为什么要进行性能优化
哪些情况需要进行性能优化
其实关于性能优化的主题,网上已经讨论很多次,这里谈一下我的理解,那么其实核心就是 2 个点:
- 服务一直高负载,业务增长需要经常扩容
- 架构不能满足业务发展,需要重构,与此同时需要进行服务的压测&性能优化
性能优化的一般步骤
- 准备阶段:发现系统性能问题,明确优化方向
- 分析阶段:通过各种工具和手段,初步定为瓶颈点
- 调优阶段:根据定位到的瓶颈点,进行性能调优
- 测试阶段:实际验证调优效果,如果不能满足期望要求,那么可能需要重复 2-3 步骤(如果还不行可能是架构设计存在问题)
linux 常见的性能问题排查工具
linux 程序常用的调试工具:
vmstat、iostat、 mpstat、netstat、 sar 、top:查看系统、程序信息等
gprof、perf、perf top:定位到具体函数、调用等
strace、ltrace:系统调用、函数调用、库函数调用等
pstack、ptree、pmap:堆栈信息
dmesg:系统 log 信息
对于 go 程序,如果遇到高负载等性能问题推荐使用:perf top、pprof 快速定位问题。
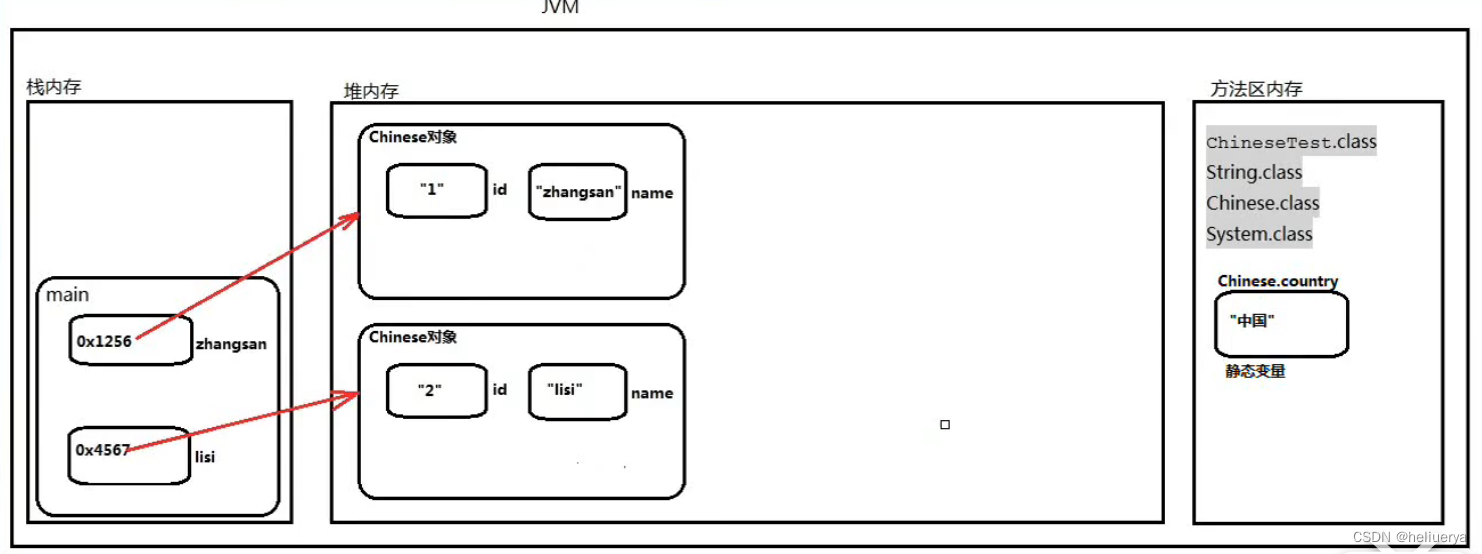
perf top
当前系统的 uptime:load average 2.50 左右,以下 perf top 信息中出现_raw_spin_unlock_irqrestore 表示系统可能比较“闲’‘,以及有较多的软中断(服务交互)。unknown 则是没有加载符号文件,所以没有显示函数名,vdso 很可能 time 相关系统调用。
runtime.scanobject、mallocgc 说明可能有较多小对象申请等等。
go 程序性能问题梳理
- 内存泄露
- 内存大量申请释放
- 协程泄露
- 协程数量异常
- 对象数量异常
- 反射使用(gc、内存问题)
- 定时器使用导致的内存泄露
- 以及业务逻辑上的问题
- ...
pprof 分析程序性能问题
pprof 如何收集程序信息
on cpu 类型的 pprof 收集原理:注册 settimer 系统调用回调,1 秒触发 100 次回调,然后遍历每个线程的堆栈信息并保存生成 prof 文件。(off cpu 则是 IO 较大的程序)
程序中如下使用,注册 pprof 监听的端口即可。
import _ "net/http/pprof"
gofunc() {
http.ListenAndServe("0.0.0.0:8080", nil)
}()
pprof.go 文件的 init 在 DefaultServeMux 默认路由上注册了多个 handle,分别用来收集 cpu、内存等信息
pprof.go
func init() {
http.HandleFunc("/debug/pprof/", Index)
http.HandleFunc("/debug/pprof/cmdline", Cmdline)
http.HandleFunc("/debug/pprof/profile", Profile)
http.HandleFunc("/debug/pprof/symbol", Symbol)
http.HandleFunc("/debug/pprof/trace", Trace)
}
对应的 handle,定期以固定 hz 频率收集程序信息到 profileBuilder 对象中。最终在收集完成返回收集的数据信息,最终 web 页面展示出来。
type profileBuilder struct {
start time.Time
end time.Time
havePeriod bool
period int64
m profMap
// encoding state
w io.Writer
zw *gzip.Writer
pb protobuf
strings []string
stringMap map[string]int
locs map[uintptr]locInfo
funcs map[string]int
mem []memMap
deck pcDeck
}
// and
runtime.MemProfileRecord // goroutine堆栈信息
runtime.MemStats // 内存数据统计信息
pprof 查看程序信息
我们可以使用下面多种方式查看程序的内存、cpu、锁等信息。
// Then use the pprof tool to look at the heap profile:
//
// go tool pprof http://localhost:6060/debug/pprof/heap
//
// Or to look at a 30-second CPU profile:
//
// go tool pprof http://localhost:6060/debug/pprof/profile?seconds=30
//
// Or to look at the goroutine blocking profile, after calling
// runtime.SetBlockProfileRate in your program:
//
// go tool pprof http://localhost:6060/debug/pprof/block
//
// Or to look at the holders of contended mutexes, after calling
// runtime.SetMutexProfileFraction in your program:
//
// go tool pprof http://localhost:6060/debug/pprof/mutex
//
// The package also exports a handler that serves execution trace data
// for the "go tool trace" command. To collect a 5-second execution trace:
//
// wget -O trace.out http://localhost:6060/debug/pprof/trace?seconds=5
// go tool trace trace.out
//
// To view all available profiles, open http://localhost:6060/debug/pprof/
// in your browser.
//
// For a study of the facility in action, visit
//
// https://blog.golang.org/2011/06/profiling-go-programs.html
简单的示例,查看 goroutine 的堆栈、程序的内存信息、gc 次数等。
go tool pprof http://localhost:6060/debug/pprof/heap?debug=1
// runtime.MemProfileRecord
heap profile: 71: 35532256 [15150: 492894072] @ heap/1048576
1: 31203328 [1: 31203328] @ 0xc2c83a 0x49ed0a 0x49ecd7 0x49ecd7 0x49ecd7 0x491985 0x4c79c1
# 0xc2c839 git.code.oa.com/tmemesh.io/sidecar.init+0x39 git.code.oa.com/tmemesh.io/sidecar@v0.0.27/report.go:14
# 0x49ed09 runtime.doInit+0x89 /usr/local/go/src/runtime/proc.go:5646
# 0x49ecd6 runtime.doInit+0x56 /usr/local/go/src/runtime/proc.go:5641
# 0x49ecd6 runtime.doInit+0x56 /usr/local/go/src/runtime/proc.go:5641
# 0x49ecd6 runtime.doInit+0x56 /usr/local/go/src/runtime/proc.go:5641
# 0x491984 runtime.main+0x1c4 /usr/local/go/src/runtime/proc.go:191
// runtime.MemStats
# runtime.MemStats
# Alloc = 83374072
# TotalAlloc = 8261199880
# Sys = 216980496
# Lookups = 0
# Mallocs = 102656515
# Frees = 102139727
# HeapAlloc = 83374072
# HeapSys = 199491584
# HeapIdle = 94797824
# HeapInuse = 104693760
...
# NextGC = 163876768
# LastGC = 1618924964269456488
# NumGC = 333
# NumForcedGC = 0
# GCCPUFraction = 0.00011171208329868897
# DebugGC = false
# MaxRSS = 130633728
投放服务【测试环境压测】
投放服务的主要工作就是给用户投放合适的内容(主播、会员广告)
这里压测 srf 服务可以使用 bm_tools 工具,可以很方便的压测 qps 以及查看服务平均延迟等(下面有示例)
资料领取直通车:Golang云原生最新资料+视频学习路线
Go语言学习地址:Golang DevOps项目实战![]() https://ke.qq.com/course/422970?flowToken=1043212
https://ke.qq.com/course/422970?flowToken=1043212
服务无太多业务逻辑(无真实内容、主播投放)
相当于服务空转的情况下的负载测试,200qps/s,并且无日志打印。当前服务 cpu 不算很高,查看 pprof 系统性能消耗。
- 没有明显业务代码占用的 cpu
- 但是较多 mcall→park_m,说明可能当前环境 g 很多,park_m 则是 g 切换 g0 并进行新一次 gmp 吊打循环
- 6%消耗在 gc 还算正常
真实业务数据投放
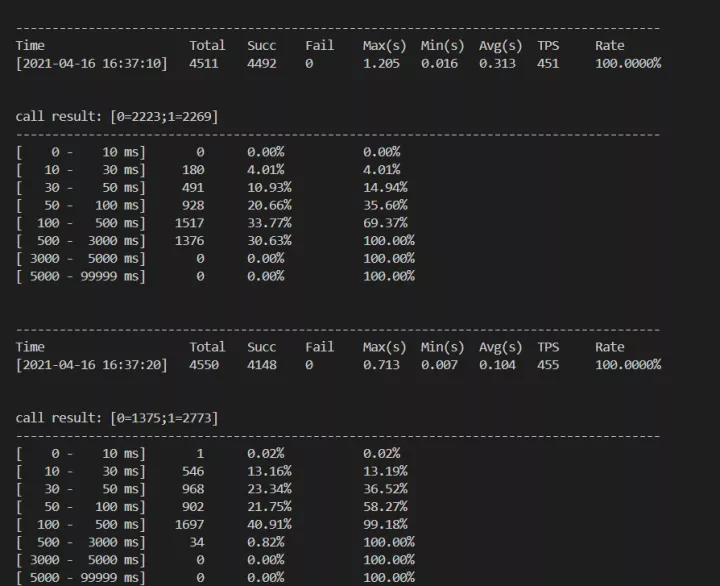
服务现在会正常投放内容和主播,100qps/s 的情况下出现较多超时等异常。这里压测工具可以使用司内的服务压测工具 eab,当然也可以使用外部其他的开源压测工具。 这里平均时延达到 1.2s,p90 超过 500ms 以上
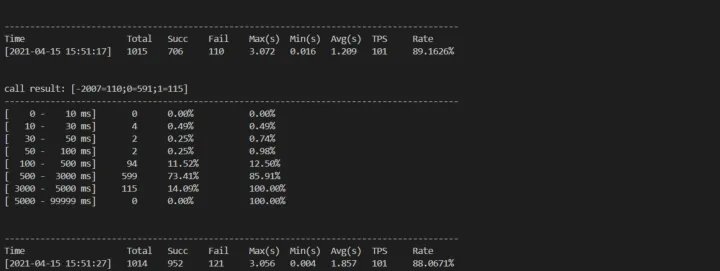
pprof 查看明显瓶颈
因为服务在 qps100 情况下(测试环境)出现了较多的超时等异常问题,所以我们可以优先使用 pprof 分析一些程序明显的问题。
如下有大块的 cpu 统计是消耗异步操作中的,这里很明显是有问题的,非关键路径占用了很多的 cpu。
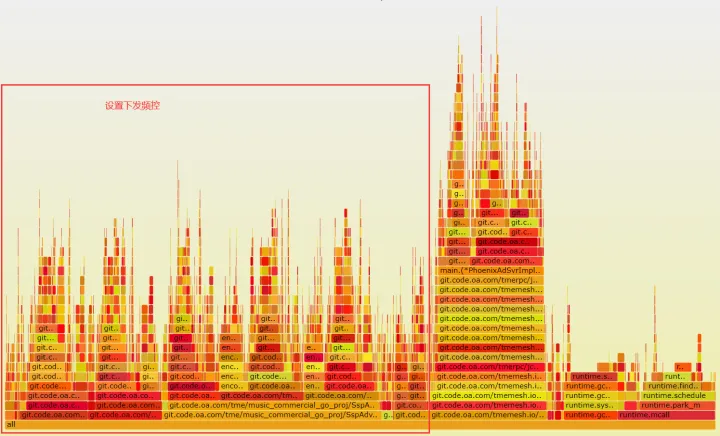
点开查看即可看到相关的业务函数大多都是 redis 相关操作,这里的逻辑是:每次受到请求后,都会开启约 10 个 goroutine 去 set 记录一些频控信息。
可能的优化点:
- 每次请求后都会创建约 10 个左右 goroutine 并发单独 set 数据,这里可以考虑协程池处理。
- 考虑使用 mset 合并不同业务数据,减少请求次数。
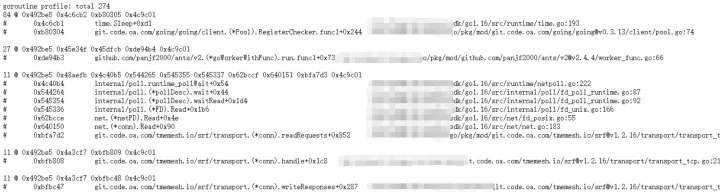
当然我们是遇到问题查看代码之后才会发现,每次请求都会创建很多 goroutine,那么在性能问题排查过程中我们有哪些办法可以判断 goroutine 数量异常,以及导致的问题。这时候就可以使用 trace 工具查看。
trace 跟踪 gc 和 g 调度
pprof 简单定位后(包括内存、cpu),其实已经没有特别明显的问题可以发现到,所以可以考虑 trace 程序查看更细节的问题。
这里我们使用 trace 生成 go trace 文件信息查看,相关调度问题。
怎么生成 trace 文件
curl localhost:/debug/pprof/trace?seconds=10 > trace.out
怎么查看 trace 文件信息
得到 trace.out 文件后,可以下载到自己电脑,使用如下命令即可使用 web 打开 trace 文件信息。
go tool trace trace.out
粗略查看 gc 约 5 秒触发一次持续 1s 左右,当前业务确实会有较多的内存申请释放,所以这里可能也会有内存相关的问题,导致 gc 频繁、持续时间较长。
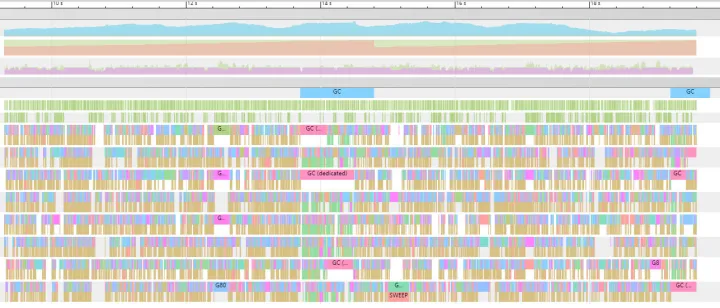
查看 g 调度时延
查看 network poll 接收时间到 goroutine 处理的时延。目前查看平均 250-300ms 收到事件才会正常处理,在当前测试环境已经属于服务饱和状态。并且结合业务出现超时等现象,这里可以断定:
- 在服务不扩容的情况下,测试环境 qps:100 已经达到极限。
- 另外 gc 属于较为频繁的情况,考虑程序内存方面需要优化。
- 另外待调度的 goroutine 数量可能太多了,导致调度的延迟很大。
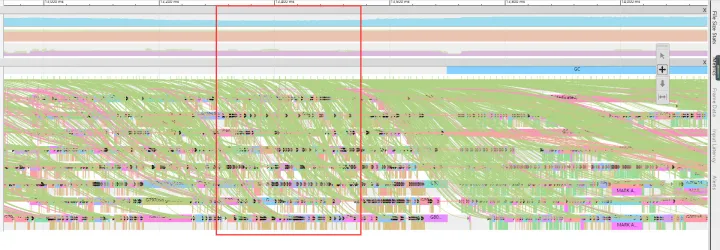
查看此时的 Goroutine analysis,来查看当前 Goroutine 的一些运行信息。可以看到很多 goroutine 的大部分的时间都会花费在:Sync Block Time(同步阻塞时间),这里我的理解应该是状态通过 gopark 已经转换为 Grunnable,但是实际上没有时间片执行导致的耗时。
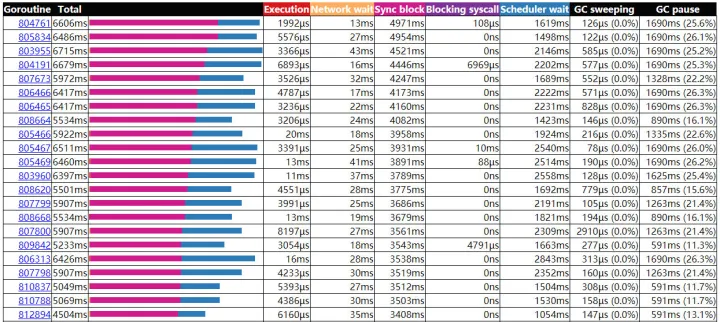
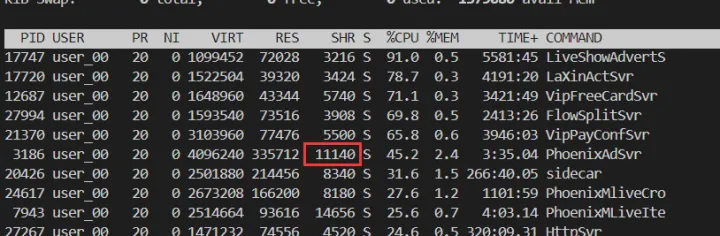
查看 g 数量信息
结合查看 pprof 以及 trace,我们分析除了业务问题、内存问题还可能是 goroutine 数量有些问题,这里直接查看 pprof 的“概览“即可看到 goroutine、heap 等信息。
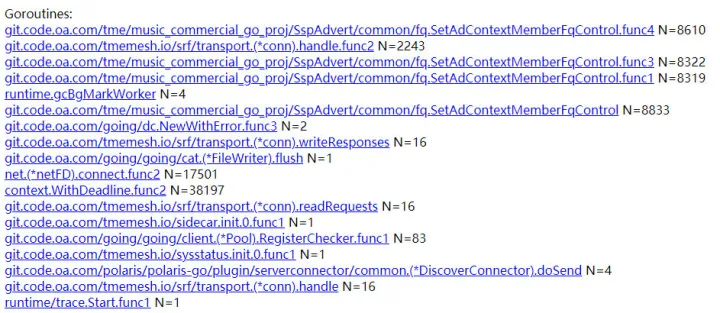
到此可以定位到,goroutine 数量确实是服务性能问题的元凶之一。
可能的优化点:
- 每次请求后都会创建约 10 个左右 goroutine 并发单独 set 数据,这里可以考虑协程池处理。
- 考虑使用 mset 合并不同业务数据,减少请求次数。
查看内存问题
考虑到 trace 查看 gc 较为频繁,所以当前系统应该也有些内存上的问题,这里直接使用 pprof 给出的是具体函数,我们想要定位到具体某一行该如何操作呢?
go tool pprof http://localhost:30065/debug/pprof/allocs
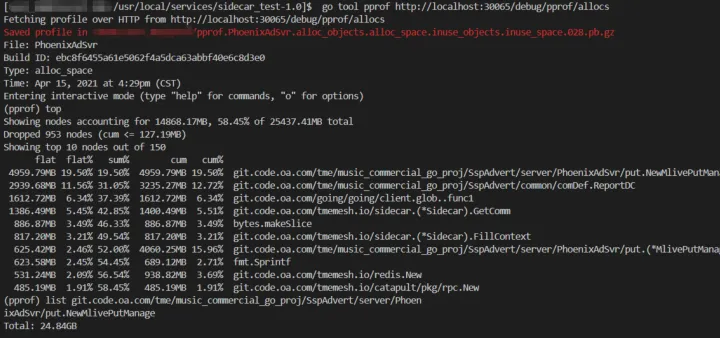
在上面的操作界面,我们可以使用 top 列出当前系统内存占用信息。使用 list 命令列出占用较高函数的详细信息。(这里因为是测试环境,代码在我们开发机,所以提示找不到.go 文件)
这里我们需要将 go tool 工具生成的.pb.gz 文件拷贝到开发机,再次使用 go tool 工具运行既可查看到具体的函数占用信息。
go tool pprof pprof.PhoenixAdSvr.alloc_objects.alloc_space.inuse_objects.inuse_space.027.pb.gz
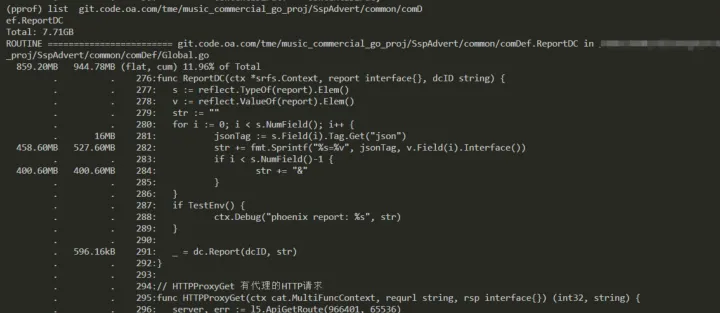
我们可以 list 查看一下几个明显占用高的函数信息:
如下则是每次服务收到请求,都会创建一个待上报的结构体,这里的 make 初始化 len 明显不合理。
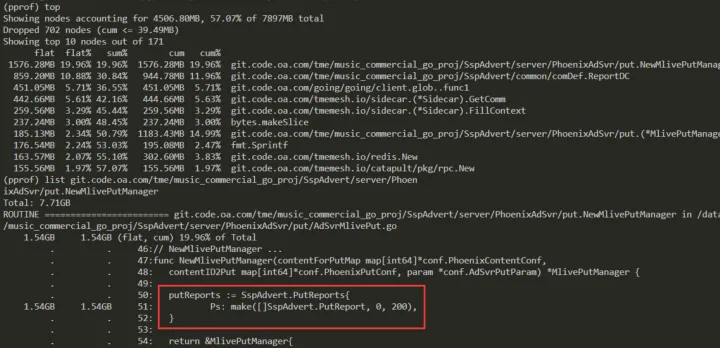
另外一个较小的内存申请如下,这里是一个通用的解析上报(使用反射通用处理),暂且认为在当前业务下,不优先处理。
查看内存泄漏问题
内存排查完成后,下一步就是观察这么大量的内存申请释放是否可能存在内存泄露问题。
针对内存泄漏场景,我们可以采集 2 个时间点的内存数据,对比这段时间哪些内存一直增长。
我们得到 2 份 pb.gz 的内存数据可以使用如下命令对比(在开发机器):
go tool pprof -base
pprof.PhoenixAdSvr.alloc_objects.alloc_space.inuse_objects.inuse_space.027.pb.gz
pprof.Phoen_objects.alloc_space.inuse_objects.inuse_space.028.pb.gz
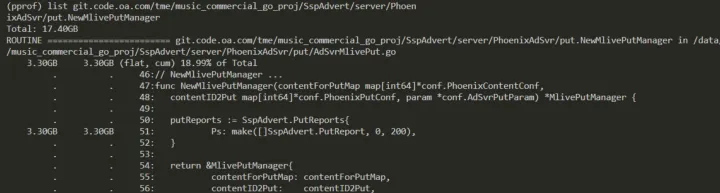
可以发现确实内存一直增长,但是对于此场景是在有请求时发现内存不断上涨,但是请求下降后内存会逐步恢复,说明当前系统虽然没有内存泄露,但是确实存在内存瓶颈,在当前 qps 下,业务处理后的内存释放跟不上内存申请的速度,最终会导致 OOM。
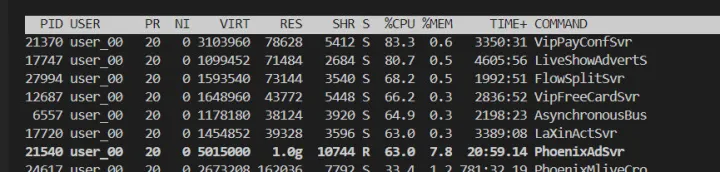
如下 RES 在已经升到了 1G,但是在请求下降后逐步恢复。
总结
根据以上的测试结果,目前系统需要做以下几个优化点:
- 下发频控设置上,启动了较多 goroutine,并且单独 set 数据,这里需要考虑如何将不同操作合并下发。
- 另外在处理下发上报时,为了防止由于系统负载问题导致,goroutine 暴增,从而雪崩的问题,考虑下发上报使用 pool 组件处理。
- 内存申请异常问题需要减少、更新其他的监控上报方式。
修复以上问题继续压测
主要使用池化减少 goroutine 数量,另外不合理的内存申请大小也需要修改。
池化
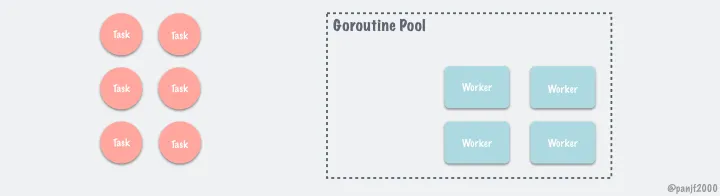
根据业务特点设置不同的 pool 以及 routiune 大小。这里使用的组件:
5k star持续维护值得使用
https://github.com/panjf2000/ants
池化的原理大概如下(图来自 README.md):
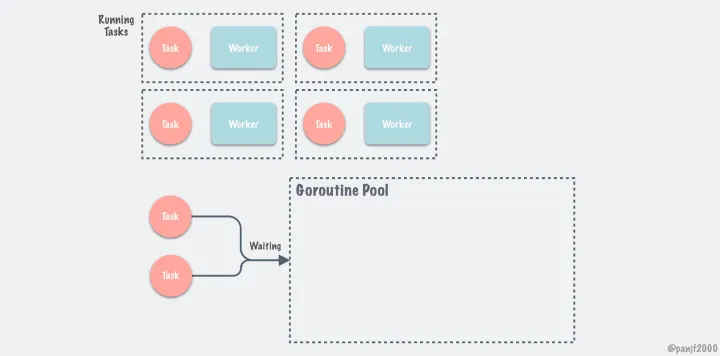
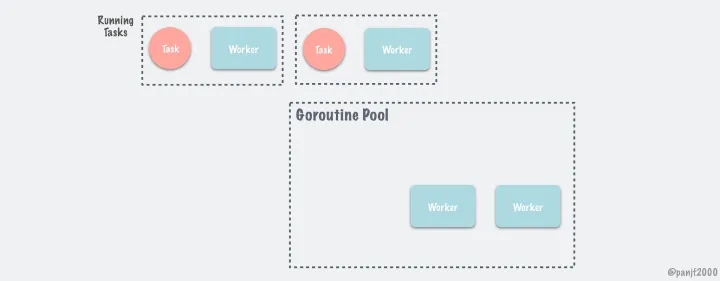
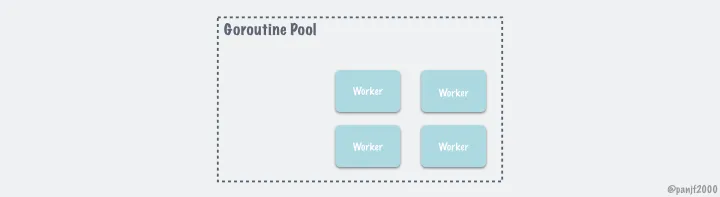
解决过大的内存申请
上报 slice 大小设置合理即可(当前业务更换了上报方式,这段代码可以删除)
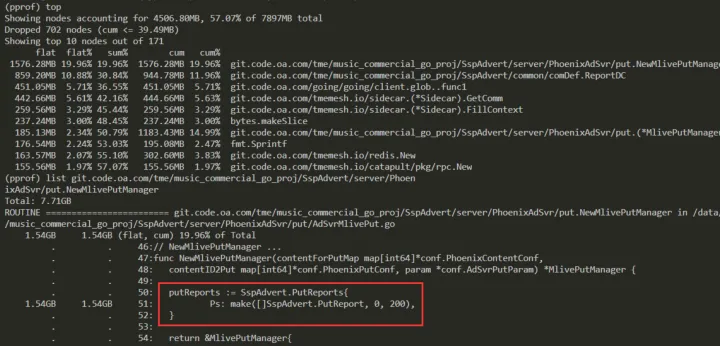
IO 业务读写合并
因为每次 set 的 key 和 value 结构不太一样,所以经过池化、内存问题解决,这里暂时先不需要合并 set 写入。
优化后压测
压测结论
在上面 3 个点(其实是 2 个点)修改后,服务性能有了明显提升,之前测试环境在相同环境 100qps/s 的情况下,会出现较多的超时问题,p90 达到 1s 左右,并且有较大的内存问题。
升级之后,qps 在测试环境能稳定在 200qps 情况下无超时,并且 p90 稳定 30-40ms 以内。另外提升到 qps300 仅出现少量超时。
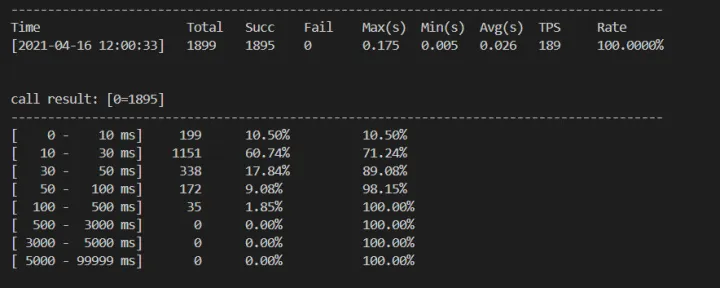
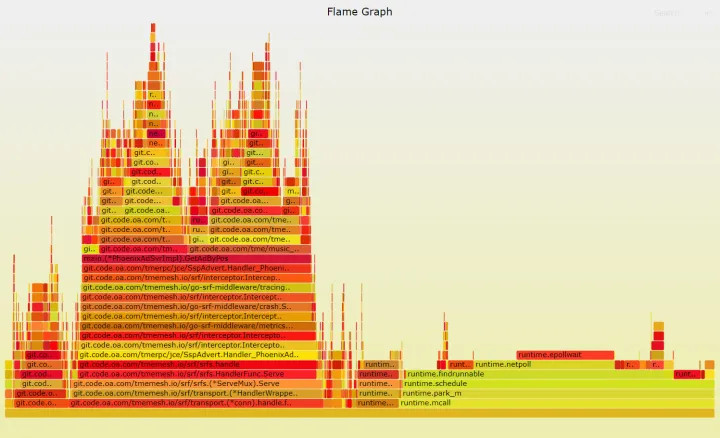
pprof 查看火焰图
可以看到异步任务由之前的占用 70%cpu,下降到 30%,有较大的优化效果。
内存效果更加明显,稳定运行一段时间,内存无明显增长。内存问题得到解决。
trace 查看调度
首先协程数量大大减少。
由于内存申请释放较少,在 qps 是原来 3 倍的情况下,此时的 gc 触发时间延长到 8s,对于当前业务,算是比较合理的执行 gc 间隔。
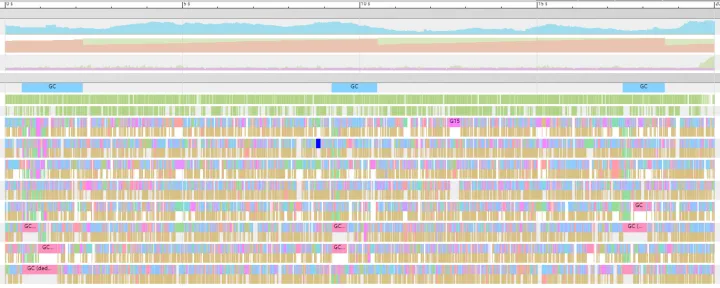
最后查看 Goroutine analysis 分析,Goroutine 基本没有太多的同步阻塞等非正常状态。
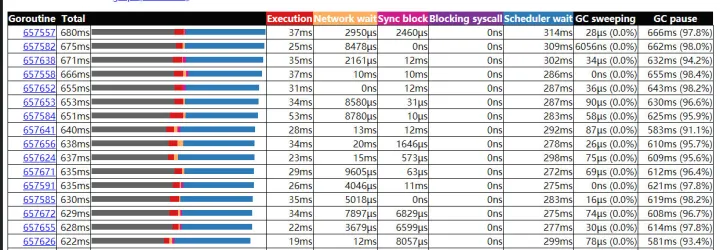
总结
经过上面 bm、pprof、trace 的结果,我们可以判断,此时系统优化已经达到比较好的效果(性能提升 3 倍+)继续深入优化的成本较高,并且收益较小。
总结一下解决性能问题的方法:
pprof 简单定位后(包括内存、cpu),其实已经没有特别明显的问题可以发现到,所以可以考虑 trace 程序查看更细节的问题。
这里我们使用 trace 生成 go trace 文件信息查看,相关调度问题。
投放服务【现网压测】
经过以上的问题修改,以及测试环境压测,已经可以说是基本可用了,所以为了保证上线没问题,我们必须要进行现网压测,只有最真实的数据才更有说服力。(然后发现了很多问题)
好的开始
会员业务属于较为简单的业务在 1000qps 下,p97 为 50ms,并且 cpu、机器负载都很低。完全可用。
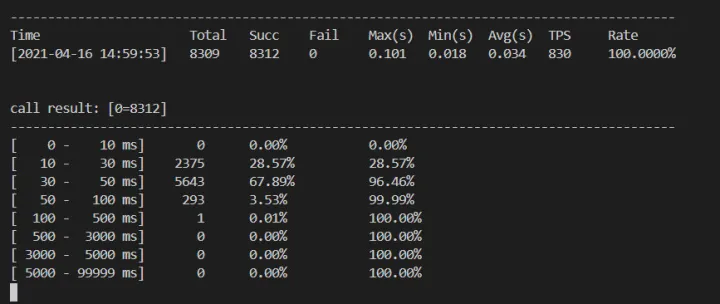
再次异常
但是直播场景压测,尝试 500qps/s 去压测服务,但是服务顺便被“打爆”,出现大量超时,并且内存急剧增长,短短几分钟 RES 达到:5G+。
所以马上保存 trace、打开 pprof 分析性能问题。
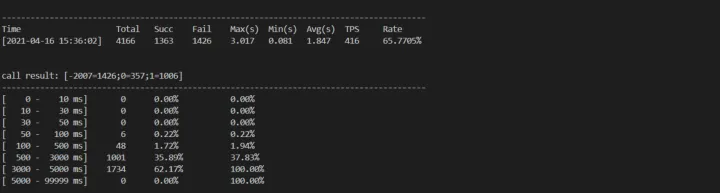
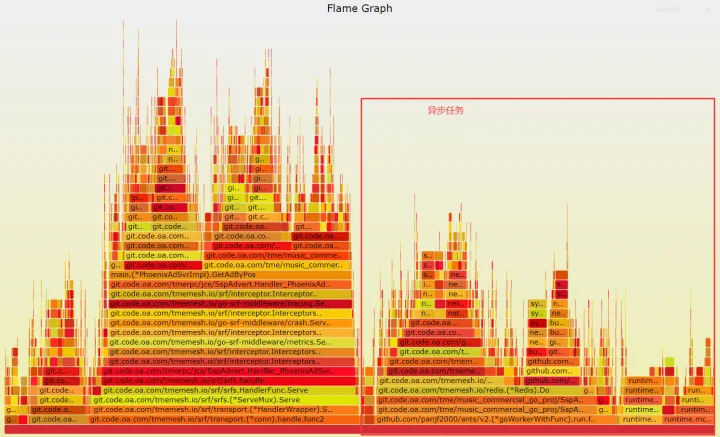
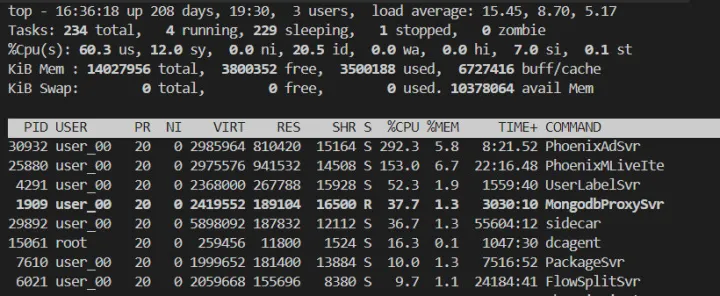
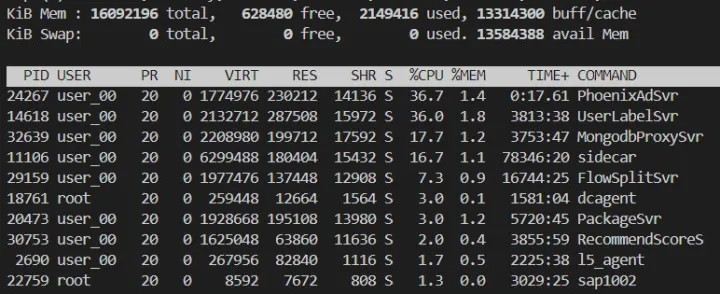
简单看了下当前的 top 信息,cpu 大约 200+,内存 RES 占用的了 5G。
CPU 元凶
打开 pprof,很明显大量 cpu 消耗在 sidecar 路由上,因为设置频控数据是有放大的,所以可能仅频控数据设置,单机都可能达到约 3000qps/s 请求 redis,此时 sidecar 寻址消耗是比较明显的,根据我们业务特点,此时还是使用配置文件,使用 l5 寻址方式去访问 redis。
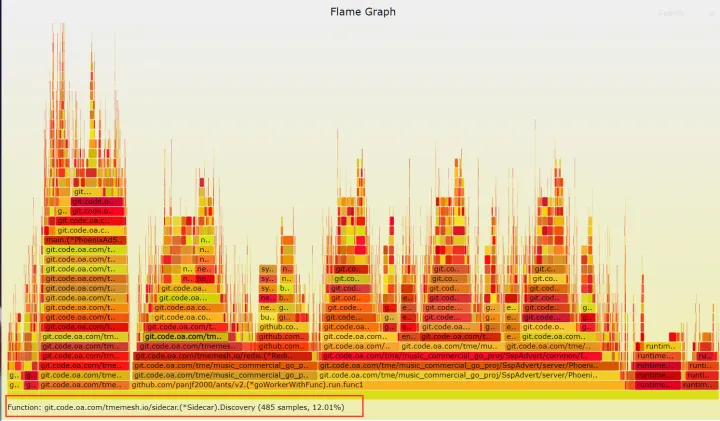
内存元凶
上面 top 分析 RES 占用巨大,所以肯定还有内存问题,这里我还是使用 pprof 查看具体那一行代码有问题。
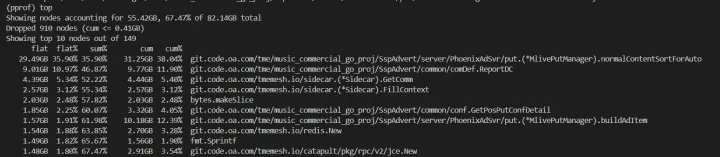
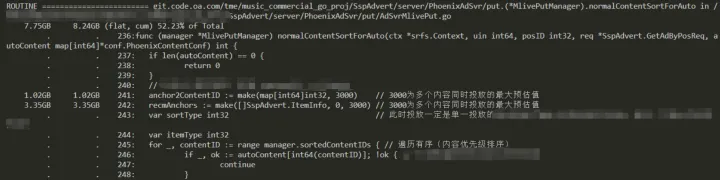
所以查看代码,我们发现还是由于初始化 slice 不合理导致,这里是根据最大开播主播设置的 1 个较大的值,所以还是业务代码不合理导致这个问题。
胜利的曙光?
通过修复上面的问题,然后编译 → 发布后再次观察。
此时内存没有明显的增长,并且开始运行也没太多的延迟。
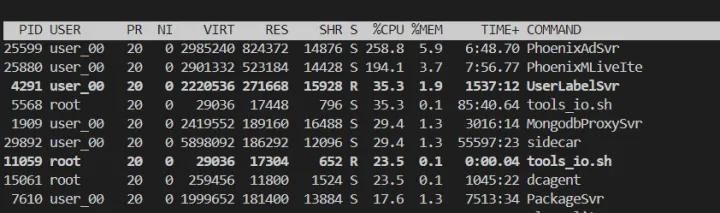
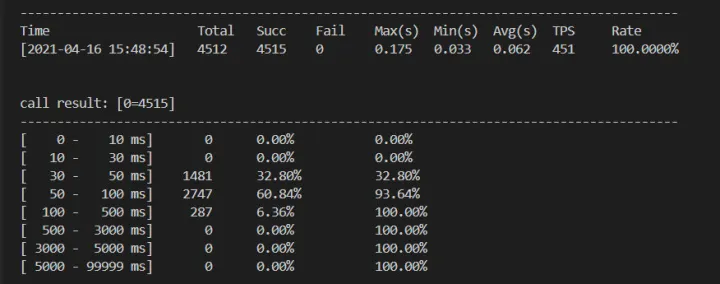
好像就这样结束了?
一波三折
然而,上个了厕所回来之后,发现延迟开始增加,有点雪崩的意思。。。此时平均时延达到了 1.5s!这时候的现象就是运行了一段时候之后,程序逐渐雪崩。
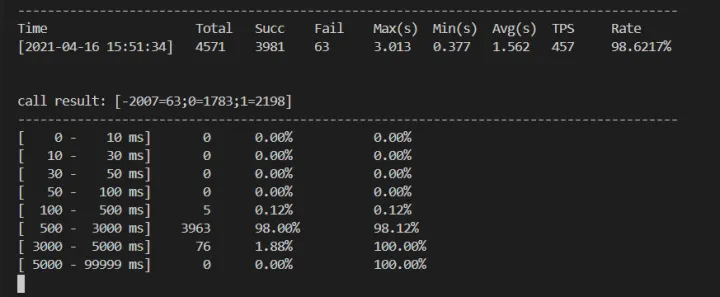
再次打开 pprof、trace 继续跟踪。。。
此时由于上面优化,使用配置文件的寻址,修改不合理的 slice 设置,我们从 pprof 并没有发现明显的性能问题。
但是注意到此时 gc 占用接近整体的 25%,那么此时我们就需要考虑,代码是否涉及到大量小内存申请(池化)、以及反射(比如 fmt、json)。
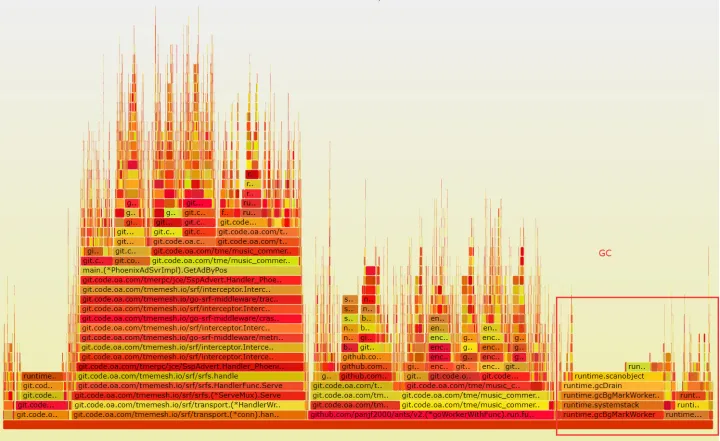
从内存问题角度出发,trace 代码后我们发现,一些问题比如 json、以及上报部分的反射使用。

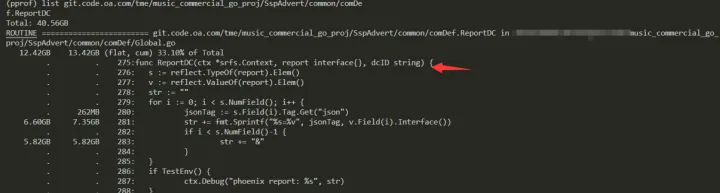
所以这里比较快的解决方案是:
- 更换更高效的 json 库
- 上报简单写,不使用反射
更换了下面这个 json 库:github.com/json-iterator/go
以及做了代码调整,取消使用反射(最简单的才是最快的)
如释重负
经过上面的修改后,马上编译 → 发布服务,在 500qps 情况下压测!
这次的结果就很 ok,运行很长一段时间,基本 p90 在 100-200ms 之间,可以满足基本业务需求。
此时服务的 cpu 较高,但是可以满足使用需求。
我们此时再次 pprof 查看内存情况,结果还是很 ok 的,内存问题暂时解决。


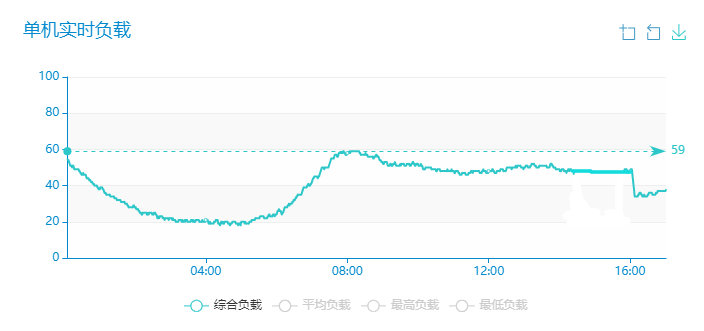
机器负载
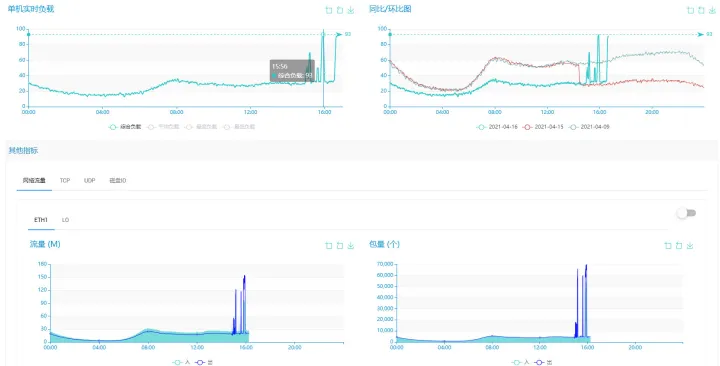
此次压测的投放服务和内容服务是混布的(2 个即将发布的服务),互相难免有些影响,上线后独立部署预计投放服务的 qps 会高很多。
查看一下机器的负载记录,当前机器仅有少量其他业务,基本在我们测试过程中,机器已经达到极限。
实际上线
业务低峰期 cpu:130
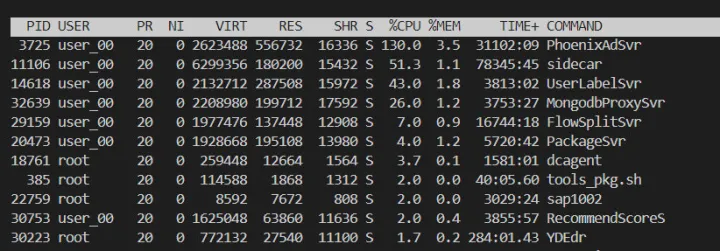
发布后 cpu:40
总结
go pprof 确实强大,可以很方便的定为问题。另外在优化过程中主要还是考虑 cpu 和内存问题,io、锁等问题可能较少。
通常可能遇到的问题:
- 初始化不合理
- 并发较多,没有做合并
- routine 过多,没有管理
- 反射对内存、cpu 的影响
- 另外考虑池化解决小内存申请过多
- g 调度延迟问题
- 等等
最重要的是关键服务一定要压测,一定要在真实环境压测!!!
内容服务【外网压测】
这个服务主要是给投放服务提供内容(主播、广告),也就是投放服务调用内容服务。此服务会执行一些频控、流量控制等操作。
在业务低峰期此时 cpu 比投放服务高的多(2 倍),肯定存在一些瓶颈需要优化。
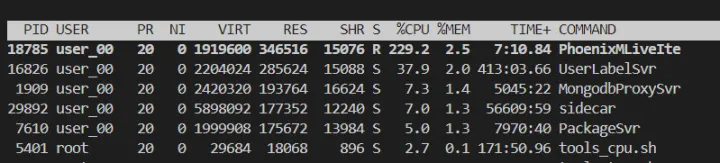
这里内容服务遇到的问题和投放服务稍有不同,例如:gc 频繁,这里记录一下 gc 频繁等问题的排查思路,和上面文章做一些互补。
这里先简单看一下 pprof 的 cpu、内存、routine 等方面的问题。
查看 CPU 问题
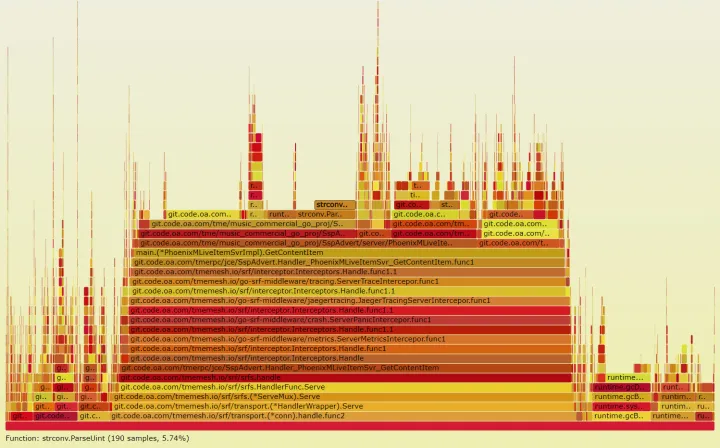
程序在运行大约 30 分钟后,我们 pprof 查看 CPU 发现有很明显问题的:
- 有些明显的“业务”类型函数调用次数很多(例如判断 2 个 slice 中重复的元素)。
- 另外 gc 项也有些占用(gcbackxxx),理论上业务服务 qps 较高时,gc 占用不会特别明显才对。
查看内存问题
程序在运行大约 30 分钟后,我们 pprof 查看内存发现有些和 CPU 维度不一样的问题:
- 某些 case 在短时存在大量的内存申请、释放问题。
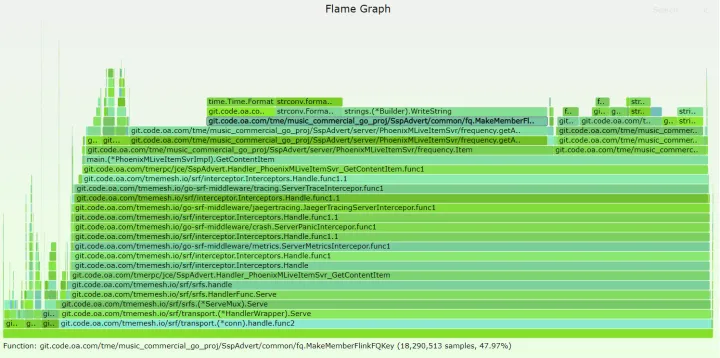
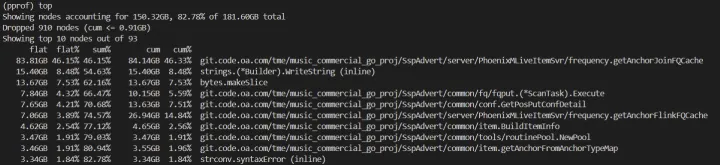
查看 gc 问题
这里 trace 之后,可以比较明显的发现 gc 的次数太多,1s 基本会有 2 次左右的 gc。
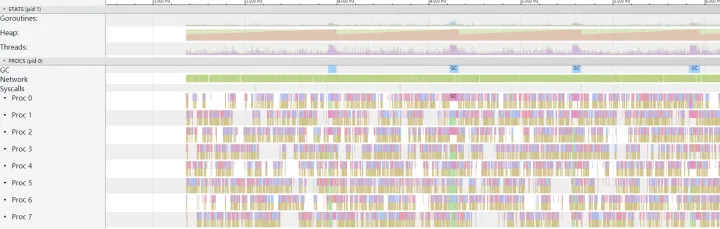
初步结论
通过以上分析,这里可以发现几个明显的问题需要取解决:
- “业务”函数(例如判断 2 个 slice 中重复的元素)调用过度,这里需要查看有没有不合理的地方。
- 内存申请过度,这里需要有没有不合理,或者需要考虑池化。
- gc 过于频繁一般也是和内存关系比较大,所以需要优先排查内存问题。
除了业务函数方面,在内存上我们可以看一下具体代码,内存分配的情况:

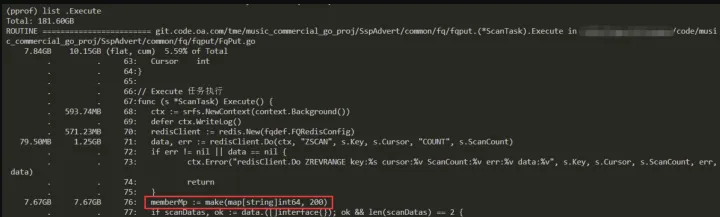
这里主要是一些临时变量的申请和释放,这里有两方面的问题:
- map[string]int,这里 string 类型是否考虑可以使用无内存、gc 扫描的基本类型,例如 int64。
- map[int]int,这种结构是否可以使用 slice 代替,这也是官方 pprof 示例中给出的优化方向。
解决问题
业务函数问题
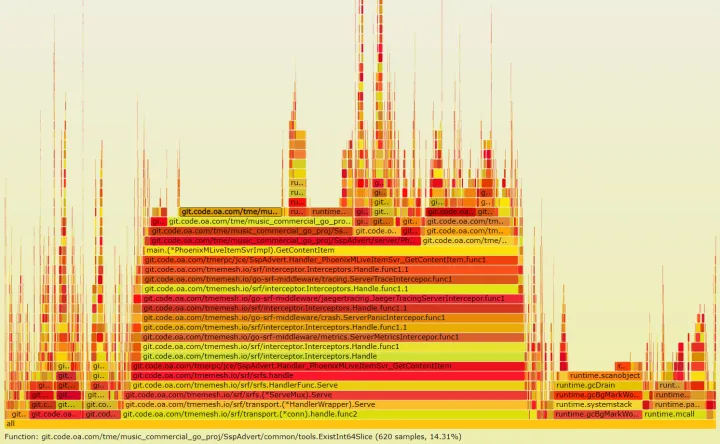
这里是匹配 2 个 slice 数据,检查 1 个 slice 的值是否存在于另一个 slice,时间复杂度为 O(nm)
这里一般 2 个优化:
- 可以先排序其中 1 个 slice,然后根据另一个 slice 迭代二分查找,复杂度降为:O(n)+O(m)*O(logn)。
- 另外从业务手段上是否可以不比较,修改部分逻辑减少无效的计算。(最终优化逻辑,不比较也可以满足要求)
字符串 key 构造问题
这里本地存储 gcache 是每个主播的一些频控数据信息,key 构造的很复杂是一个比较大的字符串,这里可以如下优化一下:
这里优化直接使用主播 id 即可。
- 本地内存查询,只需要简单的主播 id 查询数据即可,节省了很多字符串拼接所需的内存。
- 另外减少 fmt 类型的 key 构造,在 qps 高以及内部访问放大的情况下,这里的优化还是有必要的,例如使用 stringbuilder 等。

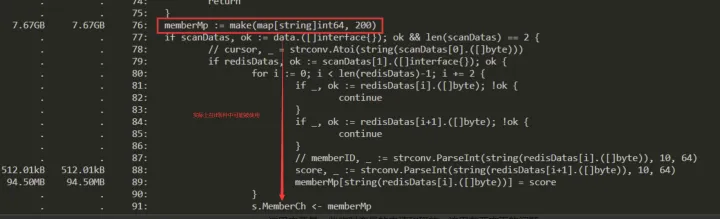
临时变量申请问题
这里也是业务逻辑需要注意的,if 条件中可能只有一小部分用户访问会进入,这里稍大的临时变量没有必要每次都需要申请,另外申请的 cap 大小也应该是可预估的。
修改前:
修改后:
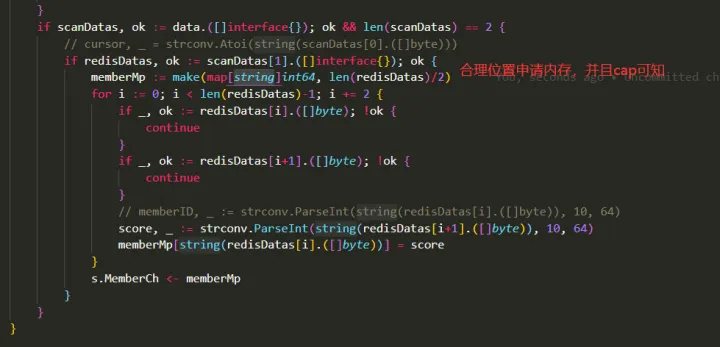
另外为了解决 map[string]int64,中指针类型对于 gc 的影响,这里修改类型为普通类型,无指针引用的 map[int64]int64 类型。可以参考 bigcache 中的优化。
大块内存申请问题

这里可能需要使用 pool 解决。
但是实际情况是,如果使用了 map 作为池,pool 的老 map 数据还需要清理,这里简单做了 benchmark,这里的测试方法是,pool 每次申请 2000 大小的 map[int]int,然后做一些简单操作后重新 put 进入 pool 中。
这里的结果是不使用 pool 的 map 效率更高!
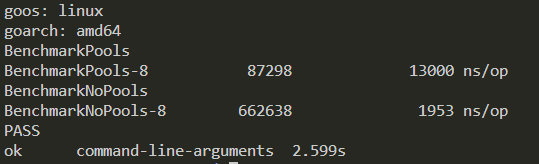
经过上面的 benchmark 分析,以及使用 map 对象 pool 比较繁琐,故这里暂不修改。
优化对比
优化前:
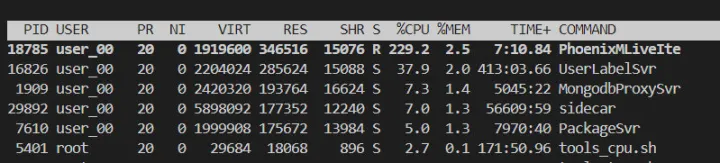
优化后:
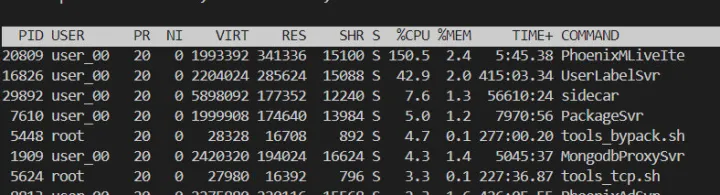
性能大约提升了 60%+:
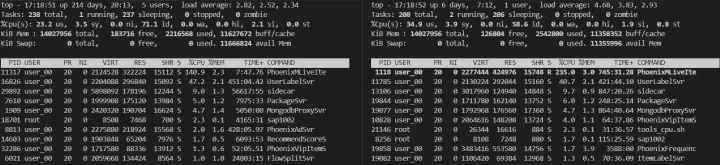
调优结论
结论梳理:
- 根据以上优化结果,我们提升了 60%的性能
- 实际的 gc 间隔也延长了,大约减少 25%的 gc 次数
查看 trace 图其中 gc 间隔延迟,查看火焰图在 cpu 方面已经没有明显的业务瓶颈,但是内存瓶颈依然存在,因为存在较多的内存申请释放,但是目前没有很好的优化手段。
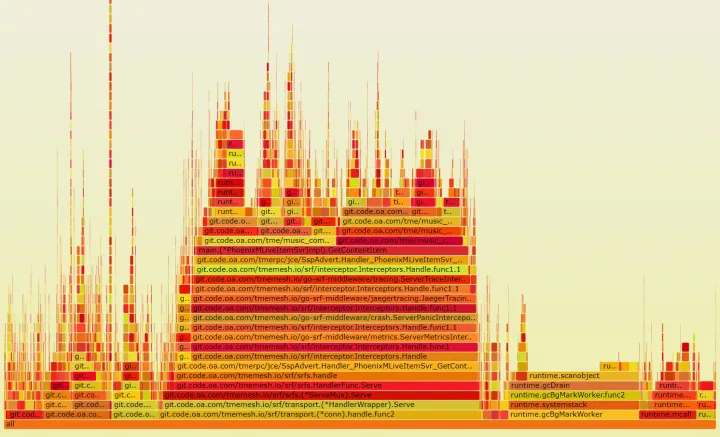
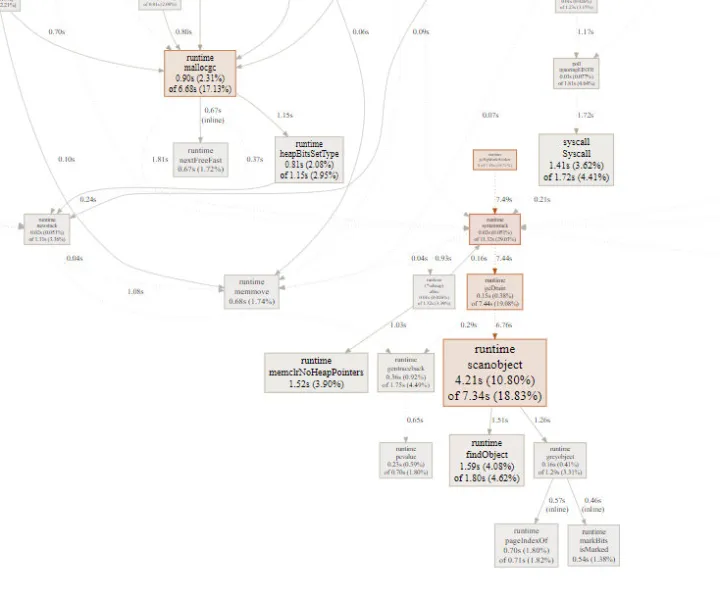
调优方法梳理
这里总结一下上面的优化手段:
- 对于 map,如果存在大量的临时变量使用,那么我们优先考虑是否可以避免这些 map 对 gc 的影响,比如把 key 和 value 设置为非指针的普通类型,比如:int(bigcache 优化手段之一)。
- 在 cpu 密集计算的过程中,有效减少计算时间复杂度是很好的手动,比如:复杂度 O(nm)降为 O(n)+O(m)*O(logn)。
- 在 string 类型拼接的过程中,如果存在大量调用,我们可以考虑更高效的字符串拼接方法,比如:stringbuilde 代替 fmt。
- 极端的如果 string 可以作为 key,那么我们业务是否可以考虑使用 int 等基本类型作为 key,这里我们在使用内存缓存查询某些数据,尽可能的设计简单。
- 另外减少无效的内存申请,无效的循环等也是一个业务优化手段。
- 等等...
go 优化建议
1 将多个小对象合并成一个大的对象
2 减少不必要的指针间接引用,多使用 copy 引用
例如使用bytes.Buffer代替*bytes.Buffer,因为使用指针时,会分配 2 个对象来完成引用。
3 局部变量逃逸时,将其聚合起来
这一点理论跟 1 相同,核心在于减少 object 的分配,减少 gc 的压力。 例如,以下代码
for k, v := range m {
k, v := k, v // copy for capturing by the goroutine
go func() {
// use k and v
}()
}
可以修改为:
for k, v := range m {
x := struct{ k, v string }{k, v} // copy for capturing by the goroutine
go func() {
// use x.k and x.v
}()
}
修改后,逃逸的对象变为了 x,将 k,v2 个对象减少为 1 个对象。
4 []byte的预分配
当我们比较清楚的知道[]byte会到底使用多少字节,我们就可以采用一个数组来预分配这段内存。 例如:
type X struct {
buf []byte
bufArray [16]byte // Buf usually does not grow beyond 16 bytes.
}
func MakeX() *X {
x := &X{}
// Preinitialize buf with the backing array.
x.buf = x.bufArray[:0]
return x
}
5 尽可能使用字节数少的类型
当我们的一些 const 或者计数字段不需要太大的字节数时,我们通常可以将其声明为int8类型。
6 减少不必要的指针引用
当一个对象不包含任何指针(注意:strings,slices,maps 和 chans 包含隐含的指针),时,对 gc 的扫描影响很小。 比如,1GB byte 的 slice 事实上只包含有限的几个 object,不会影响垃圾收集时间。 因此,我们可以尽可能的减少指针的引用。
7 使用sync.Pool来缓存常用的对象
8 使用 slice 代替 map
=https://software.intel.com/content/www/us/en/develop/blogs/debugging-performance-issues-in-go-programs.html
https://blog.golang.org/pprof
![[附源码]java毕业设计基于的考研408课程学习平台](https://img-blog.csdnimg.cn/2b4fc346ad5549cf88bfe860e466601c.png)