一、Exporter结束
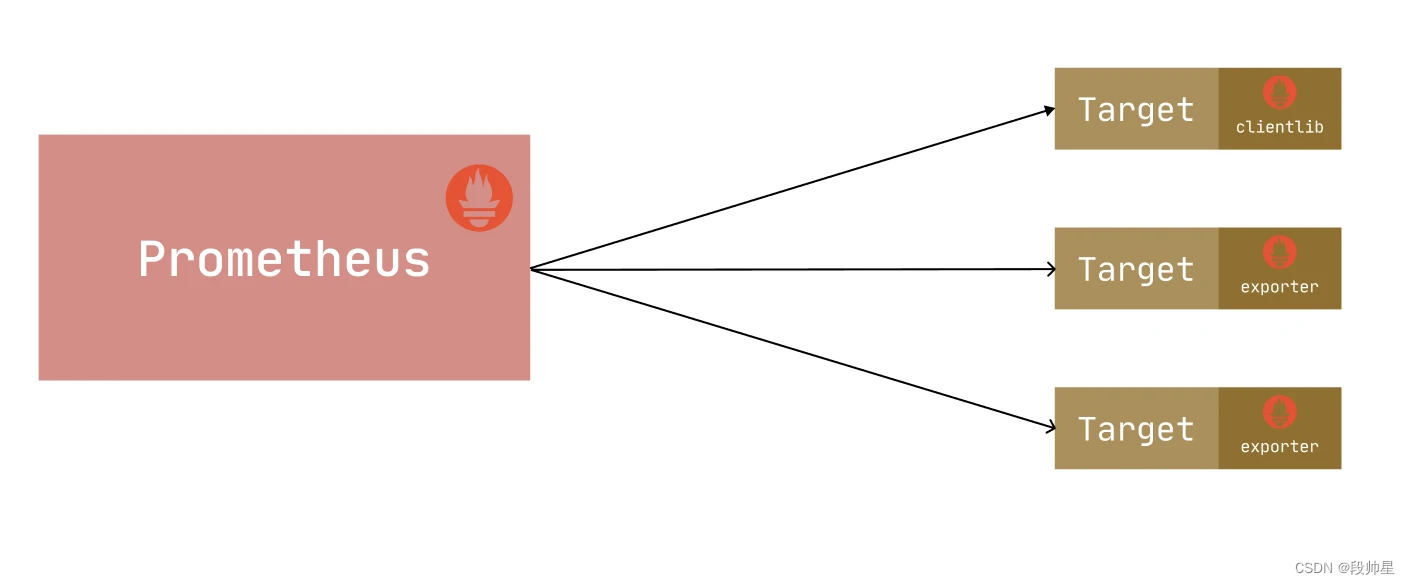
可以通过一个 metrics 接口为 Prometheus 提供监控指标,最好的方式就是直接在目标应用中集成该接口,但是有的应用并没有内置支持 metrics 接口,比如 linux 系统、mysql、redis、kafka 等应用,这种情况下就可以单独开发一个应用来专门提供 metrics 服务,这就是说的 Exporter,广义上讲所有可以向 Prometheus 提供监控样本数据的程序都可以被称为一个 Exporter,Exporter 的一个实例就是我们要监控的 target。
1、官方 Exporter
Prometheus 社区提供了丰富的 Exporter 实现,涵盖了从基础设施、中间件以及网络等各个方面的监控实现,当然社区也出现了很多其他的 Exporter,如果有必要,我们也可以完全根据自己的需求开发一个 Exporter,但是最好以官方的 Exporter 开发的最佳实践文档(https://prometheus.io/docs/instrumenting/writing_exporters/)作为参考实现方式,我们会在后续内容中介绍如何开发一个合格的 Exporter。官方提供的主要 Exporter 如下所示
- 数据库:Consul exporter、Memcached exporter、MySQL server exporter
- 硬件相关:Node/system metrics exporter
- HTTP:HAProxy exporter
- 其他监控系统:AWS CloudWatch exporter、Collectd exporter、Graphite exporter、InfluxDB exporter、JMX exporter、SNMP exporter、StatsD exporter、Blackbox exporter
由于 Exporter 是用于提供监控指标的独立服务,所以需要单独部署该服务来提供指标服务,比如 Node Exporter 就需要在操作系统上独立运行来收集系统的相关监控数据转换为 Prometheus 能够识别的 metrics 接口,接下来我们主要和大家来介绍几个比较常见的 Exporter 的使用。
二、Node Exporter
1、介绍:Node Exporter 是用于暴露 *NIX 主机指标的 Exporter,比如采集 CPU、内存、磁盘等信息。采用 Go 编写,不存在任何第三方依赖,所以只需要下载解压即可运行。
2、部署:由于 Node Exporter 是一个独立的二进制文件,可以直接从 Prometheus 下载页面 下载解压运行:
wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
tar -xf node_exporter-1.6.1.linux-amd64.tar.gz
cd node_exporter-1.6.1.linux-amd64/ && ls -la
./node_exporter
从日志上可以看出 node_exporter 监听在 9100 端口上,默认的 metrics 接口通过 /metrics 端点暴露,我们可以通过访问 http://localhost:9100/metrics 来获取监控指标数据:
该 metrics 接口数据就是一个标准的 Prometheus 监控指标格式,我们只需要将该端点配置到 Prometheus 中即可抓取该指标数据。为了了解 node_exporter 可配置的参数,我们可以使用 ./node_exporter -h 来查看帮助信息:
☸ ➜ ./node_exporter -h
--web.listen-address=":9100" # 监听的端口,默认是9100
--web.telemetry-path="/metrics" # metrics的路径,默认为/metrics
--web.disable-exporter-metrics # 是否禁用go、prome默认的metrics
--web.max-requests=40 # 最大并行请求数,默认40,设置为0时不限制
--log.level="info" # 日志等级: [debug, info, warn, error, fatal]
--log.format=logfmt # 置日志打印target和格式: [logfmt, json]
--version # 版本号
--collector.{metric-name} # 各个metric对应的参数
......
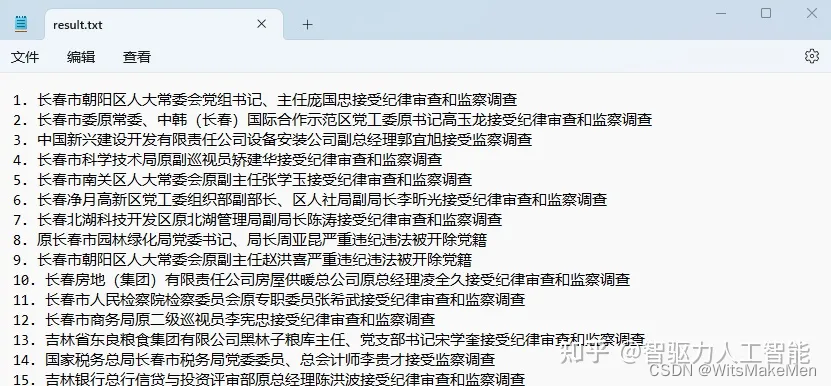
其中最重要的参数就是 --collector.,通过该参数可以启用我们收集的功能模块,node_exporter 会默认采集一些模块,要禁用这些默认启用的收集器可以通过 --no-collector. 标志来禁用,如果只启用某些特定的收集器,基于先使用 --collector.disable-defaults 标志禁用所有默认的,然后在通过指定具体的收集器 --collector. 来进行启用。下图列出了默认启用的收集器

3、systemd 管理
一般来说为了方便管理我们可以使用 docker 容器来运行 node_exporter,但是需要注意的是由于采集的是宿主机的指标信息,所以需要访问主机系统,如果使用 docker 容器来部署的话需要添加一些额外的参数来允许 node_exporter 访问宿主机的命名空间,如果直接在宿主机上运行的,我们可以用 systemd 来管理,创建一个如下所示的 service unit 文件:
cp -a node_exporter /usr/local/bin/
chmod + x /usr/local/bin/node_exporter
cat /etc/systemd/system/node_exporter.service
[Unit]
Description=node exporter service
Documentation=https://prometheus.io
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/bin/node_exporter # 有特殊需求的可以在后面指定参数配置
Restart=on-failure
[Install]
WantedBy=multi-user.target
systemctl daemon-reload && systemctl restart node_exporter && systemctl enable node_exporter && systemctl status node_exporter
4、添加到prometheus
systemd 的方式在两个节点上(node1、node2)分别启动 node_exporter,启动完成后我们使用静态配置的方式在之前的 Prometheus 配置中新增一个 node_exporter 的抓取任务,来采集这两个节点的监控指标数据,配置文件如下所示
global:
scrape_interval: 5s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'demo'
scrape_interval: 15s # 会覆盖global全局的配置
scrape_timeout: 10s
static_configs:
- targets: ['localhost:10000', 'localhost:10001', 'localhost:10002']
- job_name: 'node_exporter' # 新增 node_exporter 任务
static_configs:
- targets: ['node1:9100', 'node2:9100'] # node1、node2 在 hosts 中做了映射
上面配置文件最后新增了一个名为 node_exporter 的抓取任务,采集的目标使用静态配置的方式进行配置,然后重新加载 Prometheus,正常在 Prometheus 的 WebUI 的目标页面就可以看到上面配置的 node_exporter 任务了。
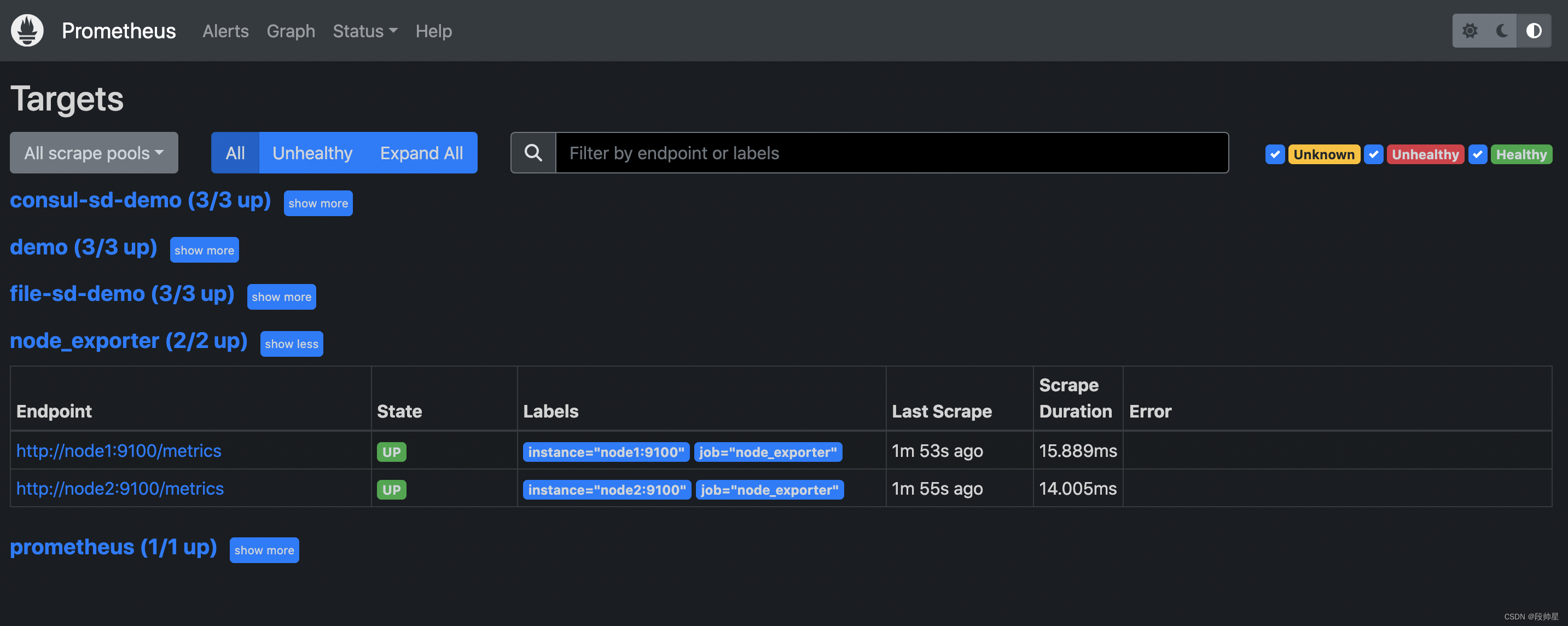
三、Node Exporter常用监控指标
1、CPU监控(需要用到 node_cpu_seconds_total 这个监控指标)
CPU 使用时间会分成几个不同的模式,比如用户态使用时间、空闲时间、中断时间、内核态使用时间等,metrics 接口中该指标内容如下所示:
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 7.65999227e+06
node_cpu_seconds_total{cpu="0",mode="iowait"} 3608.65
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 665.64
node_cpu_seconds_total{cpu="0",mode="softirq"} 12148.63
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 112622.4
node_cpu_seconds_total{cpu="0",mode="user"} 195728.73
要计算 CPU 的使用率,需要搞清楚这个使用率的含义,CPU 使用率是 CPU 除空闲(idle)状态之外的其他所有 CPU 状态的时间总和除以总的 CPU 时间得到的结果。要计算除空闲状态之外的 CPU 时间总和,更好的方式是不是直接计算空闲状态的 CPU 时间使用率,然后用 1 减掉就是我们想要的结果了,所以首先先过滤 idle 模式的指标,在 Prometheus 的 WebUI 中输入 node_cpu_seconds_total{mode=“idle”} 进行过滤:
node_cpu_seconds_total{mode="idle"}
要计算使用率,肯定就需要知道 idle 模式的 CPU 用了多长时间,然后和总的进行对比,由于这是 Counter 指标,我们可以用 increase 函数来获取变化,使用查询语句 ,因为 increase 函数要求输入一个区间向量,所以这里我们取 1 分钟内的数据:
increase(node_cpu_seconds_total{mode="idle"}[1m])
查询结果中有很多不同 cpu 序号的数据,我们当然需要计算所有 CPU 的时间,所以我们将它们聚合起来,我们要查询的是不同节点的 CPU 使用率,所以就需要根据 instance 标签进行聚合,使用查询语句
sum(increase(node_cpu_seconds_total{mode="idle"}[1m]))by(instance)
分别拿到不同节点 1 分钟内的空闲 CPU 使用时间了,然后和总的 CPU (这个时候不需要过滤状态模式)时间进行比较即可,使用查询语句
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)
然后计算 CPU 使用率就非常简单了,使用 1 减去乘以 100 即可
(1 - sum(rate(node_cpu_seconds_total{mode="idle"}[20m]))by(instance)/sum(rate(node_cpu_seconds_total[20m]))by(instance)) * 100
或者
(1 - sum(increase(node_cpu_seconds_total{mode="idle"}[20m]))by(instance)/sum(increase(node_cpu_seconds_total[20m]))by(instance)) * 100
2、内存监控
节点内存的监控了使用 free 命令查看
free -hm
total used free shared buff/cache available
Mem: 969Mi 415Mi 71Mi 2.0Mi 482Mi 378Mi
Swap: 0B 0B 0B
free 命令的输出会显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存等,所以要对内存进行监控我们需要先了解这些概念,我们先了解下 free 命令的输出内容:
- Mem 行(第二行)是内存的使用情况
- Swap 行(第三行)是交换空间的使用情况
- total 列显示系统总的可用物理内存和交换空间大小
- used 列显示已经被使用的物理内存和交换空间
- free 列显示还有多少物理内存和交换空间可用使用
- shared 列显示被共享使用的物理内存大小
- buff/cache 列显示被 buffer 和 cache 使用的物理内存大小
- available 列显示还可以被应用程序使用的物理内存大小
其中需要重点关注的 free 和 available 两列。free 是真正尚未被使用的物理内存数量,而 available 是从应用程序的角度看到的可用内存,Linux 内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据,就是 buffer 和 cache,所以对于内核来说,buffer 和 cache 都属于已经被使用的内存,只是应用程序需要内存时,如果没有足够的 free 内存可以用,内核就会从 buffer 和 cache 中回收内存来满足应用程序的请求。所以从应用程序的角度来说 available = free + buffer + cache,不过需要注意这只是一个理想的计算方式,实际中的数据有较大的误差。
如果要在 Prometheus 中来查询内存使用,则可以用 node_memory_* 相关指标,同样的要计算使用的,我们可以计算可使用的内存,使用 promql 查询语句
(1-(node_memory_Buffers_bytes + node_memory_Cached_bytes + node_memory_MemFree_bytes)/node_memory_MemTotal_bytes)*100
3、磁盘监控: (需要用到 node_filesystem_* 相关的指标)
1>磁盘容量监控
要监控磁盘容量,需要用到 node_filesystem_* 相关的指标,比如要查询节点磁盘空间使用率,则可以同样用总的减去可用的来进行计算,磁盘可用空间使用 node_filesystem_avail_bytes 指标,但是由于会有一些我们不关心的磁盘信息,所以我们可以使用 fstype 标签过滤关心的磁盘信息,比如 ext4 或者 xfs 格式的磁盘:
node_filesystem_avail_bytes{fstype=~"ext4|xfs"}
2>查询磁盘空间使用率
(1 - node_filesystem_avail_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"}) * 100