一、kafka详解
安装包下载地址:https://download.csdn.net/download/weixin_45894220/87020758
1.1Kafka是什么?
1、Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目,该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
2、Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
3、Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性
1.2kakfa与zookeeper的关系?
1、所有Broker的管理,broker 会向 zookeeper
发送心跳请求来上报自己的状态。体现在zookeeper上会有一个专门用来Broker服务器列表记录的点,节点路径为/brokers/ids
2、zookeeper 保存了 topic 相关配置,例如 topic 列表、每个 topic 的 partition数量、副本的位置等等。
3、kafka 集群中有一个或多个broker,其中有一个通过zookeeper选举为leader控制器。控制器负责管理整个集群所有分区和副本的状态,例如某个分区的 leader 故障了,控制器会选举新的 leader。
1.3常见的消息队列
我们知道常见的消息系统有Kafka、RabbitMQ、ActiveMQ等等,但是这些消息系统中所使用的消息模式如下两种:
Peer-to-Peer (Queue)
简称PTP队列模式,也可以理解为点到点。例如单发邮件,我发送一封邮件给小徐,我发送过之后邮件会保存在服务器的云端,当小徐打开邮件客户端并且成功连接云端服务器后,可以自动接收邮件或者手动接收邮件到本地,当服务器云端的邮件被小徐消费过之后,云端就不再存储(这根据邮件服务器的配置方式而定)。
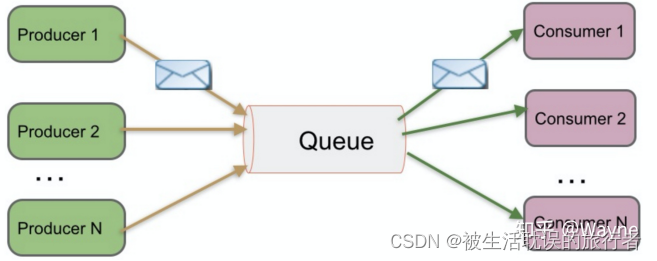
名词解释:
Producer=生产者
Queue=队列
Consumer=消费者
Peer-to-Peer模式工作原理:
1、消息生产者Producer1生产消息到Queue,然后Consumer1从Queue中取出并且消费消息。
2、消息被消费后,Queue将不再存储消息,其它所有Consumer不可能消费到已经被其它Consumer消费过的消息。
3、Queue支持存在多个Producer,但是对一条消息而言,只会有一个Consumer可以消费,其它Consumer则不能再次消费。
4、但Consumer不存在时,消息则由Queue一直保存,直到有Consumer把它消费。
Publish/Subscribe(Topic)
简称发布/订阅模式。例如我微博有30万粉丝,我今天更新了一条微博,那么这30万粉丝都可以接收到我的微博更新,大家都可以消费我的消息。
注:以下图示中的Pushlisher是错误的名词,正确的为Publisher
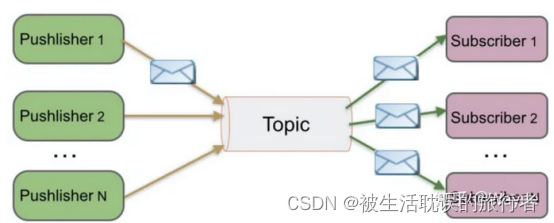
名词解释:
Publisher=发布者
Topic=主题
Subscriber=订阅者
Publish/Subscribe模式工作原理:
1、消息发布者Publisher将消息发布到主题Topic中,同时有多个消息消费者
2、Subscriber消费该消息。和PTP方式不同,发布到Topic的消息会被所有订阅者消费。
3、当发布者发布消息,不管是否有订阅者,都不会报错信息。 4、一定要先有消息发布者,后有消息订阅者。注意:Kafka所采用的就是发布/订阅模式,被称为一种高吞吐量、持久性、分布式的发布订阅的消息队列系统。
1.4常用消息系统对比
1、RabbitMQ Erlang编写,支持多协议 AMQP,XMPP,SMTP,STOMP。支持负载均衡、数据持久化。同时
支持Peer-to-Peer和发布/订阅模式
2、Redis 基于Key-Value对的NoSQL数据库,同时支持MQ功能,可做轻量级队列服务使用。就入队操作而言,
Redis对短消息(小于10KB)的性能比RabbitMQ好,长消息的性能比RabbitMQ差。
3、ZeroMQ轻量级,不需要单独的消息服务器或中间件,应用程序本身扮演该角色,Peer-to-Peer。它实质上是一个库,需要开发人员自己组合多种技术,使用复杂度高
4、ActiveMQ JMS实现,Peer-to-Peer,支持持久化、XA事务
5、Kafka/Jafka 高性能跨语言的分布式发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理
6、MetaQ/RocketMQ 纯Java实现,发布/订阅消息系统,支持本地事务和XA分布式事务
1.5Kafka六大特点
1、高吞吐量、低延迟:可以满足每秒百万级别消息的生产和消费。它的延迟最低只有几毫秒,topic可以分多个partition, consumer group 对partition进行consumer操作
2、持久性、可靠性:有一套完善的消息存储机制,确保数据高效安全且持久化。消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
3、分布式:基于分布式的扩展;Kafka的数据都会复制到几台服务器上,当某台故障失效时,生产者和消费者转而使用其它的Kafka。
4、可扩展性:kafka集群支持热扩展
5、容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
6、高并发:支持数千个客户端同时读写
1.6Kafka的几个概念Kafka的几个概念
1、Kafka作为一个集群运行在一个或多个服务器上,这些服务器可以跨多个机房,所以说kafka是分布式的发布订阅消息队列系统。
2、Kafka集群将记录流存储在称为Topic的类别中。
3、每条记录由键值;"key value"和一个时间戳组成。
1.7Kafka核心组件
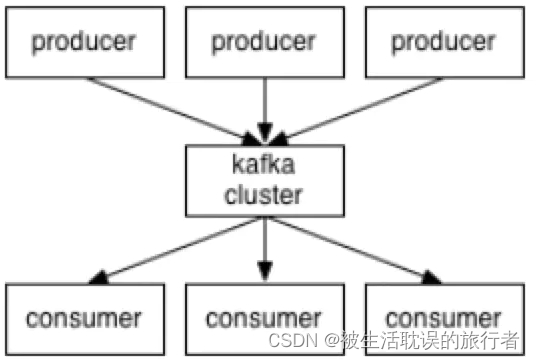
1、Producer:消息生产者,产生的消息将会被发送到某个topic
2、Consumer:消息消费者,消费的消息内容来自某个topic
3、Topic:消息根据topic进行归类,topic其本质是一个目录,即将同一主题消息归类到同一个目录
4、Broker:每一个kafka实例(或者说每台kafka服务器节点)就是一个broker,一个broker可以有多个topic
Zookeeper:zookeeper集群不属于kafka内的组件,但kafka依赖zookeeper集群保存meta信息,所以在此做声明其重要性。
zookeeper集群搭建地址:https://blog.csdn.net/weixin_45894220/article/details/127866337
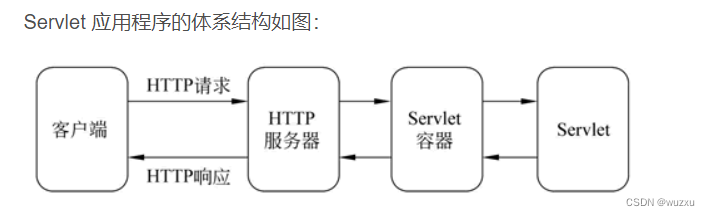
结构图如下
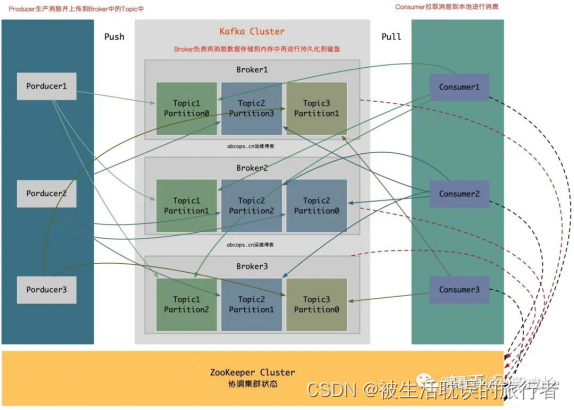
1、Producer:消息和数据的生产者,主要负责生产Push消息到指定Broker的Topic中。
2、Broker:Kafka节点就是被称为Broker,Broker主要负责创建Topic,存储Producer所发布的消息,记录消息处理的过程,现是将消息保存到内存中,然后持久化到磁盘。
3、Topic:同一个Topic的消息可以分布在一个或多个Broker上,一个Topic包含一个或者多个Partition分区,数据被存储在多个Partition中。
4、replication-factor:复制因子;这个名词在上图中从未出现,在我们下一章节创建Topic时会指定该选项,意思为创建当前的Topic是否需要副本,如果在创建Topic时将此值设置为1的话,代表整个Topic在Kafka中只有一份,该复制因子数量建议与Broker节点数量一致。
5、Partition:分区;在这里被称为Topic物理上的分组,一个Topic在Broker中被分为1个或者多个Partition,也可以说为每个Topic包含一个或多个Partition,(一般为kafka节.点数CPU的总核心数量)分区在创建Topic的时候可以指定。分区才是真正存储数据的单元。6、Consumer:消息和数据的消费者,主要负责主动到已订阅的Topic中拉取消息并消费,为什么Consumer不能像Producer一样的由Broker去push数据呢?因为Broker不知道Consumer能够消费多少,如果push消息数据量过多,会造成消息阻塞,而由Consumer去主动pull数据的话,Consumer可以根据自己的处理情况去pull消息数据,消费完多少消息再次去取。这样就不会造成Consumer本身已经拿到的数据成为阻塞状态。
7、ZooKeeper:ZooKeeper负责维护整个Kafka集群的状态,存储Kafka各个节点的信息及状态,实现Kafka集群的高可用,协调Kafka的工作内容。
Broker和Consumer有使用到ZooKeeper,而Producer并没有使用到ZooKeeper。
因为Kafka从0.8版本开始,Producer并不需要根据ZooKeeper来获取集群状态,而是在配置中指定多个Broker节点进行发送消息,同时跟指定的Broker建立连接,来从该Broker中获取集群的状态信息,所以Producer可以知道集群中有多少个Broker是否在存活状态,每个Broker上的Topic有多少个Partition。
Prodocuer会讲这些元信息存储到Producuer的内存中。
如果Producoer向集群中的一台Broker节点发送信息超时等故障,Producer会主动刷新该内存中的元信息,以获取当前Broker集群中的最新状态,转而把信息发送给当前可用的Broker,当然Prodocuer也可以在配置中指定周期性的去刷新Broker的元信息以更新到内存中。
注意:
我们可以看到上图,Broker和Consumer有使用到ZooKeeper,而Producer并没有使用到ZooKeeper,因为Kafka从0.8版本开始,Producer并不需要根据ZooKeeper来获取集群状态,而是在配置中指定多个Broker节点进行发送消息,同时跟指定的Broker建立连接,来从该Broker中获取集群的状态信息,这是Producer可以知道集群中有多少个Broker是否在存活状态,每个Broker上的Topic有多少个Partition,Prodocuer会讲这些元信息存储到Producuer的内存中。如果Producoer像集群中的一台Broker节点发送信息超时等故障,Producer会主动刷新该内存中的元信息,以获取当前Broker集群中的最新状态,转而把信息发送给当前可用的Broker,当然Prodocuer也可以在配置中指定周期性的去刷新Broker的元信息以更新到内存中。
注意:只有Broker和ZooKeeper才是服务,而Producer和Consumer只是Kafka的SDK罢了
1.8Kafka数据处理步骤
1、Producer产生消息,发送到Broker中
2、Leader状态的Broker接收消息,写入到相应topic中
3、Leader状态的Broker接收完毕以后,传给Follow状态的Broker作为副本备份
4、Consumer消费Broker中的消息
1.9Kafka名词解释和工作方式
Producer:消息生产者,就是向kafka broker发消息的客户端。 Consumer:消息消费者,向kafka
broker取消息的客户端 Topic:可以理解为一个队列。
Consumer Group(CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
Broker:一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
1.10Consumer与topic关系
kafka只支持Topic
1、每个group中可以有多个consumer,每个consumer属于一个consumer
group;通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效那么其消费的partitions将会有其他consumer自动接管。
2、对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer;那么一个group中所有的consumer将会交错的消费整个Topic,每个group中consumer消息消费互相独立,我们可以认为一个group是一个"订阅"者。
3、在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);
一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。
4、kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。kafka只能保证一个partition中的消息被某个consumer消费时是顺序的;事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的。
1.11Kafka消息的分发
1、Producer客户端负责消息的分发
2、kafka集群中的任何一个broker都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"、“partitions
leader列表"等信息;
3、当producer获取到metadata信息之后, producer将会和Topic下所有partition leader保持socket连接;
4、消息由producer直接通过socket发送到broker,中间不会经过任何"路由层”。
事实上,消息被路由到哪个partition上由producer客户端决定,比如可以采用"random"“key-hash”"轮询"等。
如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的。
1、在producer端的配置文件中,开发者可以指定partition路由的方式。
2、Producer消息发送的应答机制设置发送数据是否需要服务端的反馈,有三个值0,1,-1
0: producer不会等待broker发送ack
1: 当leader接收到消息之后发送ack
-1: 当所有的follower都同步消息成功后发送ack request.required.acks=0
1.12Consumer的负载均衡
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力,步骤如下:
1、假如topic1,具有如下partitions: P0,P1,P2,P3
2、加入group A 中,有如下consumer:C0,C1
3、首先根据partition索引号对partitions排序: P0,P1,P2,P3
4、根据consumer.id排序: C0,C1
5、计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6、然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
Kafka原理参考地址:
https://zhuanlan.zhihu.com/p/163836793
https://cdn.modb.pro/db/105106
https://www.jianshu.com/p/47487f35b964
二、kafka集群搭建超详细教程
2.1、准备三个虚拟机:
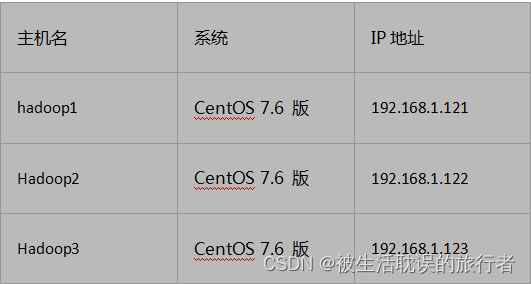
1、虚拟机上配置有ssh服务,可以进行免密登录
2、Kafka运行在JVM上,需要安装JDK
3、kafka依赖zookeeper,需要安装zookeeper,
具体可参考:
https://blog.csdn.net/weixin_45894220/article/details/127866337
2.2、下载安装包
[root@hadoop1 ~]# cd /opt/module
#下载kafka安装包
[root@hadoop1 module]# wget https://archive.apache.org/dist/kafka/2.6.0/kafka_2.13-2.6.0.tgz
2.3、解压
[root@hadoop1 module]# tar -zxvf kafka_2.13-2.6.0.tgz
[root@hadoop1 module]# mv kafka_2.13-2.6.0 kafka
2.4、创建存放kafka消息的目录
[root@hadoop1 module]# cd kafka
[root@hadoop1 kafka]# mkdir kafka-logs
2.5、修改配置文件
进入配置文件目录
[root@hadoop1 config]# cd config/
备份
[root@hadoop1 config]# cp server.properties server.properties.bak
修改配置文件
[root@hadoop1 config]# vim server.properties
# 修改如下参数
broker.id=0
listeners=PLAINTEXT://hadoop1:9092
log.dirs=/opt/module/kafka/kafka-logs
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181
参数说明:
broker.id : 集群内全局唯一标识,每个节点上需要设置不同的值
listeners:这个IP地址也是与本机相关的,每个节点上设置为自己的IP地址
log.dirs :存放kafka消息的
zookeeper.connect : 配置的是zookeeper集群地址
2.6、分发kafka安装目录
#分发kafka安装目录给其他集群节点
[root@hadoop1 config]# scp -r /opt/module/kafka/ hadoop2:/opt/module
[root@hadoop1 config]# scp -r /opt/module/kafka/ hadoop3:/opt/module
分发完成后,其他集群节点都需要修改配置文件server.properties中的broker.id和listeners参数
hadoop2 修改
broker.id=2
listeners=PLAINTEXT://hadoop2:9092
hadoop3修改
broker.id=3
listeners=PLAINTEXT://hadoop3:9092
2.7、编写kafka集群操作脚本
[root@hadoop1 config]# cd /opt/module/kafka/bin
#创建kafka启动脚本
vim kafka-cluster.sh
# 添加如下内容
#!/bin/bash
case $1 in
"start"){
for i in hadoop1 hadoop2 hadoop3
do
echo -------------------------------- $i kafka 启动 ---------------------------
ssh $i "source /etc/profile;/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
}
;;
"stop"){
for i in hadoop1 hadoop2 hadoop3
do
echo -------------------------------- $i kafka 停止 ---------------------------
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh"
done
}
;;
esac
保存退出后,修改执行权限
chmod +x ./kafka-cluster.s
脚本命令说明:
启动kafka集群命令
./kafka-cluster.sh start
停止kafka集群命令
./kafka-cluster.sh stop
7.8、启动kafka集群
首先启动zookeeper集群
然后执行kafka集群脚本启动命令
[root@hadoop1 bin]# ./kafka-cluster.sh start
-------------------------------- hadoop1 kafka 启动 ---------------------------
-------------------------------- hadoop2 kafka 启动 ---------------------------
-------------------------------- hadoop3 kafka 启动 ---------------------------
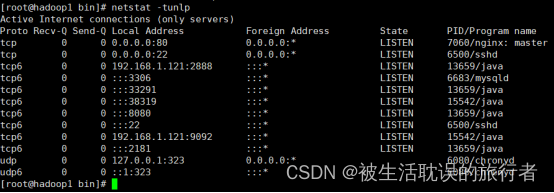
查看进程是否存在
[root@hadoop1 bin]# netstat -tunlp
7.9、测试验证
kafka集群启动成功后,我们就可以对kafka集群进行操作了
创建主题
[root@hadoop1 kafka]# cd /opt/module/kafka
[root@hadoop1 kafka]# ./bin/kafka-topics.sh --create --bootstrap-server hadoop1:9092 --replication-factor 3 --partitions 1 --topic test
输出:Created topic test.
查看主题列表
[root@hadoop1 kafka]# ./bin/kafka-topics.sh --list --bootstrap-server hadoop1:9092
输出:test
启动控制台生产者
[root@hadoop1 kafka]# ./bin/kafka-console-producer.sh --broker-list hadoop1:9092 --topic test
启动控制台消费者
[root@hadoop1 kafka]# ./bin/kafka-console-consumer.sh --bootstrap-server hadoop1:9092 --topic test --from-beginning
在生产者控制台输入hello kafka,消费者控制台,就可以消费到生产者的消息,输出 hello kafka,表示消费端成功消费了生产者生产的消息!
至此,我们就顺利完成了kafka集群搭建的整个过程!