文章目录
- 背景
- 火焰图
- ostringstream 的结构
- 引用
背景
在实习过程中,有一个业务场景需要用到 ostringstream,但经过导师提醒,ostringstream 在多线程关系下,竞态消耗较大,但对于当前业务场景,每次操作,都有自己独立的 ostringstream,为什么还会有竞争关系存在呢?
https://chys.info/blog/2017-11-06-ostringstream-performance
在上面这篇文章初窥门径。
火焰图
用以测试的文件:就是建立20个线程,用stringstream做一下数据操作,对照组是 fmt::memory_buffer。
用火焰图进行观测
stringstream 版

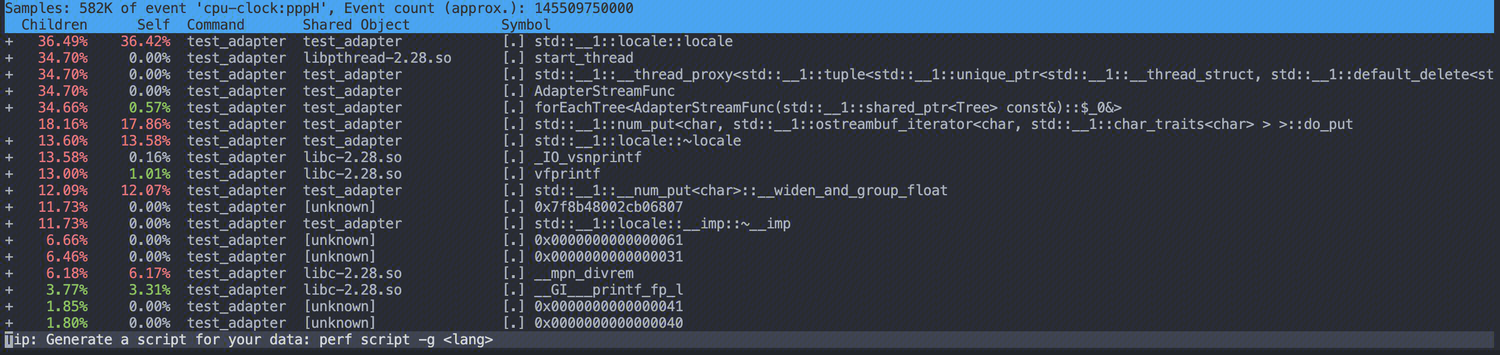
可以看出 locale的构造函数和析构函数的占用是相对较高的,而采用 memorybuffer 的:
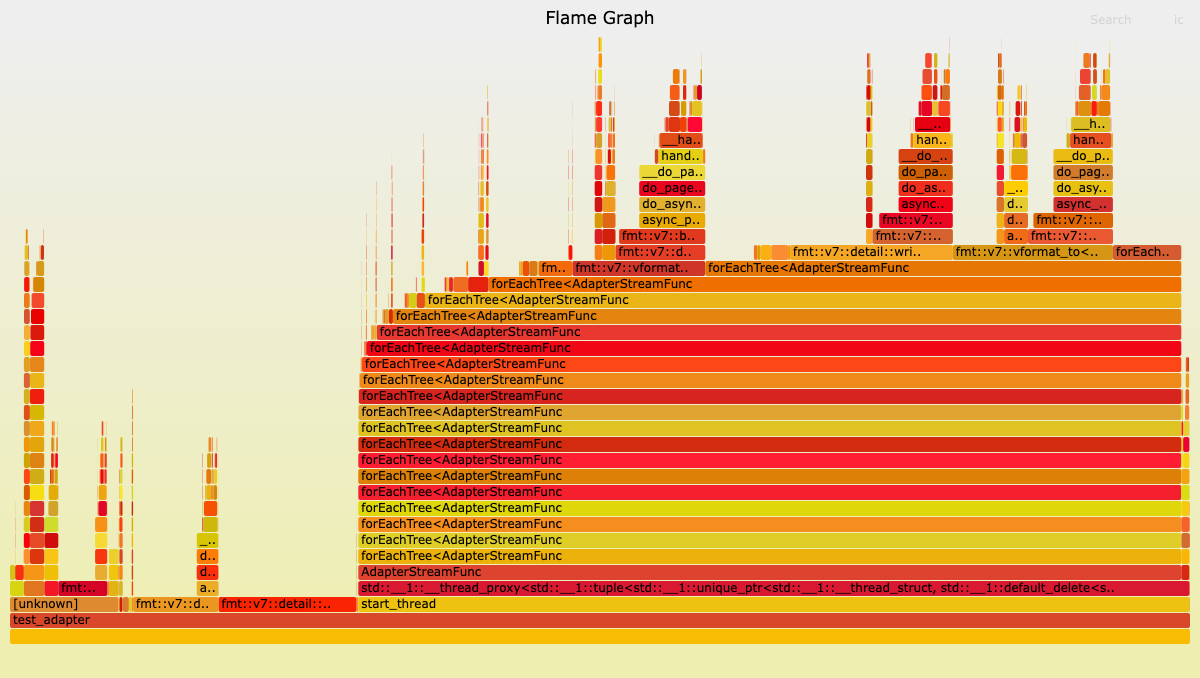
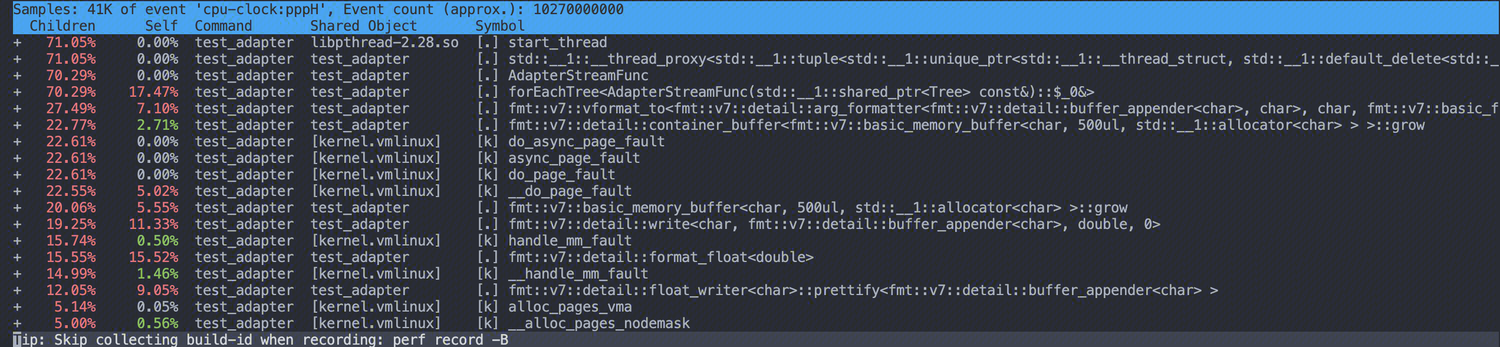
由此可以看出,stringstream 的调用时间,被 local 的构造析构函数拉长了,且对于数据的组装ostringtream 性能也是逊色于 fmt::memory_buffer,下面来分析原因。
locale 是什么
ostringstream 的结构
上面火焰图得到了原因,我们现在直接去锁定 local 这个结构在哪。
ostringstream 是 basic_ostringstream 的特化版本
typedef basic_ostringstream<char> ostringstream;
之后就存在着一个继承关系

经过代码的阅读和排查,最终锁定在basic_ostream 的构造函数中,总体是一个这样的逻辑:
当一个 ostringstream被构造出来,首先在他的构造函数中会调用基类的构造函数
explicit basic_ostringstream(ios_base::openmode __wch = ios_base::out)
: basic_ostream<_CharT, _Traits>(&__sb_) // 这里
, __sb_(__wch | ios_base::out)
{ }
然后该基类的构造函数,会调用 init 方法,该方法继承自 ios_base
explicit basic_ostream(basic_streambuf<char_type, traits_type>* __sb)
{ this->init(__sb); }
void
ios_base::init(void* sb)
{
__rdbuf_ = sb;
__rdstate_ = __rdbuf_ ? goodbit : badbit;
__exceptions_ = goodbit;
__fmtflags_ = skipws | dec;
__width_ = 0;
__precision_ = 6;
__fn_ = 0;
__index_ = 0;
__event_size_ = 0;
__event_cap_ = 0;
__iarray_ = 0;
__iarray_size_ = 0;
__iarray_cap_ = 0;
__parray_ = 0;
__parray_size_ = 0;
__parray_cap_ = 0;
::new(&__loc_) locale; // 关注这里
}
该 init 函数便与那个锁竞争有关。
该函数中,新建了一个 locale 变量,下面是该变量的析构和构造函数:
locale::locale() _NOEXCEPT
: __locale_(__global().__locale_)
{
__locale_->__add_shared(); // 原子性操作 该变量与 __shared_count 存在继承关系,
}
locale::~locale()
{
__locale_->__release_shared(); // 原子性操作 该变量与 __shared_count 存在继承关系
}
且从上面火焰图可知,该类的变量__locale_ 的构造函数耗时也不小:
locale::__imp::__imp(const __imp& other)
: facets_(max<size_t>(N, other.facets_.size())),
name_(other.name_)
{
facets_ = other.facets_;
for (unsigned i = 0; i < facets_.size(); ++i)
if (facets_[i])
facets_[i]->__add_shared(); // 原子性操作
}
再因为由于每一个stringstream 的流式操作都是用相同的 locale ,因此在测试程序刚开始运行时,就会产生激烈的锁竞争因此影响性能。
而 memory_buffer 则是与 locale 无关,且数据组装部分实现也较为高效,故建议替代。
且在查阅资料后发现
由此观之,标准库中所有输入输出流,都存在着此问题。
引用
locale 是什么
http://blog.chinaunix.net/uid-27670726-id-3327314.html
https://blog.51cto.com/xqtyler/2058706
![[Linux]动静态库](https://img-blog.csdnimg.cn/img_convert/e275ac4cd796029cfb49e93ce8c23945.png)



![buuctf crypto 【[AFCTF2018]Morse】解题记录](https://img-blog.csdnimg.cn/da80fc9988374fb8a1906118f10b33a5.png)