1、Java的SPI机制
SPI的全称是Service Provider Interface,是JDK内置的动态加载实现扩展点的机制,通过SPI可以动态获取接口的实现类,属于一种设计理念。
系统设计的各个抽象,往往有很多不同的实现方案,在面向的对象的设计里,一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。如果代码中引用了特定的实现类,那么就违反了可插拔的原则。为了进行实现的替换,需要对代码进行修改。需要一种服务发现机制,以实现在模块装配时无需在程序中动态指定。最常见的使用案例有JDBC、Dubbo和Spring。
笔者在代码中最常用的就是将策略设计模式+SPI进行组合,不直接对接口的实现类进行代码的硬编,可以根据业务的实际使用选择对应的实现类。
SPI由三个组件构成,Service、Service Provider以及ServiceLoader,下面是一个简单例子:
// 1、使用SPI时先定义好接口
package com.theone.feather
public interface SendService {
String say();
}
// 2、创建实现类
package com.theone.feather;
public class HelloSendService implements SendService {
@Override
public String say() {
return "Hello SPI";
}
}
// 3、在classpath下创建META-INF/services目录,添加文件com.theone.feather.SendService
// 文件名要和接口全路径一样, 里面内容填写实现类的全路径,每个路径各占一行
// 4、通过ServiceLoader调用
@SpringBootApplication
public class TheOneApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication.run(TheOneApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
ServiceLoader<SendService> loader = ServiceLoader.load(SendService.class);
for(SendService sendService : loader) {
System.out.println(sendService.say());
}
}
}从例子也可以看出,传统的SPI迭代时会遍历所有的实现,需要定制化能够做到根据条件自动加载某个实现。
2、Dubbo的SPI机制
在聊Dubbo的SPI机制的时候,需要说下开闭原则,开闭原则就是指对扩展开放,修改关闭,尽量通过扩展软件的模块、类、方法,来实现功能的变化,而不是通过修改已有的代码来完成。这样做就可以大大降低因为修改代码而给程序带来的出错率。
对于Dubbo而言,涉及到服务的RPC调用以及服务治理相关的功能需要抽象出来,而对于具体的实现开放出来,由用户去根据自身业务需要随意扩展(例如下图中各个功能的扩展)。

所以在Dubbo中,会经常看到下面的逻辑,分别是自适应扩展点、指定名称的扩展点、激活扩展点
ExtensionLoader.getExtensionLoader(xxx.class).getAdaptiveExtension();
ExtensionLoader.getExtensionLoader(xxx.class).getExtension(name);
ExtensionLoader.getExtensionLoader(xxx.class).getActivateExtension(url, key);比如在Protocol的获取中,会有
Protocol protocol = ExtensionLoader
.getExtensionLoader(Protocol.class)
.getAdaptiveExtension();
Dubbo根据你的相关配置,找到具体的Protocol实现类,并实例化具体的对象。所以总结来说,Extension就是指某个功能的扩展实现,可能是Dubbo自带的,也可能是业务自己实现的。
正常来说,我们用SPI都是把接口的实现的全路径写在文件里面,解析出来之后再通过反射的方式去实例化这个类,然后将这个类放在集合里面存储起来。Dubbo也是这样的操作,而且它还是实现了IOC和AOP的功能。IOC 就是说如果这个扩展类依赖其他属性,Dubbo 会自动的将这个属性进行注入。这个功能如何实现了?一个常见思路是获取这个扩展类的 setter 方法,调用 setter 方法进行属性注入。AOP 指的是什么了?这个说的是 Dubbo 能够为扩展类注入其包装类。比如 DubboProtocol 是 Protocol 的扩展类,ProtocolListenerWrapper 是 DubboProtocol 的包装类。
下文介绍时,每个功能会用扩展点指代,而对应的实现则是扩展来指代。
3、Dubbo SPI的实现
在了解Dubbo的SPI机制之前,有几个注解我们要先了解下
3.1、@SPI注解
@SPI注解用于标记一个扩展点接口,该注解提供了扩展点的默认实现已经作用域。
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface SPI {
/**
* 默认扩展点实现名
*/
String value() default "";
/**
* 扩展点的作用域
*/
ExtensionScope scope() default ExtensionScope.APPLICATION;
}
Dubbo的除了和java原生的spi一样,文件名是接口名之外,内容上支持两种类型的格式
// 第一种格式和Java的SPI一样
com.foo.XxxProtocol
com.foo.YyyProtocol
// 第二种支持key-value的形式,其中key是扩展点实现的名称
xxx=com.foo.XxxProtocol
yyy=com.foo.YyyProtocol
zzz,default=com.foo.ZzzProtocol3.2、@Activate注解
@Activate的作用是用于特定条件下的激活,用户通过group和value配置激活条件,@Activate标记的扩展点实现在满足某个条件时会被会激活并且实例化。也就是自适应扩展类的使用场景,比如我们有需求,在调用某一个方法时,基于参数选择调用到不同的实现类。和工厂方法有些类似,基于不同的参数,构造出不同的实例对象。 在 Dubbo 中实现的思路和这个差不多,不过 Dubbo 的实现更加灵活,它的实现和策略模式有些类似。每一种扩展类相当于一种策略,基于 URL 消息总线,将参数传递给 ExtensionLoader,通过 ExtensionLoader 基于参数加载对应的扩展类,实现运行时动态调用到目标实例上。
3.3、ExtensionAccessor
扩展访问的最基本类型是ExtensionAccessor,它提供了Extension的默认获取实现(由接口的default方法指定)

public interface ExtensionAccessor {
// ExtensionDirector继承自ExtensionAccessor, ExtensionAccessor反过来
// 又从ExtensionDirector获取ExtensionLoader
ExtensionDirector getExtensionDirector();
default <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
return this.getExtensionDirector().getExtensionLoader(type);
}
default <T> T getExtension(Class<T> type, String name) {
ExtensionLoader<T> extensionLoader = getExtensionLoader(type);
return extensionLoader != null ? extensionLoader.getExtension(name) : null;
}
default <T> T getAdaptiveExtension(Class<T> type) {
ExtensionLoader<T> extensionLoader = getExtensionLoader(type);
return extensionLoader != null ? extensionLoader.getAdaptiveExtension() : null;
}
default <T> T getDefaultExtension(Class<T> type) {
ExtensionLoader<T> extensionLoader = getExtensionLoader(type);
return extensionLoader != null ? extensionLoader.getDefaultExtension() : null;
}
}上面的ExtensionAccessor塞入ExtensionDirector的方式,应该是用了代理设计模式提供了默认的实现。ExtensionAccessor提供了接口的同时,也充当着Proxy的角色,default关键字使得这种方式得以实现。
3.4、ExtensionDirector
ExtensionAccessor会将请求交给子类ExtensionDirector去处理,ExtensionDirector是一个带有作用域的扩展访问器,这一点从它带有属性ScopeModel可以看出
public ExtensionDirector(ExtensionDirector parent, ExtensionScope scope, ScopeModel scopeModel) {
// 这里传入了父ExtensionDirector,类似java的双亲委派机制
this.parent = parent;
// 传递作用域ExtensionScope和ScopeModel
this.scope = scope;
this.scopeModel = scopeModel;
}从ExtensionAccessor调用ExtensionDirector的逻辑可以看到,ExtensionDirector会将扩展交给内部的ExtensionLoader去处理
public <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
checkDestroyed();
if (type == null) {
throw new IllegalArgumentException("Extension type == null");
}
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!");
}
if (!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type (" + type +
") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!");
}
// 1. find in local cache
// 根据传递的类型从本地缓存中获取
ExtensionLoader<T> loader = (ExtensionLoader<T>) extensionLoadersMap.get(type);
ExtensionScope scope = extensionScopeMap.get(type);
// 如果扩展的作用域在本地缓存为空,则通过注解@SPI尝试去获取
if (scope == null) {
SPI annotation = type.getAnnotation(SPI.class);
scope = annotation.scope();
extensionScopeMap.put(type, scope);
}
// 对于第一次获取的类型,可能loader为空,如果作用域是仅限自我访问
// 这时就需要创建一个针对该类型的extensionLoader
if (loader == null && scope == ExtensionScope.SELF) {
// create an instance in self scope
loader = createExtensionLoader0(type);
}
// 2. find in parent
// 这里用到了构造函数时传入进来的ExtensionDirector,如果本地找不到就去parent查找
if (loader == null) {
if (this.parent != null) {
loader = this.parent.getExtensionLoader(type);
}
}
// 3. create it
// 创建针对该类的extensionLoader,注意这里是在上面获取parent之后
// 所以正常是如果parent不为null的情况,这里是和java的双亲委派机制一样的
// 有父ExtensionDirector去创建ExtensionLoader并且放在父ExtensionDirector的本地缓存中
// 查找时先查找自己本地缓存,如果找不到再去父ExtensionDirector去查找
if (loader == null) {
loader = createExtensionLoader(type);
}
return loader;
}ExtensionDirector获取ExtensionLoader的方式参考了Java的双亲委派机制,如果本地缓存中查找不到Class对应的ExtensionLoader,则是去父ExtensionDirector中查找。如果ExtensionDirector不为空,且Scope不是SELF,则由父ExtensionDirector去负责创建针对该扩展点类型的ExtensionLoader。
这里也可以看出每一个扩展点对应一个ExtensionLoader。
前面提到了ExtensionDirector是带有作用域ScopeModel的访问器,这点在创建ExtensionLoader中有所体现
private <T> ExtensionLoader<T> createExtensionLoader(Class<T> type) {
ExtensionLoader<T> loader = null;
// 检查扩展点的ScopeModel是否和ExtensionDirector的ScopeMode是否一致
if (isScopeMatched(type)) {
// if scope is matched, just create it
loader = createExtensionLoader0(type);
}
return loader;
}
private <T> ExtensionLoader<T> createExtensionLoader0(Class<T> type) {
checkDestroyed();
ExtensionLoader<T> loader;
extensionLoadersMap.putIfAbsent(type, new ExtensionLoader<T>(type, this, scopeModel));
loader = (ExtensionLoader<T>) extensionLoadersMap.get(type);
return loader;
}
private boolean isScopeMatched(Class<?> type) {
// 通过注解@SPI获取当前扩展点的作用域
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
return defaultAnnotation.scope().equals(scope);
}上面逻辑的意思是,只有同个作用域的扩展点,才能被ExtensionDirector访问并且创建。但是在getExtensionLoader的时候可以看到,对于本地缓存没有的ExtensionLoader,是可以去父类中查找并返回的,也就是说父ExtensionDirector可以和子ExtensionDirector存在不一样的Scope,甚至比子ExtensionDirector更高的作用域。
3.5、ExtensionLoader
类似ClassLoader的作用,整个扩展机制的主要逻辑部分,其提供了配置的加载、缓存扩展类以及对象生成的工作。
ExtensionLoader的主要入口是通过三个方法调用,分别是getExtension,getAdaptiveExtensionClass以及getActivateExtension三个方法。
3.5.1、getExtension
要记住一点是ExtensionLoader的每个实例只用于一个type,所以在初始化的时候会指定当前ExtensionLoader所能处理的type。
ExtensionLoader(Class<?> type, ExtensionDirector extensionDirector, ScopeModel scopeModel) {
// 每一个ExtensionLoader对应一个type
this.type = type;
...getExtension是最常用的方法,一般是通过指定name获取文件中对应的实现(name=com.xxx)。
public T getExtension(String name) {
T extension = getExtension(name, true);
if (extension == null) {
throw new IllegalArgumentException("Not find extension: " + name);
}
return extension;
}
public T getExtension(String name, boolean wrap) {
checkDestroyed();
if (StringUtils.isEmpty(name)) {
throw new IllegalArgumentException("Extension name == null");
}
// 如果传递的name为true,则返回默认的扩展点实现
if ("true".equals(name)) {
return getDefaultExtension();
}
String cacheKey = name;
if (!wrap) {
cacheKey += "_origin";
}
// ExtensionLoader也会缓存类型的具体实现,类似Spring那样的bean单例模式
final Holder<Object> holder = getOrCreateHolder(cacheKey);
Object instance = holder.get();
if (instance == null) {
// 这里用Holder,而不是直接用具体扩展点实现的对象的原因是为了避免这里的锁冲突
// 一个具体的扩展点实现对应一个Holder,这样不同的实现类在创建的时候,由于
// holder的不同,synchronized就不是锁同一个对象,这样并发的时候减少锁冲突的作用
// 这里也还常见的volatile、双重检查创建单例模式的写法
// 我想想这里为啥用holder,其实holder就是给name对应类型的一个锁,每个name各自有一个
// 如果不这么做的话,就必须得有外部一个全局的对象去避免创建对象的线程安全问题
// 这样的话会造成并发创建慢
synchronized (holder) {
instance = holder.get();
if (instance == null) {
instance = createExtension(name, wrap);
holder.set(instance);
}
}
}
return (T) instance;
}当然Dubbo肯定是懒加载的机制,不会一口气把所有的扩展点实现都实例化,只有用到的时候再去创建实力(当时类还是会加载的)。这里createExtension可以根据具体的name找到并实例化extension。
private T createExtension(String name, boolean wrap) {
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null || unacceptableExceptions.contains(name)) {
throw findException(name);
}
try {
// extensionInstances是缓存的对应类型的实例化对象,这里应该是每个类型一个对象的单例模式
T instance = (T) extensionInstances.get(clazz);
if (instance == null) {
// createExtensionInstance负责初始化对象
extensionInstances.putIfAbsent(clazz, createExtensionInstance(clazz));
instance = (T) extensionInstances.get(clazz);、
// 这里的postBefore和postAfter应该是类似实例前后的埋点操作
instance = postProcessBeforeInitialization(instance, name);
injectExtension(instance);
instance = postProcessAfterInitialization(instance, name);
}
// wrap是是否包装的意思,类似AOP
if (wrap) {
List<Class<?>> wrapperClassesList = new ArrayList<>();
if (cachedWrapperClasses != null) {
wrapperClassesList.addAll(cachedWrapperClasses);
wrapperClassesList.sort(WrapperComparator.COMPARATOR);
Collections.reverse(wrapperClassesList);
}
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
for (Class<?> wrapperClass : wrapperClassesList) {
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
boolean match = (wrapper == null) || ((ArrayUtils.isEmpty(
wrapper.matches()) || ArrayUtils.contains(wrapper.matches(),
name)) && !ArrayUtils.contains(wrapper.mismatches(), name));
if (match) {
// 将新生成的实例注入到wrapper中,不过Wrapper类必须构造函数要有可以加入代理的属性
instance = injectExtension(
(T) wrapperClass.getConstructor(type).newInstance(instance));
instance = postProcessAfterInitialization(instance, name);
}
}
}
}
// Warning: After an instance of Lifecycle is wrapped by cachedWrapperClasses, it may not still be Lifecycle instance, this application may not invoke the lifecycle.initialize hook.
initExtension(instance);
return instance;
} catch (Throwable t) {
throw new IllegalStateException(
"Extension instance (name: " + name + ", class: " + type + ") couldn't be instantiated: " + t.getMessage(),
t);
}
}第一次实例化的时候,扩展点实现的信息全部为空,这时需要第一次扫描下文件的内容以及缓存到内存中,其中第一步就是获取文件内的扩展点实现的全路径。
private Map<String, Class<?>> getExtensionClasses() {
// cachedClasses指缓存文件中的扩展点实现已经对应的名字name
Map<String, Class<?>> classes = cachedClasses.get();
if (classes == null) {
synchronized (cachedClasses) {
// 再次获取避免等锁的时候有其他线程获取了
classes = cachedClasses.get();
if (classes == null) {
try {
// 第一次获取时为空,所以遍历文件查询
classes = loadExtensionClasses();
} catch (InterruptedException e) {
logger.error(COMMON_ERROR_LOAD_EXTENSION, "", "",
"Exception occurred when loading extension class (interface: " + type + ")",
e);
throw new IllegalStateException(
"Exception occurred when loading extension class (interface: " + type + ")",
e);
}
cachedClasses.set(classes);
}
}
}
return classes;
}
private Map<String, Class<?>> loadExtensionClasses() throws InterruptedException {
checkDestroyed();
// 缓存默认的扩展点实现,这里@SPI注解可以指定
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
// 分别通过三个不同优先级的扩展点实现获取地方加载
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy, type.getName());
// compatible with old ExtensionFactory
if (this.type == ExtensionInjector.class) {
loadDirectory(extensionClasses, strategy, ExtensionFactory.class.getName());
}
}
return extensionClasses;
}
private void cacheDefaultExtensionName() {
// 用于获取接口中的@SPI注解
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation == null) {
return;
}
// 这里的value是获取@SPI的value值,表示默认扩展点名
String value = defaultAnnotation.value();
if ((value = value.trim()).length() > 0) {
// 默认的扩展点实现不能有多个
String[] names = NAME_SEPARATOR.split(value);
if (names.length > 1) {
throw new IllegalStateException(
"More than 1 default extension name on extension " + type.getName() + ": " + Arrays.toString(
names));
}
if (names.length == 1) {
cachedDefaultName = names[0];
}
}
}Dubbo有三个不同优先级的扩展点实现的加载机制,也就是去哪些目录扫描扩展点实现的地方,通过LoadingStrategy表示。按优先级大小排序的话分别是
DubboInternalLoadingStrategy(META-INF/dubbo/internal/) > DubboLoadingStrategy(META-INF/dubbo/) > ServicesLoadingStrategy(META-INF/services/) private void loadDirectory(Map<String, Class<?>> extensionClasses, LoadingStrategy strategy,
String type) throws InterruptedException {
loadDirectoryInternal(extensionClasses, strategy, type);
try {
String oldType = type.replace("org.apache", "com.alibaba");
if (oldType.equals(type)) {
return;
}
//if class not found,skip try to load resources
ClassUtils.forName(oldType);
loadDirectoryInternal(extensionClasses, strategy, oldType);
} catch (ClassNotFoundException classNotFoundException) {
}
}
private void loadDirectoryInternal(Map<String, Class<?>> extensionClasses,
LoadingStrategy loadingStrategy, String type)
throws InterruptedException {
// 文件名通常是扩展点接口的全路径,这里不同的策略会有不同的文件夹目录,所以加起来就是全路径
String fileName = loadingStrategy.directory() + type;
try {
List<ClassLoader> classLoadersToLoad = new LinkedList<>();
// try to load from ExtensionLoader's ClassLoader first
// 这里是指是否loadingStrategy的classLoader要和ExtensionLoader的一样
// 我暂时能想到的是这样加载效率会高一点,这样ExtensionLoader和扩展点对应的ClassLoader是同一个
// findClass的时候就可以直接找到,我猜的
if (loadingStrategy.preferExtensionClassLoader()) {
ClassLoader extensionLoaderClassLoader = ExtensionLoader.class.getClassLoader();
if (ClassLoader.getSystemClassLoader() != extensionLoaderClassLoader) {
classLoadersToLoad.add(extensionLoaderClassLoader);
}
}
if (specialSPILoadingStrategyMap.containsKey(type)) {
String internalDirectoryType = specialSPILoadingStrategyMap.get(type);
//skip to load spi when name don't match
if (!LoadingStrategy.ALL.equals(
internalDirectoryType) && !internalDirectoryType.equals(
loadingStrategy.getName())) {
return;
}
classLoadersToLoad.clear();
classLoadersToLoad.add(ExtensionLoader.class.getClassLoader());
} else {
// load from scope model
Set<ClassLoader> classLoaders = scopeModel.getClassLoaders();
if (CollectionUtils.isEmpty(classLoaders)) {
// 直接从类路径下获取这个文件,注意这里是systemResource,会调用systemClassLoader获取
// 那这样看LoadStrategy只是指定了优先级和去哪里找的路径
// 注意这里的ClassLoader是去所有的类路径下寻找fileName,可以能不同的包下会有相同名字的目录和文件名
// 所以这里会返回多个
Enumeration<java.net.URL> resources = ClassLoader.getSystemResources(fileName);
if (resources != null) {
while (resources.hasMoreElements()) {
// 这里就是读取文件的每一行,然后分析=两边的name和实现的全路径,并且加载类到extensionClasses中
loadResource(extensionClasses, null, resources.nextElement(),
loadingStrategy.overridden(), loadingStrategy.includedPackages(),
loadingStrategy.excludedPackages(),
loadingStrategy.onlyExtensionClassLoaderPackages());
}
}
} else {
classLoadersToLoad.addAll(classLoaders);
}
}
Map<ClassLoader, Set<java.net.URL>> resources = ClassLoaderResourceLoader.loadResources(
fileName, classLoadersToLoad);
resources.forEach(((classLoader, urls) -> {
loadFromClass(extensionClasses, loadingStrategy.overridden(), urls, classLoader,
loadingStrategy.includedPackages(), loadingStrategy.excludedPackages(),
loadingStrategy.onlyExtensionClassLoaderPackages());
}));
} catch (InterruptedException e) {
throw e;
} catch (Throwable t) {
logger.error(COMMON_ERROR_LOAD_EXTENSION, "", "",
"Exception occurred when loading extension class (interface: " + type + ", description file: " + fileName + ").",
t);
}
}Dubbo可扩展机制源码解析
SPI 自适应拓展
先贴两篇dubbo官方文档吧,等后续有时间再把自适应和激活扩展解析下~
4、Models提供的隔离级别
Dubbo目前提供了三个级别上的隔离:JVM级别、应用级别、服务(模块)级别,从而实现各个级别上的生命周期及配置信息的单独管理。这三个层次上的隔离由 FrameworkModel、ApplicationModel 和 ModuleModel 及它们对应的 Config 来完成。
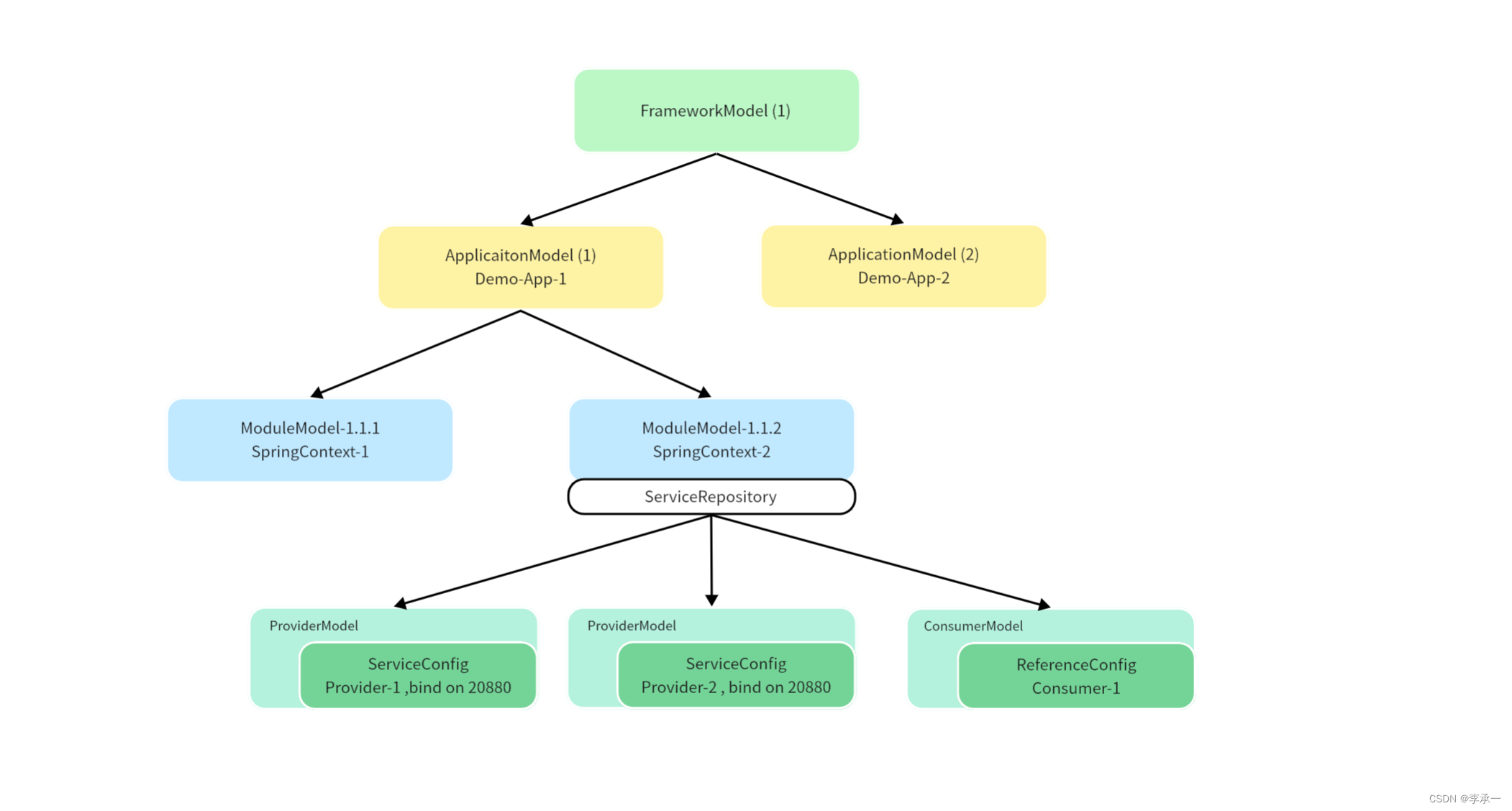
从这个树状图的可以看出来,FrameworkModel提供了最顶级的资源配置隔离,同个JVM的不同应用可以通过FrameworkModel管理自己的配置和元数据,不会互相干扰(可以通过某些配置使得不同的java应用使用同一个JVM,这里就不介绍了)。所以FrameworkModel提供的是JVM级别的配置隔离。
eg:假设我们有一个在线教育平台,平台下有多个租户,而我们希望使这些租户的服务部署在同一个 JVM 上以节省资源,但它们之间可能使用不同的注册中心、监控设施、协议等,因此我们可以为每个租户分配一个 FrameWorkModel 实例来实现这种隔离。


![2023年中国电子白板市场规模、竞争格局及应用领域市场结构[图]](https://img-blog.csdnimg.cn/img_convert/30f59a81dfea2739b7e6d0461e430b05.png)