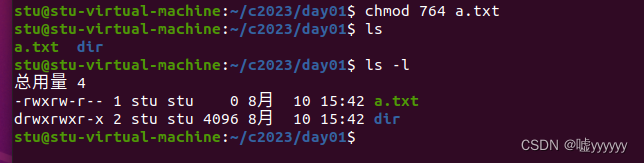
主题模型能够自动将文本语料库编码为一组具有实质性意义的类别。这些类别称为主题。
主题模型分析的典型代表就是本篇文章将要介绍的隐含迪利克雷分布,也就是LDA。
假设我们有一个文档或者新闻的集合,我们想将他们分类为主题。

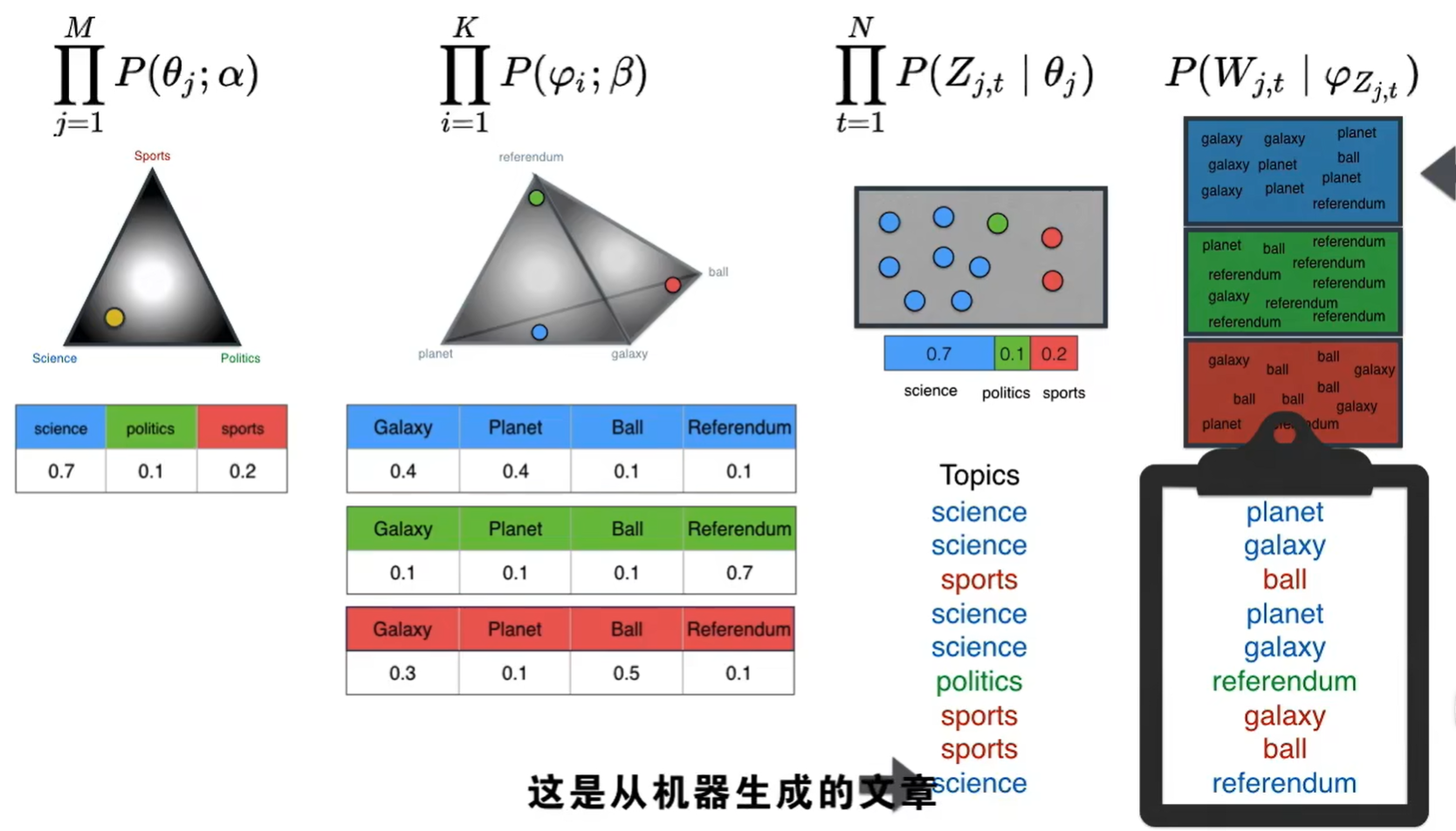
我们设置好主题数量后,运行LDA模型就会得到每个主题下边词语的分布概率,以及文档对应的主题概率。

LDA可以实现这个需求,LDA采用几何学的方法,
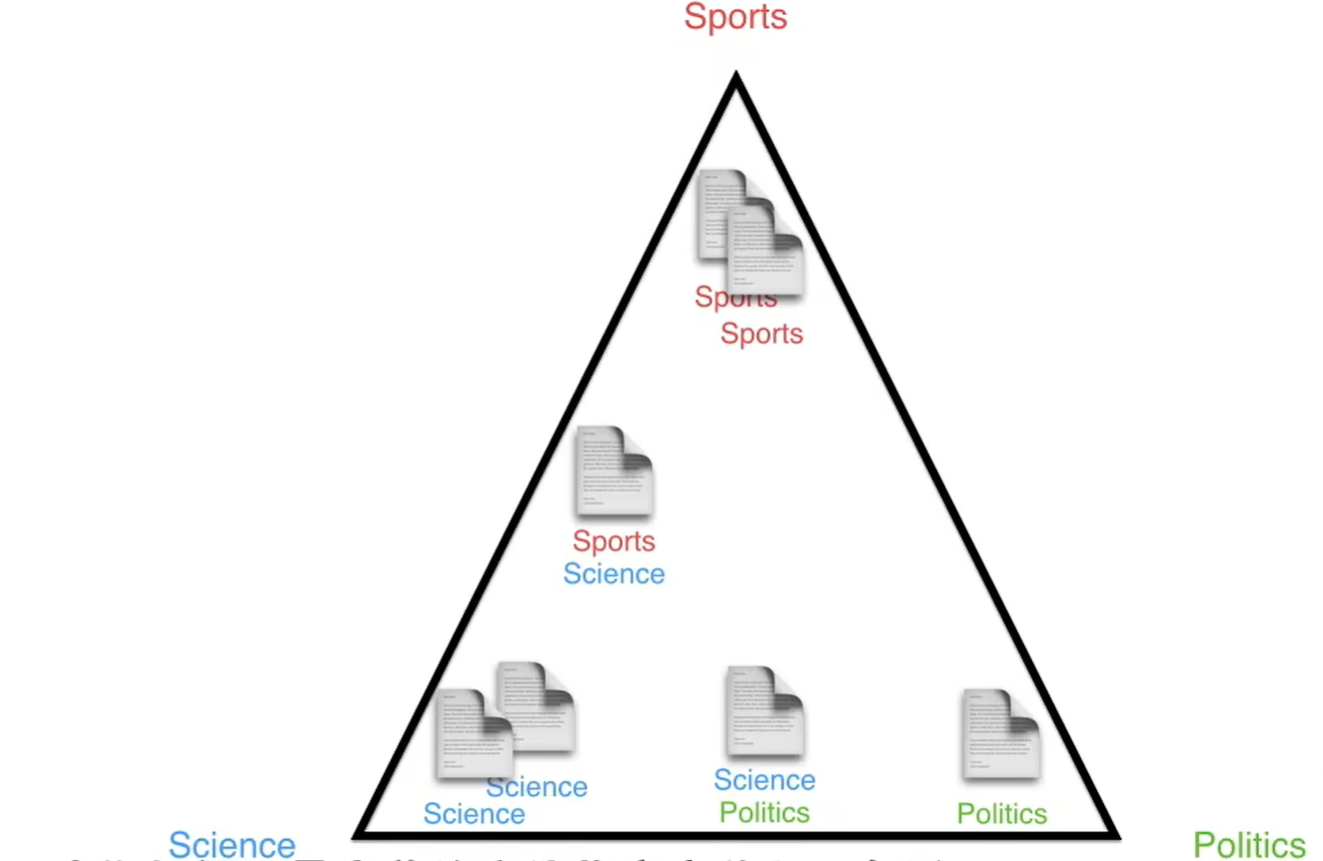
如何以最完美的方法将文章放入三角形呢?这就是LDA发挥作用的地方,我们可以把LDA看作一个生成文档的机器:
将生成的文档与原文档进行对比,以此判断模型的好坏,

LDA是怎么工作的呢?
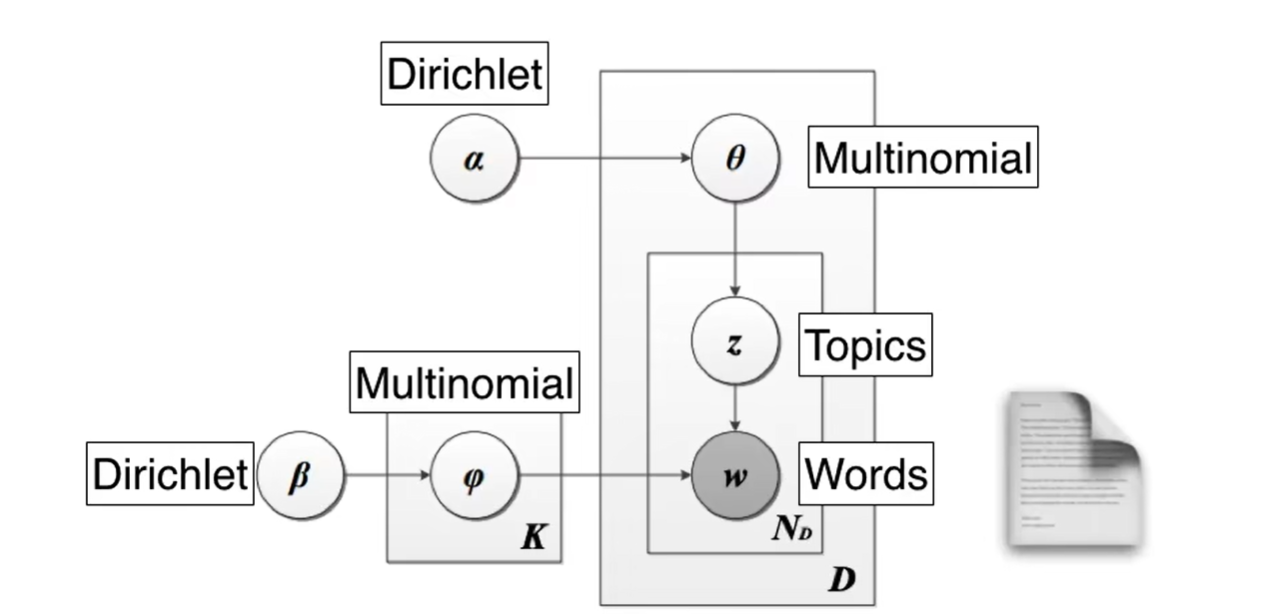
前两个是狄利克雷分布,后两个是多项式分布。
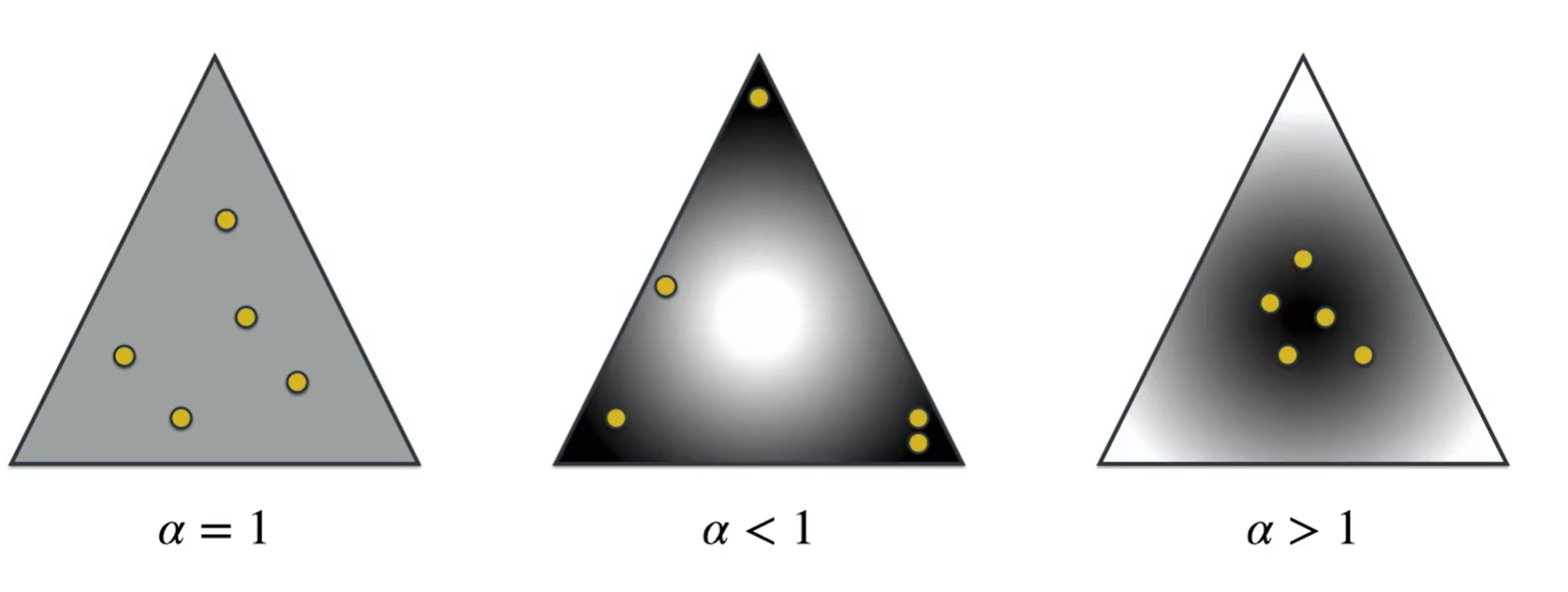
接下来看什么是狄利克雷分布,
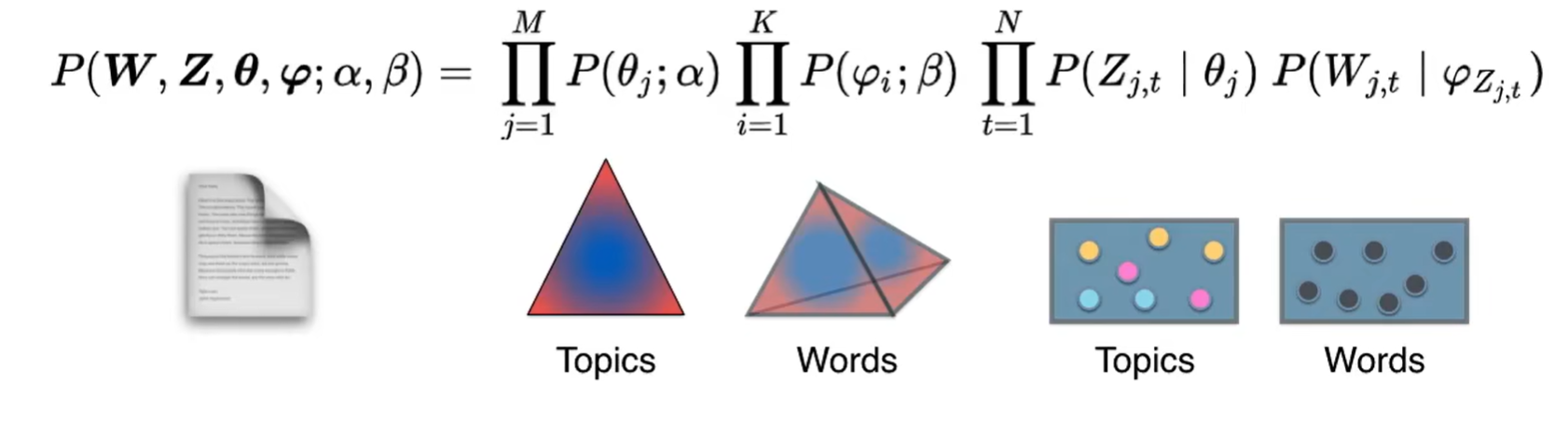
下面是狄利克雷分布的概率密度函数:

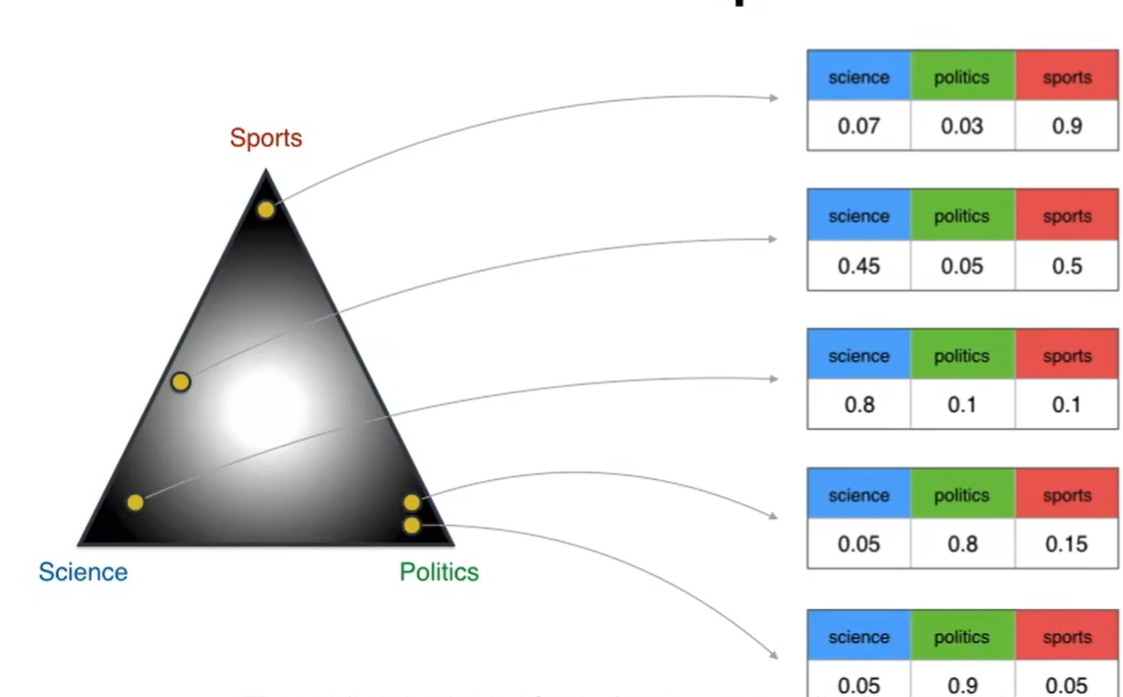
假设上图三个顶点是主题,黄色的点是文章,那么中间那个就是主题-文档的狄利克雷分布
来看另一种狄利克雷分布,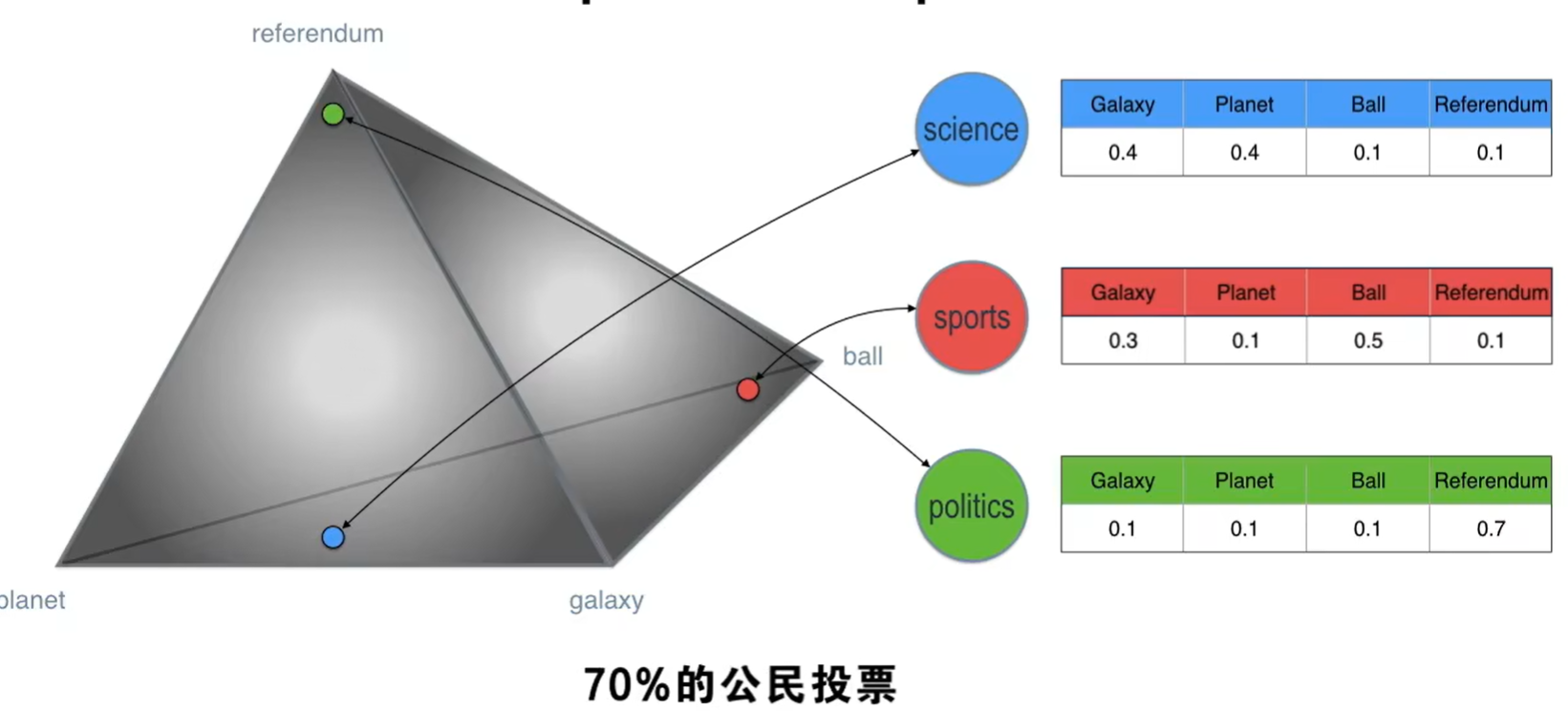
我们有两个狄利克雷分布,
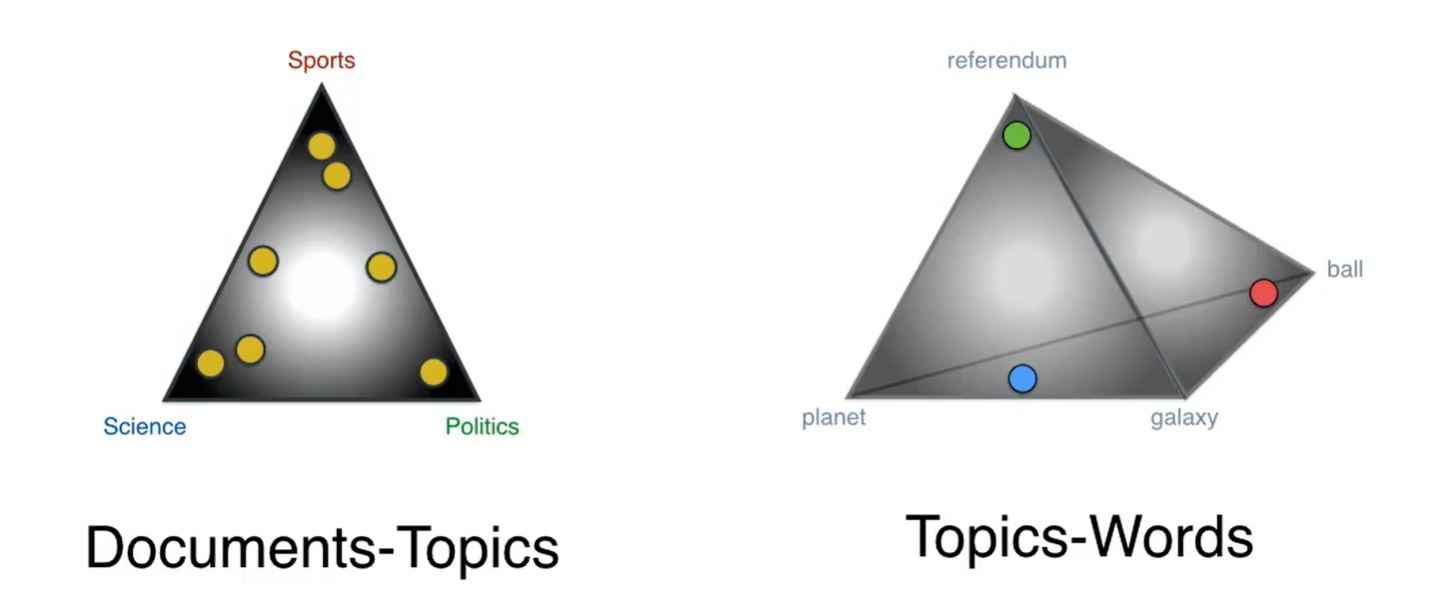
左边这个通过对应的主题把文档联系起来,右边这个通过与他们对应的单词把主题联系起来,那么这两个怎么联系起来呢?

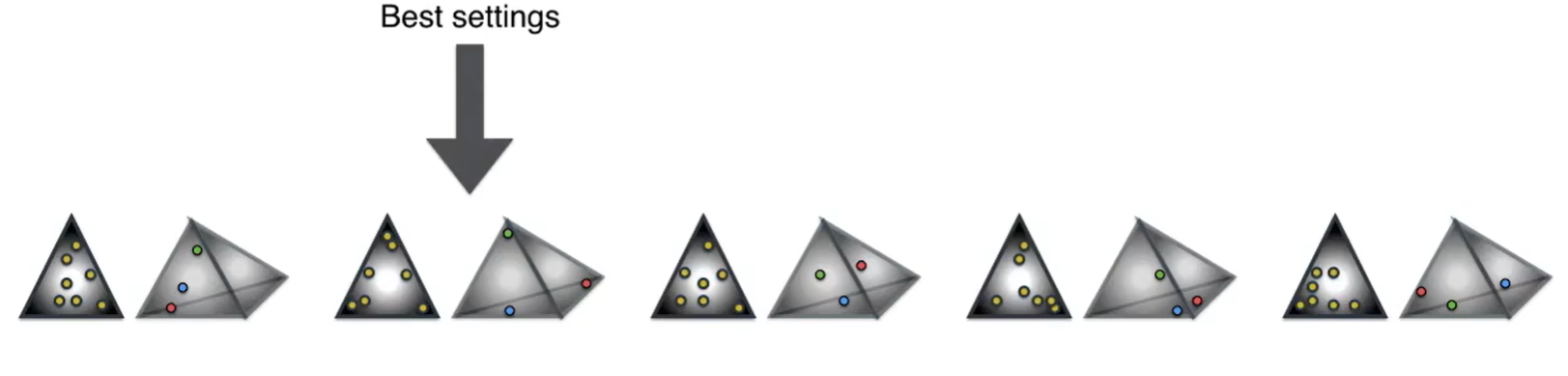
有最佳设置大的那个最有可能给出原始语料库
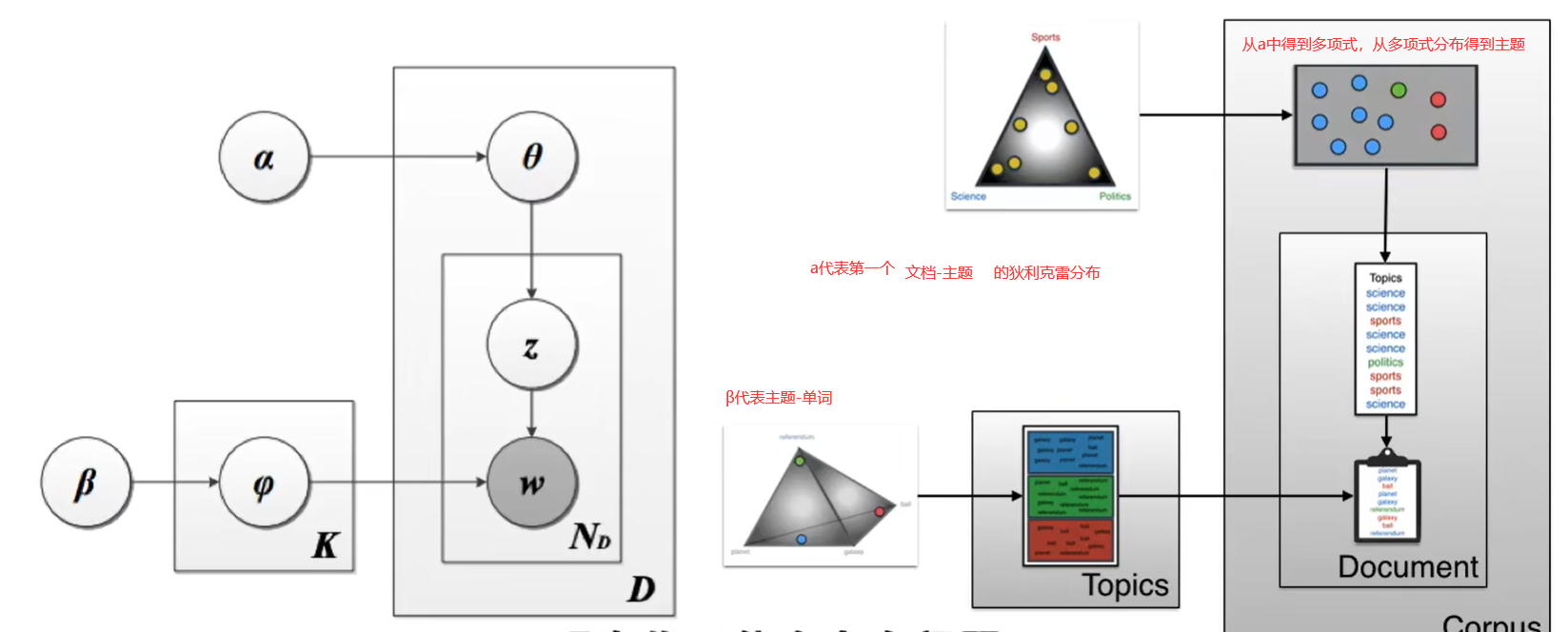
重复多次生成语料库中的大量文档,之后与原始文档进行比较,找出狄利克雷中点的最佳排布方式。从而最大化概率。
接下来介绍训练LDA模型的方法,称为gibbs采样。
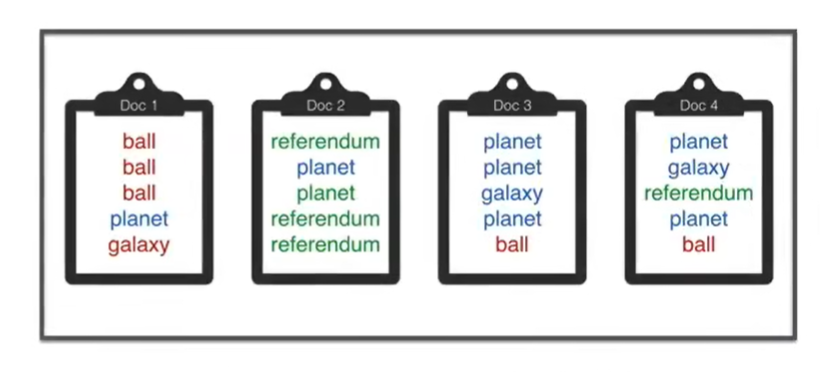
通过某种方式为每个单词着色来使这个概率最高,试图使文章更加单色,以便将我们的文档分类为主题。
视频链接

![[保研/考研机试] KY163 素数判定 哈尔滨工业大学复试上机题 C++实现](https://img-blog.csdnimg.cn/img_convert/ade46a7d882bbe21b083c568891aad74.png)