1.分区
1.概念
Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多
个人理解白话:按表中或者自定义的一个列,对数据进行了group by, 然后这时候,查询出的一行就是一个文件,或者说,分区列一行对应一个文件
本质是MR中默认的分区操作,分桶字段就是MR中的key,分桶数就是MR中ReduceTask的数量
2.操作
一级分区学习
1.创建分区表
就是加个partition by (分区列名 列格式)
create table dept_partition
(
deptno int, --部门编号
dname string, --部门名称
loc string --部门位置
)
partitioned by (day string)
row format delimited fields terminated by '\t';
2.添加数据
创建数据
//在/opt/module/hive/datas/路径上创建文件dept_20220401.log,并输入如下内容。
[atguigu@hadoop102 datas]$ vim dept_20220401.log
10 行政部 1700
20 财务部 1800
插入数据 需要指定插入的分区
load data local inpath '/opt/module/hive/datas/dept_20220401.log'
into table dept_partition
partition(day='20220401');
insert overwrite table dept_partition partition (day = '20220402')
select deptno, dname, loc
from dept_partition
where day = '2020-04-01';
3.读数据
需要指明分区
select deptno, dname, loc ,day
from dept_partition
where day = '2020-04-01';
4.添加和删除分区
注意 分区分桶的操作,都是表操作,DDL 都是alter
为什么呢?因为分区相当于多加了一列,
// 1.查看所有分区新信息
show partitions dept_partition;
// 2.创建单个分区
alter table dept_partition
add partition(day='20220403');
// 3.创建多个分区
alter table dept_partition
add partition(day='20220404') partition(day='20220405');
// 4.删除单个分区
alter table dept_partition
drop partition (day='20220403');
// 5.删除多个分区
alter table dept_partition
drop partition (day='20220404'), partition(day='20220405');
4.修复分区
为什么要修复分区?
数据不同步 : 情况1: 元数据有 HADOOP 无
情况2: 元数据无 HADOOP 有
但是注意
情况1 数据已经不存在了,只有元数据存在,同步的话,需要删除元数据
情况2 HADOOP中的数据还存在,元数据没有了,这时候,同步就生成元数据即可(重新导入一遍)
命令
add 增加分区信息
drop 删除分区信息
sync = add+drop
msck repair table table_name [add/drop/sync partitions];
2.二级分区
就是多加一列,用逗号隔开
create table dept_partition2(
deptno int, -- 部门编号
dname string, -- 部门名称
loc string -- 部门位置
)
partitioned by (day string, hour string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/hive/datas/dept_20220401.log'
into table dept_partition2
partition(day='20220401', hour='12');
select
*
from dept_partition2
where day='20220401' and hour='12';
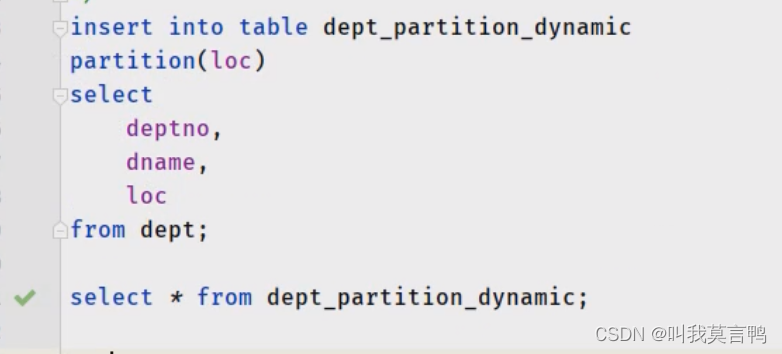
3.动态分区
根据最后一个列作为分区标准
感觉动态分区一般作为表优化使用(表数据量过大需要分区,但是手动分区太过繁琐)

2.分桶
1.概念
按行进行截取,行进行分桶
2. 例题
1.建表
create table stu_buck_sort(
id int,
name string
)
clustered by(id) sorted by(id)
into 4 buckets
row format delimited fields terminated by '\t';
分成4个部分,默认分桶规则是哈希取余(或者整数取余)
分桶必排序