前言
Redis 为了提高内存效率,设计了一种特殊的数据结构 ziplist(压缩列表)。ziplist 本质是一段字节数组,采用了一种紧凑的、连续存储的格式,可以有效地压缩数据,提高内存效率。
hash、zset 在数据量比较小时,会优先用 ziplist 存储数据,否则会分配大量指针,指针本身会占用空间,而且会增加内存的碎片化率。以 hash 为例,可以通过下列配置当 Entry 数量小于 512,且 数据长度小于 64 时使用压缩列表存储,否则采用 哈希表 存储。
hash-max-ziplist-entries=512
hash-max-ziplist-value=64
ZipList
ziplist 的优点:
- 内存效率高,无需额外分配指针,数据紧凑的存储在一起
- 高效的顺序访问,因为是一块连续的内存空间
- 减少内存碎片
当然,ziplist 也有一些缺点,否则也不会数据量大了以后,Redis 就放弃它了。
- 查找时间复杂度 O(N)
- 内存重分配,ziplist 长度是固定的,无法动态扩展,只能重新申请一块内存
- 连锁更新的问题
ziplist 的缺点还是很明显的,但是不能因为它有缺点就不用它,在数据量小,写入操作不多的时候,它确实可以节省内存。根据数据的特点使用不同的数据结构来存储,不正是 Redis 的设计哲学吗?
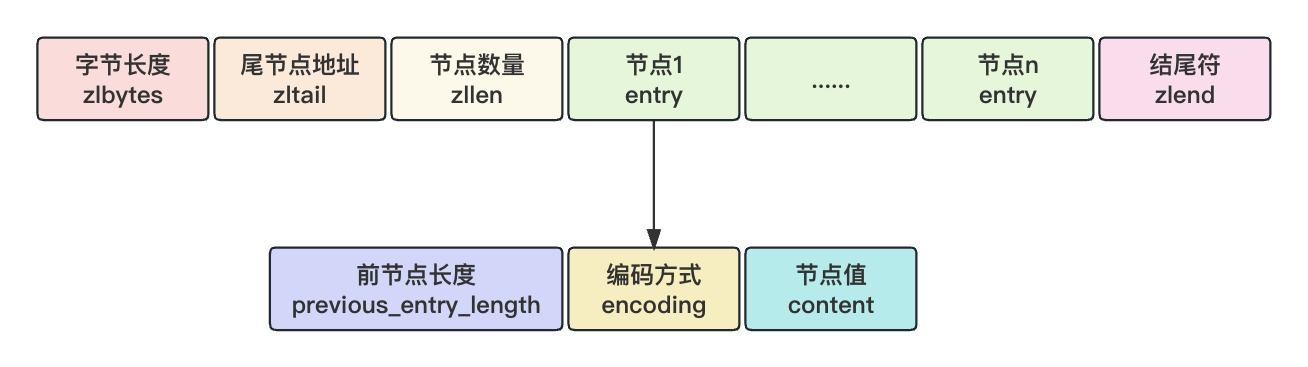
源码里对 ziplist 的布局描述如下,所有数据都是紧凑排列的:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
| 属性 | 类型 | 长度 | 描述 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | ziplist 占用字节数 |
| zltail | uint32_t | 4 字节 | 尾节点距离起始地址的距离 |
| zllen | uint16_t | 2 字节 | 节点数量 |
| entry | 变长 | 节点 | |
| zlend | uint8_t | 1 字节 | 结尾符 0xff |
因为记录了尾节点的位置,所以 ziplist 在查找头尾节点时很快就能找到,但是对于中间节点就需要遍历了。
Entry 代表 ziplist 里的元素,由三部分组成:
<previous_entry_length> <encoding> <content>
- previous_entry_length:前一个 Entry 的长度,采用变长设计,占用 1 或 5 字节。如果前一个 Entry 长度小于 254 就用 1 字节存储,否则用 5 字节存储
- encoding:数据的编码类型,记录了数据的类型和长度。高位 1 开头代表是数字,高位 0 开头代表是字节数组
- content:存储节点的值
Redis 会根据值的类型来编码 encoding 和 content,举例:
- encoding 1111 开头,后 4 位表示整型值,没有 content 部分
- encoding 11111110 开头,代表 content 存储的是 8 位整型值
- encoding 11000000 开头,代表 content 存储的是 16 位整型值
- encoding 00 开头,后 6 位表示长度,content 是一个最大长度 63 的字节数组
- encoding 01 开头,后 6 位 + 1 字节表示长度,content 是一个最大长度 2^14-1 的字节数组
- …
Redis 定义了 encoding 的各种类型:
/* Different encoding/length possibilities */
#define ZIP_STR_MASK 0xc0
#define ZIP_INT_MASK 0x30
#define ZIP_STR_06B (0 << 6)
#define ZIP_STR_14B (1 << 6)
#define ZIP_STR_32B (2 << 6)
#define ZIP_INT_16B (0xc0 | 0<<4)
#define ZIP_INT_32B (0xc0 | 1<<4)
#define ZIP_INT_64B (0xc0 | 2<<4)
#define ZIP_INT_24B (0xc0 | 3<<4)
#define ZIP_INT_8B 0xfe
源码
ziplist 对应的源码文件是src/ziplist.c和src/ziplist.h。
- ziplistNew
创建一个空的 ziplist,因为本质是字节数组,所以没有结构体,返回的是一个指针。
unsigned char *ziplistNew(void) {
// ziplist空间 header(4+4+2)+end(1)
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
// 分配内存
unsigned char *zl = zmalloc(bytes);
// 写入总长度
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
// 写入zltail 因为还没元素,指向header结束位置
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
// 写入zllen=0
ZIPLIST_LENGTH(zl) = 0;
// 写入结尾符
zl[bytes-1] = ZIP_END;
return zl;
}
- zlentry
Redis 定义了结构体 zlentry 来承载节点 Entry 数据,但这不代表 Entry 数据实际的存储方式。
typedef struct zlentry {
unsigned int prevrawlensize; // 记录前一个节点长度占用的字节数 1或5
unsigned int prevrawlen; // 前一个节点的长度
unsigned int lensize; // 当前节点的长度占用的字节数 1或5
unsigned int len; // 当前节点的长度
unsigned int headersize; // 节点头部长度
unsigned char encoding; // 编码方式 整形/字符串
unsigned char *p; // 存储值的指针
} zlentry;
- zipEntry
zlentry 结构比较复杂,Redis 提供了 zipEntry()方法对其编码:
static inline void zipEntry(unsigned char *p, zlentry *e) {
// 解码前节点长度
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);
// 设置编码方式
ZIP_ENTRY_ENCODING(p + e->prevrawlensize, e->encoding);
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);
assert(e->lensize != 0);
e->headersize = e->prevrawlensize + e->lensize;
e->p = p;
}
- ziplistPush
用来向 ziplist 头部或尾部插入新的节点。
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {
unsigned char *p;
// 判断向头部还是尾部插入
p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);
return __ziplistInsert(zl,p,s,slen);
}
- __ziplistInsert
向 ziplist 指定位置插入新的节点,主要步骤:
- 对元素的内容进行编码
- 重新申请一块内存空间
- 数据拷贝
/**
* ziplist插入节点
* @param zl ziplist指针
* @param p 插入的位置 p的前面
* @param s 内容
* @param slen 长度
* @return
*/
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen, newlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789;
zlentry tail;
if (p[0] != ZIP_END) { // 压缩列表不为空,根据p查找要插入的位置
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen); // 解码 prevlen 长度
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLengthSafe(zl, curlen, ptail);
}
}
// 尝试编码为整型,如果失败则直接保存字符数组
if (zipTryEncoding(s,slen,&value,&encoding)) {
reqlen = zipIntSize(encoding);
} else {
reqlen = slen;
}
// reqlen代表当前节点长度 = 前置节点长度+encoding长度+content长度
reqlen += zipStorePrevEntryLength(NULL,prevlen);
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
offset = p-zl;
newlen = curlen+reqlen+nextdiff;
zl = ziplistResize(zl,newlen);
p = zl+offset;
if (p[0] != ZIP_END) {
/* Subtract one because of the ZIP_END bytes */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
if (forcelarge)
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
assert(zipEntrySafe(zl, newlen, p+reqlen, &tail, 1));
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
// 更新 zllen 字段
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
通过源码发现,ziplist 插入元素的开销还是很大的,其实删除和更新也是一样,因为数据是紧密排列的,一旦要写入新数据,或者更新后的数据比之前大,就会出现没有存储空间的尴尬局面,此时不得不重新分配一块新的内存空间。
- ziplistFind
ziplist 元素的查找,时间复杂度是 O(N),从头到尾遍历元素对比,直到遇到结尾符。
unsigned char *ziplistFind(unsigned char *zl, unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip) {
int skipcnt = 0;
unsigned char vencoding = 0;
long long vll = 0;
size_t zlbytes = ziplistBlobLen(zl);
while (p[0] != ZIP_END) { // 从头到尾遍历,直到遇到结尾符
struct zlentry e;
unsigned char *q;
assert(zipEntrySafe(zl, zlbytes, p, &e, 1));
q = p + e.prevrawlensize + e.lensize;
if (skipcnt == 0) {
if (ZIP_IS_STR(e.encoding)) {
// 字符串的比较方法,逐个字符对比
if (e.len == vlen && memcmp(q, vstr, vlen) == 0) {
return p;
}
} else {
// 整型的比较
if (vencoding == 0) {
if (!zipTryEncoding(vstr, vlen, &vll, &vencoding)) {
vencoding = UCHAR_MAX;
}
assert(vencoding);
}
if (vencoding != UCHAR_MAX) {
long long ll = zipLoadInteger(q, e.encoding);
if (ll == vll) {
return p;
}
}
}
skipcnt = skip;
} else {
skipcnt--;
}
// 移动到下一个节点
p = q + e.len;
}
return NULL;
}
连锁更新
除了增删改的开销大外,ziplist 还有一个风险点,就是连锁更新。
假设现在 ziplist 存储了 100 个元素,长度都是 253,此时每个元素刚好都可以用 1 字节来存储前一个元素的大小,大家相安无事。这个时候,突然有一个更新操作,把表头的数据长度给改了,超过了254。此时影响就不只是它自己了,因为它的长度超过了254,导致它的后一个元素不能再用 1 字节存储长度了,而要改成 5 字节,后一个元素改成 5 字节存储前一个元素的长度后,又导致自己的长度超了 254,又会导致 后后一个元素要使用 5 字节来存储它的长度,以此类推,产生连锁反应。
连锁更新带来的影响非常大,不过好在发生的概率不高。
尾巴
Redis 为了提高内存效率,当 hash、list、zset 存储的数据量较小时,会优先使用一个叫 ziplist 的数据结构存储数据。它本质是一个字节数组,把所有元素按照特定的编码格式编码后紧凑的排列在一起,提高内存效率。缺点是数据更新需要重新分配内存。
总体而言,ziplist 适用于存储较小的有序集合或哈希表数据。但对于大型数据、需要频繁扩展或需要高效迭代的情况,常规的有序集合或哈希表可能更合适。在使用ziplist时,需要权衡利弊,并根据实际需求选择合适的数据结构。