ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
-
更强大的性能:基于 ChatGLM 初代模型的开发经验,全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
-
更长的上下文:基于 FlashAttention 技术,将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练。对于更长的上下文,发布了 ChatGLM2-6B-32K 模型。LongBench 的测评结果表明,在等量级的开源模型中,ChatGLM2-6B-32K 有着较为明显的竞争优势。
-
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
-
更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
一、ChatGLM2-6B评测结果
下面是ChatGLM2-6B 模型在 MMLU (英文)、C-Eval(中文)、GSM8K(数学)、BBH(英文) 上的测评结果。在 evaluation 中提供了在 C-Eval 上进行测评的脚本。
MMLU
| Model | Average | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|
| ChatGLM-6B | 40.63 | 33.89 | 44.84 | 39.02 | 45.71 |
| ChatGLM2-6B (base) | 47.86 | 41.20 | 54.44 | 43.66 | 54.46 |
| ChatGLM2-6B | 45.46 | 40.06 | 51.61 | 41.23 | 51.24 |
| ChatGLM2-12B (base) | 56.18 | 48.18 | 65.13 | 52.58 | 60.93 |
| ChatGLM2-12B | 52.13 | 47.00 | 61.00 | 46.10 | 56.05 |
Chat 模型使用 zero-shot CoT (Chain-of-Thought) 的方法测试,Base 模型使用 few-shot answer-only 的方法测试
C-Eval
| Model | Average | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|
| ChatGLM-6B | 38.9 | 33.3 | 48.3 | 41.3 | 38.0 |
| ChatGLM2-6B (base) | 51.7 | 48.6 | 60.5 | 51.3 | 49.8 |
| ChatGLM2-6B | 50.1 | 46.4 | 60.4 | 50.6 | 46.9 |
| ChatGLM2-12B (base) | 61.6 | 55.4 | 73.7 | 64.2 | 59.4 |
| ChatGLM2-12B | 57.0 | 52.1 | 69.3 | 58.5 | 53.2 |
Chat 模型使用 zero-shot CoT 的方法测试,Base 模型使用 few-shot answer only 的方法测试
GSM8K
| Model | Accuracy | Accuracy (Chinese)* |
|---|---|---|
| ChatGLM-6B | 4.82 | 5.85 |
| ChatGLM2-6B (base) | 32.37 | 28.95 |
| ChatGLM2-6B | 28.05 | 20.45 |
| ChatGLM2-12B (base) | 40.94 | 42.71 |
| ChatGLM2-12B | 38.13 | 23.43 |
所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 http://arxiv.org/abs/2201.11903
使用翻译 API 翻译了 GSM8K 中的 500 道题目和 CoT prompt 并进行了人工校对
BBH
| Model | Accuracy |
|---|---|
| ChatGLM-6B | 18.73 |
| ChatGLM2-6B (base) | 33.68 |
| ChatGLM2-6B | 30.00 |
| ChatGLM2-12B (base) | 36.02 |
| ChatGLM2-12B | 39.98 |
所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 https://github.com/suzgunmirac/BIG-Bench-Hard/tree/main/cot-prompts
二、推理性能
ChatGLM2-6B 使用了 Multi-Query Attention,提高了生成速度。生成 2000 个字符的平均速度对比如下
| Model | 推理速度 (字符/秒) |
|---|---|
| ChatGLM-6B | 31.49 |
| ChatGLM2-6B | 44.62 |
使用官方实现,batch size = 1,max length = 2048,bf16 精度,测试硬件为 A100-SXM4-80G,软件环境为 PyTorch 2.0.1
Multi-Query Attention 同时也降低了生成过程中 KV Cache 的显存占用,此外,ChatGLM2-6B 采用 Causal Mask 进行对话训练,连续对话时可复用前面轮次的 KV Cache,进一步优化了显存占用。因此,使用 6GB 显存的显卡进行 INT4 量化的推理时,初代的 ChatGLM-6B 模型最多能够生成 1119 个字符就会提示显存耗尽,而 ChatGLM2-6B 能够生成至少 8192 个字符。
| 量化等级 | 编码 2048 长度的最小显存 | 生成 8192 长度的最小显存 |
|---|---|---|
| FP16 / BF16 | 13.1 GB | 12.8 GB |
| INT8 | 8.2 GB | 8.1 GB |
| INT4 | 5.5 GB | 5.1 GB |
ChatGLM2-6B 利用了 PyTorch 2.0 引入的
torch.nn.functional.scaled_dot_product_attention实现高效的 Attention 计算,如果 PyTorch 版本较低则会 fallback 到朴素的 Attention 实现,出现显存占用高于上表的情况。
量化对模型性能的影响如下,基本在可接受范围内。
| 量化等级 | Accuracy (MMLU) | Accuracy (C-Eval dev) |
|---|---|---|
| BF16 | 45.47 | 53.57 |
| INT4 | 43.13 | 50.30 |
三、Multi-Query-Attention(MQA)
论文地址:https://arxiv.org/pdf/1911.02150.pdf
MQA 是 19 年提出的一种新的 Attention 机制,其能够在保证模型效果的同时加快 decoder 生成 token 的速度,因此在目前大模型时代被广泛应用。下面看一下论文的实验效果:
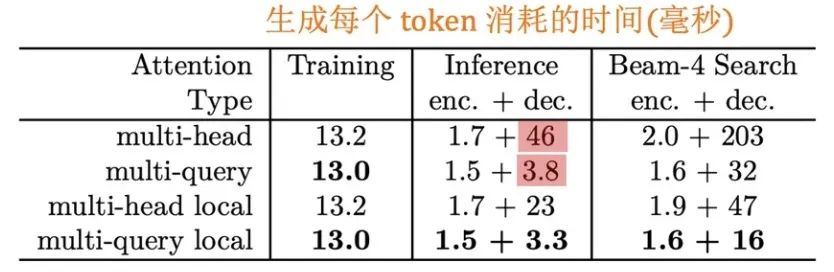
从上图表中可以看到,MQA 在 encoder 上的提速没有非常明显,但在 decoder 上的提速是很显著的。
传统的Transformer是Multi Head Attention(MHA)结构,每个 head 又是由: query(Q),key(K),value(V) 3 个矩阵共同实现的,这三个矩阵的参数都是独立的,而MQA 让所有的头之间 共享 同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
他们的关键区别在于Wqkv的实现上,下面展示一下代码示例:
# Multi Head Attentionself.Wqkv = nn.Linear( # 【关键】Multi-Head Attention 的创建方法self.d_model,3 * self.d_model, # 有 query, key, value 3 个矩阵, 所以是 3 * d_modeldevice=device)query, key, value = qkv.chunk( # 【关键】每个 tensor 都是 (1, 512, 768)3,dim=2)# Multi Query Attentionself.Wqkv = nn.Linear( # 【关键】Multi-Query Attention 的创建方法d_model,d_model + 2 * self.head_dim, # 只创建 query 的 head 向量,所以只有 1 个 d_modeldevice=device, # 而 key 和 value 不再具备单独的头向量)query, key, value = qkv.split( # query -> (1, 512, 768)[self.d_model, self.head_dim, self.head_dim], # key -> (1, 512, 96)dim=2 # value -> (1, 512, 96))
在 MHA 中,query, key, value 每个向量均有 768 维度;而在 MQA 中,只有 query 是 768 维,而 key 和 value 只有 96 维,恰好是 1 个 head_dim 的维度。除了 query 向量还保存着 8 个头,key 和 value 向量都只剩 1 个「公共头」了
下面来测试一下MHA和MQA维度的变化:
import mathimport warningsimport torchimport torch.nn as nnfrom einops import rearrangefrom typing import Optionaldef scaled_multihead_dot_product_attention(query,key,value,n_heads,past_key_value=None,softmax_scale=None,attn_bias=None,key_padding_mask=None,is_causal=False,dropout_p=0.0,training=False,needs_weights=False,multiquery=False,):q = rearrange(query, 'b s (h d) -> b h s d', h=n_heads) # (1, 512, 768) -> (1, 8, 512, 96)kv_n_heads = 1 if multiquery else n_headsk = rearrange(key, 'b s (h d) -> b h d s', h=kv_n_heads) # (1, 512, 768) -> (1, 8, 96, 512) if not multiquery# (1, 512, 96) -> (1, 1, 96, 512) if multiqueryv = rearrange(value, 'b s (h d) -> b h s d', h=kv_n_heads) # (1, 512, 768) -> (1, 8, 512, 96) if not multiquery# (1, 512, 96) -> (1, 1, 512, 96) if multiqueryattn_weight = q.matmul(k) * softmax_scale # (1, 8, 512, 512)attn_weight = torch.softmax(attn_weight, dim=-1) # (1, 8, 512, 512)out = attn_weight.matmul(v) # (1, 8, 512, 512) * (1, 1, 512, 96) = (1, 8, 512, 96)out = rearrange(out, 'b h s d -> b s (h d)') # (1, 512, 768)return out, attn_weight, past_key_valueclass MultiheadAttention(nn.Module):"""Multi-head self attention.Using torch or triton attention implemetation enables user to also useadditive bias."""def __init__(self,d_model: int,n_heads: int,attn_impl: str = 'triton',clip_qkv: Optional[float] = None,qk_ln: bool = False,softmax_scale: Optional[float] = None,attn_pdrop: float = 0.0,low_precision_layernorm: bool = False,verbose: int = 0,device: Optional[str] = None,):super().__init__()self.attn_impl = attn_implself.clip_qkv = clip_qkvself.qk_ln = qk_lnself.d_model = d_modelself.n_heads = n_headsself.softmax_scale = softmax_scaleif self.softmax_scale is None:self.softmax_scale = 1 / math.sqrt(self.d_model / self.n_heads)self.attn_dropout_p = attn_pdropself.Wqkv = nn.Linear(self.d_model, 3 * self.d_model, device=device)fuse_splits = (d_model, 2 * d_model)self.Wqkv._fused = (0, fuse_splits) # type: ignoreself.attn_fn = scaled_multihead_dot_product_attentionself.out_proj = nn.Linear(self.d_model, self.d_model, device=device)self.out_proj._is_residual = True # type: ignoredef forward(self,x,past_key_value=None,attn_bias=None,attention_mask=None,is_causal=True,needs_weights=False,):qkv = self.Wqkv(x) # (1, 512, 2304)if self.clip_qkv:qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)query, key, value = qkv.chunk(3, dim=2) # both q, k, v: (1, 512, 768)key_padding_mask = attention_maskcontext, attn_weights, past_key_value = self.attn_fn(query,key,value,self.n_heads,past_key_value=past_key_value,softmax_scale=self.softmax_scale,attn_bias=attn_bias,key_padding_mask=key_padding_mask,is_causal=is_causal,dropout_p=self.attn_dropout_p,training=self.training,needs_weights=needs_weights,)return self.out_proj(context), attn_weights, past_key_valueclass MultiQueryAttention(nn.Module):"""Multi-Query self attention.Using torch or triton attention implemetation enables user to also useadditive bias."""def __init__(self,d_model: int,n_heads: int,attn_impl: str = 'triton',clip_qkv: Optional[float] = None,qk_ln: bool = False,softmax_scale: Optional[float] = None,attn_pdrop: float = 0.0,low_precision_layernorm: bool = False,verbose: int = 0,device: Optional[str] = None,):super().__init__()self.attn_impl = attn_implself.clip_qkv = clip_qkvself.qk_ln = qk_lnself.d_model = d_modelself.n_heads = n_headsself.head_dim = d_model // n_headsself.softmax_scale = softmax_scaleif self.softmax_scale is None:self.softmax_scale = 1 / math.sqrt(self.head_dim)self.attn_dropout_p = attn_pdropself.Wqkv = nn.Linear(d_model,d_model + 2 * self.head_dim,device=device,)fuse_splits = (d_model, d_model + self.head_dim)self.Wqkv._fused = (0, fuse_splits) # type: ignoreself.attn_fn = scaled_multihead_dot_product_attentionself.out_proj = nn.Linear(self.d_model, self.d_model, device=device)self.out_proj._is_residual = True # type: ignoredef forward(self,x,past_key_value=None,attn_bias=None,attention_mask=None,is_causal=True,needs_weights=False,):qkv = self.Wqkv(x) # (1, 512, 960)if self.clip_qkv:qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)query, key, value = qkv.split( # query -> (1, 512, 768)[self.d_model, self.head_dim, self.head_dim], # key -> (1, 512, 96)dim=2 # value -> (1, 512, 96))key_padding_mask = attention_maskif self.qk_ln:# Applying layernorm to qkdtype = query.dtypequery = self.q_ln(query).to(dtype)key = self.k_ln(key).to(dtype)context, attn_weights, past_key_value = self.attn_fn(query,key,value,self.n_heads,past_key_value=past_key_value,softmax_scale=self.softmax_scale,attn_bias=attn_bias,key_padding_mask=key_padding_mask,is_causal=is_causal,dropout_p=self.attn_dropout_p,training=self.training,needs_weights=needs_weights,multiquery=True,)return self.out_proj(context), attn_weights, past_key_valueif __name__ == '__main__':# attn = MultiQueryAttention(# 768,# 8,# 'torch'# )attn = MultiheadAttention(768,8,'torch')attn(torch.ones(size=(1, 512, 768)))
四、FlashAttention
论文地址:https://arxiv.org/abs/2205.14135
代码地址:https://github.com/HazyResearch/flash-attention
Transformer的自注意力机制(self-attention)的计算的时间复杂度和空间复杂度都与序列长度有关,时间复杂度是,所以在处理长序列的时候会变的更慢,同时内存会增长更多。通常的优化是针对计算复杂度(通过F L O P s FLOPsFLOPs 数衡量), 优化会权衡模型质量和计算速度。
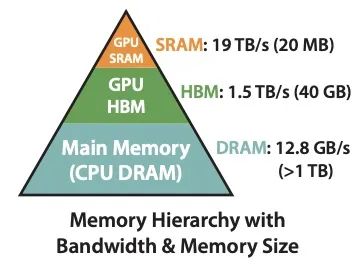
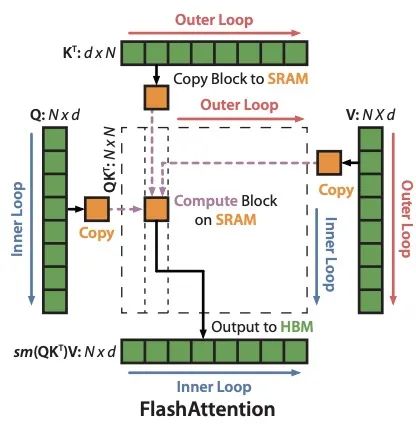
在FlashAttention中考虑到attention算法也是IO敏感的,通过对GPU显存访问的改进来对attention算法的实现进行优化。如下图,在GPU中片上存储SRAM访问速度最快,对应的HBM(high bandwidth memory)访问速度较慢,为了加速要尽量减少HBM的访问次数。
4.1 标准Transformer简述
标准的attention算法实现中的QKV都是与HBM交互的,具体如下:

4.2 FlashAttention算法实现的关键三点:
-
softmax的tiling展开,可以支持softmax的拆分并行计算,从而提升计算效率
-
反向过程中的重计算,减少大量的显存占用,节省显存开销。
-
通过CUDA编程实现fusion kernel
4.2.1 softmax展开(tiling)
- 基本softmax:在计算
的值的时候需要用到所有的
值,计算公式如下:
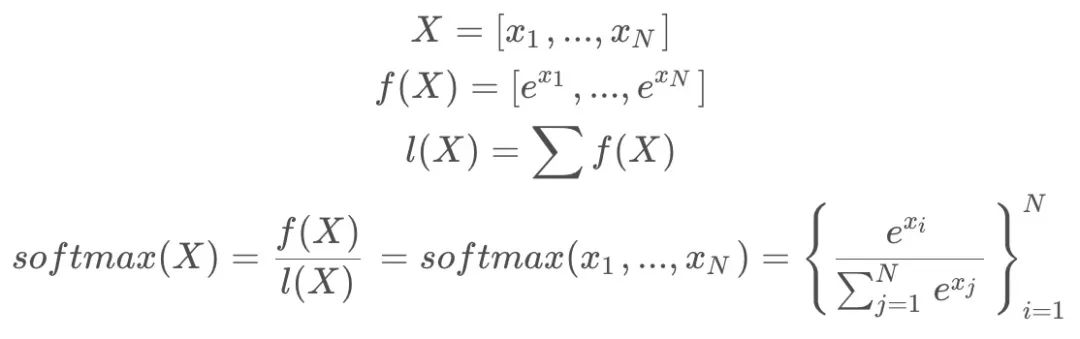
- 安全(safe) softmax:由于
很容易溢出, 比如FP16支持范围是
,当
的时候,
, 使得
, 这时幂操作符对负数输入的计算是准确且安全的。
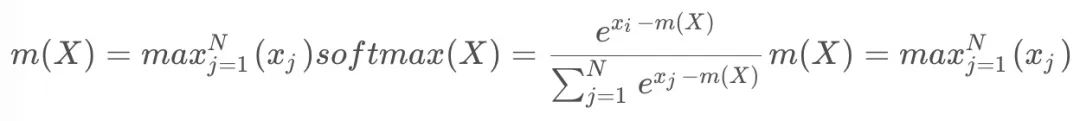
- Safe softmax tiling:对于 X 分为两组情况进行说明,其中
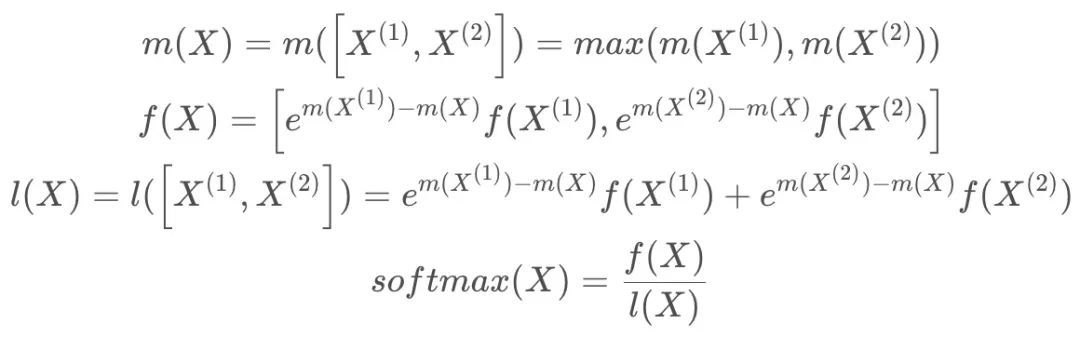
-
safe softmax基本计算示例
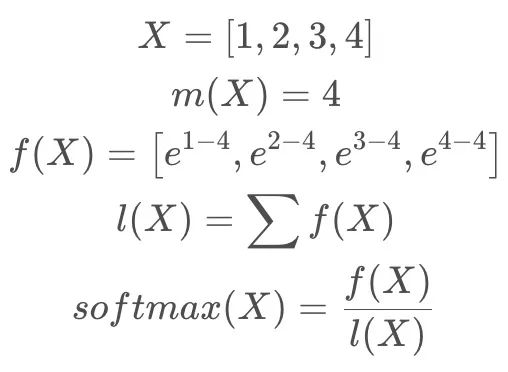
-
safe softmax tiling计算示例(结果跟基本计算示例一致)
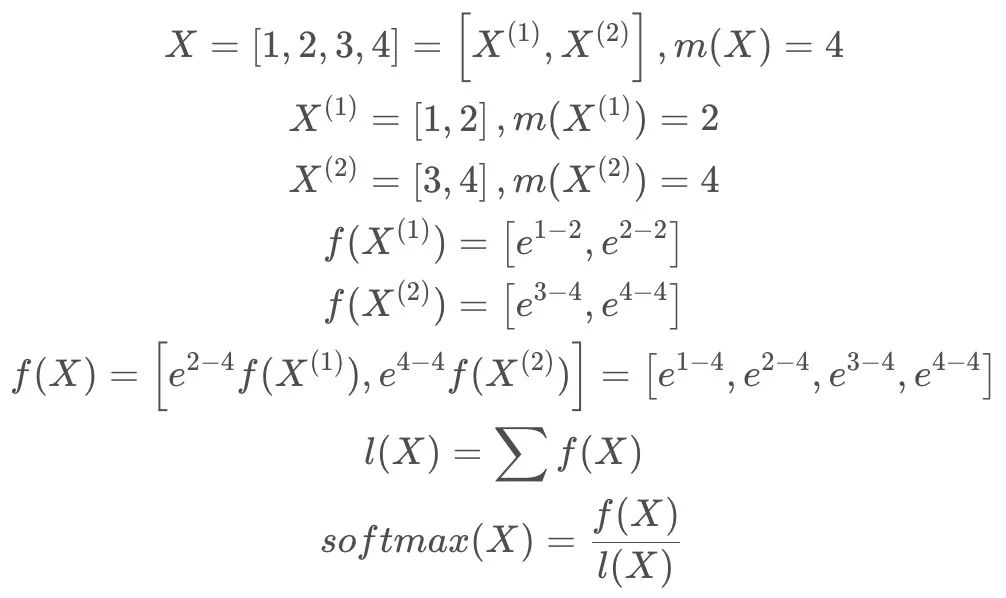
有了softmax tiling的基础以后,在执行的时候可以对Q、K、V 三个矩阵进行分块操作并行计算了,如下图所示:
4.2.2 反向过程中的重计算
类似于gradient checkpoint方法,在前向的时候把输出结果 、
、
存入HBM中, 在反向时候重新计算需要的数据,最终完整的算法说明如下:

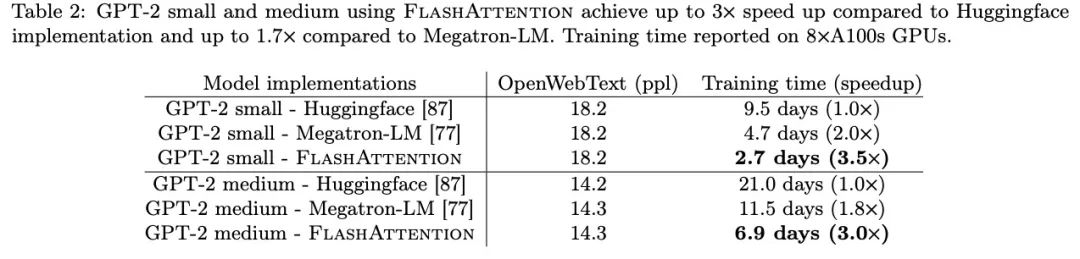
4.3 实验效果
BERT

GPT-2
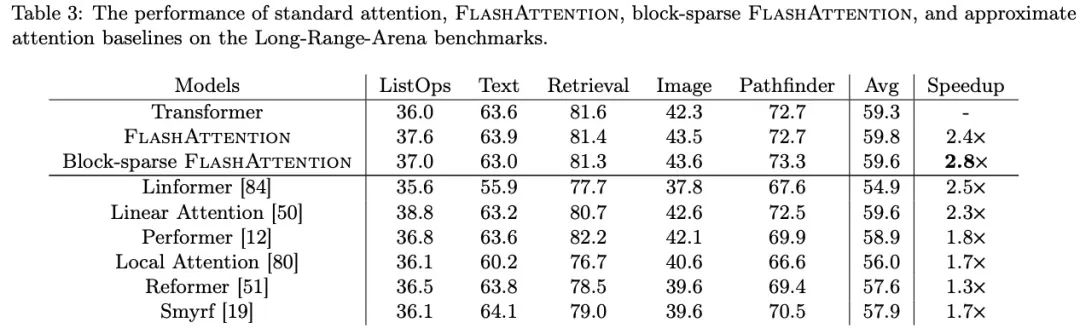
Long-range Arena
参考文献:
[1] https://github.com/THUDM/ChatGLM2-6B
[2] https://link.zhihu.com/?target=https%3A//github.com/mosaicml/llm-foundry/blob/9c89ab263e72fb9610f28c8ab9cde5d2205b6bff/llmfoundry/models/layers/attention.py
[3]https://paperswithcode.com/paper/flashattention-fast-and-memory-efficient