10.0 概述
本章包含了一个例子:如何用Linux性能工具在受CPU限制的应用程序中寻找并修复性能问题。
阅读本章后,你将能够:
- 在受CPU限制的应用程序中明确所有的CPU被哪些源代码行使用。
- 用1trace和oprofile弄清楚应用程序调用各种内部与外部函数的频率。
- 在应用程序源代码内寻找模式,在线搜索应用程序的行为表现与可能的解决方案。
- 以本章为模板,跟踪与CPU相关的性能问题。
10.1受CPU限制的应用程序
本章的调查对象是一个受CPU限制的应用程序。其重点在于能够对受CPU限制的应用程序进行优化,因为,这是最常见的性能问题之一。
通常,这也是高度调优的应用程序的最后战线。
当消除了磁盘和网络瓶颈后,一个应用程序就变成了受CPU限制的。此外,与改进CPU相比,购买更快的磁盘或更多的内存要容易得多,因此,如果程序是受CPU限制的,那么比起仅仅买一个新系统来说,能够追踪并修复CPU性能问题就是一项重要技能了。
10.2 确定问题
性能追踪的第一步是确定要调查的问题。本例中,我选择调查使用GIMP时出现的性能问题,GIMP是一个开源的图像处理程序。它能对一个图像的各个方面进行分割,但它也有一组强大的过滤器,能够用多种方式对图像进变形和修改。这些过滤器根据一些复杂的算法来改变图像的外观。通常情况下,过滤器的工作需要很长时间才能完成,并且非常耗费CPU资源。特别是其中的一个过滤器Von Gogh(梵高,LIC),它接收一个图像为输入,将其修改为看上去像梵高风格的画作。这个过滤器所花费的时间特别长。过滤器运行时使用了几乎100%的CPU资源,且完成时间长达几分钟。完成时长涉及的因素包括:图像大小、机器CPU的速度,以及传递给过滤器的参数值。本章中,我们用Linux性能工具调查为什么这个过滤器这么慢,同时还要弄清楚是否有方法能提高它的速度。
10.3 找到基线/设置目标
任何性能追踪的第一步就是要确定问题当前的状况。对GIMP过滤器而言,我们需要确定它在特定图像上运行要花多少时间,这就是基准时间。一旦掌握了这个基准时间,接下来就可以尝试优化,看看是否减少了它的执行时间。有时候,计量某个工作耗费的时间是很难的,不像拿个秒表那么简单,因为当我们相当耗费CPU资源的作业正在运行的时候,操作系统可能会调度其他任务。在这种情况下,如果除了计算密集型作业之外还有其他作业也在运行,那么墙钟时间也许会大大超过该进程实际使用的CPU时间。就这点来说,我们是幸运的,当运行过滤器时,通过观察top,可以看到lic进程占用了绝大部分的CPU使用量,如清单10.1所示。
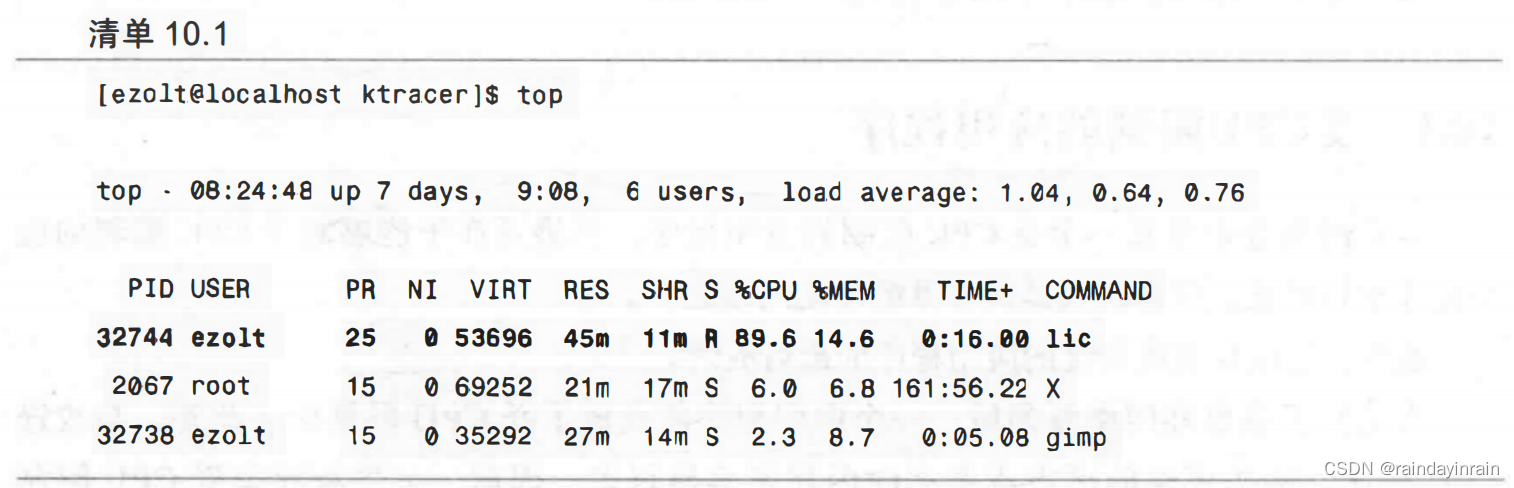
由此,我们可以推断在运行过滤器时,GIMP实际上派生出一个独立进程来运行。因此,当过滤器运行时,我们就可以利用ps来追踪该进程消耗了多少CPU时间,以及它是什么时候结束的。知道了使用top的过滤器的PID之后,可以运行清单10.2中的循环,要求ps周期性地观察该过滤器使用了多少CPU时间。

如果在没有秒表的情况下对一个应用程序计,你可以把time和cat当作简易的秒表来用。只需在想要开始计时的时候键入time cat,然后在结束时按下<Ctrl-D>组合键即可。time将会显示已经过的时间。
在参照图像(从我的地下室获取的图片)上运行lic过滤器并用刚才描述的ps方法对该过滤器计时,我们可以从清单10.2中看出来,处理整个图像花费了2分46秒。这个时间就是我们的基准时间。既然知道了该过滤器直接运行耗费的时间,我们就可以设置本次性能追踪的目标了。如何为性能调查设置合理的目标并非总是清晰明了的。一个合理的目标值取决于多个因素,包括根据特定问题和用户需求已经完成的调优。通常,最好的方法是以有相同情况且性能更快的应用程序为基础来设置目标。可惜的是,我们不知道还有哪个GIMP过滤器是完成类似工作的,因此,我们必须做出猜测。对一段相对未调优的代码来说,一般5%~10%的性能优化是一个合理的目标,所以,我们设定了10%的速度提升,即运行时间为2分30秒。
既然目标已经挑好了,我们就需要一种方法来保证我们的调优带给过滤器结果的变化是可以接受的。此时,我们将在参照图像上运行初始过滤器,并把其结果记录在另一个文件中。这样,我们可以将优化后的过滤器输出与初始过滤器输出进行比较,看看优化是否改变了输出。
10.4 为性能追踪配置应用程序
我们调查的下一步是为性能追踪设置应用程序,用符号重新编译该程序。符号能让性能工具(比如oprofile)调查哪些函数和源代码行消耗了CPU时间。
回到GIMP,我们从其网站下载最新的GIMP源代码压缩包,然后重新编译它。对GIMP和许多开源软件来说,重新编译的第一步就是运行configure命令,产生将用于构建应用程序的生成文件。configure命令向生成文件传递出现在CFLAGS环境变量中的所有标志。在这种情况下,由于我们希望用符号构建GIMP,因此设置的CFLAGS变量含有-g3。这就使得符号包含在生成的二进制文件中。清单10.3显示了这个命令,覆盖了CFLAGS环境变量的当前值,并将其设置为-g3。

之后,我们生成并安装包含所有符号的GIMP版本,当运行这个版本时,性能工具将会告诉我们时间都消耗在了哪里。
10.5安装和配置性能工具
如果性能工具还没有安装,那么追踪的下一步就是安装它们。尽管看上去这是件容易的事儿,但它常常涉及跟踪定制包的分发,甚至是从头开始对工具进行重新编译。本例中,我们在Fedora Core 2上使用oprofile,因此,我们既要跟踪oprofile内核模块(在Fedora 下,它只包含在对称多处理(SMP)内核中),也要跟踪oprofile软件包。同样可能让人觉得有意思的还有用ltrace性能工具查看被调用的库函数及其被调用的频率。幸运的是,Itrace 包含在Fedora Core 2中,所以我们不需要跟踪它。
10.6运行应用程序和性能工具
接下来,我们运行应用程序,并用性能工具进行测量。由于lic过滤器直接由GIMP调用,因此,我们使用的工具必须能够附加到已运行进程,且能对其进行监控。
对oprofile来说,我们启动oprofile,运行过滤器,然后在过滤器完成工作后停止oprofile。因为lic过滤器在运行时占用了将近90%的CPU,所以oprofile收集的系统整体样本将主要与lic过滤器相关。当lic开始运行时,我们在另一个窗口启动oprofile。当lic 结束时,我们停止oprofile。oprofile的启动和停止如清单10.4所示。

运行ltrace必定存在一点差异。在过滤器启动后,ltrace可以附加到运行中的进程上。与oprofile不同,ltrace附加到进程后会降低整个进程的速度。这会导致每个库的调用时间增加一些误差,但是它却提供了每个调用的次数信息。ltrace如清单10.5所示。
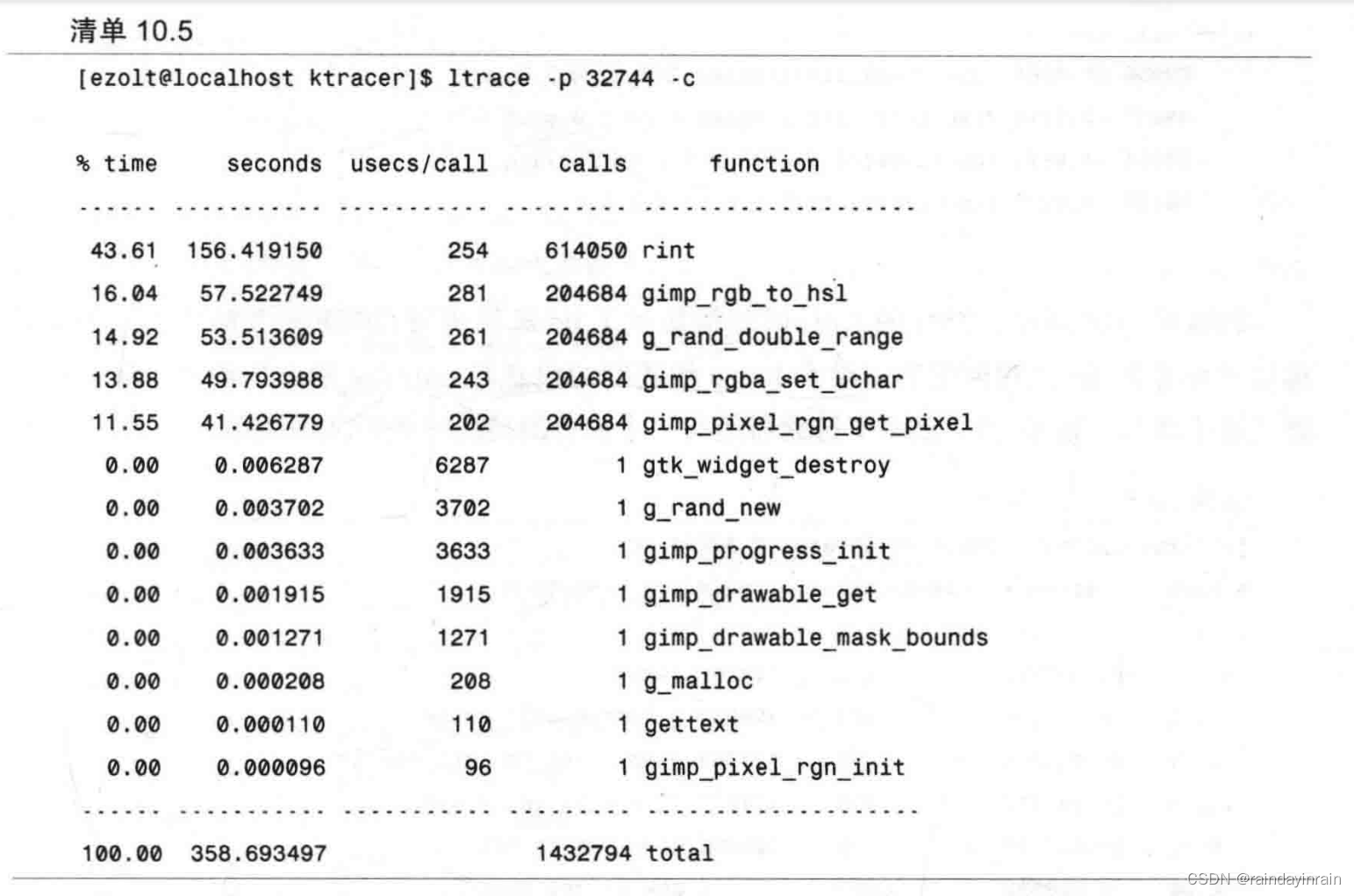
要获得库调用的全部数量,可以让ltrace持续运行直到完成。但是,这需要很多的时间,所以在这种情况下,经过一段较长时间后就按下组合键。这个方法不见得总是有效,原因在于应用程序可能会经历不同的执行阶段,如果停止时间过早,可能就无法得到应用程序调用函数的完整信息。不过,这个短小的样本至少是我们分析的起点。
10.7分析结果
既然我们已经利用oprofile收集到了过滤器运行的时间信息,现在就必须对结果进行分析,寻找改变其执行和提高其性能的方法。
首先,我们用oprofile查看整个系统是如何消耗时间的,结果如清单10.6所示。
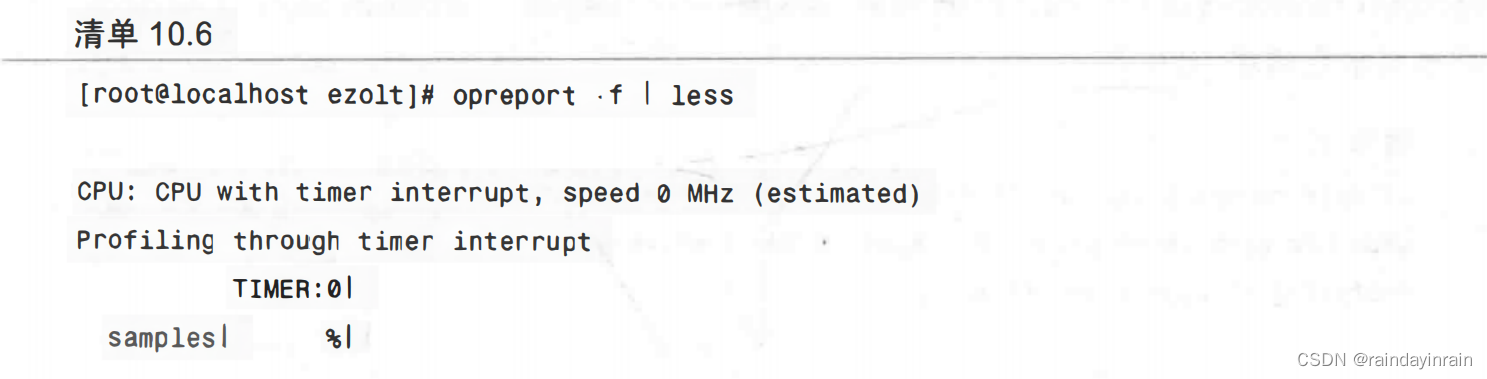
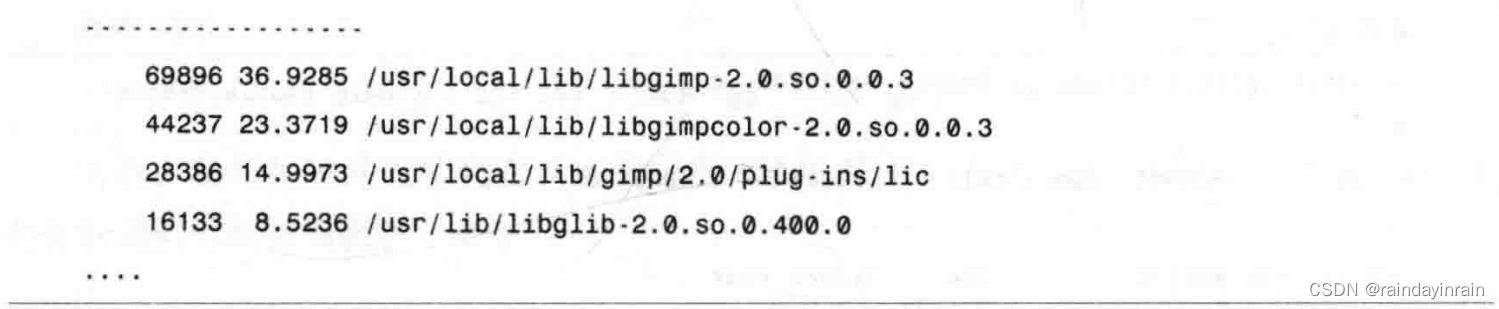
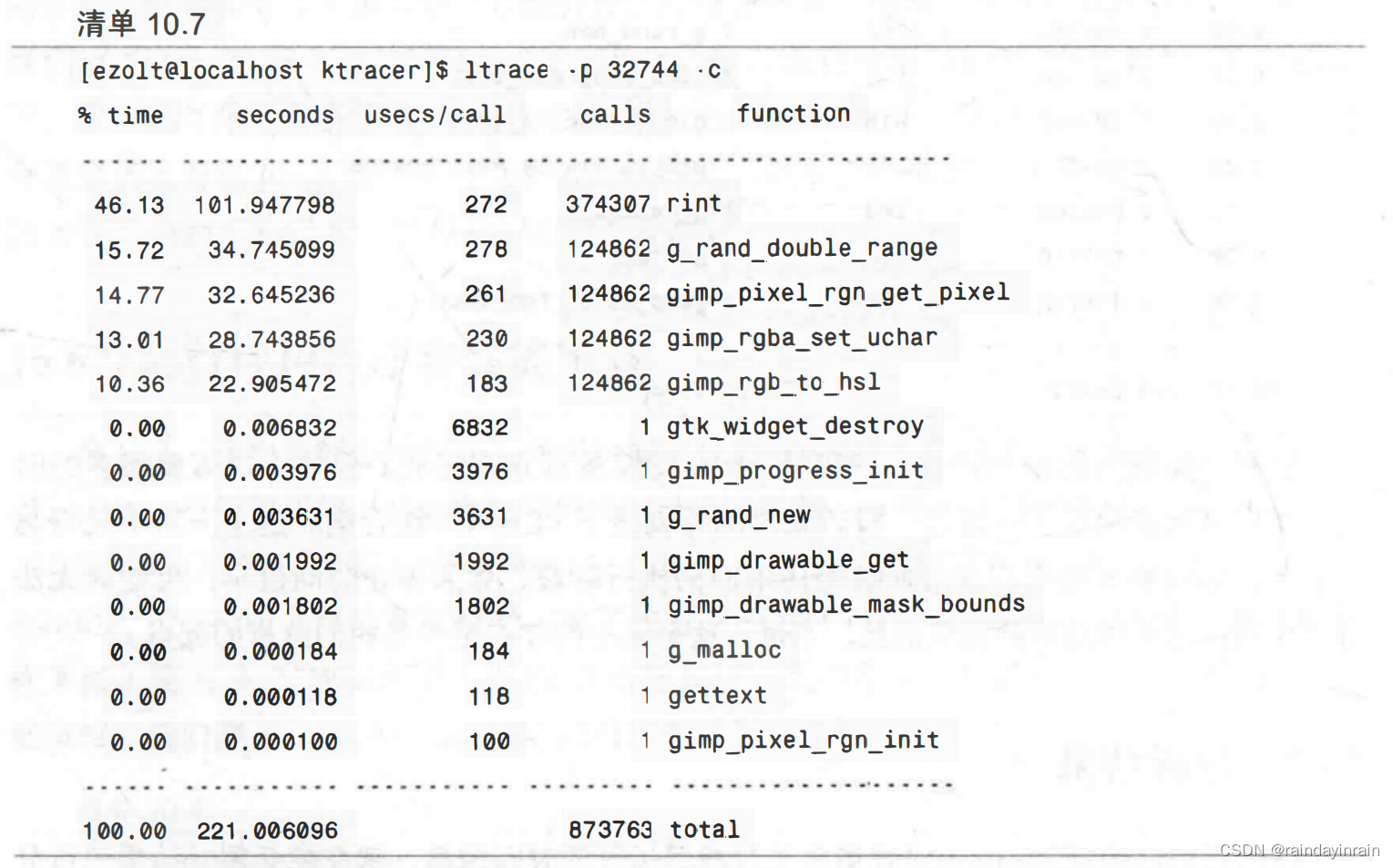
如清单10.6所示,75%的CPU时间消耗在了lic进程或与GIMP相关的库上。极有可能这些库是被lic进程调用的,结合ltrace给我们的信息与oprofile给出的信息,我们可以确认这个事实。清单10.7显示了过滤器运行一小部分的情况下进行的库调用。
接下来,我们要调查oprofile提供的关于每个库内部CPU时间消耗的信息,看看库中的热点函数是否与过滤器调用的那些一致。对于最占用CPU时间的前三个库,我们要求opreport提供库内每一个函数时间消耗的详细信息。libgimp、libgimp-color库和lic进程的结果显示在清单10.8中。


通过比较清单10.8中的ltrace输出和清单10.9中的oprofile输出可以得知:lic过滤器反复调用的库函数消耗了全部时间。
接下来,我们调查lic过滤器的源代码,确定它是如何构成的,它的热点函数究竟起了怎样的作用,以及过滤器是如何调用GIMP库函数的。生成大多数样本的lic函数是getpixel,如清单10.9中的opannotate输出所示。opannotate在源代码的左侧以列的形式依序显示了样本数量和所占样本总量百分比。这使你能查看源代码,精确定位哪些代码行是热点。


关于get_pixel函数还有一些有趣的事儿需要注意。首先,它调用gimp_bilinear_rgb函数,该函数是GIMP库中的一个热点函数。其次,它调用了peek函数4次。如果get_pixel 调用执行多次,那么peek函数执行的次数就是它的4倍。用opannotate查看peek函数(如清单10.10所示),可以看到它调用了gimp_pixel_rgn_get_pixel和gimp_rgba_set_uchar,它们分别是libgimp和libgimp-color的高级函数。

尽管不是很清楚究竟过滤器是干什么的或者库调用的作用是什么,还是有几个让人想去了解的要点。首先,peek的功能听起来像是从图像获取像素以便过滤器对它们进行处理。我们马上就可以验证这个预感。其次,过滤器中的大部分时间似乎并不是用于在图像数据上运行数学算法。并没有将所有CPU时间都用于根据像素数值进行计算,该过滤器好像花费了大部分时间来检索待处理的像素。如果真是这样,那么这一点也许能修复。
10.8转战网络
既然我们已经发现了大部分时间里用的是哪些GIMP函数,现在我们就必须弄清楚这些函数是什么,并尽可能优化它们的使用。首先,我们在Web上搜索pixel_rgn_get_pixel,并尝试明确它是做什么的。开始出错几次后,清单10.11给出的链接和信息证实了我们对pixel_rgn_get_pixel功能的猜测。

同时,清单10.12中的信息表明避免使用pixel_rgn_get_calls是个好主意。

此外,通过Web搜索找到函数的源代码,很方便地知道了gimp_rgb_set_uchar函数的信息。如清单10.13所示,该调用就是把呈现单一颜色的红色、绿色、蓝色值都放入GimpRGB结构中。

从Web收集的信息证实了我们的猜测:函数pixel_rgn_get_pixel是从图像抽取数据的一种方法,而函数gimp_rgb_set_uchar则仅仅获取从pixel_rgn_get_pixel返回的颜色数据,并将它们送入GimpRGB数据结构中。我们不但看到了如何使用这些函数,而且其他页面也暗示,如果我们想要过滤器的性能达到巅峰,那么这些函数可能不是最好的选择。其中一个网页(http://www.home.unix-ag,org/simon/gimp/guadec2002/gimp-plugin/html/efficientaccess.html)建议通过使用GIMP图像缓存有可能提高性能。另一个网站(http://gimp-plug-ins.sourceforge.net/doc/Writing/html/sect-tiles.html)则建议有可能通过重写过滤器使其更高效地访问图像数据来提高性能。
10.9增加图像缓存
网站解释GIMP以一种稍显怪诞的方式管理图像。与使用大的数组保存图像不同,GIMP将图像分解为一组分片,这些分片的宽度都是64×64。当过滤器想要访问图像中的一个特定像素时,GIMP就加载相应的分片,然后找到并返回该像素的值。每个检索特定像素的调用都可能会很慢。如果对每一个像素都重复这个过程,那么GIMP重载用于检索像素值的分片就会显著降低性能。幸运的是,GIMP提供了一种方法来缓存旧的分片值,每一次使用的是这个缓存值而不是重载分片。这将会提高性能。GIMP提供的缓存量可以用gimp_tile_cache_ntiles调用来控制。该调用当前在lic内部使用,并将缓存设置为图像分片数量的两倍。
即便这个缓存看上去够用了,GIMP可能还会需要更大的缓存。测试方式很简单,将缓存量增加到一个非常大的值,然后看看性能是否有所提升。因此,本例中,我们把缓存量增加到通常使用量的10倍。缓存值加大后,重新运行过滤器,检索时间为2分40秒。虽然所用时间减少了6秒,但是还是没有达到目标时间2分30秒。这表示我们必须从其他方面来提升性能。
10.10遇到(分片引发的)制约
除了使用分片缓存之外,网页提出了一种更好的方法来提高get_pixel的性能。通过直接访问像素信息(不调用gimp_pixel_rgn_get_pixel),可以显著提高像素访问的性能。
GIMP为过滤器编程者提供了一种直接访问图像分片的方法。之后过滤器就可以像访问一个数组一样访问图像数据,而不用请求对GIMP库的调用。但是,这里有个问题。当直接访问像素信息时,它只针对当前分片。因此,GIMP将遍历图像中的全部分片,以便你最终得到图像中的所有像素,可是你却无法同时访问它们。只能查看单个分片的像素,而这与lic访问数据的方式不相符。当lic过滤器在特定位置产生一个新的像素时,它是基于其周围像素的值来计算这个新值。所以,如果是在一个分片的边缘产生了新像素,lic 过滤器就需要其周围所有像素的数据。但是,这些像素可能是在图像的上一个分片上,也可能是在下一个分片上。由于该像素信息不可用,图像过滤器将不会使用这个优化的访问方法。
10.11解决问题
由于我们已经判定读取像素值很占时间,这里还有另一种方法可以解决这个问题。我们必须开始审视过滤器是如何运行的。在它生成新图像时,它会重复请求同一个像素。这是因为新像素的值是根据其周围像素的值得来的,因此,在对图像运行过滤器的过程中,每个像素会被其8个邻居像素访问。这就意味着图像中的每个像素都将被其每一个邻居像素读取,其结果就是它将被至少读取9次。
调用GIMP库的开销是很大的,所以我们只想对每个像素进行一次这样的操作,而不是9 次。对图像访问可能的优化是:过滤器启动时将整个图像读入一个本地数组,在过滤器运行期间就访问这个本地数组,而不是在每次想要访问数据时调用GIMP库函数。这个方法可以显著降低查找像素数据的开销。每次访问数据时不再进行几个函数调用,取而代之的是只访问本地数组。过滤器初始化时,用malloc分配该数组,并用像素数据进行填充。具体操作如清单10.14所示。

同时,函数peck也重新编写为只访问这个本地数组,而不再调用GIMP库函数。具体操作如清单10.15所示。

那么,有效果吗?当我们用新方法运行过滤器时,运行时间减少了56秒!刚好在目标时间范围2分30秒内,性能有明显提升。
虽然令人印象深刻,但是这个性能结果不是平白得来的。我们做的是性能工程中的一个经典取舍:用内存的增加换取了性能的提高。举个例子,如果过滤器使用的是一个1280×1024的图像,所需内存量将增加5MB。对于非常大的图像,缓存该数据可能是不实际的。但是,对于大小合理的图像,相较于过滤器两倍多速度的提高,5MB内存使用量的增加似乎是个不错的牺牲。
10.12 验证正确性
我们已经用一个优化明显降低了过滤器的运行时间,现在重要的是验证过滤器优化后和优化前产生的图像输出是相同的。加载了原来的参考图像后,将它与新生成的图像比较,这里使用了GIMP来获取两个图像之间的差异。如果参考图像和优化后图像是相同的,那么所有的像素都应该为零(黑色)。但是,差异图像并非是完全黑色的。从视觉上看,它像是黑色的,可仔细检查后(使用GIMP颜色选择器)发现有些像素是非零的。这就意味着参考图像与优化后图像存在差异。
通常这会引起关注,因为这可能表明该优化改变了过滤器的行为。但是,仔细检查过滤器源代码后显示,有几个地方的随机噪声在过滤器运行前就使得图像产生了轻微抖动。过滤器的任意两次运行都会有所不同,因此,很可能不应为此责备优化。由于两个图像之间的差异在视觉上如此微小,因此我们可以假设优化没有引入任何问题。
10.13 后续步骤
我们超额完成了lic过滤器性能增加10%的目标,因此就这点来说,我们已经完成了优化过程。但是,如果想要继续优化性能,就必须对使用新优化的过滤器进行重新分析。每一个性能优化应用后,重新分析应用程序,不依赖于之前的分析对应用程序的继续优化来说是非常重要的。每次优化后,应用程序的运行时行为可能发生显著变化。如果不在每次优化后进行分析,你就有可能承担继续追逐已不存在的性能问题的风险。
10.14本章小结
本章中,我们确定了为什么一个应用程序(GIMP过滤器lic)是受CPU限制的。我们计算出了该应用程序的基准运行时间,设置了一个优化目标,保存了一个参考图像以验证我们的优化没有改变应用程序的行为。我们使用了Linux CPU性能工具(oprofile和ltrace)调查究竟为什么该应用程序是受CPU限制的。然后依靠Web理解了该应用程序是如何工作的,并了解了对其不同的优化方法。我们尝试了几种不同的优化,但是最后还是选择了经典的性能权衡:增加内存使用量来降低CPU使用量。
我们达到了优化目标,之后还验证了优化并未改变应用程序的输出。
本章侧重于优化单个应用程序的运行时间,下一章的性能追踪则集中于减少与X Window交互时的延迟。降低延迟可能会非常棘手,因为单一事件通常会引发一组非显著性的其他事件。最困难的部分是找出被调用的事件有哪些,它们耗时多长。