5.2启动内存分页机制,畅游虚拟空间
即使机器上只有512MB的内存,每个进程自己的内存空间也是4GB,这4GB便是指的虚拟内存空间。下面就是讲解虚拟内存空间是怎么来的。
5.2.1内存为什么要分页
问题场景:由于多进程的发展,当内存固定时为了支持更多进程的运行,而传统的内存段基址:段内偏移是直接访问物理地址,而一段程序的地址是连续的这就导致了所需要的物理地址也是连续的。当内存中出现很多内存碎片的时候,总的空闲内存满足但是这些内存不满足连续,这就将导致进程无法加载。所有为了解决这个问题引出了内存分页机制。
下面是一个例子:
图54所示模拟了多个进程并行的情况。 在第1步中, 系统里有3个进程正在运行。 进程A、 B、 C各占了 10MB、 20MB、 30MB 的内存空间。 物理内存还是挺宽裕的,还剩下 15MB 可用。 到了第2步就悲催了。此时进程B 已经运行结束。 腾出了 20MB 的内存。 可是待加载运行的进程D需要20MB+3KB的内存空间, 即20483KB。 现在的运行环境未开启分页功能。 “段基址+段内偏移”产生的线性地址就是物理地址 ′程序中引用的线性地址是连续的 所以物理地址也连续。 虽然总共剩下 35MB 内存可用。可问题是明摆着的, 现在连续的内存块只有原来进程B 的20MB 和最下面可用内存 15MB。 哪一块都不够进程D用的这怎么办呢?
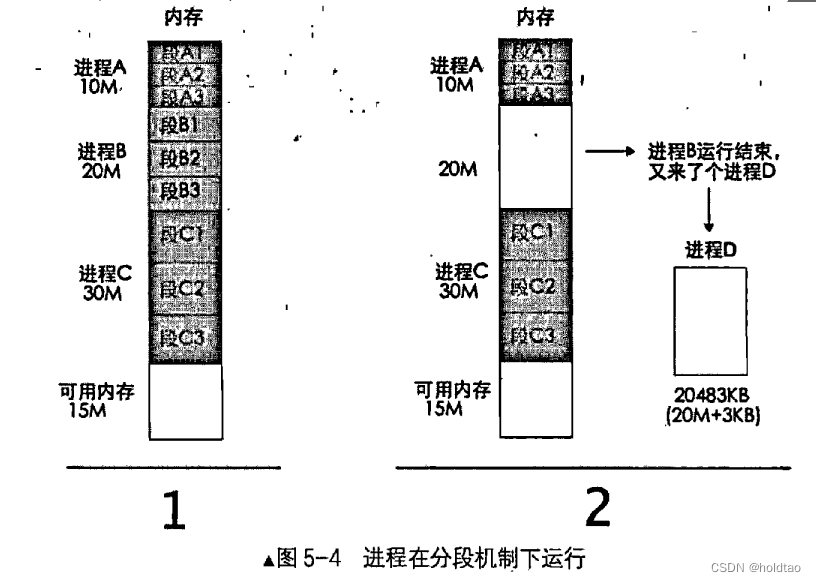
对于上面的解决方案有两个:
1.等待进程C运行完后腾出内存, 这样连续可用的内存就够运行进程D 了。
2.将进程A的段A3 或进程C的段 C1 换出到硬盘上。 腾出一部分空间。 加上邻接的 20MB. 足够容纳进程D。
针对第二种解决方案首先需要进行内存的换入换出:
内存是怎么换出的:
在保护模式下, 段描述符是内存段的身份i正。 CPU 在引用一个段时, 都要先查看段描述符。 很多时候,段描述符存在于描述符表中 (GDT或LDT), 但与此对应的段并不在内存中, 也就是说, CPU 允许在描述符表中已注册的段不在内存中存在,这就是它提供给软件使用的策略 我们利用它实现段式内存管理。 如果该描述符中的P位为1, 表示该段在内存中存在。 访问过该段后, CPU将段描述符中的A位置1, 表示近来刚访问过该段。相反, 如果P位为0, 说明内存中并不存在该段, 这时候CPU将会抛出个NP (段不存在) 异常, 转而去执行中断描述符表中NP异常对应的中断处理程序, 此中断处理程序是操作系统负责提供的, 该程序的工作是将相应的段从外存中载入到内存中, 并将段描述符的P位置1,中断处理函数结束后返回, CPU重复执行这个检查, 继续查看该段描述符的P位, 此时己经为1了, 在检查通过后,将段描述符的A位置1。
内存是怎么换出的:
段描述符的A位由 CPU置1, 但清0工作可是由操作系统来完成的。 此位干吗用的呢? 如果仅仅用来表示
该段被访问过, 这也意义不大啊。 其实这正是软件和硬件相互配合的体现,操作系统每发现该位为1后就将该位清0,这样一来, 在一个周期内统计该位为1 的次数就知道该段的使用频率了, 从而可以找出使用频率最低的段。当物理内存不足时, 可以将使用频率最低的段换出到硬盘以腾出内存空间给新的进程。 当段被换出至硬盘后,操作系统将该段描述符的P位置 0。 当下次这个进程上 CPU 运行后, 如果访问了这个段, 这样程序就回到了刚开始 CPU检查出P位为0、 紧接着抛出异常、 执行操作系统中断处理程序、 换入内存段的循环。
这样通过A位P位,中断处理程序,硬件,操作系统实现了内存换入和换出的循环。
第二个方法虽然解决了内存不足的问题, 但也有缺陷。 比如物理内存特别小, 无法容纳任何一个进程的
段, 这就没法运行进程了。 更没法做段的换入换出。
想一想, 出现这种问题的原因是什么? 问题的本质是在目前只分段的情况下, CPU 认为线性地址等于物理地址。 而线性地址是由编译器编译出来的, 它本身是连续的, 所以物理地址也必须要连续才行。 但我们可用的物理地址不连续 换句话说,如果线性地址连续 而物理地址可以不连续不就解决了吗。
按照这种思路,我们首先要做的是解除线性地址与物理地址一一对应的关系 然后将它们的关系重新建立。 通过某种映射关系 可以将线性地址映射到任意物理地址。这种映射关系是通过一张表来实现的,该表就是我们所说的页表,查找也表的工作是由硬件完成的。
5.2.2一级页表
保护模式下的分段机制:
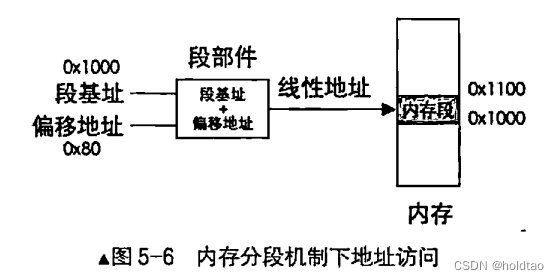
在保护模式中段寄存器中的内容已经是选择子。 但选择子最终就是为了要找到段基士止, 其内存访
问的核心机制依然是 “段基址= 段内偏移地士止″, 这两个地址在相加之后才是绝对地址。 也就是我们所说
的线性地址, 此线性地址在分段机制下被 CPU 认为是物理地址。 直接拿来就能用, 也就是说, 此线性地
士止可以直接送上地址总线。 将段基址和段内偏移地址相加求和的工作是由 CPU 的段部件自动完成的。 整
个访问内存的过程如图 5_6所示。
保护模式下的分页机制:
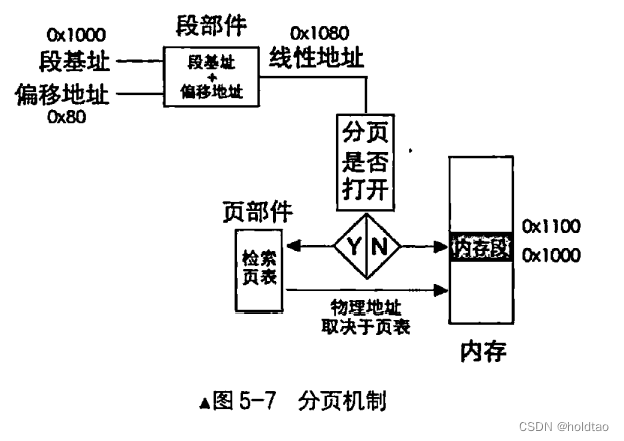
分页机制要建立在图 5-6 所示分段机制的基础上, 也就是说, 段部件的工作依然免不了, 所以分页只能是在分段之后进行的, 其过程如图 5-7 所示。
图 5-7 说明, CPU 在不打开分页机制的情况下,是按照默认的分段方式进行的段基址和段内偏移地址经过段部件处理后所输出的线性地址, CPU 就认为是物理地址。如果打开了分页机制, 段部件输出的线性地址就不再等同于物理地址了。 我们称之为虚拟地址, 它是逻辑上的, 是假的, 不应该被送上地址总线 (因为地址只是个数字, 任何数字都可以当作地址, 这里说的 “不应该″ 是指应该人为保证送上地址总线上的数字是正确的地址)CPU必须要拿到物理地址才行, 此虚拟地址对应的物理地址需要在页表中查找, 这项查找工作是由页部件自动完成的。 为了要搞清楚页部件的工作原理, 必须要搞清楚这两件事
1.分页机制的原理
2.页表的结构
分页机制的思想是: 通过映射, 可以使连续的线性地址与任意物理内存地址相关联, 逻辑上连续的线性地址其对应的物理地址可以不连续。
分页机制的作用有两方面。
1.将线性地址转换成物理地址。
2.用大小相等的页代替大小不等的段。这两方面的作用
由于有了线性地址到真实物理地址的这层映射经过段部件输出的线性地址便有了另外一个名字,虚拟地址。
下面根据上图介绍一下操作系统在分页机制下加载进程的过程。
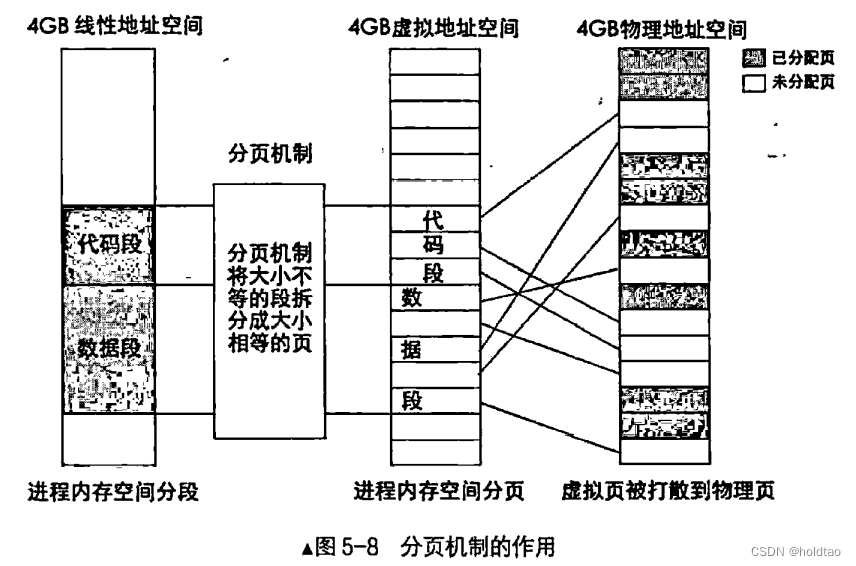
图5-8 表示的是一个进程的地址转换过程, 从线性空间到虚拟空间再到物理地址空间, 每个空间大小都是 4GB。 图上的 4GB 物理地址空间属于所有进程包括操作系统在内的共享资源, 其中标注为已分配页的内存块被分配给了其他迸程, 当前进程只能使用未分配页。 此转换过程对任意一个进程都是一样的, 也就是说, 每个进程都有自己的 4GB 虚拟空间。
前面说过啦, 分页机制建立在分段机制之上, 与其脱离不了干系, 即使在分页机制下的进程也要先经过逻辑上的分段才行,每加载一个进程, 操作系统按照进程中各段的起始范围, 在进程自己的 4GB 虚拟地址空间中寻找可用空间分配内存段, 此虚拟地址空间可以是页表。也可以是操作系统维护的某种数掂结构总之此阶段的分配是逻辑上的,并没有真正写入物理内存。在分页机制下,分配情况如图 5-8 中所示的虚拟地址空间中的代码段和数据段。代码段和数据段在逻辑上被拆分成以页为单位的小内存块。 这时的虚拟地址虚如其名, 不能存放在任何数据。 接着操作系统开始为这些虚拟内存页分配真实的物理内存页, 它查找物理内存中可用的页, 然后在页表中
登记这些物理页地址。 这样就完成了虚拟页到物理页的映射, 每个进程都以为自己独享4GB地址空间。
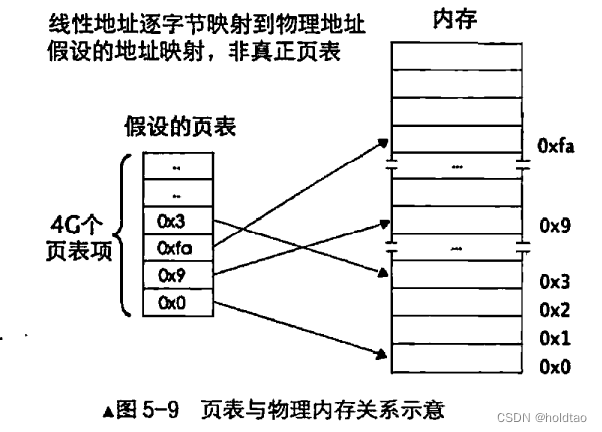
对于从虚拟地址空间到物理地址空间的映射关系保存在页表中。页表就是个N行 1 列的表格页表中的每一行 (只有一个单元格) 称为页表项 (PageTableEntry,
PTE), 其大小是 4 字节, 页表项的作用是存储内存物理地址。 当访问一个线性地址时, 实际上就是在访问页表项中所记录的物理内存地址。
下图是映射方案原理:
下图是针对上面映射方案,为了使得页表不会占据太大的内存下图是选择合适的内存块大小:
官方中的内存块大小就是如图所示的情况,每个内存块大小是4KB,一种有1M的内存块,即也就是有1M的页表项。
上面所说的也就是一级页表:
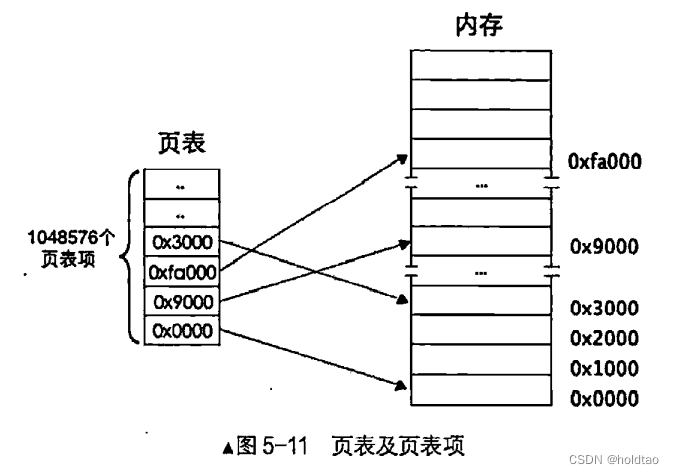
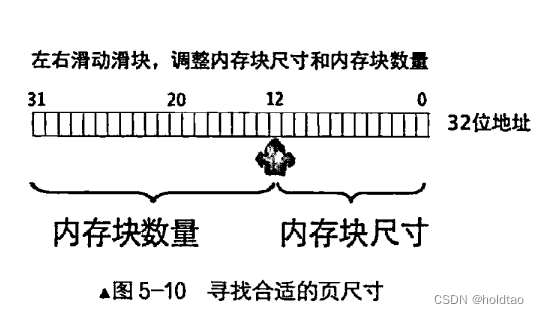
针对如何寻找到正确的地址,可以利用5-10理解。右边第11-0位用来表示页的大小,也就是这12位可以作为页内寻址。左边第31-12位用来表示页的数量,同样这20位也用来索引一个页,可以来找到第几页的情况。
任意一个地址最终会落到某一个物理页中。 32 位地址空间共有 1M (1048756)
个物理页, 首先要做的是定位到某个具体物理页, 然后给出物理页内的偏移量就可以访问到任意1字节的内存啦。 所以用20 位二进制就可以表示全部物理页啦。 标准页都是4KB, 12 位二进制便可以表达4KB之内的任意地址。
在32位保护模式下虚拟地址的高20 位可用来定位一个物理页, 低 12 位可用来在该物理页内寻址。 这是如何实现的呢? 物理地址写在页表的页表项中, 段部件输出的只是线性地址, 所以问题就变成了:怎样用线性地址找到页表中对应的页表项。
在转换之前需要提前知道这两件事情:
1:分页机制打开前要将页表地址加载到控制寄存器 CR3 中, 这是启用分页机制的先决条件之一, 在介绍二级页表时会细说。 所以, 在打开分页机制前加载到寄存器 cr3 中的是页表的物理地址,页表中页表项的地址自然也是物理地址了。
2:虽然内存分页机制的作用是将虚拟地址转换成物理地址, 但其转换过程相当于在关闭分页机制下进行, 过程中所涉及到的页表及页表项的寻址, 它们的地址都被 CPU 当作最终的物理地址 (本来也是物理地址) 直接送上地址总线, 不会被分页机制再次转换 (否则会递归转换下去〉。
地址转换过程原理如下:
一个页表项对应一个页, 所以, 用线性地址的高 20 位作为页表项的索引每个页表项要占用 4字节大小, 所以这高 20 位的索引乘以4后才是该页表项相对于页表物理地址的字节偏移量。 用 cr3 寄存器中的页表物理地址加上此偏移量便是该页表项的物理地址, 从该页表项中得到映射的物理页地址, 然后用线性地址的低 12 位与该物理页地址相加所得的地址之和便是最终要访问的物理地址。
上面从虚拟地址到物理地址的过程通过页部件来计算:
页部件的工作:用线性地址的高20位在页表中索引页表项,用线性地址的低12位与页表项中的物理地址相加,所求的和便是最终线性地址对应的物理地址。
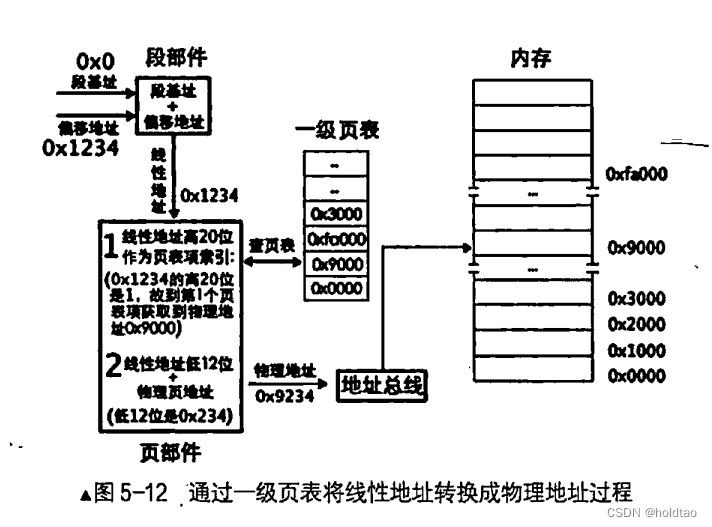
假设咱们是在平坦模型下工作, 不管段选择子值是多少, 其所指向的段基址都是 0, 指令 mov ax,[0xl234]中的 0x1234 称为有效地址, 它作为 “段基址= 段内偏移地址″ 中的段内偏移地址。 这样段基址为 0, 段内偏移地址为 0x1234. 经过段部件处理后, 输出的线性地址是 0x1234。由于咱们是演示分页机制, 必须假定系统己经打开了分页机制, 所以线性地址0x1234被送入了页部件。 页部件分析 0x1234的高20 位, 用十六进制表示高 20 位是 0x00001。 将此项作为页表项索引, 再将该索引乘以4后加上 cr3 寄存器中页表的物理地址, 这样便得到索引所指代的页表项的物理地址, 从该物理地址处 (页表项中〉 读取所映射的物理页地址= 0x9000。 线性地址的低 12 位是 0x234, 它作为物理页的页内偏移地址与物理页地址0x9000 相加, 和为 0x9234这就是线性地址 0X1234 最终转换成的物理地址。
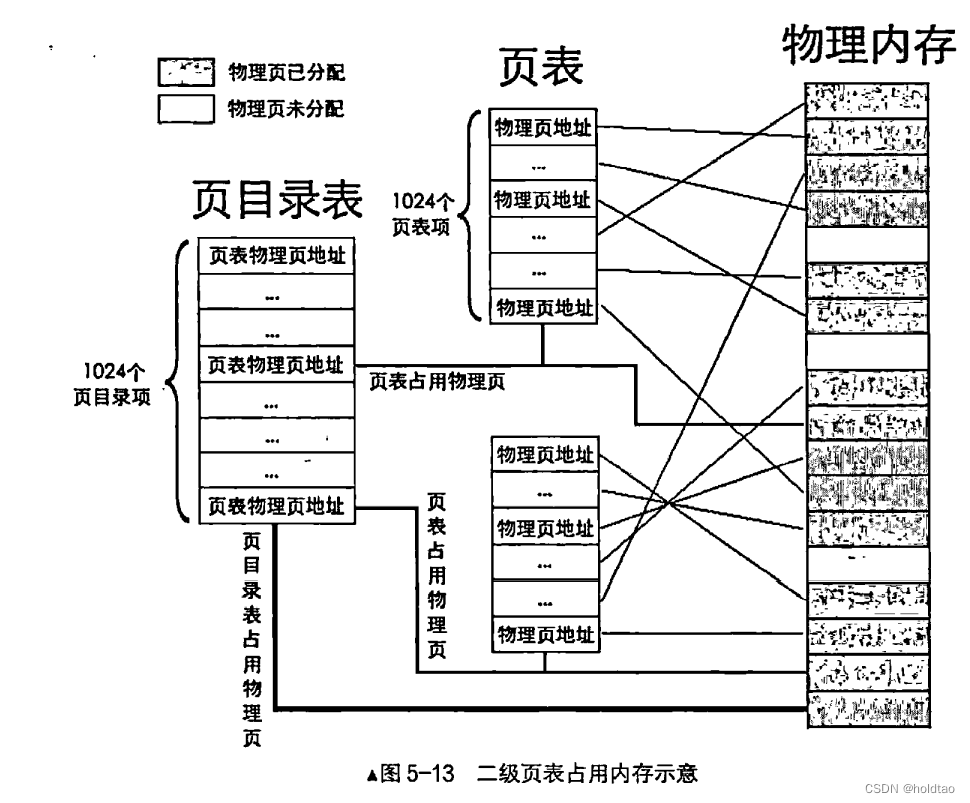
二级页表
问题引出:为什么有了一级页表为什么还要搞二级页表?
(1) 一级页表中最多可容纳 1M (1048576) 个页表项每个页表项是4字节, 如果页表项全满的话便是4MB大小
(2) 一级页表中所有页表项必须要提前建好, 原因是操作系统要占用 4GB 虚拟地址空间的高1GB,挪用户进程要占用低 3GB。
(3) 每个进程都有自己的页表, 进程一多, 光是页表占用的空间就很可观了。
归根结底,我们要解决的是不要一次性地将全部页表项建好需要时动态创建页表项。如何解决呢?
什么是二级页表?
无论是几级页表, 标准页的尺寸都是4KB, 这一点是不变的。 所以 4GB 线性地址空间最多有1M个标准页。 一级页表是将这 1M个标准页放置到一张页表中, 二级页表是将这 1M 个标准页平均放置lK个 页表中。 每个页表中包含有 1K个页表项。 页表项是4字节大小, 页表包含1K个页表项, 故页表大小为 4KB, 这恰恰是一个标准页的大小。
拆分出了这么多个页表, 如何使用它们昵? 为此,专门有个页目录表来存储这些页表。 每个页表的物理地址在页目录表中都以页目录项 (PageDirectoryEntry,PDE) 的形式存储, 页目录项大小同页表项一 样, 都用来描述一个物理页的物理地址, 其大小都是4字节, 而且最多有 1024 个页表所以页目录表也是4KB大小,同样也是标准页的大小。页表是用于管理内存的数据结构, 其也要占用内存, 所以页目录表和页表所占用的物理页, 同样混迹 于物理内存之中, 如图5-13所示