
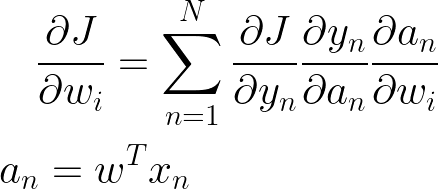
尝试自己派生解决方案,也尝试矢量化解决方案,以便我们可以轻松地在 NumPy 中编写所有内容。这意味着重新安排解决方案以利用NumPy的点积功能。
2.9 解决
让我们取关于 yn 的一阶导数
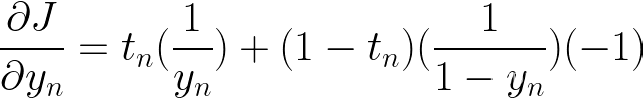
接下来取 yn 关于 (激活函数) 的导数

最后取一个 with resepct 的导数到 wi,我们在做线性回归时已经计算过了
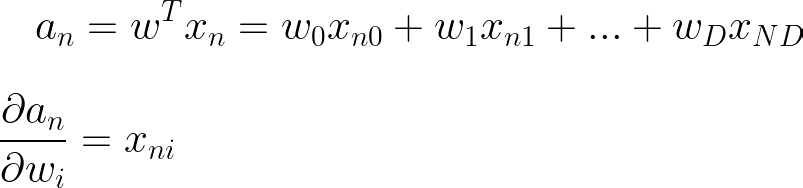
现在我们可以组合结果来计算最终导数
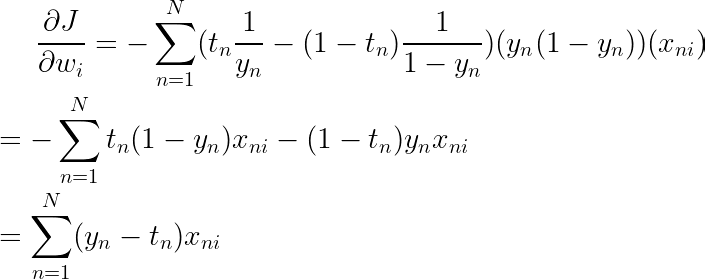
我们可以矢量化这个等式
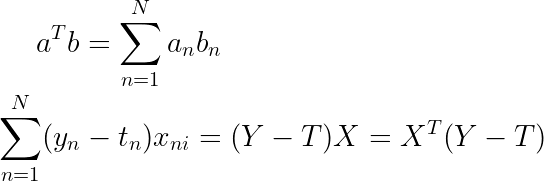
让我们快速仔细检查矩阵乘法的大小,以便我们知道我们没有做错任何事,并且我们的输出是正确的大小。我们的输出应该是大小为 Dx1 的矢量,用于我们所有权重的梯度。
![]()
现在,您可以尝试通过将导数设置为 0 来求解权重,但不幸的是,此导数没有闭式解。
2.10 梯度下降/上升
我们可以使用一种迭代方法,在误差函数的局部最小值方向上采取小步骤来找到最佳权重,这称为梯度下降。
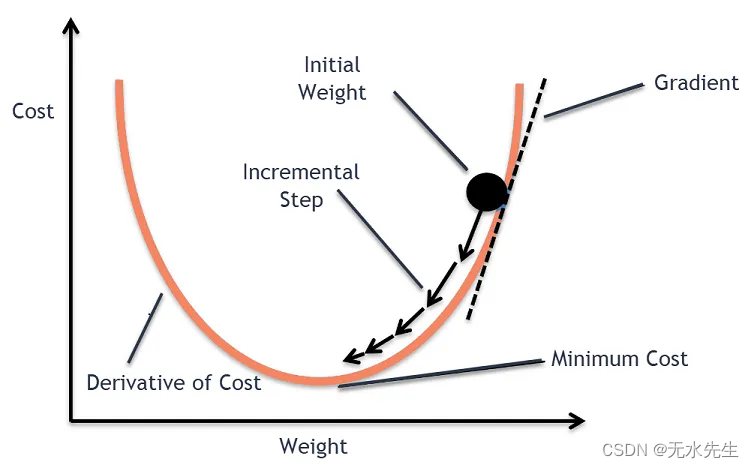
请注意,这并不能保证找到全局最小值,只能保证找到局部最小值
步长也称为学习率,是我们朝着最低成本方向采取的步骤的大小。我们设置什么学习率?嗯,它主要是直觉,我们希望设置一个足够大的学习率,这样学习过程就不会进行太多迭代,但也足够小,这样我们就不会超过最小值,然后围绕它振荡。在实践中,您希望在梯度下降时观察误差。让我们做一个简单的例子来巩固这个想法

我们知道 J 的最小值是 x=0,但假装我们不知道
- 迭代 1:w = 5 -0.1*10 = 4
- 迭代 2:w=4 – 0.1*8= 3.2
- 迭代 3:w=3.2 -0.1*6.4 = 2.65
现在,如果您还没有做过微积分 3,您应该对梯度下降的工作原理有一个很好的了解。如果我们试图最大化一个值,只需将公式中的符号从负数切换到正数即可。这样,您可以选择最小化交叉熵误差或最大化对数似然,这两种方法都会产生相同的结果。
2.11 练习:对模型进行编码
在 repo 中有一个名为“logisitic_regression_practice”的文件,在您的编辑器中打开它,并使用您学到的填写变量和函数。另外,请确保下载数据“logistic_data.csv”。如果您想要额外的挑战,请尝试在没有帮助的情况下从头开始编写模型。只需加载logisitic_data即可。如果您遇到困难,您可以随时查看名为“logisitic_regression_solution”的解决方案。
三、多类逻辑回归
假设现在我们要对 2 个以上的东西进行分类,到目前为止我们一直在进行二元分类,我们的目标是“0”或“1”。如果我们想使用多个类,我们的原始模型将不起作用。让我们继续使用一些几何图形来帮助我们构建直觉。假设我们现在预测的不是预测 2 个类,而是预测 3 个类。
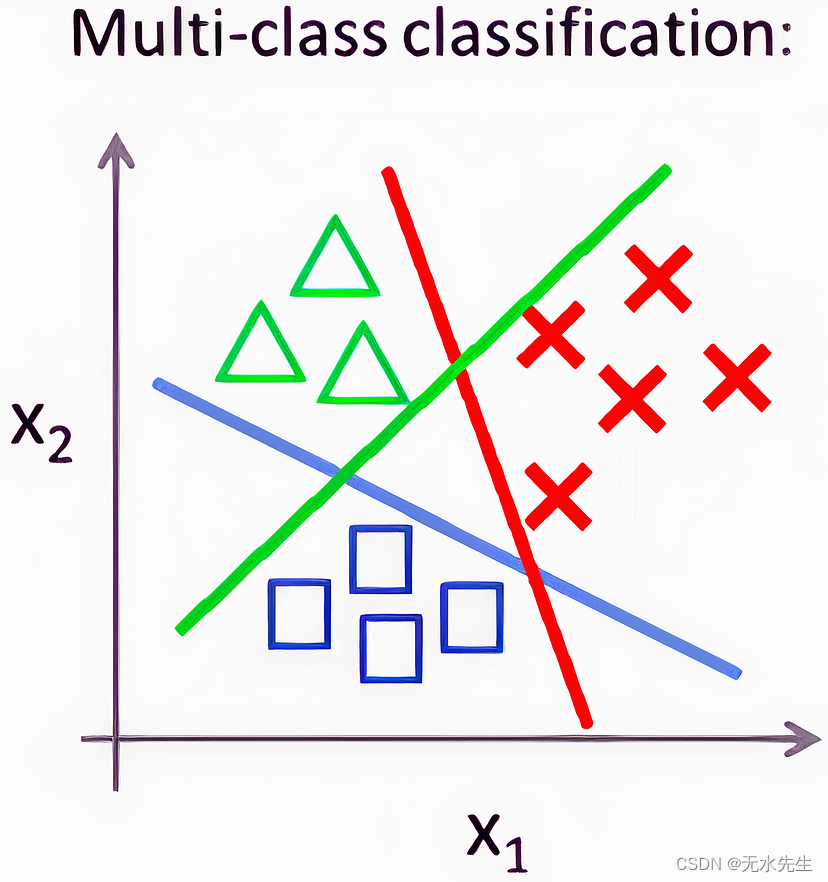
直观地说,我们似乎需要 3 个二元逻辑回归模型来解决这个问题,我们可以将它们组合在一起以制作多类逻辑回归模型。所以现在让我们定义这 3 个方程。
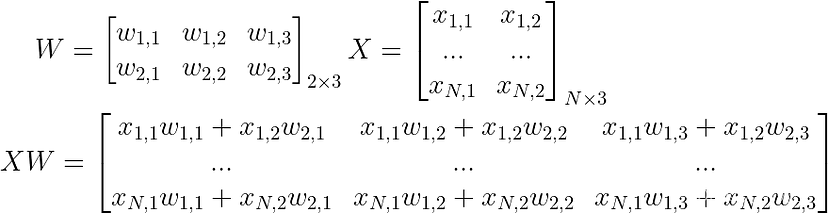
这里的错别字,X 是 Nx2
现在我们的权重不再是一个向量,而是一个矩阵。
通常,我们可以将 D 输入、K 类和 N 个样本的 X 和 W 视为
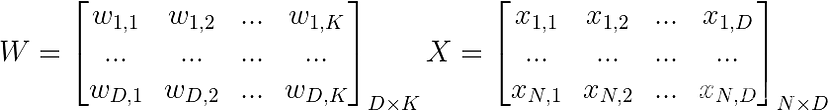
3.1 软最大激活
让我们继续以 K=3 为例,其中我们预测了 3 个类。现在我们需要一个与 sigmoid 不同的激活函数,如果我们使用 sigmoid,我们就不能再将其输出作为概率,因为它们的总和不会为 1。您可以通过设置随机权重并计算 3 个类的 sigmoid 来自行验证这一点。相反,让我们对 3 个神经元的输出进行归一化。为此,我们可以将每个neruon输出除以所有神经元输出的总和。为了确保所有输出都是绝对值,我们可以取所有输出的指数。类似于我们如何通过除以每个分量的大小来归一化线性代数中的向量。这样,每个神经元的每个输出都将是一个概率。我们可以简单地从所有神经元中获取最高概率作为我们的预测。
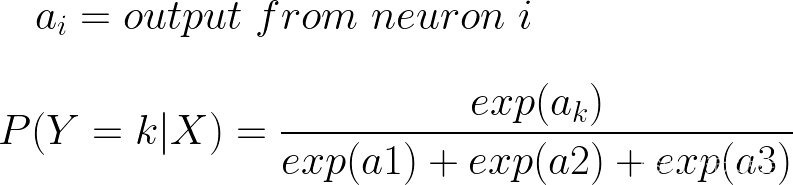
3.2 前向传递
让我们画一个图表,并做一个快速的例子来巩固所有这些。假设我们只有 1 个样本,让我们为权重矩阵分配随机权重。
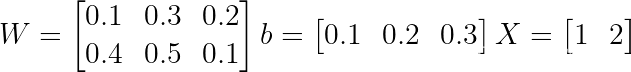
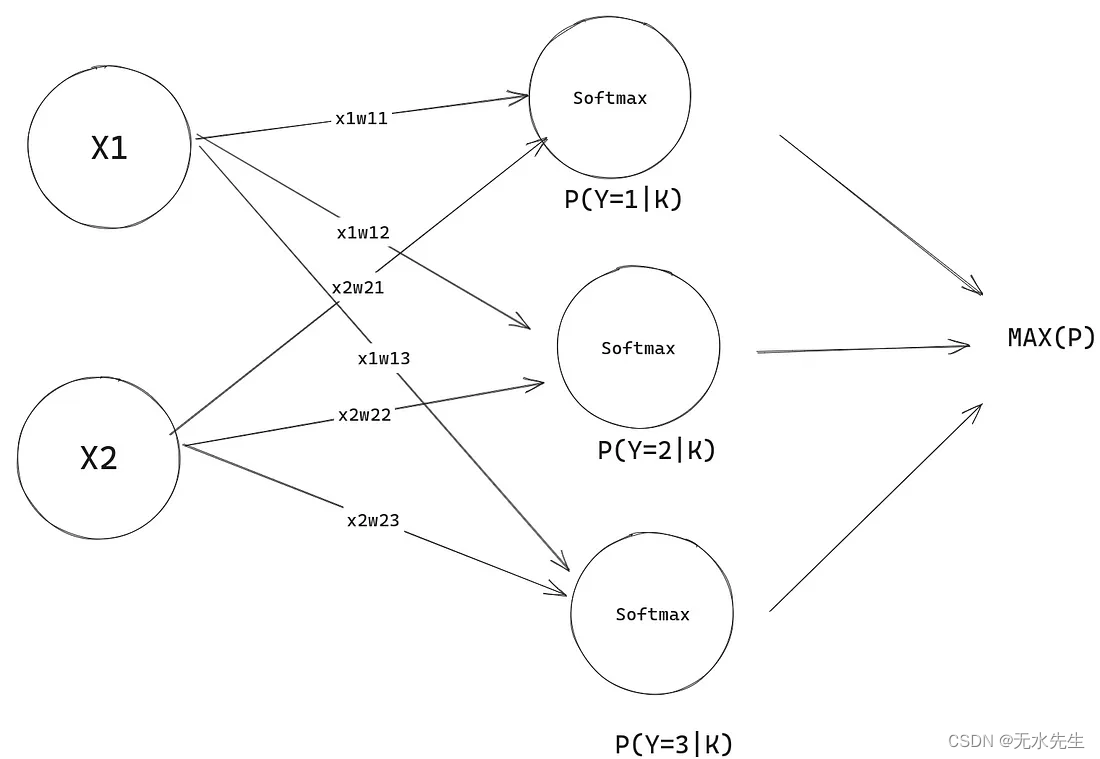
现在这实际上开始类似于神经网络,令人兴奋的是,这是一个没有隐藏层的神经网络。完成此操作后,我们将准备好处理神经网络。
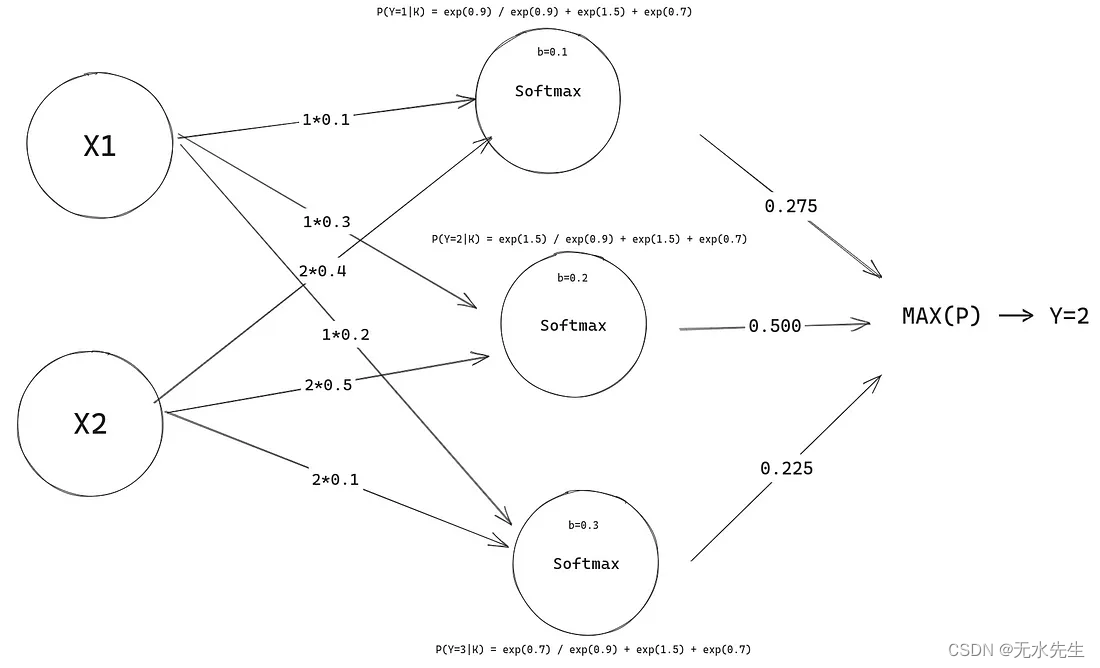
请注意所有概率的总和如何为 1 !
现在我们的模型可以做出预测,即使它们是完全随机的。
3.3 计算误差
我们需要弄清楚现在如何计算每个预测的误差。我们只关心模型应该预测的类的预测概率。单个样本的 Softmax 回归模型输出是一个大小为 NxK 的矩阵。我们可以对目标矩阵进行单热编码,从大小 Nx1 到大小 NxK。如果你不熟悉一种热门编码,我会在线性回归博客中介绍它。假设我们有 3 个目标,这些目标的表示将有一个热编码矩阵。

一般来说,这个独热编码矩阵的大小为 NxK,与我们的预测矩阵大小相同。然后我们可以对每个样本的所有 K 类求和并取交叉熵误差,如果该类不是目标,则误差将简单地乘以 0,因此我们只会得到目标类的模型预测的交叉熵误差,而忽略所有其他类。

在进行推导时携带负号是非常不方便的,所以让我们最大化对数可能性

3.4 练习:推导解决方案
如果你还没有学过矩阵微积分,你可能会在这里挣扎,但我建议你仍然遵循。如果您不熟悉,请观看此视频,了解如何将向量的导数转换为向量,因为我们将在推导中处理这个问题。将向量/矩阵的导数 wtr 转换为标量非常容易,我们已经完成了。
这个推导是相当棘手的,无论如何都不简单,所以在你完全理解它之前需要一些练习。我们想要采用的导数类似于我们对二进制逻辑回归所做的导数,只是现在变量略有不同。
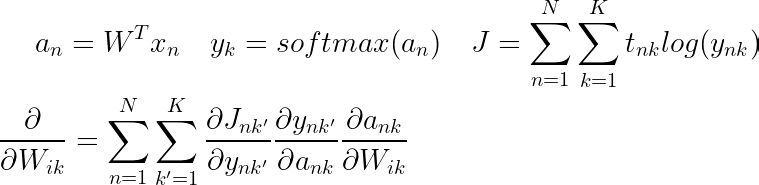
你会注意到这里有一些虚拟变量 n 和 k',在进行推导时,我们会变得非常混乱和模棱两可,我们将引用哪些索引,这就是我们使用这些虚拟变量的原因。你可以把这些变量想象成我们在 C 风格的 for 循环中用来迭代数组的变量。
这个衍生品链中的二阶导数是最困难的。这也是我们从k'切换到k的时候。我们从查看 k' 迭代的所有类切换到 k,即我们正在采用导数 wrt 的特定类。
发生这种情况的原因是 softmax 函数依赖于所有激活输入,而不仅仅是它自己的。因此,softmax 函数将向量作为输入。下面是一个 k=3 的快速示例。
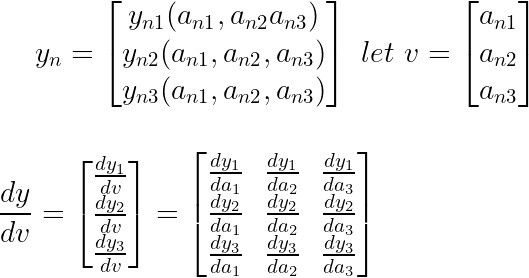
结果将是一个雅可比矩阵。
3.5 解决
Lets start by taking the first derivative
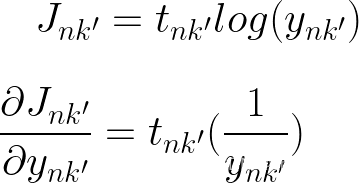
现在是第二个也是最难的导数,在我们采用导数之前,让我们快速回顾一下我们正在处理的内容
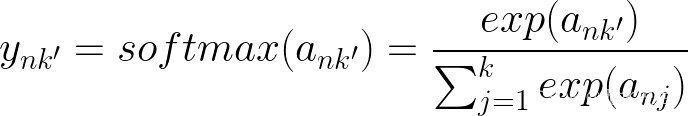
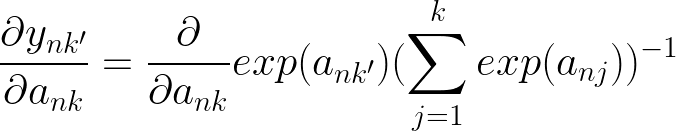
当 k != k' 和 k = k' 时,我们有 2 种不同的情况,因为我们取导数 wrt ank,当 k != k' 时,我们将 ank' 项视为常数,当它们相等时,我们还必须取它的导数。同样对于求和,我们必须考虑 j=k 何时并取相应的导数。
让我们首先考虑当 k != k'
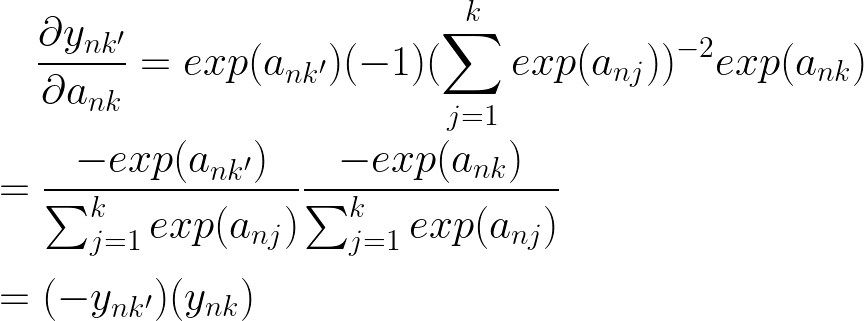
现在让我们考虑当 k = k'
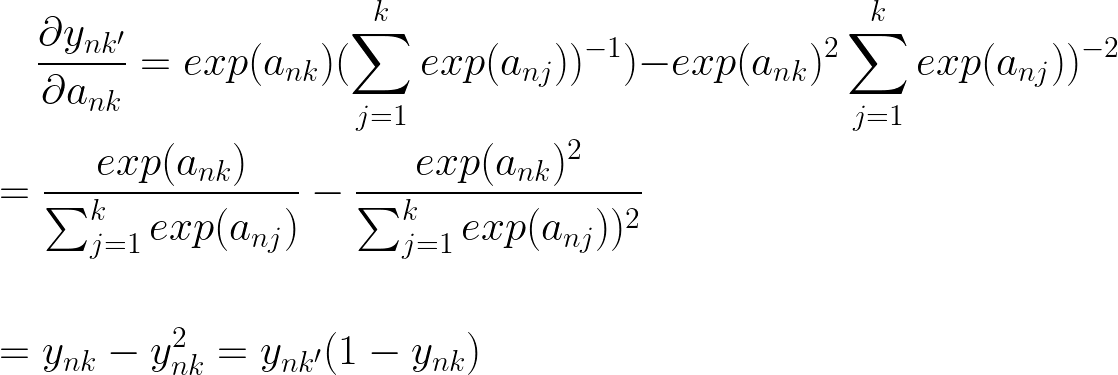
我们可以使用克罗内克三角洲函数来处理我们需要值等于 0 或 1 的情况。
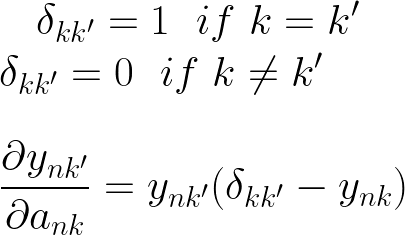
当 k = k' 时,我在导数的最终结果中用 ynk 代替了 ynk',这样我们就可以有一个简洁的最终表达式来总结这两种情况。
现在我们可以进入第三阶也是最后一阶导数
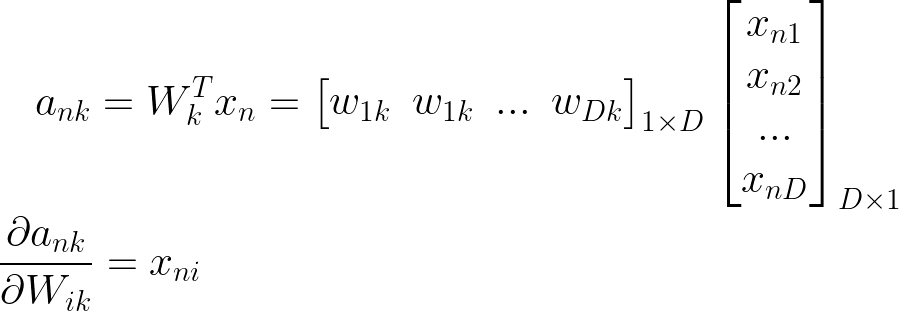
将所有三个导数组合在一起,我们得到
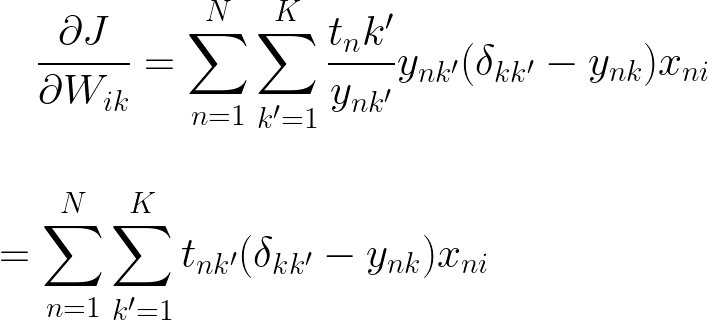
现在为了隔离增量,让我们暂时忘记 N 上的求和并扩展表达式
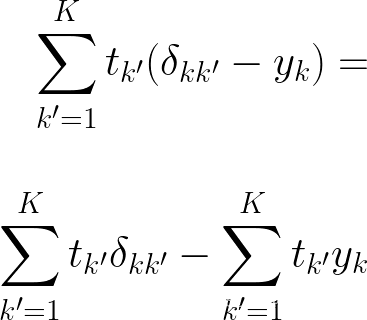
我们知道克罗内克增量 = 1 当且仅当 k = k',所以我们知道整个三角洲的总和将乘以零,除非 k = k'
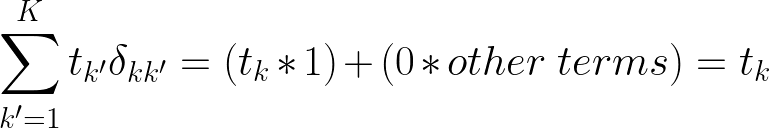
由于 yk 不依赖于求和,我们可以将其分解掉,并且所有 k 可能性中只有 1 个目标,因此我们知道 tk' = 1 的总和
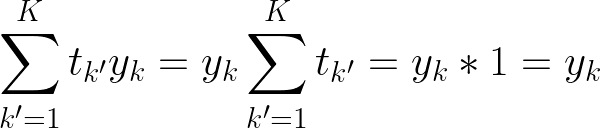
现在让我们回到 N 上的求和。
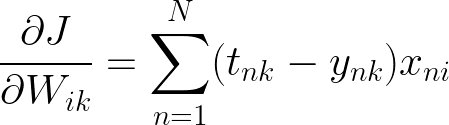
这个结果看起来与二进制逻辑回归解决方案非常相似,这很好。
四、结论
您可以尝试自己编写 Softmax 回归算法,我之所以不在这里编码,是因为我们将在下一篇博客中做神经网络时深入探讨它。如果我在这里共享非常相似的代码,它只会变得多余。我们在这里学到的想法将成为神经网络的完美垫脚石,如果你很好地理解了Logisitic Regressoin,它将使神经网络变得更容易。我在这个博客中没有涉及很多东西,比如正则化和其他实际问题。将此视为简要介绍,而不是全面的指南。祝你好运!

![NSS [BJDCTF 2020]easy_md5](https://img-blog.csdnimg.cn/img_convert/c00adaef60f1a52ed9a7a48d79bbcd57.png)


![[架构之路-239]:目标系统 - 纵向分层 - 中间件middleware](https://img-blog.csdnimg.cn/c9bbd3b41e204ac6aaeb50a47033e2e8.png)