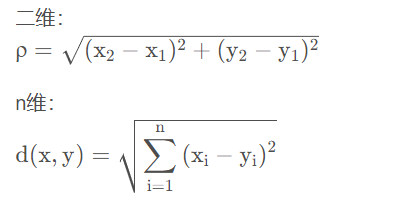1、集成学习概念
集成学习(ensemble learning)是一类机器学习框架,通过构建并结合多个学习器来完成学习任务。一般结构是:先产生一组“个体学习器”,再用某种策略将它们结合起来。结合策略主要有平均法、投票法和学习法等
集成学习包含三个典型算法:Bagging、Staking和Boosting
hard voting投票
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.ensemble import VotingClassifier
from collections import Counter
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
# plt.scatter(X[y == 0, 0], X[y == 0, 1])
# plt.scatter(X[y == 1, 0], X[y == 1, 1])
# plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
print(log_reg.score(X_test, y_test))
svc = SVC()
svc.fit(X_train, y_train)
print(svc.score(X_test, y_test))
dt_clf = DecisionTreeClassifier()
dt_clf.fit(X_train, y_train)
print(dt_clf.score(X_test, y_test))
y_predict1 = log_reg.predict(X_test)
y_predict2 = svc.predict(X_test)
y_predict3 = dt_clf.predict(X_test)
# 循环遍历每一个元素在三种模型中的预测结果,使用Counter计算出得票最多预测结果
y_predict = np.empty(len(y_predict1),dtype=int)
for i in range(0, len(y_predict1)):
votes = Counter([y_predict1[i], y_predict2[i], y_predict3[i]])
y_predict[i] = votes.most_common(1)[0][0]
print(accuracy_score(y_test, y_predict))
# 使用hard voting投票
vot_clf = VotingClassifier(estimators=[
('log_reg', LogisticRegression()),
('svc', SVC()),
('dt_clf', DecisionTreeClassifier())
], voting='hard')
vot_clf.fit(X_train,y_train)
print(vot_clf.score(X_test,y_test))
soft voting投票
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 使用soft voting投票
vot_clf = VotingClassifier(estimators=[
('log_reg', LogisticRegression()),
# probability是否开启概率估计,svc默认不开启
('svc', SVC(probability=True)),
('dt_clf', DecisionTreeClassifier())
], voting='soft')
vot_clf.fit(X_train,y_train)
print(vot_clf.score(X_test,y_test))
虽然有很多的机器学习算法,但是从投票的角度看,依然不够多,我们希望有成百上千甚至上万的投票者,来保证投票结果的可信度。
我们需要创建更多的子模型,集成更多子模型的意见。同时子模型之间要有差异性,多个子模型的投票才有意义。
创建不同的子模型的方法有:
-
初始化参数不同
-
不同的训练集
-
不同特征集
可能有同学就会问,特征不是越多学习的效果越好吗?但是其实不是这样的,在集成学习中,我们希望个体学习机越弱越好(Weak learners)。越强的学习器,所消耗的资源也越多,也越容易造成过拟合。
Bagging:从给定训练集中有放回的均匀抽样
Pasting:从给定训练集中不放回的均匀抽样
2、Bagging集成学习
Bagging子模型互相独立
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# n_estimators要创建多少个子模型,max_samples每个子模型看多少个样本数据,bootstrap是否放回取样
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True)
bag_clf.fit(X_train, y_train)
print(bag_clf.score(X_test,y_test))
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=5000, max_samples=100, bootstrap=True)
bag_clf.fit(X_train, y_train)
print(bag_clf.score(X_test,y_test))
放回取样平均大约会有37%的样本没有取到,因此当使用放回取样集成学习时,就不需要将数据集拆分成训练数据集和测试数据集,可以使用这部分未取到的样本数据做测试/验证。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
import time
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
# n_estimators要创建多少个子模型,max_samples每个子模型看多少个样本数据
# bootstrap是否放回取样, oob_score是否使用未抽取到的数据进行验证
startTime = time.time()
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True, oob_score=True)
bag_clf.fit(X, y)
endTime = time.time()
print(endTime - startTime)
print(bag_clf.oob_score_)
print('=====================================')
startTime = time.time()
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True, oob_score=True,
n_jobs=-1)
bag_clf.fit(X, y)
endTime = time.time()
print(endTime - startTime)
print(bag_clf.oob_score_)
# 这里不知道存在什么问题,加上n_jobs=-1,fit训练消耗的时间反而更多
Bagging的思路非常利于并行处理。这里是使用随机抽取训练集使模型差异化,也可以使用随机抽取特征(Random Subspaces)使模型差异化,适合特征较多的场景,例如图像识别。
也可以综合起来Random Patches,即对训练集随机取样,又随机抽取特征。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
# n_estimators要创建多少个子模型,max_samples每个子模型看多少个样本数据
# bootstrap是否放回取样, oob_score是否使用未抽取到的数据进行验证,max_features每个子模型最多使用几个特征
# 子模型使用随机特征制造差异化
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500, max_samples=500, bootstrap=True, oob_score=True,max_features=1)
bag_clf.fit(X, y)
print(bag_clf.oob_score_)
# 即随机抽取训练集,又随机使用特征制造差异化
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True, oob_score=True,max_features=1)
bag_clf.fit(X, y)
print(bag_clf.oob_score_)
这种随机抽取训练集和特征生成的决策树就叫做随机树,集成了大量随机树的算法模型就叫做随机森林。
3、随机森林
sklearn提供的随机森林算法本身集成了Bagging和决策树。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
import time
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
startTime = time.time()
rf_clf = RandomForestClassifier(n_estimators=500, random_state=666, oob_score=True)
rf_clf.fit(X, y)
endTime = time.time()
print(endTime - startTime)
print(rf_clf.oob_score_)
print('===========================')
startTime2 = time.time()
rf_clf = RandomForestClassifier(n_estimators=500, random_state=666, oob_score=True, n_jobs=-1)
rf_clf.fit(X, y)
endTime2 = time.time()
print(endTime2 - startTime2)
print(rf_clf.oob_score_)
# 这里不知道存在什么问题,加上n_jobs=-1,fit训练消耗的时间反而更多
和随机森林类似的还有Extra trees(极其随机的森林),决策树在节点划分上使用随机的特征和随机的阈值。
提供了额外的随机性,抑制了过拟合,但增大了偏差。
sklearn中提供的Extra trees:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import ExtraTreesClassifier
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
et_clf = ExtraTreesClassifier(n_estimators=500, random_state=666, bootstrap=True, oob_score=True)
et_clf.fit(X,y)
print(et_clf.oob_score_)
4、Boosting集成学习
集成多个子模型,每个子模型都在尝试增强(Boosting)整体的效果。如果某一个数据在这次分错了,那么在下一次我就会给它更大的权重。
4.1 Ada Boosting
最典型的Boosting,Ada Boosting
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t0PvqtUX-1668557907252)(C:\Users\11244\AppData\Roaming\Typora\typora-user-images\image-20221115181820037.png)]](https://img-blog.csdnimg.cn/47b22e410248444a956d20d9e6232c40.png)
sklearn中的Ada Boosting:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), n_estimators=500)
ada_clf.fit(X_train,y_train)
print(ada_clf.score(X_test,y_test))
4.2 Gradient Boosting
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-55AFsDRI-1668557907253)(C:\Users\11244\AppData\Roaming\Typora\typora-user-images\image-20221115215917988.png)]](https://img-blog.csdnimg.cn/812edee9bfea4a81b0079a9a37e1f6b7.png)
sklearn中提供的Gradient Boosting:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import GradientBoostingClassifier
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
gb_clf = GradientBoostingClassifier(max_depth=2, n_estimators=500)
gb_clf.fit(X_train, y_train)
print(gb_clf.score(X_test, y_test))
5、Stacking
Stacking和Bagging一样要集成多个子模型,不同的是Stacking不是直接使用子模型的预测结果投票或者取平均值,而是根据各个子模型预测得出的结果作为输入再添加一层算法进行预测。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5PoCQbua-1668557907253)(C:\Users\11244\AppData\Roaming\Typora\typora-user-images\image-20221115221744181.png)]](https://img-blog.csdnimg.cn/84df35c6d9b14306ab04f65cb5e665ce.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DPqO6Otz-1668557907253)(C:\Users\11244\AppData\Roaming\Typora\typora-user-images\image-20221115222124046.png)]](https://img-blog.csdnimg.cn/453e4fc1fc9746c38d5a84ec9971ccc1.png)
sklearn中没有提供Stacking集成学习的接口,需要按照设计思路自己实现。