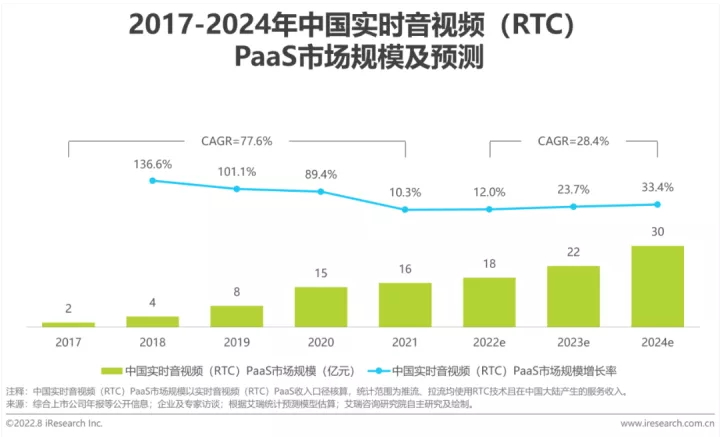
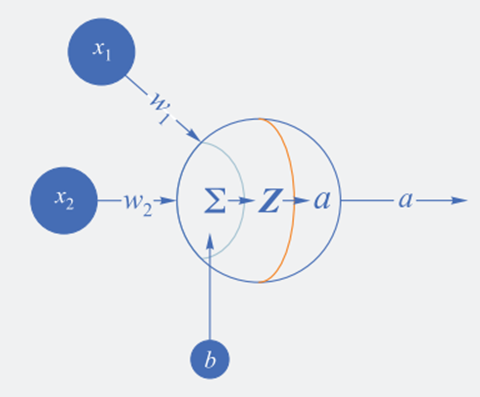
神经网络结构
从视觉上判断是线性可分的,使用单层神经网络;
输入层设置两个输入单元,表示经纬度:𝑋=𝑥1,𝑥2
输出层设置一个单元,表示地盘所属阵营:
𝑧=𝑋𝑊+𝐵
a=Logistic(z)
权重参数为: 𝑊=(𝑤1,𝑤2)^𝑇 , 𝐵=(𝑏)
损失函数为交叉熵损失函数,反向传播公式为:

线性二分类工作原理
回忆一下前面学习过的线性回归,通过用均方差函数的误差反向传播的方法,不断矫正拟合直线的斜率和截距,因为均方差函数能够准确地反映出当前的拟合程度。
线性分类与线性回归相似的地方是,两者都需要划出那条“直线”来,但是不同的地方也很明显:线性回归要求用直线来拟合所有样本,使得各个样本到这条直线的距离尽可能最短;而线性分类则要求用直线来分割所有样本,使得正例样本和负例样本尽可能分布在直线两侧。
二分类的代数原理
代数方式:通过一个分类函数计算所有样本点在经过线性变换后的概率值,使得正例样本的概率大于0.5,而负例样本的概率小于0.5。
基本公式回顾
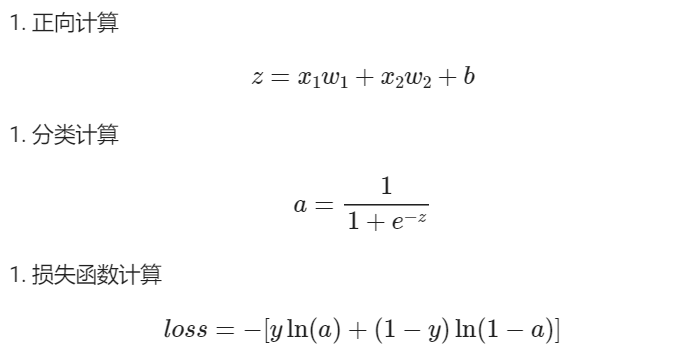
举例理解
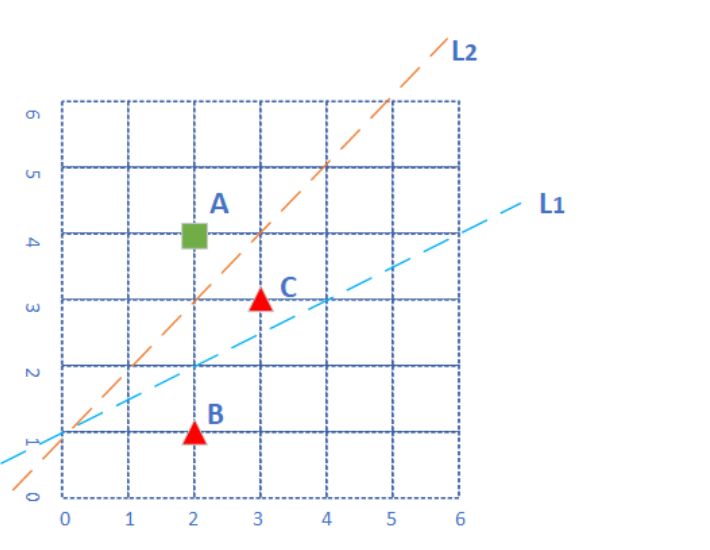
平面上有三个点,分成两类,绿色方块为正类,红色三角为负类。各个点的坐标为:,,A(2,4),B(2,1),C(3,3)。
当分类线为 L1 时
假设神经网络第一次使用 L1 做为分类线,此时:w1=−1,w2=2,b=−2,我们来计算一下三个点的情况。
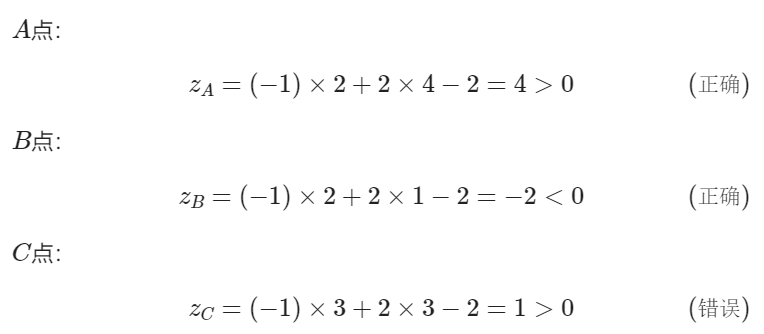
我们知道当 z>0 时,Logistic(z)>0.5 为正例,反之为负例,所以我们只需要看三个点的 z 值是大于0还是小于0就可以了,不用再计算 Logistic 函数值。
此时 C 点的损失函数值为(核心:注意 C 的标签值 y=0):
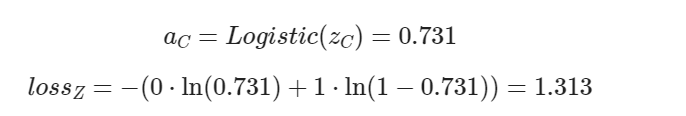
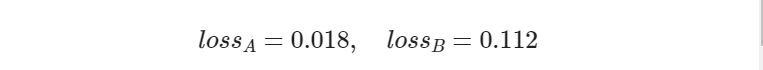
可知 A,B点处于正确的分类区,而 C 点处于错误的分类区
可见,对于分类正确的 A,B 点来说,其损失函数值比 C 点要小很多,所以 C 点的反向传播的力度就大。
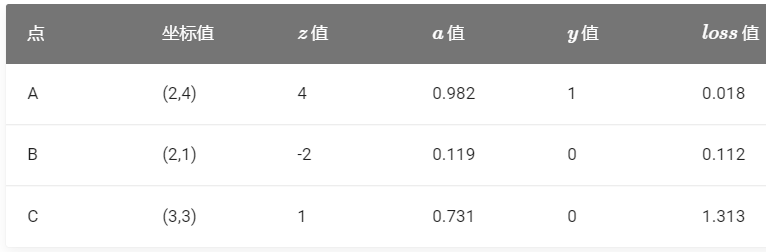
- 在正例情况 y=1 时,a 如果越靠近 1,表明分类越正确,此时损失值会越小。点 A 就是这种情况:a=0.982,距离 1 不远;loss 值 0.018,很小;
- 在负例情况 y=0 时,a 如果越靠近 0,表明分类越正确,此时损失值会越小。点 B 就是这种情况:a=0.119,距离 0 不远;loss 值 0.112,不算很大;
- 点 C 是分类错误的情况(y=0,将他视为0类来计算),a=0.731,本应小于 0.5,实际上距离 0 远,距离 1 反而近,它的 loss=1.313,与其它两个点的相对值来看非常大,这样误差就大,反向传播的力度也大。



![[附源码]java毕业设计基于的考研408课程学习平台](https://img-blog.csdnimg.cn/2b4fc346ad5549cf88bfe860e466601c.png)